
GPT-5.5 发布:这次 OpenAI 真的把桌子掀了一下

GPT-5.5 发布了。
我看完 Every 团队连续 3 周的实测,又把文章和视频都过了一遍,最强烈的感受是:
这不是一次普通升级。 这是 OpenAI 久违地做出了一款,让人很想立刻切过去当主力的模型。
过去一年,很多人已经默认形成了分工:
写作找 Claude。
复杂规划找 Claude。
长任务和 coding 也更偏向 Claude。
OpenAI 更像一个“通用入口”,好用,但很少让人产生那种“我想长期住进去”的感觉。
GPT-5.5 这次,把这种印象狠狠干扰了一下。
一句话结论
如果只用一句话概括 GPT-5.5,我会这么说:
它终于同时具备了三件很稀缺的事:够强、够顺手、够像一个真的能长期协作的工作伙伴。
强模型很多。
顺手的模型也有。
但“又强又顺手”,还覆盖 coding、写作、知识工作,这种组合其实非常少见。
Every 给它的判断:
它是一个 coding powerhouse,同时又 fast、friendly、easy to talk to。
翻译成人话就是:
它不只是厉害。
它还让人愿意一直用。
编程能力,这次真的有“坐直身子”的感觉
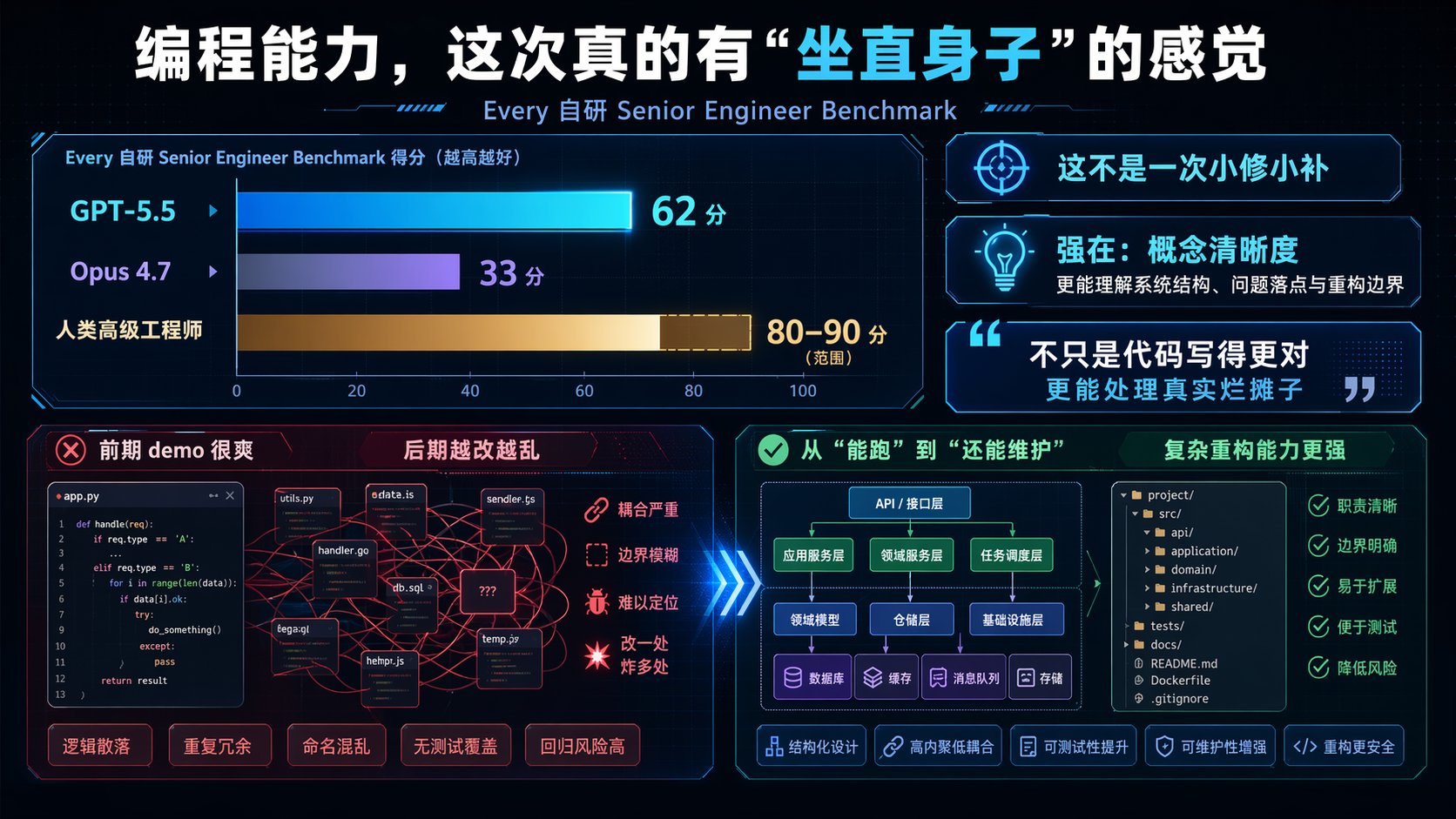
Every 自研了一个 Senior Engineer Benchmark,用来测模型到底能不能像一个高级工程师一样处理复杂代码任务。
结果很扎眼:
- GPT-5.5:**62 分
- Opus 4.7:33 分
- 人类高级工程师参考区间:80-90 分
先说清楚,benchmark 从来都不该神化。
但这个差距已经足够说明,这不是一次小修小补。
更重要的是,GPT-5.5 这次强的点,不只是“代码写得更对”。
它强在一种很少见的东西:
概念清晰度。
也就是它更能抓住一个系统到底是怎么运转的,哪里真的坏了,改动应该落在哪里,哪些旧代码该留,哪些旧代码该删,什么时候该继续修,什么时候该直接重构。
这点特别重要。
