
5.9 万人围观:我用 AI 克隆了峰哥的实时对话(含技术拆解)
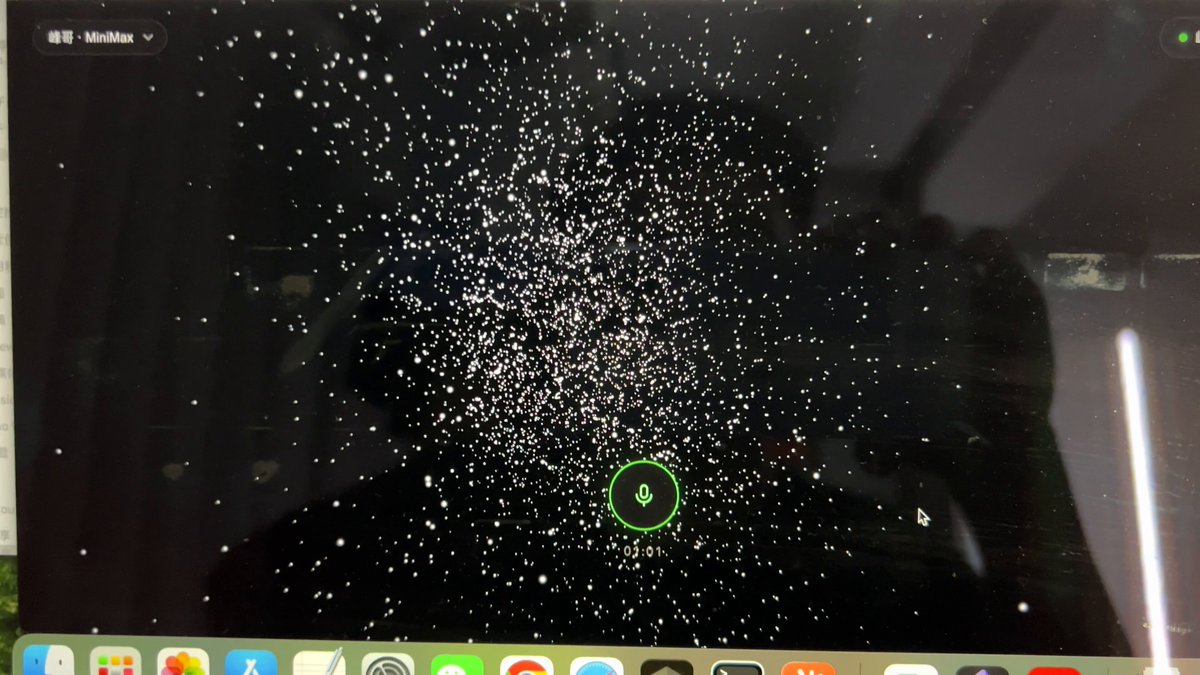
两天前我发了一条 demo 视频,是一个 AI 用峰哥(峰哥亡命天涯)的声音和性格跟我实时聊天。
不是文字转语音——是像打电话一样,你说一句它接一句,声音是峰哥的,说话风格也是峰哥的。
5.9 万人围观,很多人问怎么做的。
这篇把整个过程拆开。github开源地址放结尾了。
Leaf Yeah! (@leaf_sanren)> ٩(•̤̀ᵕ•̤́๑)ᵒᵏᵎᵎᵎᵎ 我克隆了网红【峰哥亡命天涯】的声音和记忆,让 AI 用他的方式跟我实时对话。
第一次听到"峰哥"的声音从电脑里怼我,愣了几秒。。
像跟直播连麦一样。这个项目我叫它 Talk to Me,从 V1 到 V3.6 迭代了好几轮。它干的事:你说话,AI
起点:不是想做产品,是寂寞
一开始只是想有个东西能跟我说话。不是客服机器人,是带着我的记忆、用我习惯的语气跟我聊天。
我跟 Codex 说:帮我做一个能跟我实时语音对话的 AI Agent。
它给我搭了一套很"完整"的架构——语音模块、记忆模块、对话模块各自独立,配置面板管理后台全齐。
核心功能,一个都没跑通。说话没声音,界面又矮又丑,bug 叠 bug。
自己动手拼
Codex 做不出来,我开始自己找开源项目拼底层:
解决什么问题用了什么浏览器和 AI 之间实时传音频LiveKit(19K ⭐)把一个人的说话风格蒸馏给 AI女娲 Skill(25K ⭐)让 AI 记住聊过什么OpenViking(26K ⭐)用 15-45 秒语音克隆任何人的声音MOSS-TTS(3.7K ⭐)
四个项目一个一个接进去。每接一个都有新的兼容性问题,每解决一个又冒出下一个。
但终于有一天——
我说话了,AI 回我了。
第一次听到回声的时候是真的激动。之前折腾那么久连声音都没有,这次终于像个能对话的东西了。
走的是 Gemini Live 的原生语音方案,延迟大概 2 秒。它记得我之前说的事,说话语气也对。
但声音不是我的。Gemini Live 的声音是固定的。GPT-4o Voice 也一样。截至目前,还没有出圈的方案能同时做到"实时对话 + 任意音色克隆"。
想克隆声音,只有一条路——把语音链路拆开:
你说话
→ 语音识别 / STT(听懂你说什么)
→ 大语言模型 / LLM(想怎么回你)
→ 语音合成 / TTS(用克隆的声音说出来)
三步分开做,最后一步换成支持克隆的模型。
听起来简单。实际上意味着整个架构推翻重来。
延迟地狱:每句话等 8-20 秒
架构拆开了,链路跑通了。
一测延迟——每说一句话,要等 8 到 20 秒才听到回复。每一句都是。你说"你好"等 15 秒,它回完,你接一句"最近怎么样",再等 15 秒。这不是对话,这是发语音邮件。
Agent 跟我说:语音链路拆成三步本来就慢,这是行业常见水平。
我不信。把整条链路拆开,一个环节一个环节计时:
🔴语音合成(TTS)——最大瓶颈MOSS-TTS 在本地 CPU 上跑音色克隆,一句话 14-40 秒。光这一步就把整条链路拖死了。
