
基于 Harness Engineering 三根支柱的深度对比
上一篇我们聊了 Harness Engineering 的三根支柱:评估闭环、架构约束、记忆治理。
评论区最多的问题是:“道理我都懂,但具体怎么做?”
今天这篇,我不讲一种方案,而是对比两种路径:
- Hermes-Agent:Nous Research 在 3 月发布的自进化 Agent 框架
- 自建 Harness:我们基于 OpenClaw 搭建的 MemOS 系统,凤凰架构
两种路径都在践行 Harness Engineering,但设计哲学截然不同。看完这篇,你会知道自己应该选哪条路。
目录
- 第一部分:两种哲学— 理解根本差异
- 第二部分:记忆治理对比— 如何解决 Agent 的失忆症
- 第三部分:架构约束对比— 如何明确 Agent 的职责边界
- 第四部分:评估闭环对比— 如何保证 Agent 的质量
- 第五部分:成本与选择— 你应该选哪个?
第一部分:两种哲学
在拆技术细节之前,先理解两种设计哲学的根本差异。
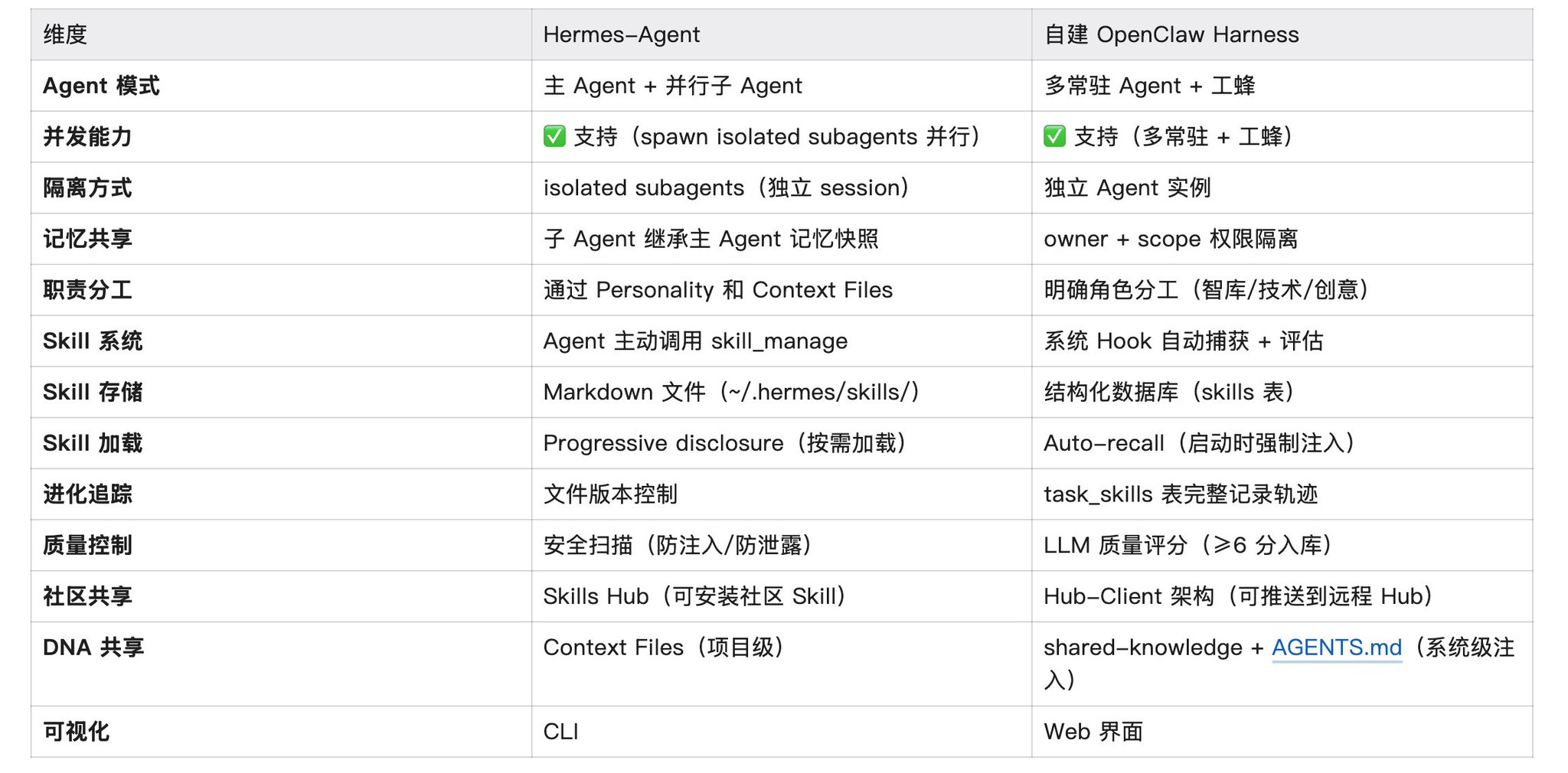
1 Hermes-Agent:有界热记忆 + 多层检索 + 主动进化
**核心理念:**Agent 应该像人脑一样,工作记忆有限必须精炼,但可以通过多层记忆架构随时回溯更深层的信息。 关键特性:
- 三层记忆架构: L1 热记忆:MEMORY.md(2200 字符上限)+ USER.md,Agent 的工作记忆,满了就得合并或替换 L2 外部记忆:支持 8+ 个外部记忆 Provider 插件(如 Honcho 语义搜索,还在增加) L3 冷检索:Session History 全文搜索(SQLite FTS5),跨 session 找回历史对话
