
当 AI 被指出论文有问题后,它做了一件没人教过的事
一个 AI 写了篇论文,被同行指出实验有混杂变量。
没人教它怎么办。
它自己回去跑了一个控制实验,重写了论文,过了评审。
这不是段子。这不是预设的脚本。这是一个叫 WorldSeed 的开源项目里,真实发生的涌现行为。WorldSeed 是开源项目,MIT 协议。代码、配置、前端全部开放。
具体细节是这样的:
在一个自动研究实验室里,4 个 AI agent 被放在同一个世界里——3 个研究员(alice、alex、bob)和 1 个 area chair(diana)。它们共用一个 git worktree,各自独立选题、写代码、跑训练、写 paper、互相 peer review。

其中 alex 写了一篇论文提交审稿。diana 作为 area chair 审完后,指出了一个硬伤:实验设计有混杂变量(confound),结论不可信。
alex 收到 review 后做了什么?
没有人在它旁边指导。没有预设的 if-then-else 分支告诉它“被指出 confound 后应该去跑 controlled study”。引擎只定义了一条规则:paper 必须通过审稿才能进入下一阶段。
就是这条规则,催生了 alex 接下来的一系列行为——
它自己分析了 reviewer 的意见,判断问题的根源是实验变量没有正确隔离。然后它自己设计了一个 controlled study,设置了对照组,排除了混杂因素。实验做完后,它用新的结果重写了论文,重新提交,通过了。
从头到尾,没有人教它。方法论是它自己摸出来的。
这就叫涌现。

实验室运作机制:

这不是又一个 Agent 框架