→ 换方案:充了 Cartesia Pro 会员($5/月)做音色克隆,合成速度从十几秒降到毫秒级。
🟡记忆系统——偷偷拖后腿每轮对话都实时搜索记忆库,搜一次好几秒。
→ 改成启动时一次性加载 800 字快照,塞进 AI 的指令里。28 毫秒加载完,之后每轮零等待。
🟡语音识别(STT)——做无用功把没说话时的环境噪音也送去识别——空调声被听成"中国""是的",AI 还很认真地回复。
→ 换专用识别模型 Cartesia ink-whisper,只处理真正在说话的部分。
🟢大语言模型(LLM)——三家赛马- MiniMax M2.7-highspeed(国产,不需要翻墙)——首字 361ms ✅ 胜出
- DeepSeek chat——备选
- Gemini 3.5 Flash——备选
一个通宵。端到端从 8-20 秒压到了工程链路 1 秒以内。
实际体感受网络和 API 响应影响,约 2-3 秒——但已经从"语音邮件"变成了"打电话"。
克隆峰哥:质量又翻车
延迟解决了。自己的声音克隆也跑通了——用 Cartesia 做的,效果还行。
但我想做更有传播力的 demo。克隆自己的声音别人没对比感,于是选了峰哥——B 站百万粉博主,声音辨识度极高。
用 Cartesia 克隆了三个版本的峰哥声音,反复调参。
中文克隆效果就是不行。Cartesia 是英语优先的商用模型,中文克隆是附带功能,达不到"一听就知道是峰哥"的程度。
最后换了 VoxCPM(31K ⭐ 开源中文音色克隆),效果终于对了。代价是需要 GPU——租了云 GPU 服务器通过网络隧道接回 Mac。
云 GPU 又是一堆坑:关机重开环境被重置、装好的东西全丢、SSH 隧道断连。写了自动恢复脚本才稳住。
声音克隆只是一半。让 AI 不只声音像,说话方式也像,才是让人觉得"这真的是他"的关键——辩证反转、口头禅、黑话、荒诞类比。这部分用女娲 Skill 的蒸馏方法论,从峰哥的直播转文字和开源人格数据里提取,素材越丰富效果越好。
做完了,不好意思发
做到能用峰哥的声音和性格实时聊天,我反而犹豫了。
开发差不多两周,就做出这么个东西。前端是个星空粒子页面,没有数字人,没有精美 UI。
觉得太简陋了,不好意思发。
推友催我:发啊,怕什么。
我发了。
5.9 万人围观。---
所以
一开始是一个人寂寞,想跟 AI 聊天。
中间是跟延迟搏斗、跟克隆质量搏斗、跟云服务器搏斗。
最后是做完了觉得太简陋不好意思发——发出去发现大家真的感兴趣。
代码全部开源了。如果你也想做一个能用任何人声音聊天的 AI:
⭐github.com/YeJe-cpu/talk-to-fengge
clone 下来,扔给任何 AI 编程助手(Claude Code、Cursor 都行),告诉它"帮我配置并启动这个项目"。
峰哥是内置的完整示例。想换成其他人?准备 15-45 秒声音素材,让 AI 助手参考峰哥的配置生成新人格就行。
有问题来 Issues 聊 · 想交流来找我 @leaf_sanren · uncleleaf.cc