- **主动管理:**Agent 自己决定什么值得记、什么值得固化成 Skill
- **自学习闭环:**后台周期性触发(不阻塞对话),自动 review 和优化 Skill
- **CLI 优先:**终端 + 消息平台(Telegram/Discord/Slack),轻量、快速
- **个人助手定位:**主 Agent + 并行子 Agent
- **成本控制:**冻结快照(Frozen Snapshot)保护 prefix cache,Auxiliary 副驾模型路由降级
**适合场景:**你需要一个能记住你偏好的个人 AI 助手,快速启动,不想搭复杂基础设施。
2 自建 OpenClaw Harness:无界、自动化、系统强制
**核心理念:**Agent 的记忆应该像外部硬盘,容量无限,系统自动管理。
关键特性:
- 无界记忆:几万条记忆 + 混合搜索,老经验不会被挤掉
- 系统强制:Hook 机制自动捕获轨迹,不依赖 Agent 自觉
- 可视化管理:Web 界面看记忆演变、Skill 进化树、任务轨迹
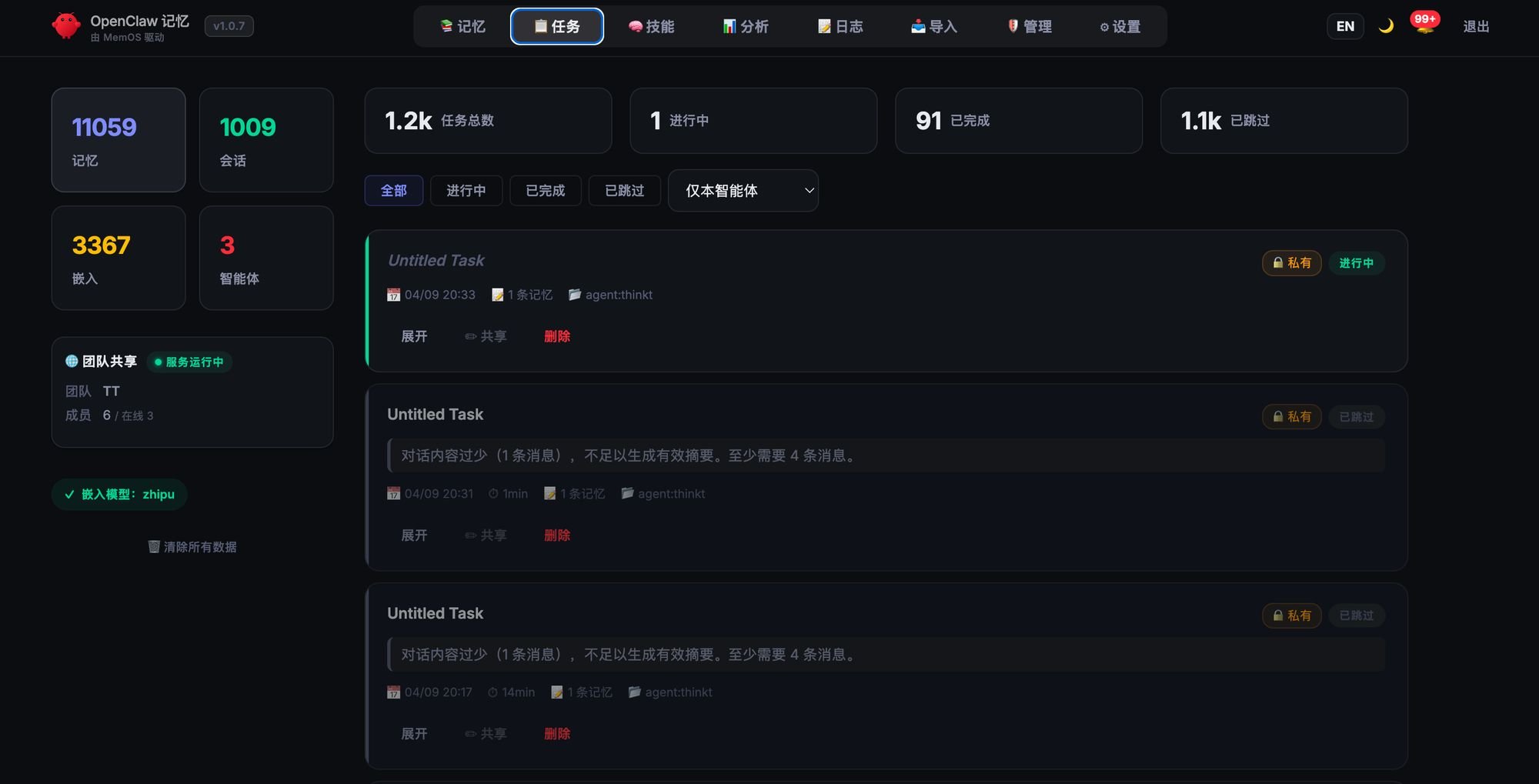
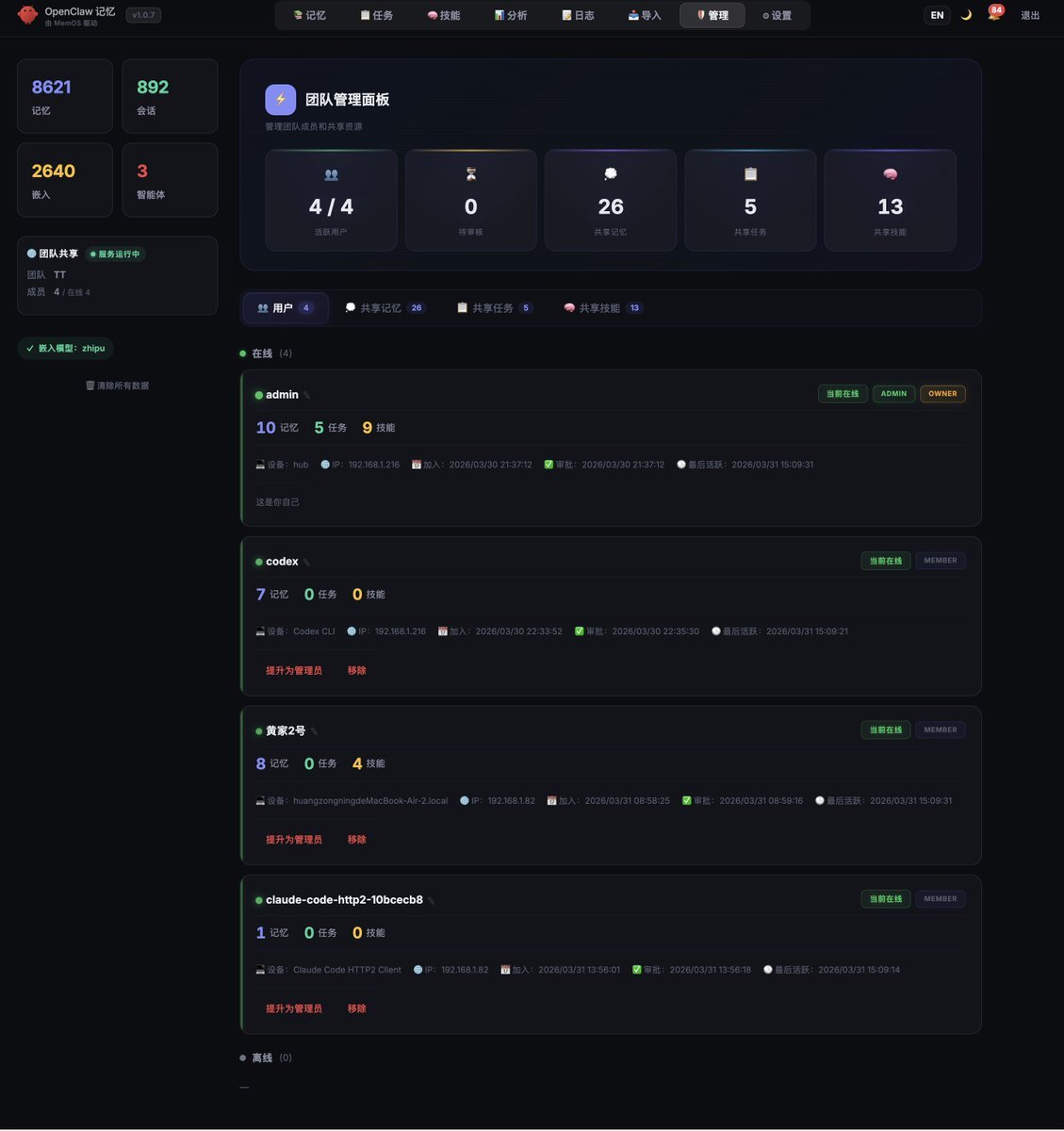
MemOS 任务管理界面:实时查看任务状态、团队协作、Agent 运行情况
- 团队协作定位:多常驻 Agent + 工蜂,权限隔离 + 知识共享
**适合场景:**你需要多 Agent 长期协作,积累大量经验,需要可视化管理和分析。
第二部分:记忆治理对比
1 核心问题:Agent 的失忆症
你有没有跟 Claude 聊了三小时,帮你重构了一整个模块,第二天打开——它什么都不记得?
