
市面上关于第二大脑的文章,你都不用看了!这里告诉你关于它的一切

这篇不是常规意义上的教程。
它不是教你怎么建几个文件夹、配几个插件、抄一套模板就结束了,而是带你更深地认识一件事:
第二大脑在 AI 时代真正该解决的,到底是什么问题。它解决的不是“记多少”,而是你的注意力怎么分配、判断怎么沉淀、任务怎么推进、长期主线怎么不被带跑。
文章比较长,你当然可以复制给 AI 辅助阅读。
如果一套“第二大脑”,只是让你更容易收藏、更容易分类、更容易获得一种“我今天没白忙”的安慰,那它根本不是第二大脑。
它只是一个更高级的仓库。
更糟的是,它还会让你误以为自己一直在进步。
你剪了很多网页,记了很多判断,存了很多爆款拆解,标签越来越密,目录越来越漂亮。
可真到要写一篇文章、做一个项目、发一条 X、准备一次分享,你还是要从头找、从头想、从头拼。你以为自己缺的是更多笔记。
其实你缺的是一套会替你做认知路由、动作推进和结果回写的外脑系统。
这也是我为什么越来越不想看市面上那些“第二大脑”文章。它们大多在解决一件事:怎么存。可真正决定你会不会变强的,从来不是你存了多少,而是高价值信息进来之后,会不会继续往判断、任务、项目、表达和分发流过去。
我现在这套第二大脑,做的就不是“知识收纳”。
它做的是认知工程。
更具体一点,它是一套基于ClaudeCode/Codex+Obsidian的面向内容创作者的数字分身。它把每日规划、项目推进、热点整理、选题孵化、深度研究、X 内容生产、风格进化、工作流自动化,收进同一个本地文件系统里。再往上一层,我还把德鲁克、乔布斯、原研哉、芒格、巴菲特、马斯克这些世界级思维模型,外接成多顾问 Agent 层,让不同领域的决策不再只靠我一个人的临场发挥。
这篇文章,我把它完整拆开。
大多数第二大脑,输在第一步
大多数第二大脑文章,教的是笔记方法,不是认知系统。
它们很爱讲收集、整理、标签、双链、PARA、卡片、数据库。
这些东西当然有用,但它们解决的是“放哪儿”,不是“接下来去哪儿”。
