
Reddit内容洞察飞书多维表自动化工作流分享

用飞书多维表,把 Reddit 原话变成内容洞察看板
最近用飞书多维表做了一套 Reddit 的内容洞察系统,能很直观地得到用户需求的细分。
把公开讨论先变成一张原始数据表,再用飞书多维表做内容洞察,最后沉淀成一个可以持续看的仪表盘。
这篇我用一个小案例讲完整流程:收集 DIY 无人机相关 subreddit r/diydrones 的少量原始数据,包括帖子正文、评论正文、总评论数和点赞数,然后直接放进飞书多维表里分析。
整条链路很简单:Reddit 原话采集 → 飞书多维表沉淀 → lark-CLI 生成洞察表 → 仪表盘跟踪需求
第一步,先收集原始讨论
最稳的方式是申请 Reddit API,然后按 subreddit、关键词、时间范围去拉数据。
这个阶段不用一上来采几万条,根据自己的数据量需求,拿近期时间段的帖子和评论做小样本就够了。
我会保留这些字段:
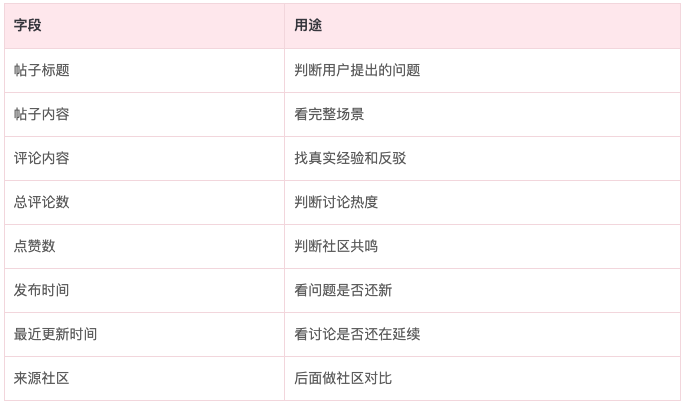