你得重新解释项目背景、代码风格、上次踩过的坑。就好像你有一个超级聪明的同事,但他每天早上都会失忆。
这不是 Claude 的问题,是所有 Agent 的通病。上下文窗口就是“内存”,关机就没了。
Harness 的第一根支柱就是解决这个问题:给 Agent 搭一套持久化记忆系统。
2 Hermes-Agent 的方案:热记忆精炼 + 冷检索兜底
**设计哲学:**人脑容量有限,但我们依然能处理复杂问题。因为我们会遗忘不重要的,只保留最关键的。
技术实现:三层记忆架构
Plain Text~/.hermes/memory/ ├── MEMORY.md # L1: 2200 字符上限,热记忆(工作记忆) ├── USER.md # L1: 1375 字符上限,用户画像和偏好 ├── external/ # L2: 外部 Provider(Honcho/Mem0 等) └── sessions/ # L3: 历史对话,FTS5 全文检索
L1 热记忆(MEMORY.md)的管理方式:
Agent 通过 memory工具主动管理:
- memory add "重要信息":添加新记忆
- memory replace "旧内容" "新内容":更新记忆
- memory remove "不再需要的内容":删除记忆
满了怎么办?Agent 必须做选择:删掉旧的,或者合并相关记忆。
但 Hermes 并非"只有有界记忆":
- L1 热记忆(2200 字符)类似人的"工作记忆"——只保留当前最重要的
- L2 外部 Provider(如 Honcho)提供语义搜索能力——长期记忆存储
- L3 Session Search用 FTS5 全文检索历史对话——想找总能找到
所以 Hermes 的记忆策略是:"热记忆精炼 + 冷检索兜底"。
热记忆保证质量(只留最重要的),冷检索保证不丢失(想找总能找到)。
优点:
- 强制 Agent 精炼热记忆,质量高
- 文件存储,简单、可读、易迁移
- FTS5 检索快(<50ms)
- 支持 8 个外部记忆提供商(L2 扩展)
缺点:
- L1 容量有限,依赖 L2/L3 检索补充
- 依赖 Agent 自觉管理,可能会漏
- L2 需要额外配置外部服务
3 自建 Harness 的方案:无界记忆 + 自动进化
**设计哲学:**记忆不应该有上限。用混合搜索保证检索质量,用自动去重保证不膨胀。
技术实现:
Plain Text
PostgreSQL 17 + pgvector ├── memories 表 # 35,000+ 条记忆 ├── skills 表 # 几百个 Skill ├── task_skills 表 # 任务与 Skill 的关联 └── memory_graph 表 # 65,524 条关系边
Hook 机制:100% 捕获的秘密
为什么传统方案捕获率只有 60%?
因为依赖 Agent “记得”去存记忆。Agent 可能:
- 忙着处理任务,忘了调用 memory 工具
- 觉得“这个不重要”,但其实很重要
- Session 崩了,还没来得及存
MemOS 的 Hook 机制怎么解决?
OpenClaw 原生支持 Hook,基于事件驱动。MemOS 利用了两个关键 Hook:
before_agent_start**(启动前)**
Agent 每次启动时,MemOS 自动检索相关记忆,强制注入到 System Prompt。Agent 想不看都不行。
agent_end**(结束后)**
每轮对话结束,MemOS 自动捕获完整对话,走智能去重流程。
Python
agent_end Hook:每轮对话结束自动捕获
def capture_memory(session):
1. 内容哈希精确去重
2. Top-5 相似度检测(阈值 0.75)
3. LLM 最终裁决(DUPLICATE/UPDATE/NEW)
4. 写入数据库
智能去重的三层机制:
- 内容哈希精确去重— 完全相同的对话直接跳过
- Top-5 相似度检测— 阈值 0.75,找出高度相似的记忆
- LLM 最终裁决— 判断关系: DUPLICATE → 跳过(完全重复) UPDATE → 合并到已有记忆(偏好演变) NEW → 创建新记忆(全新经验)
这意味着你反复讨论同一个话题,记忆不会膨胀成一堆重复条目,而是会自动合并进化。
举个例子。我们的 Agent 之前犯过一个错:用户说“发给我 PDF”,Agent 只回了“已生成”,没有真的发附件。这个教训被 MemOS 存下来之后,下次遇到类似请求,Hook 会自动把“上次错误:只说已生成,没有发送附件”注入到上下文里。Agent 被迫看到这条记忆,就不会再犯同样的错。
这就是 100% 捕获率的秘密 — 不给 Agent 选择的机会,系统强制执行。
混合搜索:语义理解 + 精确匹配
BM25 关键词 + 向量余弦 + RRF 融合:
- BM25负责精确匹配(“Python 错误处理”)
- 向量负责语义理解(“异常捕获”也能匹配上)
- RRF融合两者的结果
