
Loop Engineering是第四层塔——Loop 、 Prompt、Context、Harness不是四个时代,是同一个系统
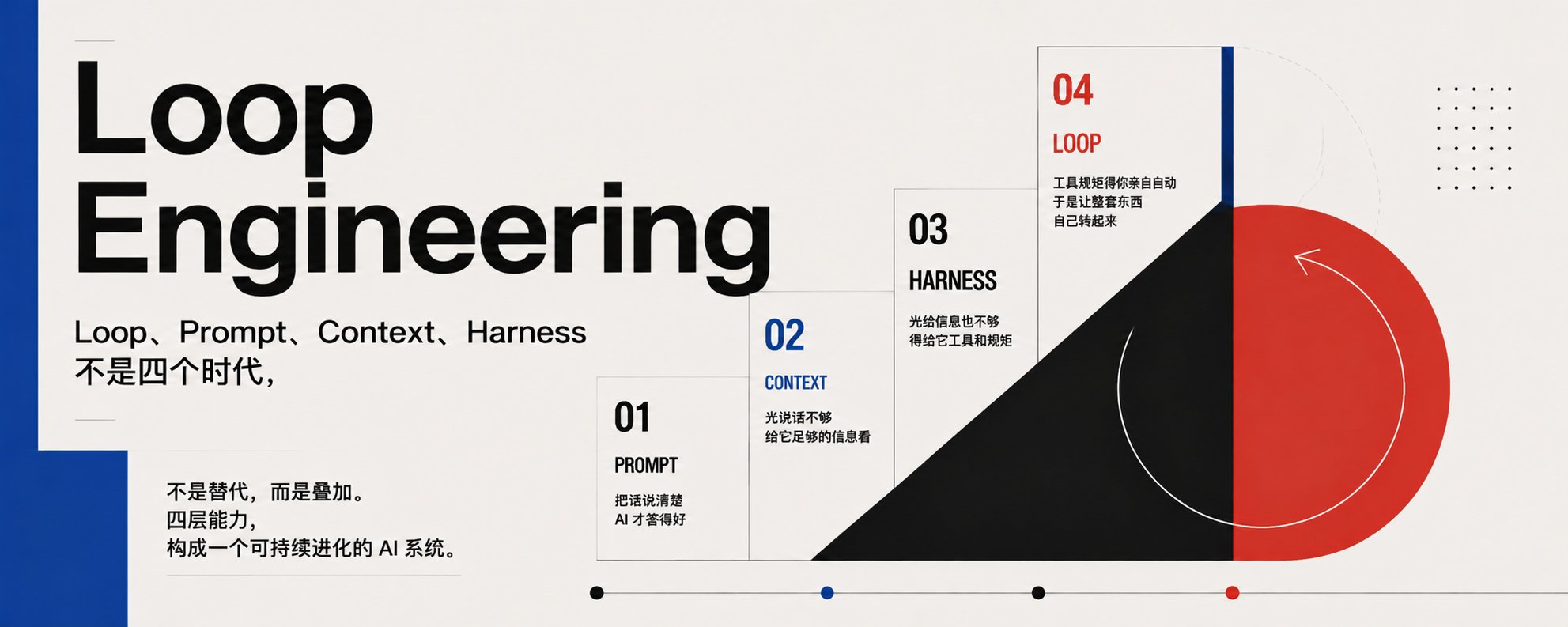
这两周 Loop Engineering 刷屏,大致意思是《Prompt 已死,Loop 当立》。但细细读完这些文章,你会发现根本讲的不是替代——Loop Engineering、 Prompt、Context、Harness就是同一个系统的四层。真正发生的事不是替代,是这座塔盖到了第四层。- Prompt——把话说清楚,AI 才答得好
- Context——光说话不够,给它足够的信息看
- Harness——光给信息也不够,得给它工具和规矩
- Loop——工具规矩得你亲自启动,于是让整套东西自己转起来。
- Prompt 是对话能力,Context 是知识储备,Harness 是行动边界,Loop 是让它自己转起来的自动机制。往外盖一层,里面那几层不但没消失,反而成了新一层能立住的地基。Loop 想跑得稳,靠的恰恰是底下 Prompt 说得清、Context 给得对、Harness 管得住。Prompt 没被 Context 取代,Harness 也没让前两层作废——四层是叠上去的,不是换下来的。---
一、Loop 到底是什么
举个对比就清楚了。
普通用法是:你说"帮我修一下这个报错",它改一版,你跑测试,挂了你再贴日志,来回拉锯。
Loop 的用法是:你定好"每天早上检查有没有报错,有就修,修完跑测试,过了就提交、通知我,连续两轮修不好就停下来找我"——然后这套流程自己每天跑,你只在它真搞不定时才出面。你从"写每一轮提示的人",变成了"设计这套提示规则的人"。这里有两个最容易被搞混的点。
第一,提示词没有死,它只是换了位置。以前你的提示词就是整段对话;现在你的提示词是写给这个循环的规矩——告诉它什么算合格、什么算失败、失败了怎么办。表达能力一点没贬值,反而更重要了,因为你写的不再是一句话,是一套要自动跑很多遍的规则。
第二,有重复动作,不等于有 Loop。假设你让 AI 把 100 个文件每个都生成一段摘要,这看着也在"循环",但它只是批处理——第一篇写得好不好,根本不影响第二篇怎么写。真正的 Loop,上一轮的结果会决定下一轮干什么:重做、调整、跳过,还是停。没有这个"根据结果调整"的反馈,就不算 Loop。
二、Loop 强在哪
理解了是什么,再说它到底好在哪。我觉得最实在的有三点。
第一,它在你不在的时候也能干活。这是最直接的好处。你把目标和规则定好,它可以挂在定时任务上,晚上你睡觉它在跑,早上你打开电脑,看到的不是"又出问题了",而是"这件事已经处理好了,等你看一眼"。Claude Code 团队的人就描述过这种状态:睡前挂上几个 loop,醒来代码改好了、测试也过了、PR 都提上去了。
第二,它能把重复劳动彻底甩掉。一次性的活不值得,但凡是你每周、每天都要重复做的事——同样的检查、同样的整理、同样的修补——Loop 设计一次,之后就一直替你跑。你前期花在"定规则"上的时间,靠它跑很多遍摊薄掉。
第三,它能跨天、跨任务地接着干。AI 每开一段新对话就什么都忘了,这是它的老毛病。Loop 的做法是把进度写在对话之外的一个文件里——做完了什么、卡在哪、下一步干啥。下一轮开始时先读这个文件,就接着上次往下走。一个要干好几天的活,因此能连贯地推进,而不是每天从零开始。