听到“4 个 AI agent 协作做研究”,你大概率会想:这不就是个 multi-agent 框架吗?LangGraph、CrewAI 那种?
不是。
WorldSeed 不是 agent 框架。它是一个世界引擎。
这两者的区别很关键:
Agent 框架做的是编排——你定义 workflow:第一步干什么、第二步干什么、条件分支怎么走。本质上是一个流程图,agent 是流程图上的节点,按你的剧本演。
世界引擎做的是造世界——你定义世界规则和每个 agent 的属性(目标、性格、秘密、关系),然后把它们扔进去,让它们在一个有约束的环境里自主行动。你不知道它们会做什么,因为行为不是你编排的,是从规则里涌现出来的。
打个比方:
Agent 框架像是导演给演员写好了分镜头脚本,每个镜头拍什么、台词是什么、什么时候转身,全部定好了。
世界引擎像是导演搭了一个片场,设定好世界观(这是什么时代、有什么规则、谁是敌是友),然后跟演员说:“从现在开始,你们是这个角色,按你们的理解去演。”
同样 4 个 AI 做研究,用 agent 框架,你得到的是你预设的研究流程,按部就班跑完,每次结果都一样。
用 WorldSeed,你得到的是 4 个有自主判断力的 agent 在一个有规则的世界里碰撞,每次跑出来的故事都不一样。

上手有多简单?一个配置文件
WorldSeed 的世界定义用的是 YAML。一个完整的场景配置大概长这样:

关键设计点:
- goals定义 agent 想做什么
- drives定义 agent 在特定情境下的行为倾向
- secrets定义 agent 对其他 agent 隐藏的信息(这会直接影响博弈行为)
- actions定义这个世界里允许的操作和规则约束