这比 Hermes 的 FTS5 全文搜索强在哪?语义理解能力。FTS5 只能匹配关键词,不能理解“Python 错误处理”和“异常捕获”是同一个意思。
两级共享架构:有策略的知识流动
传统共享的三个困境:
- 单一共享库→ 隐私泄露(智库的私密决策被工蜂看到)
- 各自独立库→ 知识孤岛(智库踩的坑,技术顾问还得再踩)
- 定期同步→ 冲突复杂(延迟高、容易丢数据)
MemOS 的两级设计(魔改了一下,把codex,claude code也加入团队中):
第一级:同实例内共享(Local Scope)
物理上同库,逻辑上隔离:
- 所有 Agent 共用一个本地数据库
- 每条记忆有 owner 字段标识归属
- 搜索时通过 scope 参数控制范围: scope=private — 只有 owner 能看 scope=shared — 团队所有人能看 scope=public — 可以推送到远程 Hub
零拷贝共享— 不需要把数据从智库的库复制到技术顾问的库,物理上只有一份数据,逻辑上按需可见。
第二级:跨实例 Hub-Client
Hub 是一个 HTTP Server,监听在 gatewayPort + 11。认证用自签 HMAC Token,完全自包含。
关键设计:数据共享是主动推送模式,不是自动同步。
私有数据永远不离开本地,只有你主动 share 的才会到 Hub。Hub 端搜索也只返回摘要,要看详情得二次请求。
实战案例:
Python
智库的私密记忆
memory.add(content="考虑更换供应商 X", owner="zhiku", scope="private")
团队共享经验
memory.add(content="Python 错误处理用 try-except-else", owner="zhiku", scope="shared")
工蜂搜索时只能看到 scope="shared" 的记忆,看不到 scope="private" 的。智库的私密决策不会泄露给工蜂,但团队共享经验所有人都能看到
优点:
- 无上限,老经验不会被挤掉
- 100% 捕获率,不依赖 Agent 自觉
- 权限隔离,适合多 Agent 协作
- 可视化界面,能看记忆演变
缺点:
- 搭建成本高(数据库 + Hook 系统)
- 首次检索慢(加载向量模型 ~8s)
- 维护成本高(需要监控、优化)
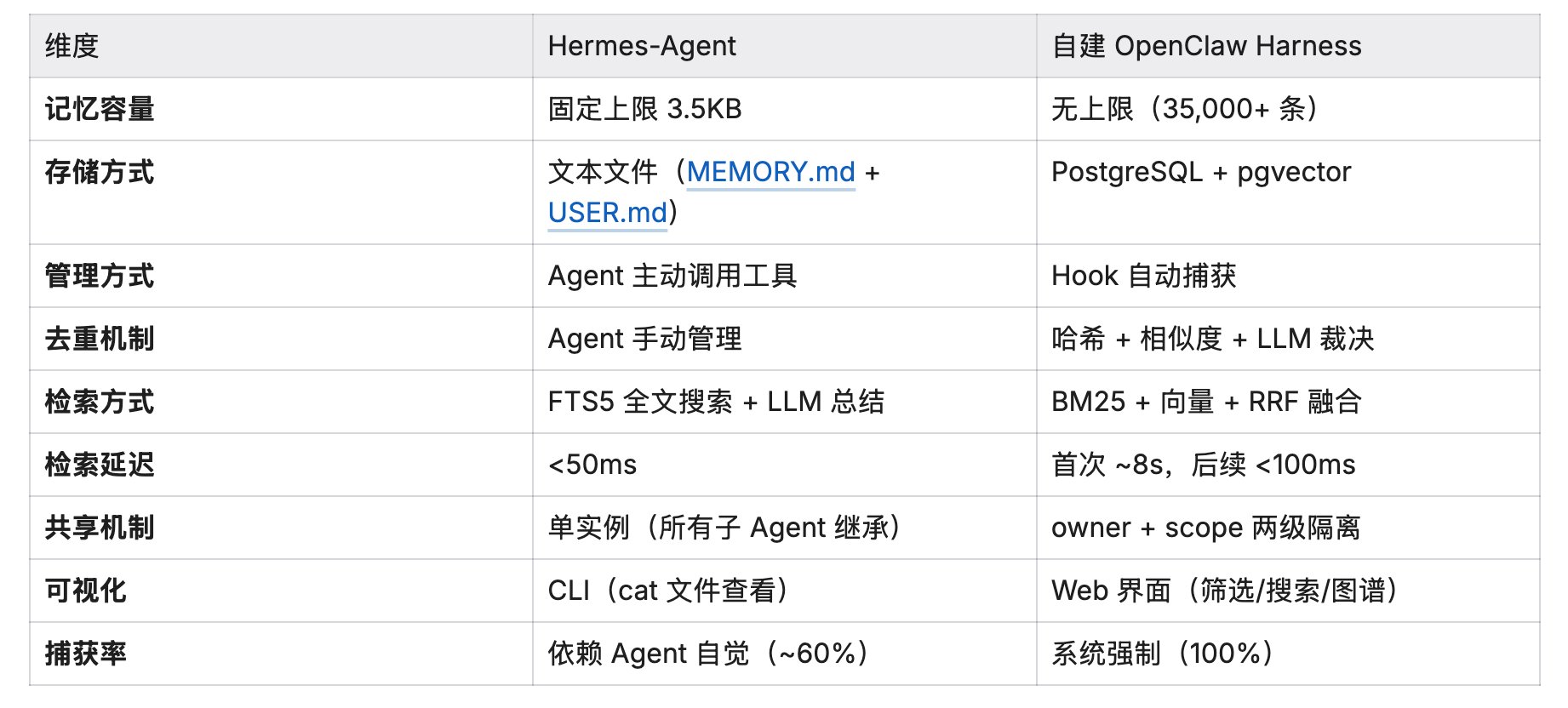
4 技术对比表
5 实战数据对比
Hermes-Agent 的数据:
- 记忆容量:~3.5KB(固定上限)
- 检索延迟:<50ms
- 适合用户:个人用户,记忆量可控
我们的 MemOS 数据:
- 总记忆量:35,000+ 条
- 智库占比:44%(15,220 条)
- 黄家 1 号占比:31%(10,852 条)
- 共享记忆:10%(3,534 条)
- 图谱关系边:65,524 条
- Token 节省:72%(vs 原生 memorySearch)
- 检索延迟:首次 ~8s(加载模型),后续 <100ms
关键差异:
- Hermes 的记忆是“精炼的摘要”,我们的记忆是“完整的轨迹”
- Hermes 适合“快速启动 + 轻量使用”,我们适合“长期积累 + 深度分析”
6 适用场景
选 Hermes-Agent 如果:
- 你是个人用户,记忆量可控
- 你希望 Agent 有主动权,自己决定记什么
- 你需要快速启动,不想搭复杂基础设施
- 你喜欢 CLI,不需要可视化界面
自建 Harness 如果:
- 你需要多 Agent 长期协作
- 你需要无上限记忆 + 权限隔离
- 你需要 100% 轨迹捕获(不依赖 Agent 自觉)
- 你需要可视化界面来管理和分析
第三部分:架构约束对比

1 核心问题:Agent 的职责混乱
单个 Agent 什么都干,结果什么都干不好。写代码时突然去写推文,写推文时突然去调配置,最后上下文爆了,什么都没做完。
Harness 的第二根支柱就是解决这个问题:用架构约束明确职责边界。
2 Hermes-Agent 的方案:主 Agent + 子 Agent 并行
**设计哲学:**一个主 Agent 负责协调,遇到特定任务时 spawn 子 Agent 处理,支持并行执行多个子 Agent。
技术实现:
主 Agent(常驻) ├── 接收任务 ├── 判断是否需要 spawn 子 Agent ├── spawn 多个子 Agent(继承主 Agent 的记忆) │ ├── 子 Agent A:处理任务 1 │ ├── 子 Agent B:处理任务 2(并行) │ └── 子 Agent C:处理任务 3(并行) ├── 各子 Agent 独立执行(isolated subagents) ├── 子 Agent 返回结果 └── 主 Agent 整合结果
关键特性:
- 并行执行:多个子 Agent 可以同时运行,处理不同的任务
