
Step2:别再把 AI 废料发出去了:应用层只做两件事,继承和清洗

读完这篇文章,你能学到:
-
为什么你的人设 Prompt 写得再长,长文一落地还是会飘出一股“维基百科汇报腔”。
-
怎么把写作系统做成可继承的积木,而不是每次都手动复述一遍身份、语气和禁区。
-
为什么真正决定文章能不能发的,不是生成那一下,而是后面那道近乎残忍的“去油清洗”工序。
上一步,我解决的是底座问题。
先把人设钉死,把禁区写死,再加上 evolution_log 这种能跨轮记忆反馈的补丁层。这样一来,模型至少不会一开口就跑偏。
但你很快会发现,底座稳,不等于产出能发。
真正开始写长文时,问题会立刻暴露出来。你明明已经给足了约束,文章也确实围着你的主题在写,可字里行间还是有一股熟悉的味道:句子很完整,逻辑很平,态度很安全,像一个过度训练过的客服,在努力把每一句话都说得“没有问题”。
这就是我最烦的东西。
它看起来像文章,摸上去却没有质感。你知道它想表达什么,但你不会想把它发出去。因为读者一眼就能闻出来,这不是一个人真的想明白之后写下来的东西,这是模型把“最稳妥”的表达概率拼出来了。
所以第二层不能再讨论“怎么生成”。第二层只做两件事:继承,和清洗。
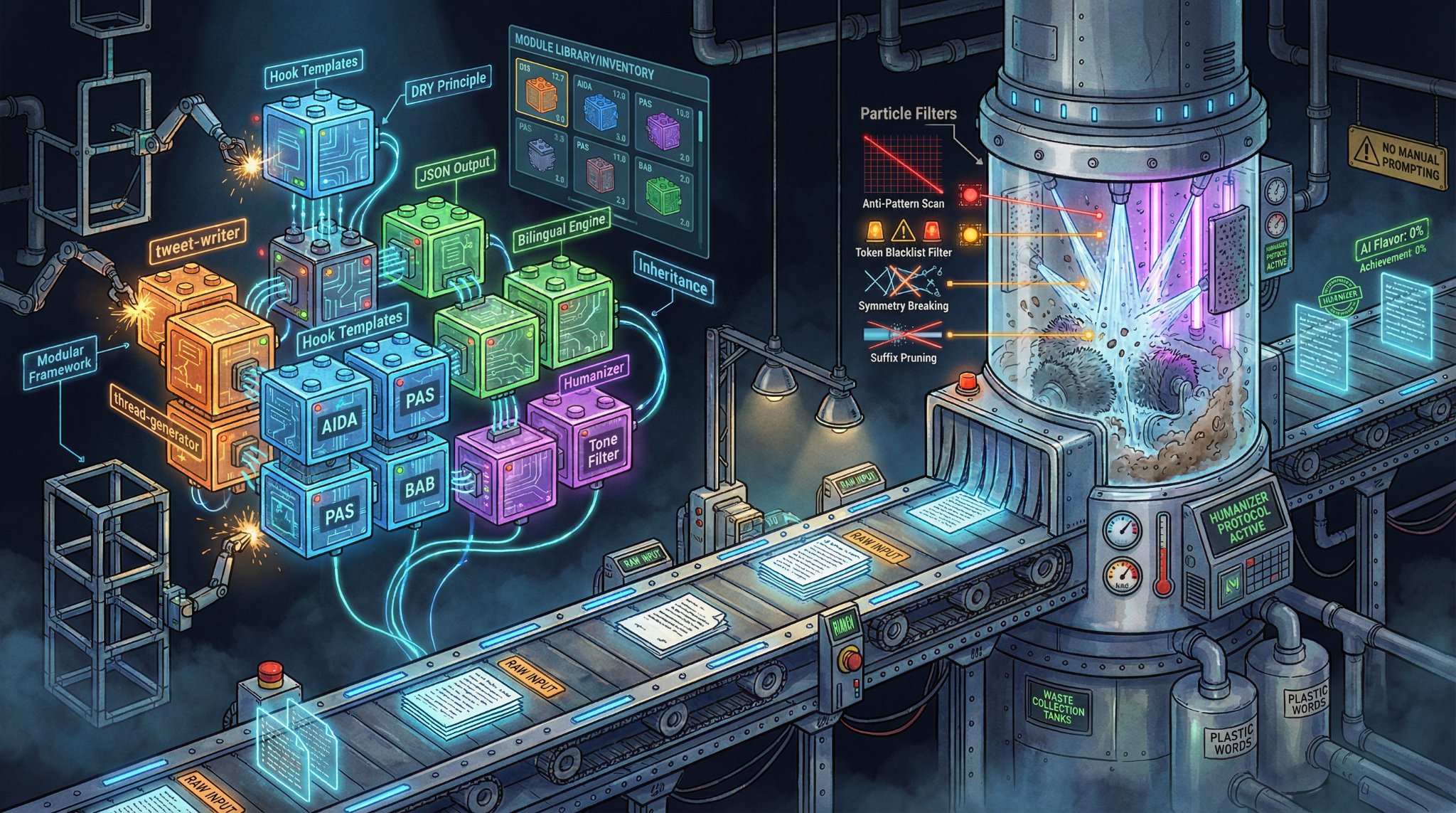
别再当人肉复读机了
很多人做 AI 写作,最大的问题不是不会写,是太原始。
今天写推文,复制一份人设 Prompt。
明天写博客,再复制一份。
后天换个平台,继续复制。
写久了你会发现,真正重复劳动最多的人不是模型,是你自己。
这在工程里根本说不过去。程序员早就给这种行为下过定义:DRY,Don't Repeat Yourself。能继承的东西,就不该反复手抄。
我的做法很简单。底层只保留那部分不会轻易变化的东西:立场、语气、禁区、偏好、进化日志。它像一个基类,负责把“你是谁”这件事固定下来。
往上一层,才是针对具体场景挂接的小模块。
比如同样是一条原始素材,发公众号和发 X,根本不是同一个任务。前者要有铺陈,要有结构递进;后者要求第一句就把人拦下来,后面每一行都得给转发留空间。
所以这时候不该重新发明一个作者,只需要挂一个场景层。
这个场景层不负责思考你的价值观。它只负责三件事:
- 接收底层已经定好的写作人格
- 注入当前平台的格式规则
- 把输出压进指定的数据结构里
拿 tweet-writer 这种模块举例。它不会问模型“你想怎么写”。它会直接规定:第一句必须反直觉,第二句给判断,后面留出换行骨架,必要时把结果固定成 JSON,方便后续自动分发。
这一步的重点不是“创作自由”。恰恰相反,是剥夺自由。
你不把模型塞进模具里,它就一定会开始表演。它会补背景,铺情绪,凑完整,最后产出一段谁都挑不出大错、但也没人真想看的标准答案。