而对内容创作者来说,最贵的成本恰恰不是存不住,而是推进不了。热点看了很多,最后一个也没写。
想法记了很多,最后一个也没启动。研究做了很多,最后一次也没成交。
人脑本身就不适合长期把所有开放环路压在头里。
前额叶负责控制、选择和抑制,但它的工作记忆容量非常有限。
你能短时间盯住几件事,不代表你能一直盯住几十条待办、十几个选题、几条项目主线和一堆没处理完的资料。
海马体适合把经验编码进长期记忆,却不会在你明天早上醒来时,自动帮你排出“今天最该先做什么”。
基底节擅长把重复动作变成习惯,但前提是系统有稳定触发器,而不是每次都让你重新决定。
所以,真正能用的第二大脑,不是替你“记更多”。
而是替你把最容易掉链子的地方外接出来。
真正的第二大脑,不是 App,是认知架构
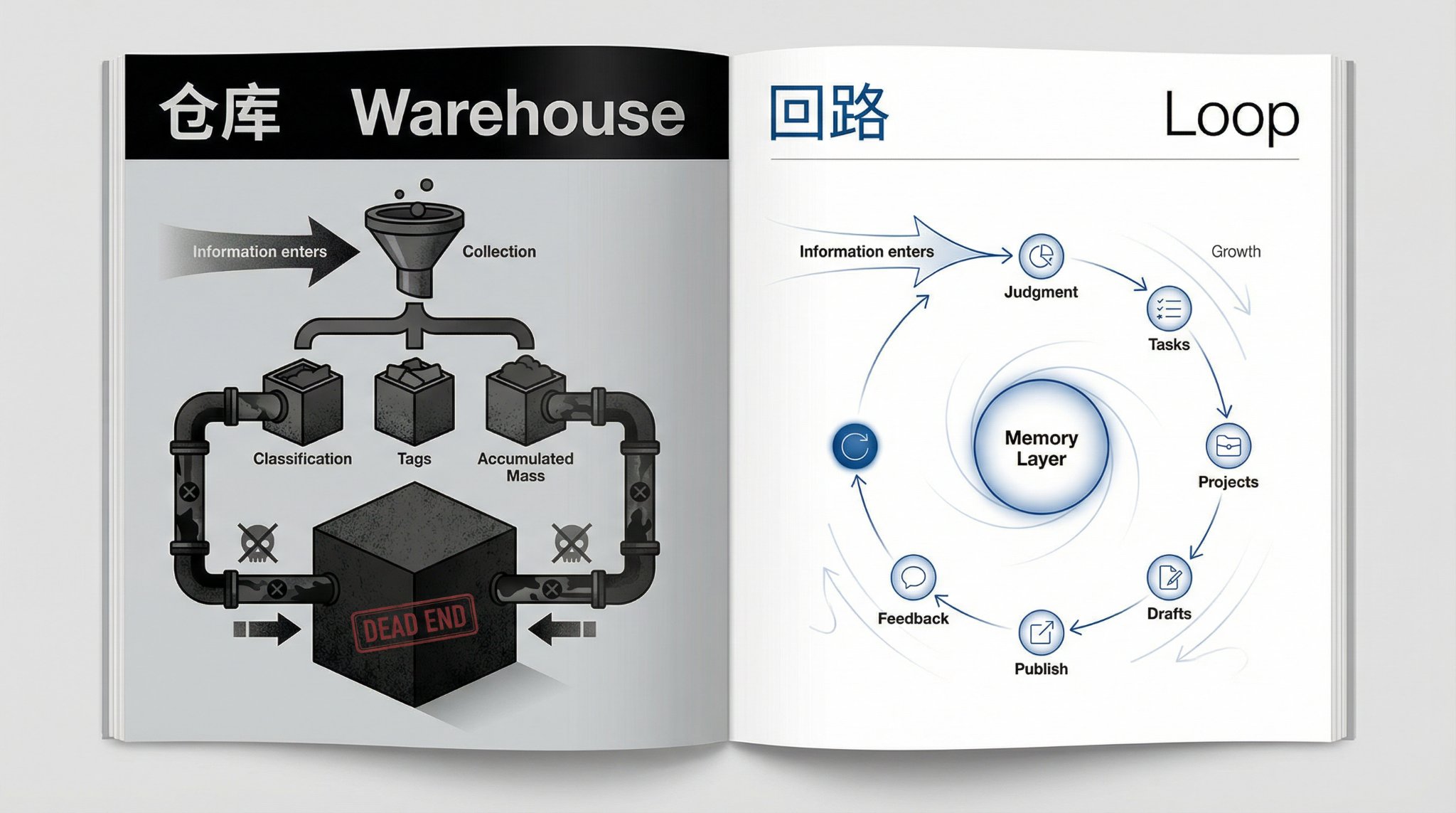
我这套系统的第一原则很简单:
不要维护两套平行结构。
如果已经有一套面向创作的目录体系,第二大脑就不应该再复制一套新宇宙。它应该做的是叠加“记忆、规则、任务、判断、动作回路”这些能力,而不是让你在两个系统里来回复制粘贴。
所以,这套系统的底层不是“我用了 Obsidian”。
底层是一个统一的本地文件系统。
计划、研究、记忆、素材、草稿、配图、工作流、发布准备,全都在同一个 vault 里。这样做听起来很朴素,但它有一个非常狠的优势:上下文不再被工具切碎。你不会在 A 工具记想法,在 B 工具排计划,在 C 工具做研究,在 D 工具写文,在 E 工具准备发布。对创作者来说,切换一次工具,往往不是切换一个窗口,而是切换一整套认知状态。
这套第二大脑最先解决的,不是信息量。
而是上下文连续性。
但如果只停在这里,这篇文章的认知还是不够高。
因为“上下文连续性”还只是效果描述,不是定义本身。
我现在越来越认同一种更底层的说法:
第二大脑真正外接出来的,不是记忆容量。
而是认知控制。
更准确一点,它外接的是四件事:
- 注意力分配
- 长期记忆索引