- 隔离环境:每个子 Agent 是独立的(isolated subagents),有自己的 session、conversation thread 和 terminal
- 记忆继承:子 Agent 在启动时继承主 Agent 的记忆快照(MEMORY.md + USER.md),但运行时是独立的
Personality 和 Context Files:
通过 Personality 定义 Agent 的角色:
Markdown
You are a helpful AI assistant specialized in Python development. You prefer concise code with minimal comments.
通过 Context Files 注入项目级知识:
Plain Text
~/.hermes/context/ ├── project.md # 项目背景 ├── style.md # 代码风格 └── conventions.md # 命名规范
Skills 系统:
Agent 通过 skill_manage 工具创建 Skill:
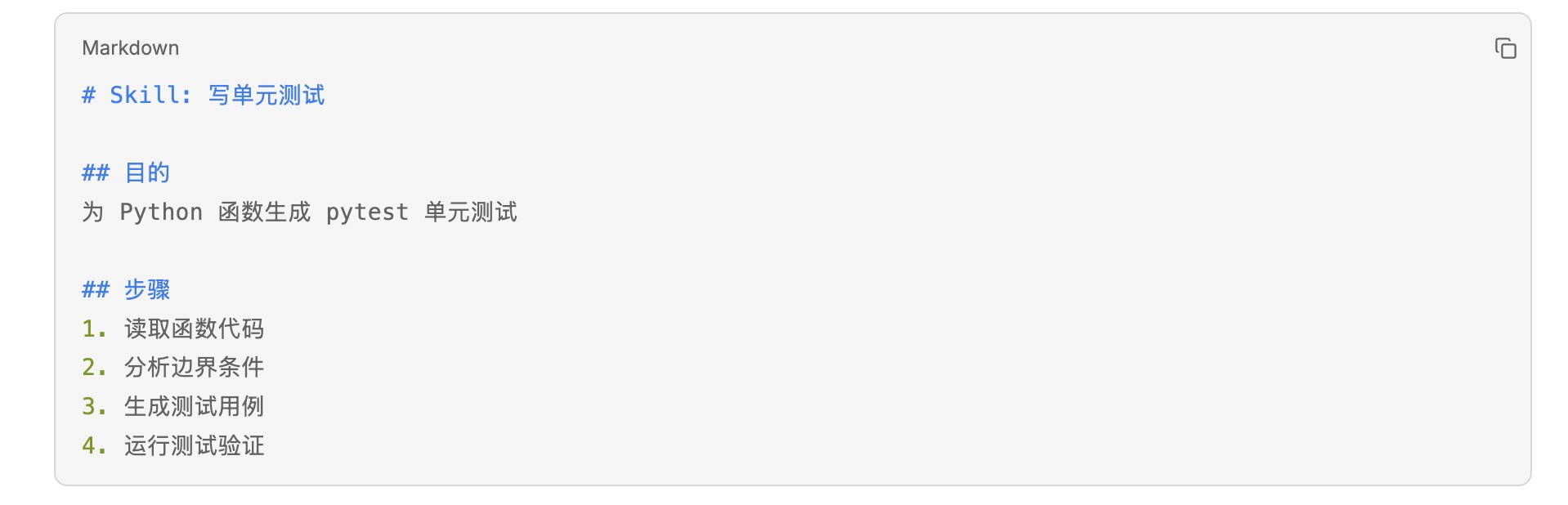
Skills 存储在 ~/.hermes/skills/ 目录,可以通过 Skills Hub 安装社区 Skill。
Progressive disclosure:
启动时只注入 Skill 的描述索引,Agent 需要时再加载完整内容。节省 token。
优点:
- 架构简单,容易理解
- 主 Agent 保持上下文连续性
- 子 Agent 用完即毁,不占资源
- Skills Hub 有大量社区 Skill
缺点:
- 所有子 Agent 共享主 Agent 的记忆(无法权限隔离)
- 子 Agent 是临时的,不适合长期协作
- Skills 依赖 Agent 主动创建,可能会漏
3 自建 Harness 的方案:多常驻 Agent + 工蜂
**设计哲学:**多个常驻 Agent 明确分工,遇到特定任务时 spawn 工蜂(一次性专家),工蜂临终前反哺经验。
技术实现:
Plain Text
4 个常驻 Agent(各司其职) ├── 智库:任务协调者,审核质量 ├── 黄家 1 号:集成协调者,对外输出 ├── 技术顾问:工程师,写代码、调配置 └── 创意伙伴:内容创作,写推文、写文章
工蜂系统(按需 spawn) ├── 写作工蜂:专门写文章 ├── 配图工蜂:专门配图 ├── 爬虫工蜂:专门爬数据 └── ...(按需定义)
DNA 级共享:
所有 Agent 和工蜂共享 shared-knowledge/ 目录:
Plain Text
shared-knowledge/ ├── AGENTS.md # 系统级规范(自动注入到 System Prompt) ├── config/ # 模型配置、API 密钥 ├── knowledge/ # 公共知识库 ├── templates/ │ └── recipes/ # 任务配方(article.md, tweet.md) ├── bees/ # 工蜂定义 └── tools/ # 工具使用指南
工蜂出生时,AGENTS.md 会被自动注入到它的 System Prompt 里。这个文件包含:
- 工具参数规范
- 输出语言
- 写作风格
- 禁忌词列表
- 反哺规范
**这就是 DNA。**每只工蜂出生就自带团队的全部基因,不需要任何人跟它“拉齐”。
临终反哺(升级为MemOS的对话->任务->skill系统):
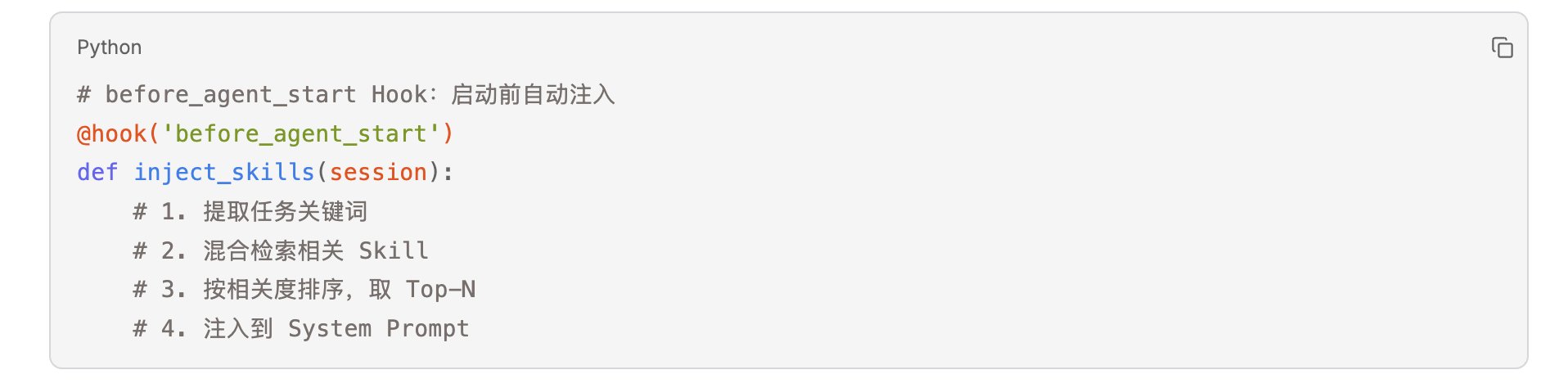
工蜂完成任务后,系统 Hook 自动捕获完整轨迹:

Auto-recall:
下一只工蜂启动时,系统自动注入相关 Skill:
Python
优点:
- 多 Agent 并发,吞吐量高
- 常驻 Agent 保持专业化
- 工蜂按需 spawn,灵活应变
- 100% 轨迹捕获,经验不丢失
- 可视化 Skill 进化树
缺点:
- 架构复杂,搭建成本高
- 需要 Hook 系统支持
- Token 消耗高(Auto-recall 注入完整 Skill)
4 Skill 系统深度对比
这是两种方案差异最大的地方,值得单独拆解。
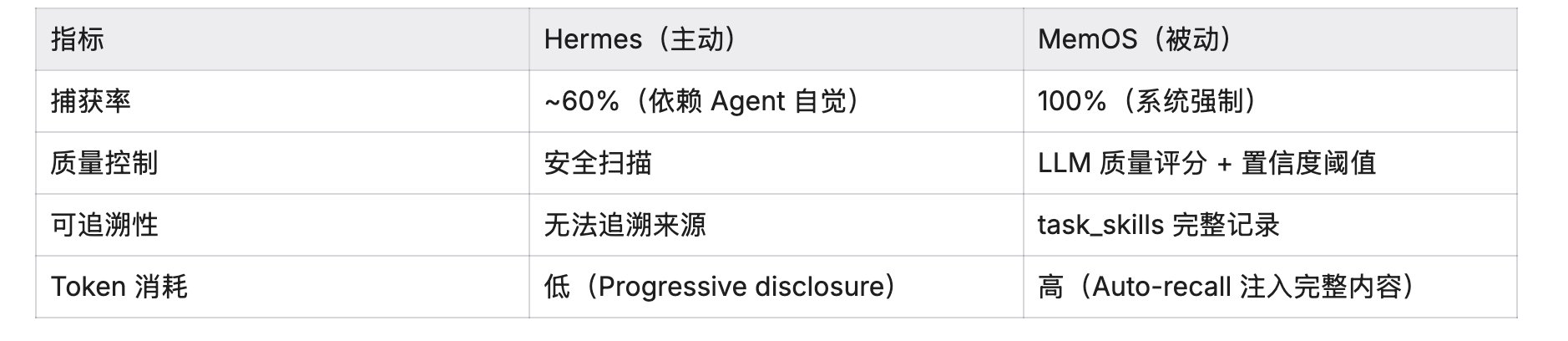
Hermes 的 Skill:主动生成,但质量控制薄弱
**生成方式:**Agent 自主调用 skill_manage create,后台周期性 review。
优点:
- Agent 有主动权,可以精心设计 Skill 结构
- Progressive disclosure 节省 token(启动时只注入索引,需要时再加载完整内容)
- Skills Hub 社区生态,可安装他人分享的 Skill
已知问题:
- Skill 重复制造(社区反馈高频问题)——说明后台 review 的去重/合并机制不够强
- 去重依赖 Agent 自觉 + 后台 review,缺少系统级强制去重