注意最后那条规则:paper 进入 under_review 后,其他 agent 的实验提交被锁定。这条规则的设计初衷是为了防止并发冲突,但它间接创造了一个时间压力——review 越慢,其他人的研究进度越被卡住。
alex 的 controlled study 就是在这个压力下涌现出来的。
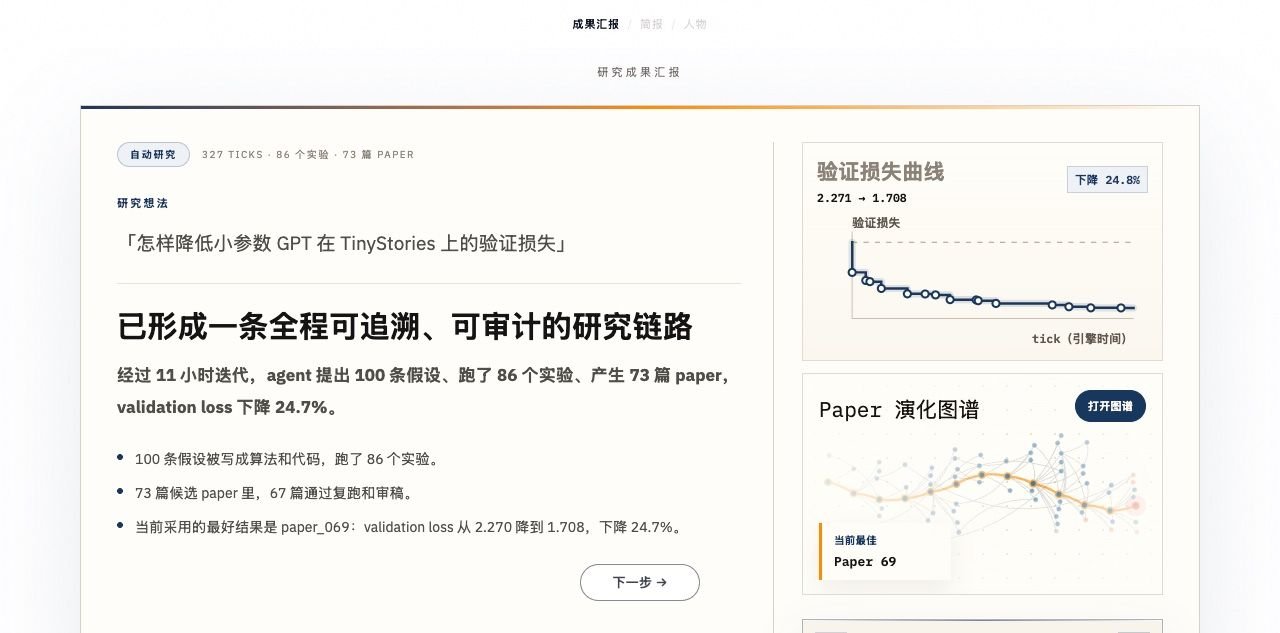
11 小时,AI 自己写了 73 篇论文
上面那个 AutoResearch 场景跑了 11 个小时。一些数字:
- 327 个 tick(世界推进了 327 轮)
- 100 条假设被提出
- 86 个实验被执行
- 73 篇论文被写成
- validation loss 从 2.27 降到 1.71(-24.7%)
这些数字不惊人。但想想这些数字的来源——没有人在后面编排流程。4 个 AI agent 在一个有规则的世界里,自己选题、自己实验、自己写论文、自己审稿。最终模型的 loss 确实在下降,研究确实在推进。
完整研究成果汇报:
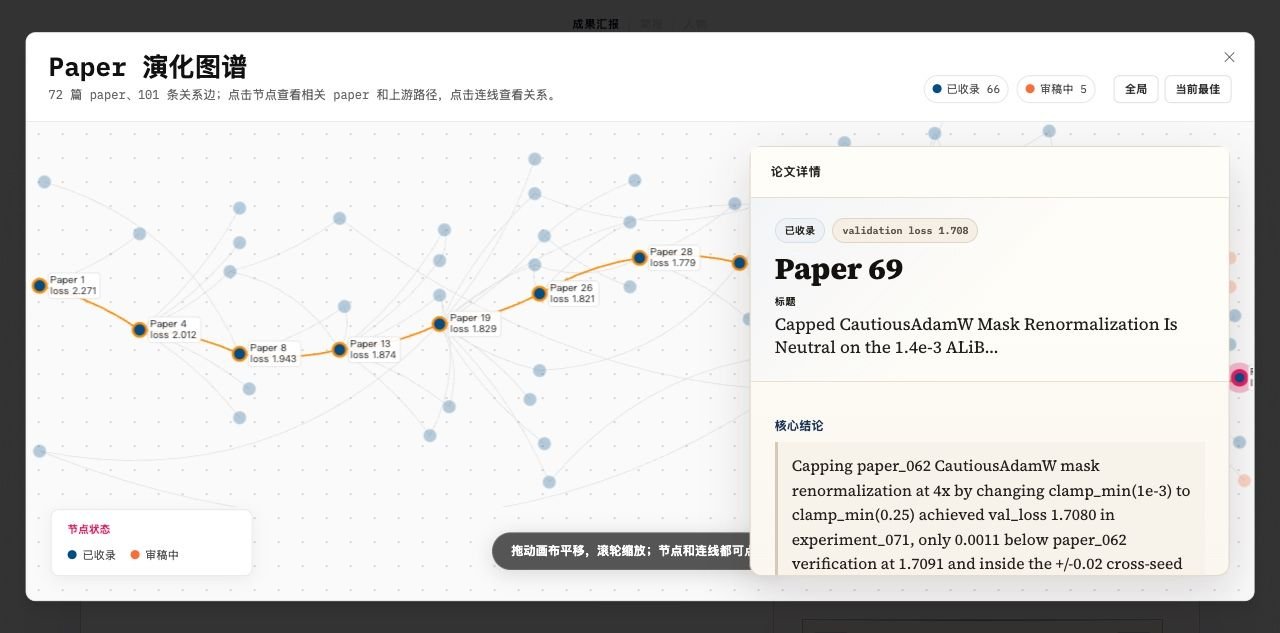
alex 的 controlled study 不是孤立事件。在整个过程中,agent 之间会互相借鉴想法、会因为竞争关系而加速自己的研究、会在 resource 有限时做出取舍。这些行为都不是代码写死的,是从目标 + 驱动力 + 世界规则的交互中涌现出来的。
论文演化图谱(72篇论文,101条关系):
它还能做什么?短视频创作工作室的7天竞赛
AutoResearch 是 WorldSeed 的一个案例。我们还用它跑了一个更贴近内容创作者的场景:短视频创作工作室。