比如 DIY 无人机场景里,用户可能会讨论飞控调参、电池续航、零件兼容、入门套件、法规限制、炸机维修、图传延迟
这些词本身不是洞察。真正有用的是:新手为什么卡住,老手为什么不满,哪些问题反复出现但没有好答案。
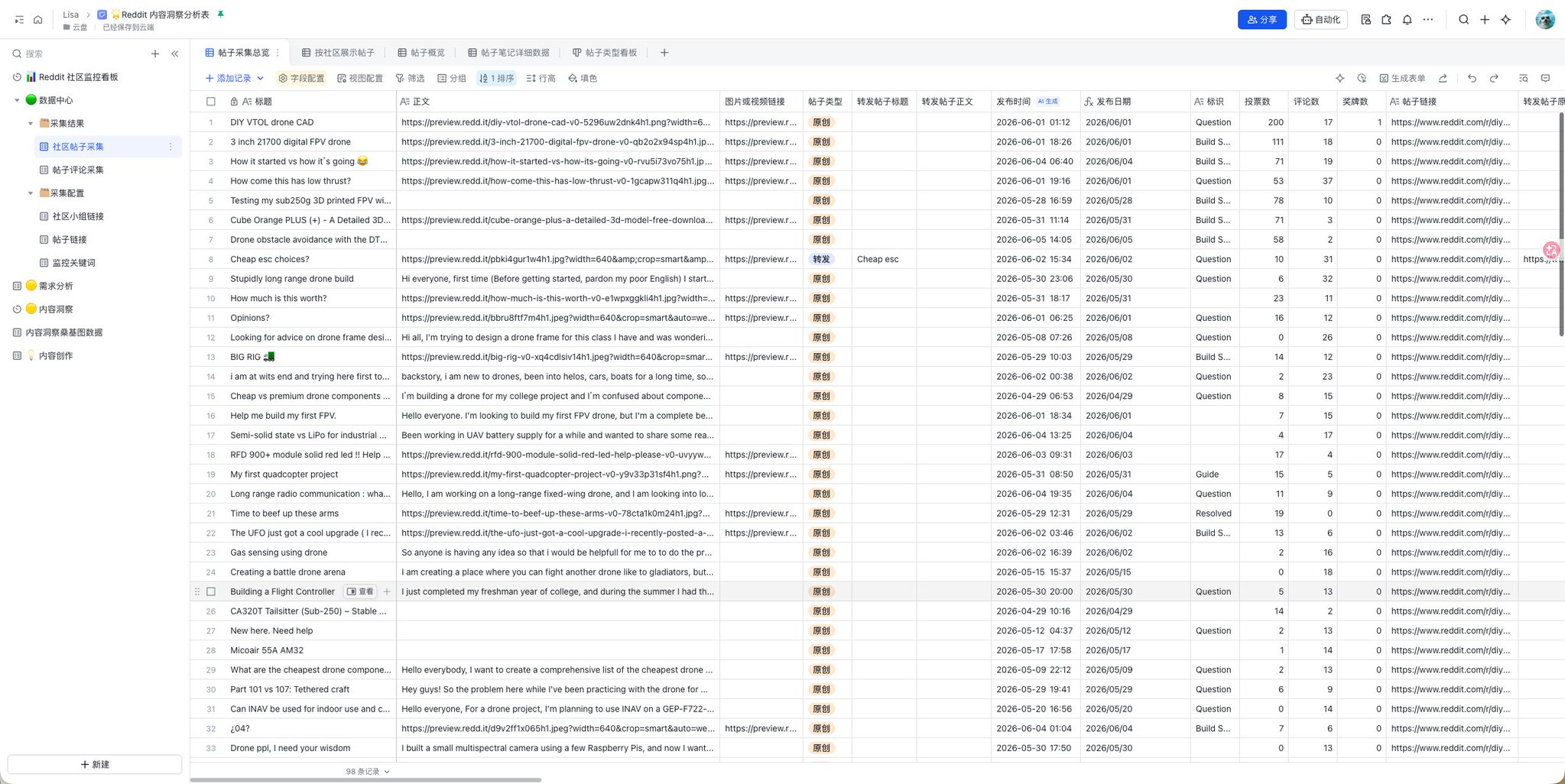
第二步,用飞书 CLI 生成内容洞察表
原始表只是素材池。
我真正想看的,是每条讨论背后反映了什么需求。
所以我会用飞书 CLI 读取原始表,再把帖子和评论交给模型分析,生成一张“内容洞察表”。这张表的字段可以这样设计:
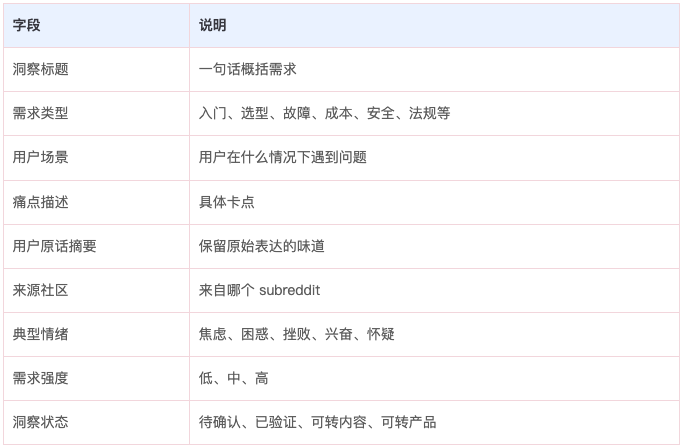
另外还可以统计这些证据字段
相关帖子数、相关评论数、总投票数、总评论数、负面评论数、帖子发表时间、最近更新时间。
最后再加几个计算维度:
证据数 / 讨论强度 / 痛点强度 / 需求热度
这里的重点不是让 AI 替你下结论,而是让它先把散乱的原话整理成可以复盘的结构。