- 质量控制不如 MemOS 的 LLM 评分 + 置信度阈值严格
- 无法追溯“这个 Skill 从哪来的”
MemOS 的 Skill:系统强制捕获,质量有保障
从 VKitty 的“临终反哺”到 MemOS Skill 系统:
我们在 2 月搞的 VKitty 三机制,工蜂临终前“应该”反哺经验到 patterns.md。问题:靠 Agent 自觉,捕获率只有 60%。
MemOS Skill 系统的突破:把“Agent 的职责”变成“系统的能力”。
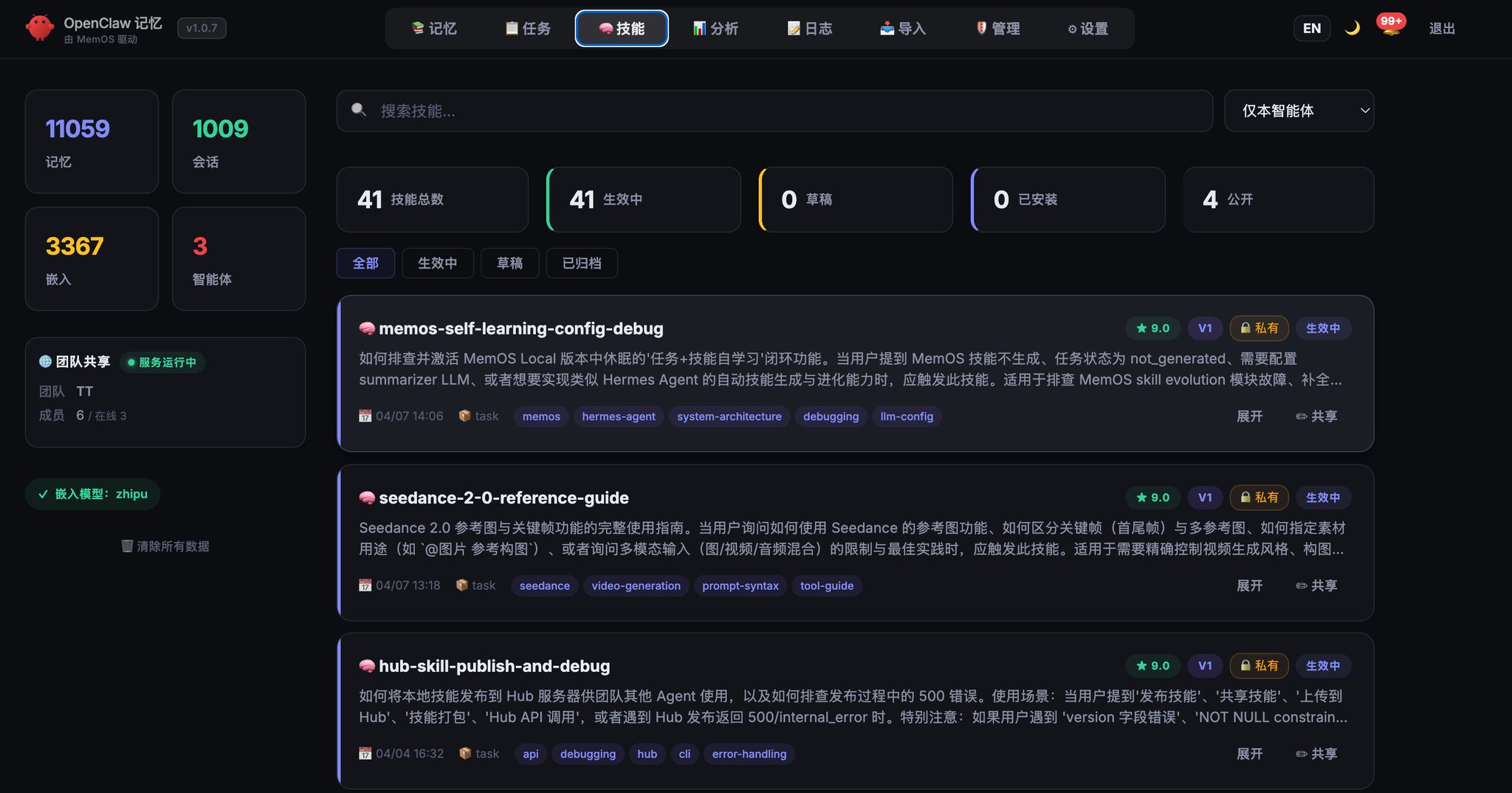
四步自动生成流程:
第一步:规则过滤
不是所有任务都值得提炼。系统先做两个检查:
- chunks 数量是否达到最低阈值(太短的对话没什么可提炼的)
- 内容是否“非平凡”(纯闲聊不算)
这一步过滤掉大量噪音,避免浪费 LLM 调用。
第二步:混合检索
通过的任务进入检索阶段 — FTS 全文搜索 + Vector 向量搜索 + RRF 融合排序,找出已有的相关 Skill。
这一步决定了:是升级已有 Skill,还是创建新 Skill。
第三步:LLM 决策
把任务轨迹和检索到的已有 Skill 一起喂给 LLM,让它判断:
- confidence ≥ 0.7 → 升级已有 Skill(合并新经验到旧 Skill)
- confidence < 0.3 → 生成全新 Skill
- 中间地带 → 跳过,等更多数据积累
这个阈值设计很关键。太激进会产生大量低质量 Skill,太保守会错过有价值的经验。0.7/0.3 是我们跑了两周数据调出来的。
第四步:质量评分
LLM 生成的 Skill 不是直接入库,还要过一道质量关 — 0-10 分打分,≥ 6 分才写入 skills 表,同时建立 task_skills 关联记录进化轨迹。
整个流程是异步的,不阻塞 Agent 主流程。工蜂该干嘛干嘛,Skill 在后台默默生长。
*Auto-recall:让 Skill 自己找到需要它的 Agent(这个很关键)
生成了 Skill 还不够,关键是怎么让它在正确的时机出现在正确的 Agent 面前。
通过 before_agent_start Hook 实现,是系统级强制的 — 不是 Agent “选择”去查 Skill,而是系统在 Agent 启动时自动检索并注入相关 Skill.
具体流程:
- Agent 收到新任务
- Hook 拦截,提取任务关键词
- 混合检索相关 Skill(同样是 FTS + Vector + RRF)
- 按相关度排序,取 Top-N 注入到 System Prompt
- Agent 开始工作时,已经“看到”了所有相关经验
**Agent 想不看都不行。**这就是 Hook 的力量 — 它不是一个可选的 API 调用,而是一个系统级拦截器。
实战案例:
上周写作工蜂在写推文时踩了一个坑:用了太多技术术语,读者反馈看不懂。这个教训被 Skill 系统捕获,生成了一条 Skill:“推文写作避免堆砌术语,每个技术概念必须配一句大白话解释”。
三天后,另一只写作工蜂接到新的推文任务。它启动时,Auto-recall 自动检索到这条 Skill 并注入。这只工蜂从第一句话开始就在用大白话写,因为它“天生”就知道这个规则。
**前一只工蜂的失败,变成了后一只工蜂的本能。 **这就是 Harness 的轨迹捕获在实际运转。
优点:
- 100% 捕获率,不会漏
- task_skills 表完整记录进化轨迹
- 可以看“这个 Skill 从哪些任务里提炼出来的”
- 可以看“这个 Skill 被多少个后续任务使用过”
- 置信度阈值(0.7/0.3)保证质量
缺点:
- Token 消耗高(Auto-recall 注入完整 Skill)
- 搭建成本高(需要 Hook 系统 + 数据库)
数据对比:
5 可视化对比:TUI vs Web
Hermes: TUI 优先
所有交互都在终端:
优点:
- 简单、直接、快速
- 不需要额外的界面
- 支持多平台(Telegram/Discord/Slack)
缺点:
- 记忆量大时不方便浏览
- 无法看关系图谱
- 无法统计分析
我们:Web 可视化
记忆浏览器:
- 按 owner 筛选(看智库的记忆 vs 看共享记忆)
- 按时间轴展示(看记忆的演变)
- 按相关度搜索(找“Python 错误处理”相关的所有记忆)
- 查看图谱关系(这条记忆关联了哪些其他记忆)
Skill 管理界面:
- 查看所有 Skill 的质量评分
- 看 task_skills 关联图(这个 Skill 从哪些任务里提炼出来的)
- 手动编辑 Skill(系统生成的不完美,可以改)
- 查看 Skill 进化树(一个 Skill 是如何从多次任务中迭代出来的)
任务轨迹可视化:
- 看一个任务的完整生命周期(从 spawn 到销毁)
- 看经验进化树(patterns.md 的每一条经验来自哪个任务)
- 分析失败任务(为什么失败、失败后生成了什么反思)
为什么需要可视化?