- 动作选择
- 跨时间的自我连续性
这四件事,才是大脑真正昂贵的部分。
人脑真正稀缺的,从来不是“能记多少”,而是“在这个时刻,什么该被看见,什么该被压后,什么该被提纯,什么该被推进,什么和我是同一条长期主线”。所以任何只优化收纳、不优化控制的第二大脑,最后都会越来越像数字阁楼。东西很多,检索也不难,但它对你的判断质量、动作速度和身份连续性帮助很小。
这也是为什么我会说,它不是知识管理工具。
它更像认知控制平面。
再往高一层,我现在其实越来越不把这件事叫“第二大脑”。
我更愿意把它理解成个人认知基础设施的治理层。
这两个说法差别很大。
“第二大脑”听起来像一个附属器官,重点是你多了一个帮你记东西的外挂。
“认知基础设施治理层”强调的则是另一件事:谁在决定你看见什么、忽略什么、优先处理什么、把什么沉淀成长期资产、又把什么导向任务、项目、表达和市场。
也就是说,真正稀缺的不是存储。
而是治理权。
在 AI 时代,这件事会越来越尖锐。平台热榜、通知系统、推荐算法、短视频流、即时消息、协作软件,看起来都只是信息通道,但它们真正争夺的,是你认知系统的调度权。谁来决定你的注意力如何分配,谁来决定什么进入高代价思考,谁来决定什么反复打断你,谁其实就在塑造你的长期轨迹。很多人以为自己只是“信息过载”,更底层的真相往往是:认知主权外包得太多。
所以我现在搭的,不是第二大脑的展示层。
而是第二大脑的思维层。
我现在这套第二大脑,具体长什么样
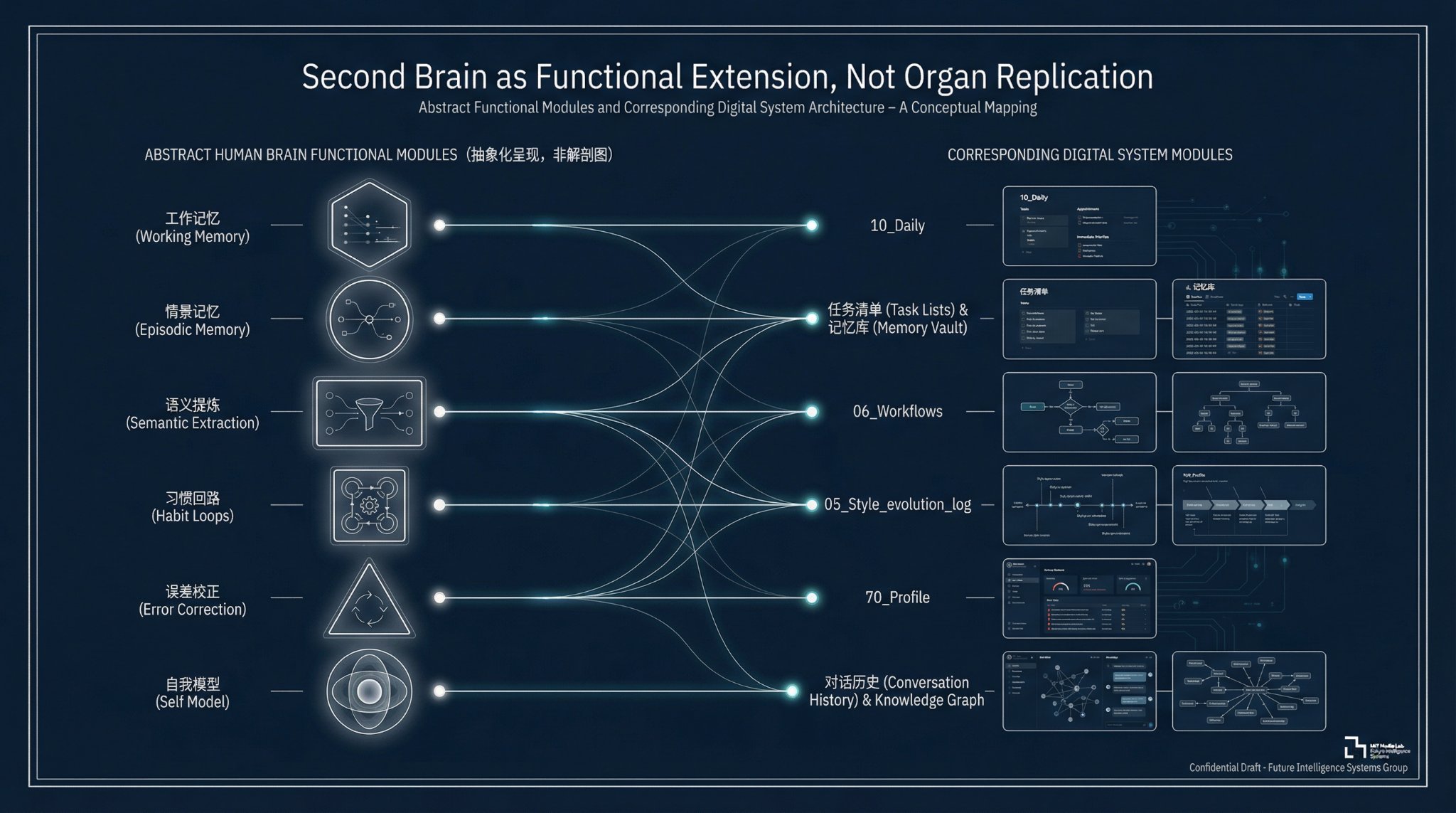
这里参考了Roland的系统:
📝 Roland 博士开源了一个 AI 第二大脑,架构思路值得每个用 AI 的人看看
2026.03.21,深圳。(Stanley @Stanleysobest 和他的朋友们 | 全球聚会深圳站2026年03月21日 at 深圳华益传媒有限公司 | 壹海国际中心)
今天听 Roland 博士 @rwayne 现场分享了他开源的「AI...