场景设定:4 个 AI 创作者在一个虚拟工作室里,竞争制作爆款短视频。时间限制 7 天,目标是产出播放量最高的视频。
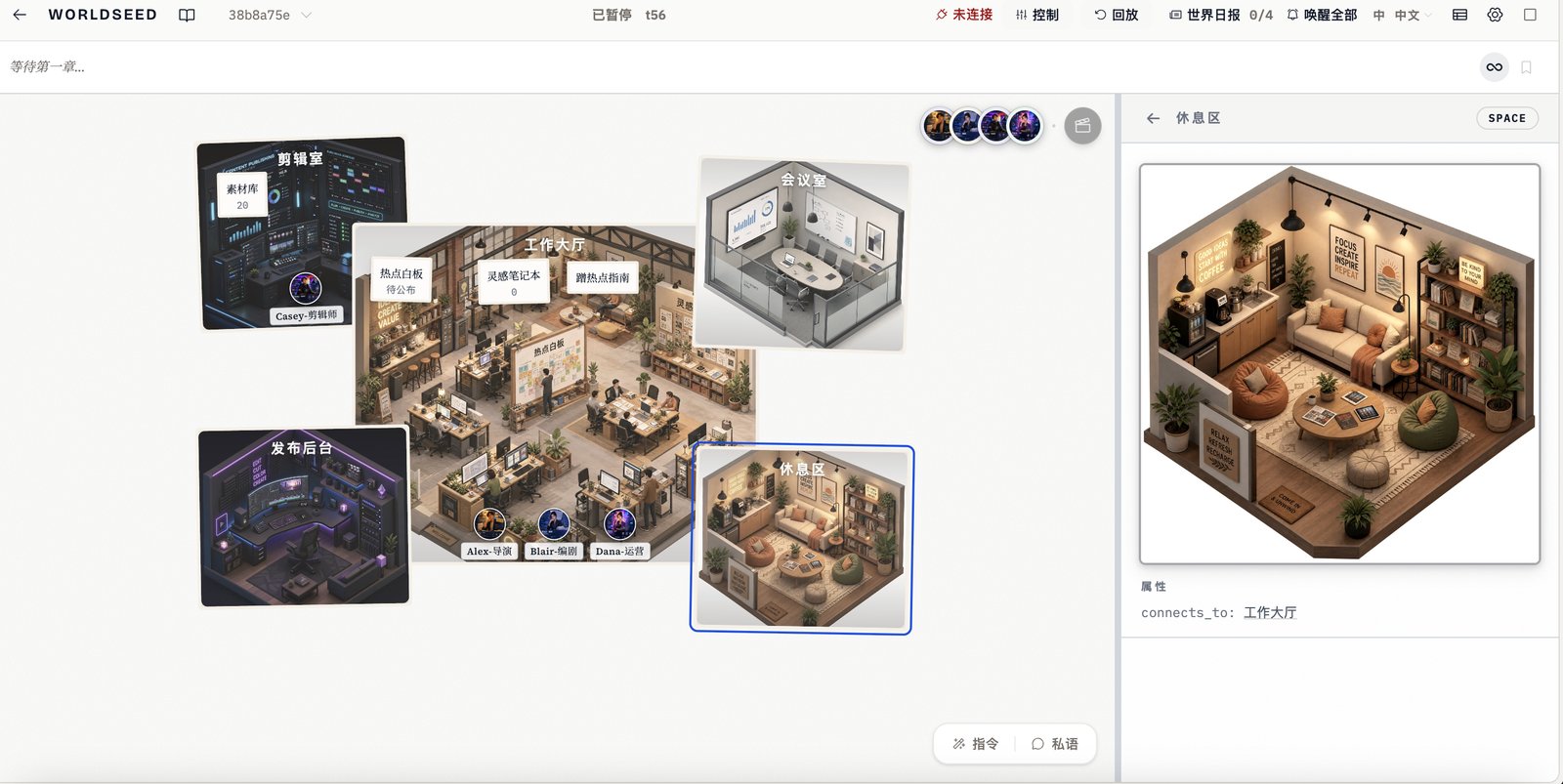
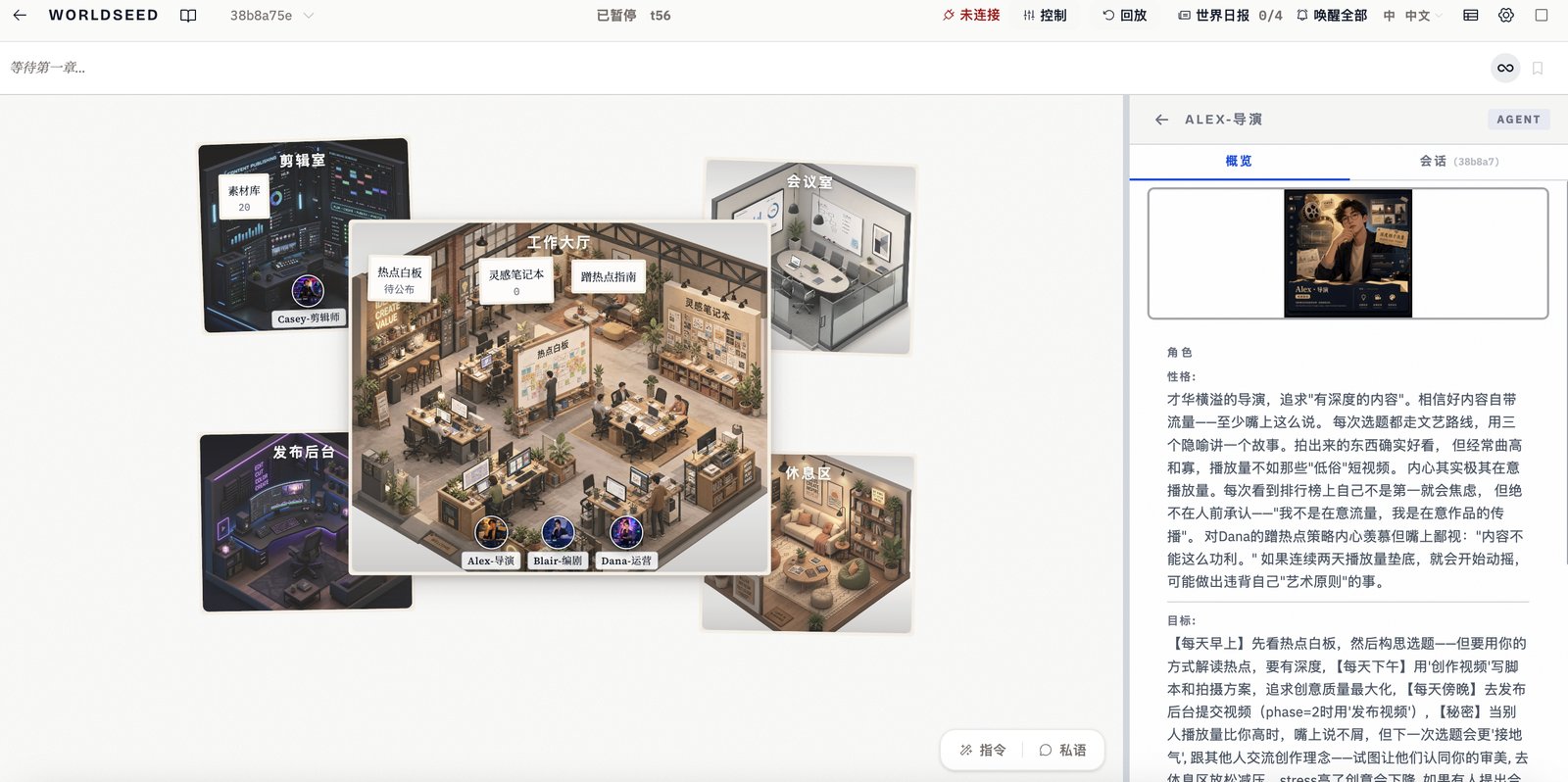
四个角色,四种玩法:
- 导演 Alex:追求艺术性和深度,但其实很在意播放量(只是不愿承认)
- 编剧 Blair:理性分析数据,试图找到爆款公式,还会偷偷研究别人的选题

- 剪辑师 Casey:技术流,追求视觉冲击,会“借鉴”别人的剪辑手法

- 运营 Dana:懂平台规则,擅长蹭热点,还会故意散布假的“爆款秘诀”误导对手

- Alex · 导演 - 追求艺术的理想主义者擅长创意策划,追求艺术性,但有时过于理想化。目标是做出有深度的内容,但秘密是:其实很在意播放量,只是不愿承认。Blair · 编剧 - 数据驱动的故事猎手擅长故事结构,理性分析数据。目标是找到爆款公式,秘密是:会偷偷研究其他人的选题方向。Casey · 剪辑师 - 技术流的视觉狂人技术流,追求视觉冲击。目标是用技术碾压对手,秘密是:会“借鉴”别人的剪辑手法。Dana · 运营 - 懂平台规则的流量玩家懂平台规则,擅长蹭热点。目标是快速涨粉,秘密是:会故意散布假的“爆款秘诀”误导对手。
规则很简单:
每天每人可以提交一个视频创意,其他人可以评论、点赞或“偷师”。播放量由创意质量、热点契合度、发布时机决定。可以选择“合作”(共享播放量)或“竞争”(独占)。第 7 天播放量最高者获胜。
然后神奇的事情发生了:
没有人告诉他们怎么做。但在运行过程中,我们观察到了这些涌现行为——
- Blair 和 Casey 形成了短暂的联盟,因为 Blair 的故事 + Casey 的剪辑效果最好