但这些好处都有个共同的前提:它们全建立在"你能检查它干得对不对"之上。没有这个前提,上面三条会全部反过来变成坏处——它在你不在时安静地把事情搞砸,还很自信地告诉你做完了。## 三、动手前先想清楚:你这事到底该不该上 Loop
Loop 不是免费的。它烧钱(反复读上下文、反复重试,不管有没有产出都在花),要花时间搭,出了问题你还得去 debug 一个自己没亲眼看它跑的系统。所以别上来就搭,先拿四个问题过一遍。
一,这活是重复的吗?每周至少出现一次,才值得自动化。一次性的活,写个好提示词更快更省。
二,做完了能不能自动判断?你能不能说清楚什么叫"做好了",并且这个标准不靠你肉眼盯、机器自己就能判?写代码有测试、有报错可以判;写文章"写得好"就很难判。判不了,Loop 就没法自己决定该停还是该重来。
三,token 预算扛得住浪费吗?Loop 会试探、会重试、会反复读上下文,每一步都在花钱,哪怕这一步没产出。预算紧,就先别让它无人值守地跑。
四,出事的范围可控吗?第一次跑 Loop,千万别给它删文件、发消息、动账户、操作支付这类权限。一旦自动跑了,撤不回来。先从只读文件、只在本地改东西这种低风险的活开始。
还有一个绕不开的:你打算认真 review 它产出的东西吗?Loop 最大的陷阱不是跑不动,而是跑得很顺、你却懒得看,最后方向早偏了你也不知道。
适合上 Loop 的活:- 把散落的资料整理成可持续提问的知识库
- 内容生产前期的选题和素材拆解
- 有测试的小代码库做"改代码—跑测试—再修"
- 定期的项目状态检查
不适合上 Loop 的活:- 纯创意("画一幅好画",你没法定义"好")
- 重大判断(该不该跳槽这种,AI 不能替你拍板)
- 以及任何"什么叫做完"你自己都说不清的事
判断标准就一条:你能不能提前讲清楚什么叫"做完了"、什么叫"做好了"。 说不清,别上 Loop,就是浪费钱。## 四、Loop 的七个结构
Loop 是一套由七个组件构成的系统——像一座微型的自动化工厂。它们大部分不是 Loop 这一层的新发明。 回头看那座塔——Skills 和 Memory 是在喂 Context,Connectors、Worktree、停止条件是在划 Harness 的边界。
真正属于 Loop 这一层的新东西,其实只有"触发"和"读写分离"两样——让它自己启动,再让它自己检查自己。剩下五个,都是把下面三层早就有的能力,只是接进这台自动循环里。
1. 触发(Automation)——心跳Loop 需要一个自动启动的方式。触发可以是定时的——每天早上 8 点跑一次 CI 检查;也可以是事件驱动的——PR 合并了、测试挂了、新 issue 创建了。Claude Code 里用 /loop 命令按间隔执行,Codex 有 Automations 面板,也可以丢到 GitHub Actions 里。没有触发,就不是 Loop。
2. 隔离(Worktree)——工位多个任务同时跑,最怕它们改同一个文件。Git worktree 给每个任务一个独立的工作目录,历史共享,但文件互不干扰。一个 Agent 修 auth 模块,另一个修 billing,各自在自己的 worktree 里操作,改完各自提 PR。没有这一步,并行的 Loop 就是灾难。
3. 知识沉淀(Skills)——操作手册AI 每次新开对话都像失忆了一样。如果 Loop 每一轮都在"重新学习"你的项目,它只会反复犯同样的错。Skills 就是来解决这个的——Claude Code 里叫 CLAUDE.md,Codex 里叫 AGENTS.md,本质都一样:把项目背景、规则、常见坑点写下来,AI 每次启动时自动读取。没有干净 skill 的 Loop,就像一个每天早上读过期文档的员工——干得越快,错得越远。