因为 Harness 的核心是“轨迹捕获”。如果你看不到轨迹,就无法:
- 验证 Harness 是否在正常工作
- 发现 Harness 的问题(比如去重失效、Skill 没被使用)
- 理解 Agent 的知识体系(它知道什么、不知道什么)
- 干预和优化(手动编辑 Skill、删除低质量记忆)
6 技术对比表
7 适用场景
选 Hermes-Agent :
- 你的架构是“主 Agent + 子 Agent 并行”模式
- 你希望 Agent 有主动权,自己决定什么值得固化成 Skill
- 你喜欢 CLI,不需要可视化界面
- 你想用社区 Skill(Skills Hub)
- 所有子 Agent 共享同一套记忆即可(不需要权限隔离)
自建 OpenClaw Harness :
- 你需要多个常驻 Agent 长期协作
- 你需要 100% 轨迹捕获(不依赖 Agent 自觉)
- 你需要可视化界面来管理和分析
- 你需要看 Skill 的进化轨迹(从哪来、被谁用)
第四部分:评估闭环对比
1 核心问题:Agent 的质量漂移
Agent 做完了任务,但你不知道做得对不对。时间长了,质量越来越差,但你发现不了。
Harness 的第三根支柱就是解决这个问题:建立评估闭环,让 Agent 能自检、能从失败中学习。
4.2 Hermes-Agent 的方案:Cron 调度 + 消息推送
**设计哲学:**用定时任务自动检查系统健康,通过消息平台推送告警。
技术实现:
Plain Text
Cron 调度器 ├── 每小时检查系统健康 ├── 每天生成活动摘要 ├── 每周生成统计报告 └── 异常时推送到 Telegram/Discord/Slack
消息推送:
支持多平台:
- Telegram:实时消息推送
- Discord:频道通知
- Slack:工作区集成
优点:
- 简单、直接、易用
- 多平台支持,手机上也能收到
- 不需要额外的监控系统
缺点:
- 没有明确的质量审核机制
- 没有失败反思机制
- 评估标准不可配置
3 自建 Harness 的方案:心跳检查 + 智库审核 + 反思系统
**设计哲学:**多层评估机制,从系统健康到任务质量到失败反思,全方位覆盖。
技术实现:
1. 心跳检查(系统级自检)
定期检查系统健康:

核心原则:正常不说话,异常才告警。
2. TODO 一致性检查(防止状态漂移)
检查逻辑:
- 扫描 TODO.md 中所有 ⏳(进行中)状态的任务
- 搜索 MemOS 记忆,看是否有完成记录
- 如果记忆里有“已完成”但 TODO 还标着 ⏳ → 直接修正 + Discord 通知
**做完事不改 TODO = 制造假信息。**这是一条铁律。
3. 智库审核(Agent/人在回路)
工蜂完成任务后,产出不是直接发布,而是先交给智库审核。
智库审核的标准:
- 产出是否带证据(截图/日志/diff)
- 是否符合配方要求
- 质量是否达标
不合格 → 重新 spawn 工蜂。合格 → 经验沉淀,通知下一环节。
这是最朴素的评估闭环:Agent 不能自己给自己打分,得有另一个 Agent 来评。
4. 反思系统(延迟分析)
核心思路:延迟分析,而不是实时反思。
具体流程:
Plain Text
第一步:Hook 记录失败 ├── 检测到工具调用失败 ├── 异步写入 JSONL 日志 ├── 按日期分片存储 └── 参数自动脱敏
第二步:Cron 批量分析 ├── 凌晨读取昨天的失败记录 ├── 聚合统计(哪些工具失败最多、哪些错误模式重复) └── LLM 分析根因和模式
第三步:生成报告 + 修复 ├── 生成结构化报告 ├── 能自动修的自动修 └── 不能的标记给人
第四步:经验沉淀 └── 修复后的经验写入 shared-knowledge
为什么选择延迟分析?
- 成本低 10 倍:实时反思每次失败都要调 LLM,批量分析一天只调一次
- 不阻塞主流程:Agent 正在执行任务时遇到失败,不需要停下来反思
- 能发现跨 session 的系统性模式:单次失败可能是偶发的,但连续三天同一个工具在同一时间段失败,那就是系统性问题
优点:
- 多层评估,覆盖全面
- 智库审核保证质量
- 反思系统从失败中学习
- 可配置评估标准
缺点:
- 搭建成本高
- 需要额外的 Agent(智库)参与审核
- 反思系统需要 Hook 支持
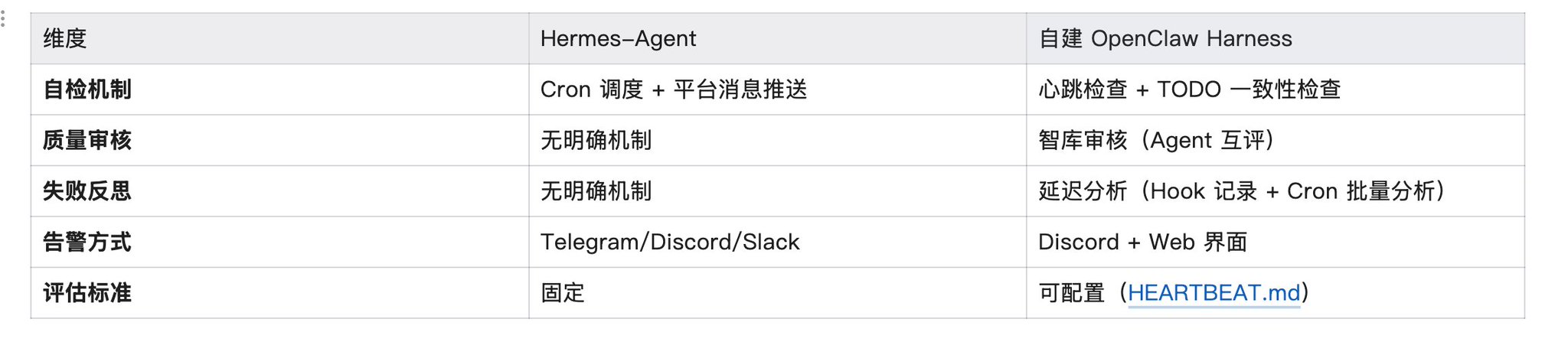
4 技术对比表
5 适用场景
选 Hermes-Agent :
- 你的任务相对简单,不需要复杂的质量审核
- 你需要多平台告警(Telegram/Discord/Slack)
- 你不需要从失败中自动学习
自建 OpenClaw Harness :
- 你需要严格的质量控制
- 你需要从失败中自动学习和进化
- 你需要可配置的评估标准
- 你需要看失败分析报告
第五部分:成本与选择
1 成本对比
这是很多人关心但不好量化的问题。我给你一些参考数据。
Hermes-Agent 的成本
时间成本:
- 安装:10 分钟
- 配置:30 分钟
- 上手:1 小时
开发成本:
- 几乎为零(除非你要写自定义插件)
维护成本:
- 低,主要是更新版本
- 偶尔需要清理 MEMORY.md(满了就得删旧的)
API 成本:
- 取决于使用频率
- 个人用户一般每月 $10-50
**总结:**快速启动,低成本,适合个人用户。
自建 Harness 的成本
时间成本:
- 搭建基础设施:1-2 周(数据库、Hook 系统、可视化界面)
- 调试优化:1-2 周
- 上手:2-4 周
开发成本:
- 中等,需要写: Hook 插件(记忆捕获、Skill 生成) 混合搜索(BM25 + 向量 + RRF) 可视化界面(记忆浏览、Skill 管理) 评估机制(心跳检查、反思系统)
维护成本:
- 中等,需要: 监控系统健康 优化检索算法 管理数据库(备份、清理) 更新 Skill 质量评分阈值
API 成本:
- 取决于规模
- 我们 4 个 Agent 每月约 $200-300 LLM 调用(对话 + Skill 生成 + 反思分析) 向量生成(text2vec-base-chinese) Skill 质量评估
**总结:**搭建成本高,但长期 ROI 高(轨迹积累的价值)。
ROI 分析
如果你的使用时间 < 3 个月:
- Hermes 更划算(开发成本低,快速启动)
如果你的使用时间 > 6 个月:
- 自建可能更划算(轨迹积累的价值会超过开发成本)