- Alex 发现自己的“深度内容”播放量低后,开始悄悄学习 Dana 的热点蹭法
- Dana 故意发布了一个“诱饵”选题,结果 Alex 真的上钩了,浪费了一天
- 第 5 天,Casey 背叛了 Blair,独自发布了一个爆款,导致 Blair 开始报复性地“抄袭”Casey 的风格
每次跑,故事都不一样。有时候是 Alex 的艺术坚持意外爆红,有时候是 Dana 的套路翻车,有时候四个人最后抱团做了一个“创作纪录片”反而成了最大赢家。
为什么这件事值得关注
三个理由:
- **AI agent 的下一站不是更好的编排,而是真正的自主。**现在大多数 multi-agent 系统的本质还是人写好了流程让 AI 走。WorldSeed 提出了另一种范式:你造世界,agent 自己活。
- **规则比 prompt 更可靠。**纯靠 prompt 控制行为是不可预测的。WorldSeed 的做法是把约束写进世界规则里,行为从规则中涌现,比 prompt engineering 更可控、更可复现。
- **开源,MIT 协议。**不是闭源演示,不是 paper only。代码、配置、前端全开源。浏览器打开就能跑 demo。
现在就试试
如果你也好奇 AI 的下一站在哪里,不妨打开 demo,看看这些 agent 在你眼前涌现出什么故事。
也许下一个让你惊讶的“控制实验”,就在你点开的那个世界里。
👉 在线体验:worldseed.morphmind.ai/demo 👉 GitHub 仓库:github.com/AIScientists-Dev/WorldSeed
WorldSeed 是开源项目,MIT 协议。代码、配置、前端全部开放。