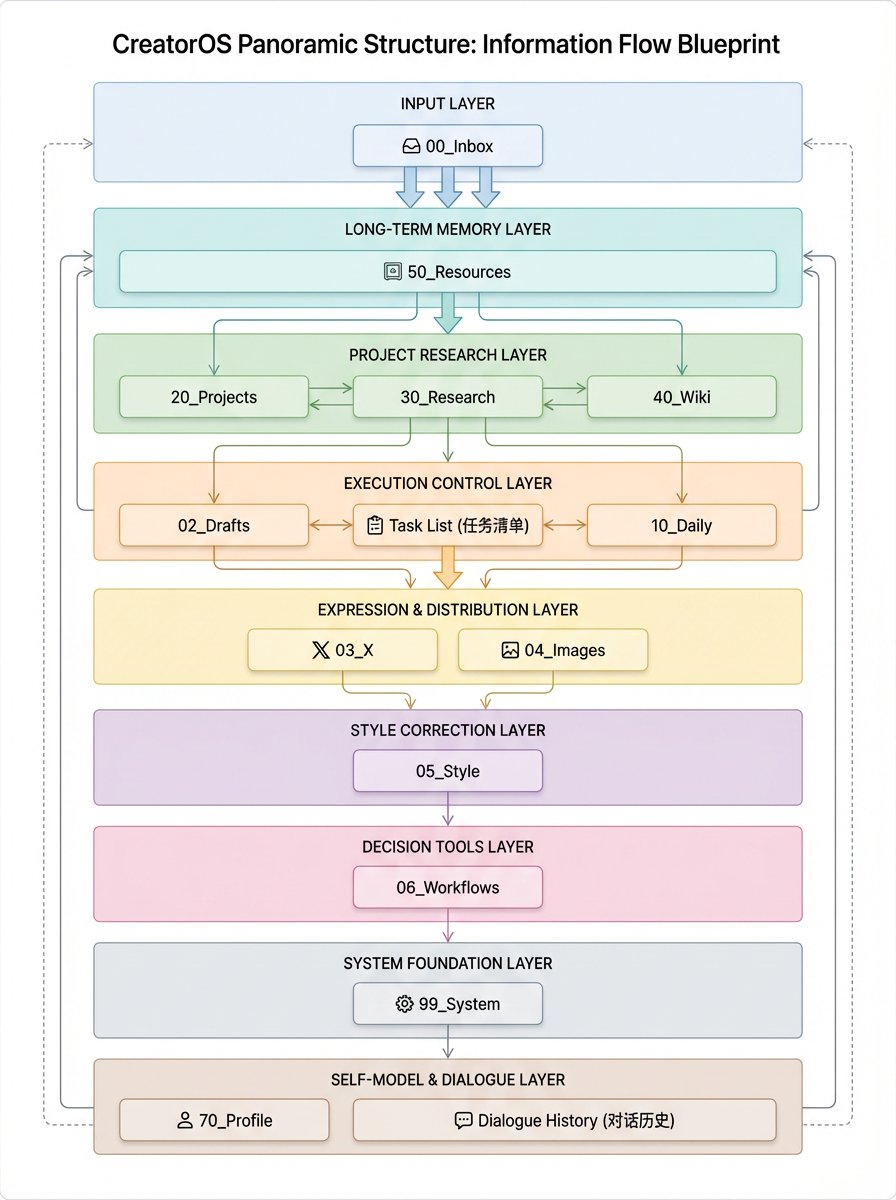
如果把它拆开看,它大概有九层。
第一层:输入层
- 00_Inbox/:所有临时想法、网页剪藏、碎片素材的收件箱。
- 50_Resources/:更稳定的外部输入层,包括 AI_News、Daily_Pulse、Topic_Seeds 和导入资料。
这层像感官入口。它负责把外部世界里的噪音、信号、灵感、热点先接住,但不假装它们已经有价值。价值不是输入自带的,价值来自后续路由。
而且这层不是乱收。
它已经有明确前门。
短内容、帖子、论坛回复、临时看到的网页,会优先通过 Obsidian Web Clipper 进入 00_Inbox/。长文、教程、文档站、GitHub README、以后可能要反复回查的原材料,则优先进入 50_Resources/Imported/。
这套分流听起来像目录洁癖,实际上是在保护后续认知加工。因为“我刚看到一个东西”和“这个东西已经值得进研究、值得进选题、值得进表达”根本不是同一件事。
这就是为什么我说 Clipper 在这里不是一个收藏插件。
它是这套外脑的前门。
先收,再判,再升级。输入和输出不混,系统才不会越来越脏。
更狠的一点在于,输入层里最重要的不是网页收藏,而是新闻发现机制。
很多人的“每日新闻”其实没有系统,只有情绪。刷了很多,感觉自己知道得不少,最后一个也没变成真正有用的判断。我现在这套第二大脑不是这么处理的。只要我说“每日新闻”“今日新闻”“把新闻抓下来”,系统默认不会退化成纯人工找新闻,也不会只盯几个官方博客。它会先走一层混合发现路线。
第一步,拉结构化发现层。分类、signal、热点和相关 X 推文会先落成 structured_input.md。
第二步,接上 Daily_Pulse 和 Daily_Radar/*.html。这里的 HTML 不是附属页面,而是默认路线的一部分。它把 AI 线、国内主盘、海外补充、平台热度和社会情绪放到一个可巡检的雷达盘里,我可以非常快地看见什么是今天新增,什么只是昨天的延续,什么应该降权,什么值得单独拎出来。
第三步,回到官方博客、官方发布页或可信一手报道验证事实。因为发现层负责扩大视野,不负责替我下结论。
第四步,把真正值得留下来的部分压成 AI_News/_digest.md 和 Topic_Seeds/_topic_seeds.md。如果 HTML 雷达里出现高讨论、强情绪、但还不适合进正式摘要的条目,也可以直接作为 html_pick 进入选题层。
也就是说,这套系统不是“先看新闻,再想写什么”。
它是“先发现信号,再验证事实,再压缩判断,再生成选题”。
一旦这条链跑顺,新闻就不再只是信息消费。
它会直接进入内容生产。
而且这里面还有一层更底的逻辑。