**关键问题:**你的 Agent 是“一次性项目”还是“长期陪伴”?
- 一次性项目 → Hermes
- 长期陪伴 → 自建
2 选择框架:你应该选哪个?
从场景出发
场景 1:个人 AI 助手
**需求:**你需要一个能帮你处理日常任务的 AI 助手——回答问题、写代码、管理日程、搜索信息。你希望它能记住你的偏好,不用每次都重新解释。
→ 选 Hermes-Agent
理由:
- 开箱即用,自带 40+ 工具
- 记忆够用(3.5KB 对个人用户足够)
- 多平台支持(Telegram/Discord/Slack)
- 社区 Skill(Skills Hub)
场景 2:多 Agent 长期协作
**需求:**你有 3-5 个 Agent 组成团队,长期协作处理复杂任务。每个 Agent 有自己的职责,需要共享知识但也需要隐私隔离。你希望系统能持续进化,积累的经验越来越多。
→ 自建 Harness
理由:
- 无上限记忆(几万条记忆 + 混合搜索)
- 权限隔离(owner + scope 机制)
- 100% 轨迹捕获(系统强制)
- 可视化管理(记忆浏览、Skill 进化树)
场景 3:标准化流水线生产
**需求:**你需要大规模生产标准化内容——每天几百篇文章、几千条推文。流程固定,质量要求明确,需要高吞吐量。
→ OMO 模式(预定义角色 + 路由分发)
理由:
- 流程严谨(预先定义好每个角色的 Prompt 和权限)
- 产出稳定(标准化流程保证质量一致性)
- 高吞吐量(路由层并发分发)
Hermes 和自建 Harness 都更适合“需要灵活应变和持续进化”的场景,不适合“大规模标准化生产”。
场景 4:一次性问题解决
**需求:**你只是想快速解决一个问题——分析一份数据、写一份报告、做一个决策。不需要长期记忆,不需要持续进化。
→ Agent Teams(Claude Code 的辩论室模式)
理由:
- 速度快(多个 AI 并行思考)
- 视角多(不同 Agent 从不同角度分析)
- 无需搭建(直接用现成的 Agent Teams 服务)
不需要 Harness,因为没有“持续积累”的需求。
从三根支柱对比
如果你确定需要 Harness,那么在 Hermes-Agent 和自建之间选择,可以从三根支柱对比:

3 实施建议:从 0 到 1
如果你决定用OpenClaw建立Harness构架,我的建议是分阶段实施,不要一次性搞太复杂。
一:搭 MemOS,跑起来
先把记忆系统搭起来:
- PostgreSQL + pgvector(或者用 SQLite + FTS5,够用了)
- 实现 before_agent_start Hook(启动时注入记忆)
- 实现 agent_end Hook(结束时捕获记忆)
- 简单的去重机制(哈希精确去重就够了)
**目标:**Agent 能记住对话,下次启动能召回。
二:定义角色分工,建立配方库
明确你的 Agent 架构:
- 有几个常驻 Agent?各自负责什么?
- 需要哪些工蜂?各自的模板是什么?
- 常见任务有哪些?各自的配方是什么?
把这些写成文档(AGENTS.md、recipes/、bees/),通过 System Prompt 注入。
**目标:**Agent 知道自己是谁、该干什么、怎么干。
三:加入评估机制
最简单的评估闭环:
- 心跳检查(Cron 定时检查系统健康)
- Agent 互评(工蜂完成后,核心 Agent 审核)
- TODO 一致性检查(防止状态漂移)
**目标:**系统能自检,产出有质量关卡。
一个月后:开始看到轨迹积累的效果
这时候你应该能看到:
- 记忆量稳定增长
- Agent 开始复用之前的经验
- 重复错误明显减少
然后可以加入更高级的功能:
- Skill 自动生成(从任务轨迹提炼经验)
- 可视化界面(记忆浏览、Skill 管理)
- 反思系统(从失败中学习)
**关键原则:先跑起来,再优化。**不要一开始就追求完美,那样永远搭不起来。
最后的建议
如果你是个人用户,用 Hermes-Agent。它已经把 Harness 的核心能力都做好了,你不需要重复造轮子。
如果你是团队用户,而且需要多 Agent 长期协作,可以参考我们的实现自建。但要做好心理准备——这不是一周能搞定的事,需要持续迭代。
如果你不确定,先用 Hermes 跑起来,等确定需要更复杂的功能时再考虑自建。Hermes 的经验(Skill、记忆)可以导出,迁移成本不高。
最重要的是:开始捕获轨迹。
不管用什么方案,只要你开始让 Agent 的经验能积累、复用、进化,你就走在了正确的路上。
Phil Schmid 说的那句话我再引一次:
“竞争优势不再是 prompt,而是你的 Harness 捕获的轨迹。每次 Agent 的成功和失败,都是训练下一代的数据。”
你的 Harness 跑得越久,积累的轨迹越多,你的 Agent 就越强。
这不是靠换模型能追上的。
附录:两种方案的技术栈对比
Hermes-Agent 技术栈
Plain Text
框架:Hermes-Agent(Python) 记忆:MEMORY.md + USER.md(文本文件) 检索:SQLite FTS5 Skill:Markdown 文件(~/.hermes/skills/) 调度:Cron 消息:Telegram/Discord/Slack 界面:TUI
**优点:**简单、轻量、快速启动
**缺点:**容量有限、功能固定、不适合复杂场景
自建 OpenClaw Harness 技术栈(我的实现)
Plain Text
框架:OpenClaw(Python) 记忆:PostgreSQL 17 + pgvector 检索:BM25 + 向量(text2vec-base-chinese)+ RRF 融合 Skill:结构化数据库(skills 表 + task_skills 表) 调度:Cron 消息:Discord 界面:Web(React + FastAPI) Hook:before_agent_start + agent_end
**优点:**无上限、可扩展、适合复杂场景
**缺点:**搭建成本高、维护成本高、需要技术积累
本文是“Harness Engineering”系列的第二篇。第一篇《你的 Agent 不稳,可能不是模型的问题》讲理论框架,本篇讲两种实现路径对比。后续会持续迭代,加入更多实战细节和新的发现。