如果是在网页端,则直接使用飞书多维表“通过AI创建即可”
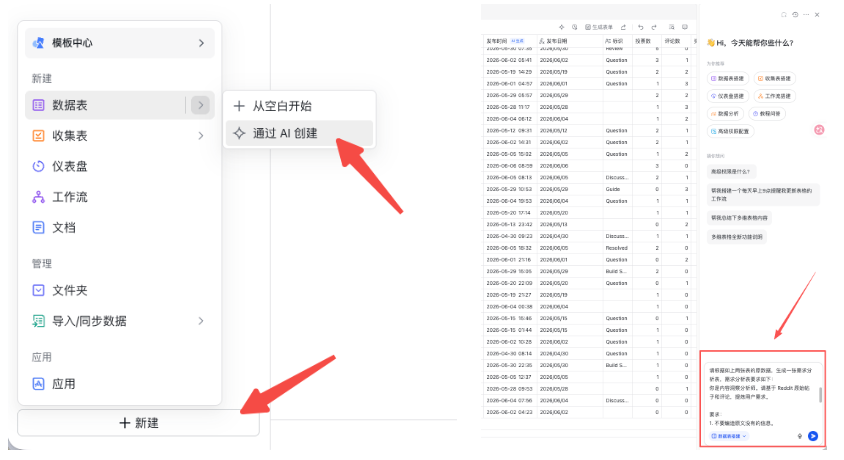
我会给模型类似这样的 prompt:
你是内容洞察分析师。请基于 Reddit 原始帖子和评论,提炼用户需求。
原始数据表格地址:
<自定义飞书多维表地址>
要求:
1. 不要编造原文没有的信息。
2. 每条洞察必须对应具体帖子或评论证据。
3. 优先识别反复出现的问题、强烈情绪、替代方案不满和求推荐行为。
4. 输出字段包括:洞察标题、需求类型、用户场景、痛点描述、用户原话摘要、来源社区、典型情绪、需求强度、洞察状态、相关帖子数、相关评论数、总投票数、总评论数、负面评论数、证据数、讨论强度、痛点强度、需求热度。
跑完以后,你看到的就不是一堆帖子了,而是一张需求地图。

比如原始评论里有很多人说“新手不知道该买哪种飞控”“教程太碎”“炸机后不知道怎么排查”,洞察表里就可能合并成一条:
新手缺少从选件到首飞的完整排错路径。
这条洞察后面可以变成文章、视频、清单、模板,甚至是一套入门产品包。