世界上的有效信号,本来就不长在同一个地方。官方源给你事实锚点,结构化发现层给你领域排序,平台热榜给你情绪温度,HTML 雷达盘给你跨类目巡检,相关推文和评论区给你叙事方向。
你如果只看其中一层,最后得到的都只是局部真相。
只看官方,你容易错过已经开始发酵的社会语境。
只看平台,你会被噪音和情绪带跑。
只看结构化榜单,你会以为分数高就等于值得写。
真正成熟的发现机制,不是站队某一层。
而是让不同层各司其职。
结构化发现层负责“哪里值得看”,HTML 雷达盘负责让你更轻松的看到、理解并处理,一手验证层负责“哪些能写进正式判断”,选题层负责“这件事最后和我有什么关系”。
这条链越清楚,创作者越不容易被新闻消费,越容易把外部世界压成自己的表达资产。
第二层:长期记忆层
- 记忆库/情景记忆/:记录具体事件、具体决策、具体上下文。
- 记忆库/语义记忆/:提炼成可复用的方法、判断、模式。
- 记忆库/强制规则/:沉淀不可违反的系统规则和底线行为。
这三层非常关键,因为它们对应的不是同一种记忆。
情景记忆更像经历本身。什么事发生了,为什么这么做,当时的约束是什么。
语义记忆更像提纯后的结论。以后再遇到类似问题,可以直接调用,而不用重新从整段经历里挖。
强制规则则更像执行约束。它不是“知道了”,而是“以后必须这么做”。比如时间意图要写进 任务清单.md,比如新文件要按内容类型路由到正确目录,比如系统默认不自动发 X,而是保留人工审核闸门。
很多人的第二大脑只有前两种东西的混合体。
我的系统把第三种也拉出来了。
这会让系统从“懂很多”,变成“行为稳定”。
如果用神经科学的语言来翻译,这一层的拆分其实很合理。
海马体更像索引器,它擅长把一次经历按时间、地点、人物、因果钉住
长期皮层表征更像抽象器,它会把多次相似经验压成模式和 schema
而真正让一个系统以后表现不同的,往往不是“知道了什么”,而是“以后默认怎么做”。
所以情景记忆、语义记忆和强制规则分开,不是为了显得高级,而是在模拟一条经验如何从事件,变成知识,再变成默认行为。
这也是为什么很多人的第二大脑越用越重。
因为他们只有沉积,没有制度。
经验当然会越积越多,但如果经验进不了规则层,它就只能作为材料存在,不能作为治理能力存在。材料多,不等于组织能力强。一个人知道很多道理却总在关键时刻掉链子,本质上不是知识不够,而是知识没有升格成默认策略。
第三层:项目与研究层
- 20_Projects/:每个活跃项目都有自己的项目笔记。
- 30_Research/:深度研究原件。
- 40_Wiki/:镜像层,用来浏览、链接和复用,不替代原件。
这里有一个非常成熟的设计选择:40_Wiki/ 不是源数据区,而是镜像层。原始研究还在 30_Research/,语义知识原件还在 记忆库/语义记忆/,选题原件还在 50_Resources/Topic_Seeds/。