4. 连接器(Connectors)——传送带一个只能看本地文件的 Loop 干不了几件事。通过 MCP 或其他协议接上 GitHub(开 PR)、Linear(更新 ticket)、Slack(发通知)、Sentry(查告警),Loop 才算真正接入了你的工作流。热点监控、数据清洗、财务对账——这些自动循环全部依赖连接器把力量延伸到外部系统。没有连接器的 Loop,只是一个封闭的思考机器,无法在真实世界里交付结果。
5. 读写分离(Sub-agents)——质检员做事的和检查的分开。写代码的模型给自己打分,天然会偏向自己的方案——它犯的错,恰好是它自己发现不了的错。用一个独立上下文里的 Agent 来做审查,或者换一个不同的模型来做检验,效果会稳定得多。这是 Loop 架构里最被低估的设计——它不依赖模型变强,只改变工作方式,就能大幅提高输出质量。
6. 状态持久化(Memory)——生产日志没有持久化的 Loop,永远在重复已经犯过的错。模型会忘,但文件系统不会。长任务跨天、跨会话,状态必须放在对话之外:一个 progress.md 文件、一块 JSON 状态、一块 Linear board,记录试过什么、通过了什么、卡在哪里、下一轮从哪继续。一个经典设计是:Coding Agent 每次启动先读 git log 和 progress.md,从未完成列表里挑下一项,做完更新进度,下一次接着跑。
7. 停止条件(Goal / Gate)——下班铃Loop 最怕两种状态:没做完就停,或者做完了还继续改。所以必须有一个硬性停止条件。"所有测试通过且 lint 零违规"就是一个好条件——可验证、无歧义、AI 自己就能判断。Claude Code 的 /goal 命令和 Codex 的"追求目标"功能,就是这个逻辑的产品化:你给一个完成条件,它自己一轮一轮检查,满足就停。没有停止条件的 Loop 不是自动循环,是一台按 token 烧钱的机器。
五、搭你的第一个简单 Loop
别一上来就奔着七个组件全配齐。第一个 Loop,挑一件你每周都要做、做完能被机器自动判对错、出事了也不会伤筋动骨的小事。
最经典的入门款是:一个有测试的小代码库,让它读" progress.md → 挑一项没做完的 → 改代码 → 跑测试 → 过了就提交、更新进度 → 没过就重来,连续两轮还不过就停下来叫你"。
这一个 loop 里,触发、Skills、Memory、停止条件全都用上了,但每一样都是最小实现:一个定时任务、一个 CLAUDE.md、一个 progress.md、一句"所有测试通过就停"。权限只给到读文件和本地改代码。跑顺了,再往外接:
接上 GitHub 让它自己提 PR(连接器),加一个独立的 Agent 替它 review(读写分离),开几个 worktree 让它并行(隔离)。每加一样,都是在已经能跑的东西上加,而不是推倒重搭。
回到那座塔
Loop Engineering 火起来之后,最常见的误读是"提示词写得好不好,以后不重要了"。恰恰相反。你写给循环的那套规矩——什么算合格、什么算失败、失败了怎么办——本身就是一段更难写的提示词。它要被自动跑很多遍,错一个字,放大很多倍。
会盖前三层的人,才是盖得动第四层的人。Prompt 说得清、Context 给得对、Harness 管得住——这三样越扎实,你的 Loop 才越敢在你不在的时候,替你把活干完。塔一点都没有换地基。它只是,又高了一层。