因为很多 AI coding 项目,真正痛苦的阶段都不是从 0 到 1。
而是从“能跑”走到“还能继续维护”。
前面做 demo 很爽。
后面越改越乱。
功能补得越来越多,代码却越来越不敢动。
修一个 bug,顺手再炸出三个 bug。
这是现在大量 vibe coding 项目的真实处境。
GPT-5.5 最让人兴奋的地方,就是它开始有能力处理这种真实烂摊子了。
它更像一个“会判断”的工程师
Every 团队里,Naveen Naidu 在测试期间用了超过 9 亿 token,持续拿 GPT-5.5 去推 Monologue 的生产功能。
这个数字很夸张。
但更夸张的是他给出的体感:
GPT-5.5 真的能理解一个系统。
这句话的分量,比任何单次跑分都重。
因为真正有价值的模型,不只是会补全代码。
它要能理解:
- 这个系统为什么变成现在这样
- 问题是表层的还是结构性的
- 修这一处会不会牵动别的模块
- 这块到底该 patch,还是该推倒重来
当一个模型开始具备这种能力,它就不再只是“代码生成器”。
它开始有一点“高级工程师味道”了。
写作能力,OpenAI 终于有点回来了
这部分其实让我很意外。
Every 的写作者 Katie Parrott 提到,她大概已经一年没有把 OpenAI 的模型放进正式写作工作流了。
测完 GPT-5.5,她切回来了。
它终于变得更自然了。
- 结构清晰
- 推进更顺
- 模仿风格更有分寸
不会一开口就写出那种“过于标准、过于正确、过于像 AI”的文本。
这个变化,对内容创作者非常关键。
很多模型写作的问题,从来都不是“不会写”。
而是写得太整齐,太用力,太像机器在拼一个完美答案。
GPT-5.5 如果真能把这种“AI 味”压下去,它会非常适合进入内容工作流:
- 热点整理
- 长文初稿
- 风格改写
- 多平台分发
- 历史内容再利用
- 知识库内容再加工
这对长期做内容的人,意义很大。

它没有明显变慢
这件事其实比很多人想象中更重要。
因为很多“更强”的模型,代价都是更慢。
更慢意味着什么?