第三步,把洞察表变成仪表盘
内容洞察如果只停留在表格里,还是不够直观。
我会在飞书多维表里给它做一个四层仪表盘。
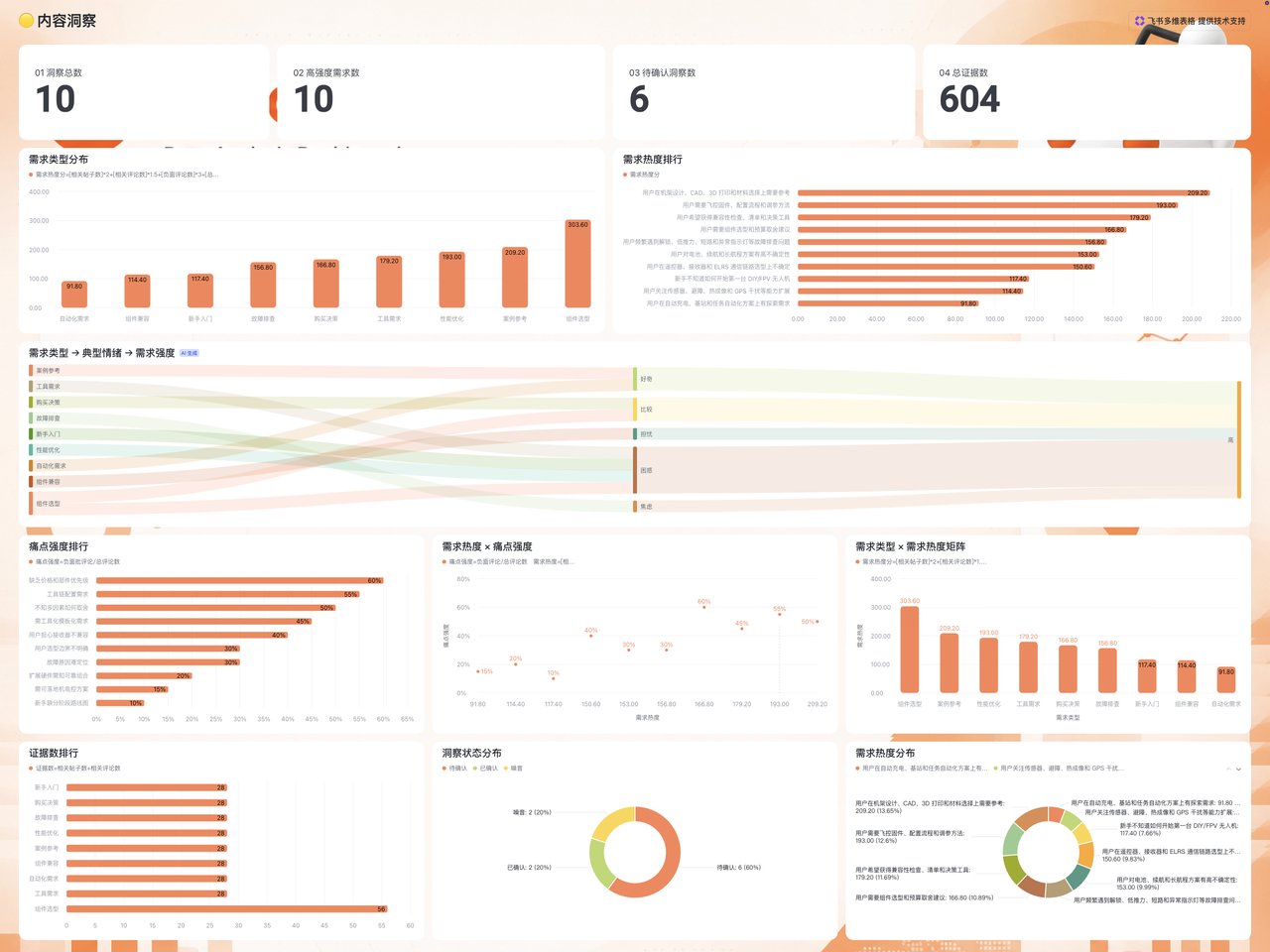
第一层是总览:
- 洞察总数
- 高强度需求数
- 待确认洞察数
- 总证据数
这一层回答:现在我们到底发现了多少需求,哪些值得先看。 第二层是用户需求地图:
- 需求类型分布
- 需求热度排行
- 需求类型 → 典型情绪 → 需求强度 桑基图
这一层回答:社区里的需求主要集中在哪里,哪些情绪正在推动讨论。 第三层是痛点与机会:
- 痛点强度排行
- 需求热度 × 痛点强度散点图
- 高热高痛需求列表
这一层最适合做选题和产品机会判断。高热高痛的需求,通常不只是“有人聊”,而是“很多人反复卡在这里”。 第四层是证据可信度:
- 证据数排行
- 证据类型分布:帖子为主、评论为主、均衡
- 低证据高热度需求列表