说到底,继承解决的是扩展性。
你以后要接长文、短帖、视频口播、邮件、产品文案,底层都不用重写。真正变化的只是场景层的钩子和格式约束。
系统一旦这么搭起来,写作才第一次像工程,而不是聊天。
再好的骨架,也会长出塑料壳
但继承只能解决“别重复造轮子”。
它解决不了另一个更恶心的问题:模型天然会把文字往平均值上拉。
这几乎是所有长文生成都会遇到的坎。结构对了,观点也没偏,可一旦放大到整篇看,整段整段都太像“正确的废话”。句子工整,语气平滑,结尾还喜欢顺手升华一下,像生怕你没看出它在认真写作。
所以生成之后,必须再过一层清洗。
我把这层叫 Humanizer。
注意,这不是“润色”。
润色的意思,是让一段话更漂亮。Humanizer 不是。它更像车间里的去毛边机,专门负责把模型最爱带出来的那层塑料壳刮掉。它不增加香味,它负责去掉异味。
我主要砍两类东西。
第一刀,砸烂对称句
模型特别迷恋对称。
你给它一个判断,它就想接一个更大的判断;你给它一个问题,它就想补一个更高层的意义。于是你会反复看到这种句子:
这不仅是一次写作流程的优化,更是一次底层认知模式的升级。
这种话表面上很完整,实际一点信息增量都没有。
它的问题不只是空,还假。一个真实的人在键盘前组织语言,不会每次都把句子收得这么圆,这么整,这么像排练过。
清洗这一刀,就是专门把这种结构砸碎。
我更喜欢把它改成这样:
流程改完以后,字没那么油了。
难点不在写模板。难点在于你敢不敢把那些听上去很体面的废话整段删掉。
差别很明显。
前一种是模型在端着说话。后一种才像一个真正动手改过系统的人,会说出来的话。长短句错开了,信息落点也更硬。读者读到这里,不会觉得你在演讲,只会觉得你确实踩过坑。

第二刀,切掉假装有意义的结尾
模型还有一个坏毛病:它总想在结尾证明自己有高度。
明明只是一次普通的功能更新,它也要补上一段像年终致辞的话:
这次升级充分体现了我们在内容系统建设上的前瞻性,也为未来的长期演化打下了坚实基础。
这种尾巴最脏。
因为它会瞬间把前面好不容易建立起来的真实感全部冲掉。你前面写得再具体,最后一旦开始“意义重大”“影响深远”“面向未来”,整篇文章都会重新塌回模型常见的宣传腔里。
我的处理很粗暴:只保留事实落点,不许空转。
比如上面那句,直接砍成:
这次改完,成稿能直接发了。
够了。
读者不是小孩。你把事实放在桌面上,他自己会判断分量。很多时候,真正有力量的句子恰恰停得很早。你一旦忍不住再多解释半句,味道就散了。
所以 Humanizer 这层,本质上不是帮模型“写得更像人”。
它是在阻止模型继续表演。
应用层为什么不能省
到这里,第二层的任务已经很清楚了。
继承,解决的是系统能不能扩。
清洗,解决的是内容能不能发。
少了前者,你会沦为提示词搬运工。每换一个场景,就重新复读一遍自己是谁。
少了后者,你会稳定地产出一堆结构正确、态度端正、但一看就不想发的 AI 回收料。
这也是为什么我越来越不相信“一个大 Prompt 走天下”这种说法。真正能用的写作系统,从来不是把全部要求堆进一次生成里,然后祈祷模型自己完成理解、约束、格式化和去油。那只是把复杂度藏起来,不是把复杂度解决掉。
该分层就分层。
该上清洗就上清洗。
写作工作流一旦进入工程视角,你就会明白一件事:模型的初稿不是作品,只是原材料。
原材料当然可以快。
但真正决定你能不能把东西发出去的,永远是后面那道处理工序。
下一步
到了这里,文字的腔调基本收住了。
但还有一颗更危险的雷没拆。
模型很会一本正经地瞎说。一个年份,一个数字,一个看似准确的引用,只要你没额外设防,它就敢往外吐。语气还特别笃定。
所以第三步,不再解决风格问题,而是解决可信度问题。