意味着更不适合高频工作。
意味着来回沟通的成本变高。
意味着它可能适合关键时刻,不适合整天挂着用。
GPT-5.5 这次最危险的地方就在这里:
它很强,但又没有强到让人用得很累。
OpenAI 官方也强调,它在多项真实任务 benchmark 上表现很猛,同时保持了更高的效率。
Every 的体感也是:它快,而且足够快,快到可以进入真正的日常工作。
这种模型,才有资格争“主力位”。
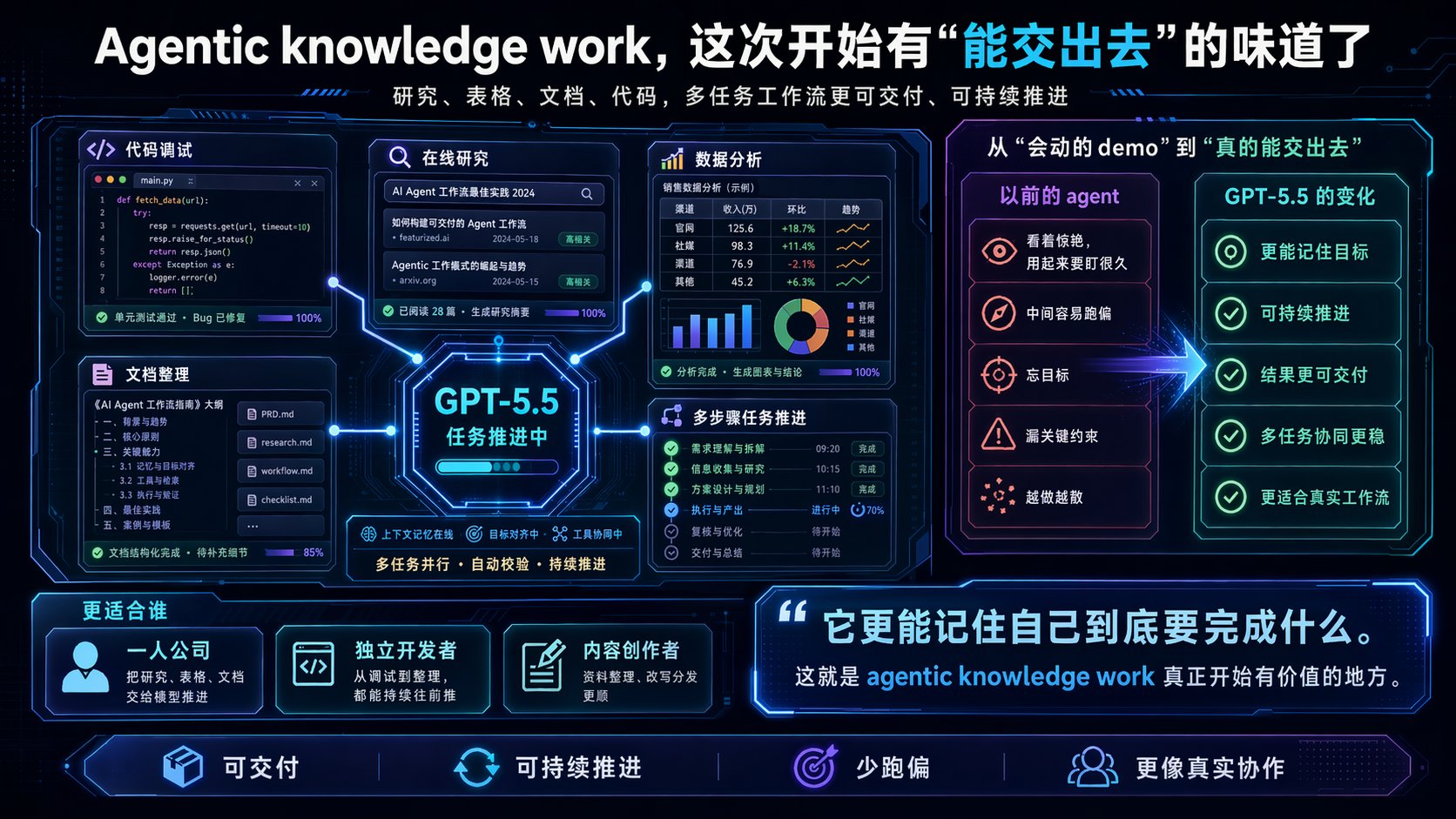
Agentic knowledge work,这次开始有“能交出去”的味道了
Every 对 GPT-5.5 的另一个评价,中文圈应该挺喜欢的:
这是他们第一次感觉,一个 OpenAI 模型真的能扛起很多 agentic knowledge work。
- 代码调试
- 在线研究
- 数据分析
- 文档整理
- 多步骤任务推进
以前的 agent,很多时候更像“会动的 demo”。
看着很惊艳,用起来要盯很久。
中间容易跑偏,忘目标,漏关键约束,或者越做越散。
GPT-5.5 这次给人的感觉是:
它更能记住自己到底要完成什么。
这点对于一人公司、独立开发者、内容创作者,价值很高。
但它还没有赢下所有地方
越是这种看起来很强的发布,越要把弱点写清楚。
Every 的结论也很坦诚。
GPT-5.5 还输在几个地方:
1. 规划质量仍然不如 Opus 4.7 GPT-5.5 的 plan 更清楚、更易读,但 Opus 的细节、洞察和判断还是更锐。