这一层用来防止自己被少数高情绪样本带偏。 如果一条需求热度很高,但证据数很低,我会先把它标成“待确认”,继续收集更多帖子和评论,而不是马上拿去做判断。最后可以让表格自己总结
飞书多维表还有一个很实用的点:智能总结。
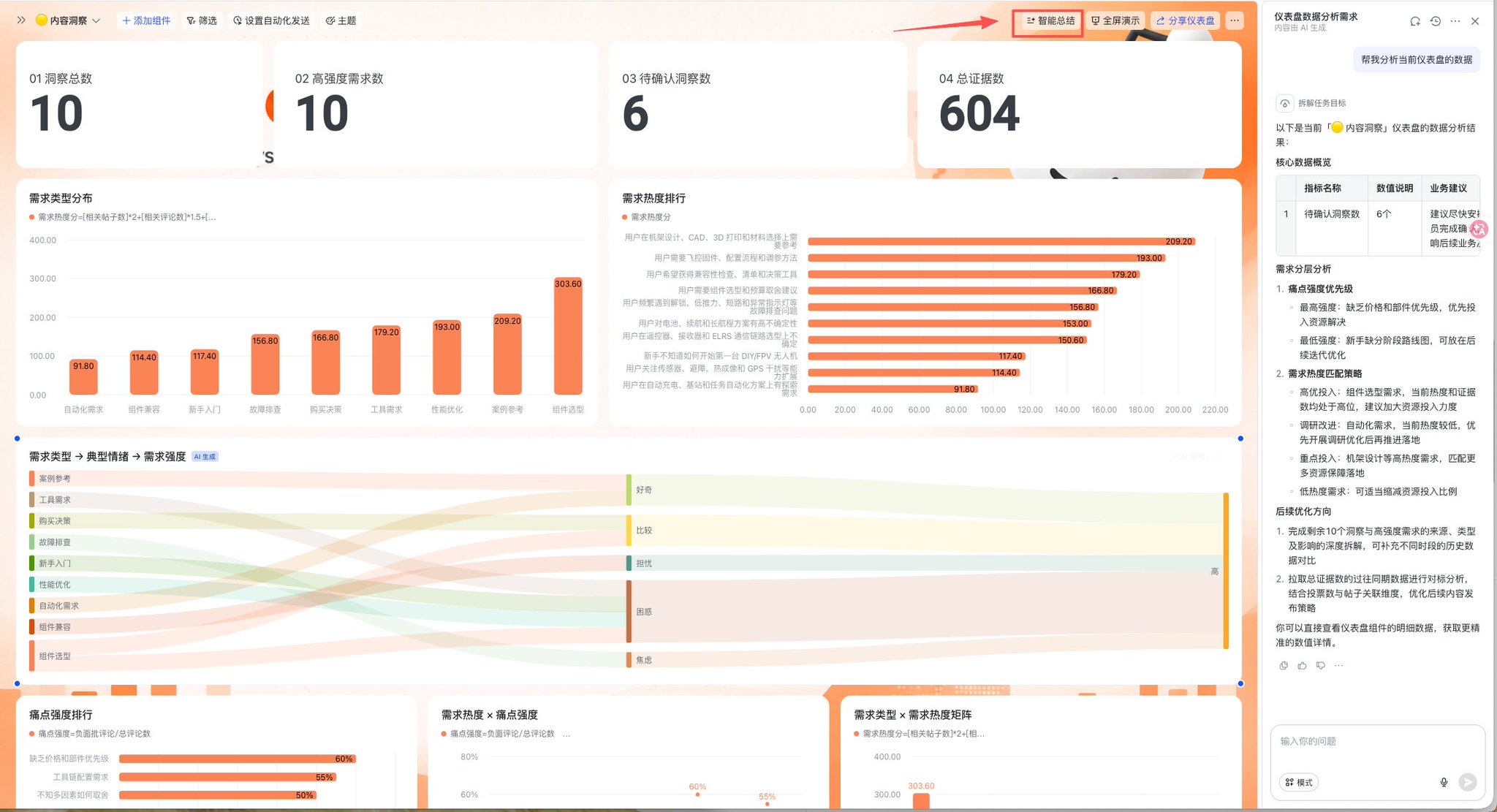
当内容洞察表跑起来之后,可以直接让它总结最近一批 Reddit 数据里最常见的需求、最强的痛点、最值得追踪的主题。
这套方法不复杂,但它解决了一个很具体的问题:
我们不再靠刷 Reddit 的感觉做判断,而是把用户原话、互动数据、情绪、痛点和证据数量放到同一张表里。
- 对于内容团队来说,它可以变成选题库。
- 对于产品团队来说,它可以变成需求池。
- 对于创业者来说,它可以变成一个小型市场雷达。
如果你想试,不用一开始做大系统。
先找一个或几个你熟悉的 subreddit,获取原贴和评论数据,放进飞书多维表,跑出第一版内容洞察。
看到第一张**“高热高痛需求列表”**的时候,你就会知道:Reddit 里真正有价值的,不是热闹本身,而是热闹背后那些反复出现的具体问题。