2. 前端和全栈产品思维还是 Opus 更稳 尤其涉及设计感、用户路径、产品结构时,Opus 依然很有优势。
3. 对模糊需求的“读空气能力”还没完全赢 如果任务很虚,只给一句 vague prompt,Opus 还是更会补全你没说出口的东西。
4. 写 Ruby 不是它的强项 这点对 Rails 用户要单独留意。
也就是说,GPT-5.5 非常强,但还没强到“一统天下”。
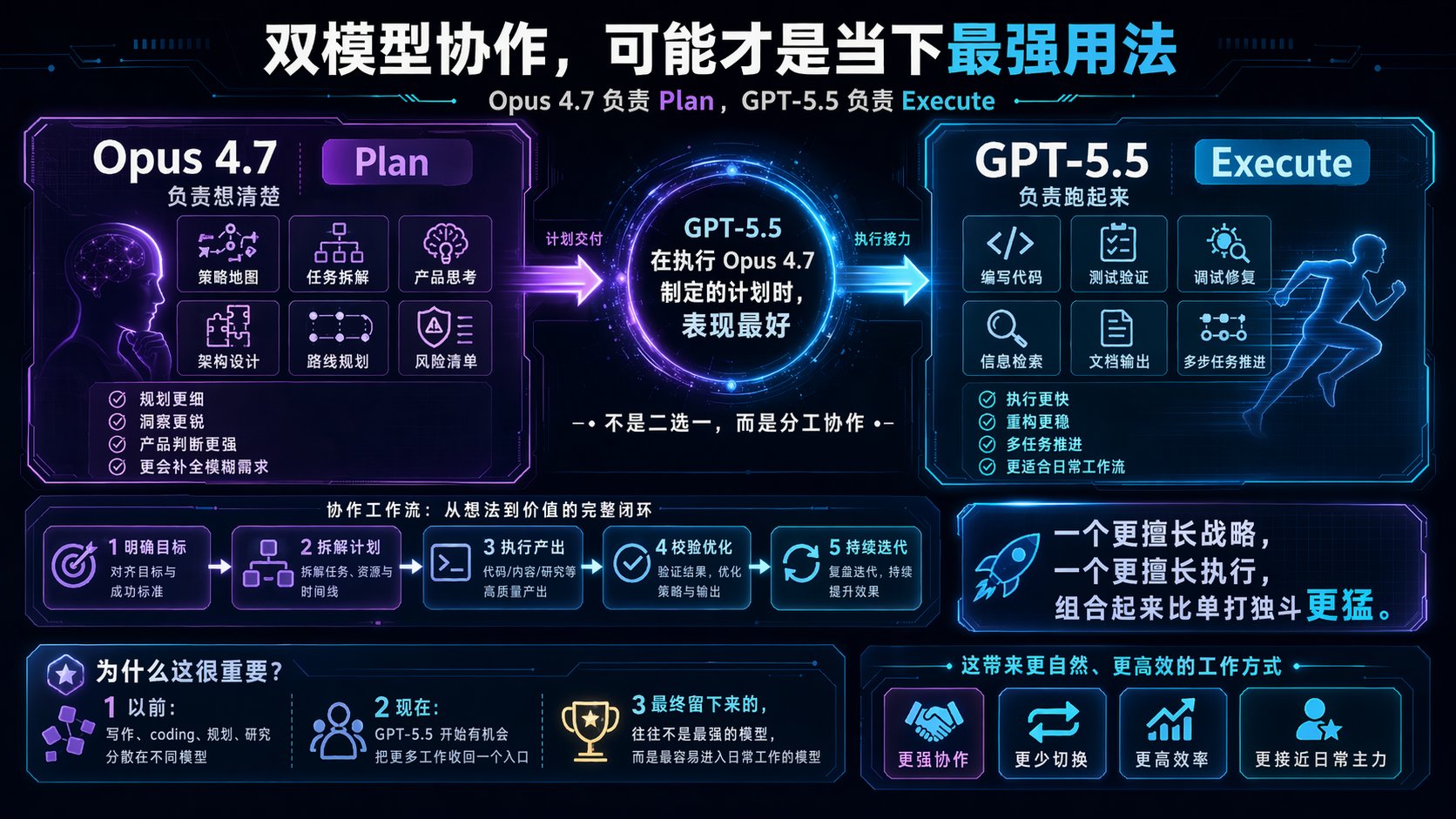
最有意思的结论,可能是这句
Every 测出来一个特别值得记下来的现象:
GPT-5.5 在执行 Opus 4.7 制定的计划时,表现反而是最好的。
它说明接下来很多人的最佳实践,可能不是“二选一”。
Opus 负责想清楚。 GPT-5.5 负责跑起来。
这很像真实团队协作。
一个人战略感更强。
一个人执行效率更高。
组合起来,反而比单打独斗更猛。
我觉得这才是这次 GPT-5.5 发布后,最值得普通用户抄走的用法。
OpenAI 重新开始认真争夺默认工作入口了。
以前大家会习惯把不同任务拆给不同模型。
写作一个,coding 一个,计划一个,研究一个。
GPT-5.5 开始有机会把这些工作重新收回来,放进一个更统一的入口里。
这件事如果成立,影响会很大。
因为大家最终留下来的,不一定是最强的模型。
往往是那个最容易进入日常工作的模型。