这样做的好处是,浏览和生产分开了。你既能拥有一个好逛、好搜、好双链的 wiki 层,又不会把真正的生产现场搞乱。
很多人到后面系统会乱,不是因为他不够勤快,而是因为浏览层、生产层、归档层、分发层混在一起了。
这套系统把这件事拆得很清楚。
第四层:执行控制层
- 任务清单.md:唯一任务总表。
- 10_Daily/YYYY-MM-DD.md:每日锚点。
- 启动第二大脑、start-my-day:每天开机时的执行入口。
这一层最像前额叶。
它不负责“知道很多”,它负责“今天先做什么、不做什么、主线是什么”。比如今天的日记会明确写:第一优先是什么工作
今天不被什么任务介绍带走
什么任务只占余量时段。
你会发现,真正降低心智消耗的,从来不是把一切都记录下来,而是提前帮自己把不该做的事也写清楚。
这也是为什么我越来越觉得,第二大脑必须有一个单一任务总表和一个每日控制塔。
没有这两层,你的系统只会越来越会存,不会越来越会选。
而且这个控制塔不是抽象的。
它接的是我真实的生活。
第五层:表达与分发层
- 02_Drafts/:内容草稿。
- 03_X/:X 成稿。
- 04_Images/:配图方案和提示词。
- 06_Workflows/:从热点到选题、从研究到成稿、从成稿到 BitBrowser 发布准备的流水线。
大多数第二大脑文章,在这里就断了。
它们教你记,教你连,教你搜,但很少教你怎么把东西真正推出去。可对创作者来说,内容不是写出来就结束了。它还要进入标题、结构、配图、审核、分发、评论区承接、后续复用。
我这套系统最不一样的地方之一,是分发层已经接上了。
X 不是“以后再说”,而是架构里的一部分。某个Browser的发布准备链路、内容管线、人工审核闸门,全都已经在 vault 里。
这意味着第二大脑不只负责记忆。
它负责把结果送到市场。
第六层:风格与误差校正层
- 05_Style/voice_profile.md
- 05_Style/evolution_log.md
这一层很少有人认真做,但它其实极其重要。
绝大多数人写作靠“这次记住”,下一次又忘了。
今天被用户骂标题不行,明天换个主题又犯同样的问题。我的系统把这种反馈直接写成长期约束。比如标题必须先打到人性,系统类长文默认补现实案例,article 不能写成拆行版短帖,钩子要先给矛盾和代价,再给结论。
你可以把这层理解成一种误差校正机制。
人脑当然也会从错误里学习,但它很容易情绪化、碎片化、选择性遗忘。
把错误写成 evolution_log,等于把“这次吃过的亏”转成以后默认生效的规则。它有点像前扣带皮层做的事,持续监控偏差;也有点像小脑的细调,不断减少动作误差。
这就是为什么我越来越觉得,第二大脑一定要有“进化日志”。
没有这一层,你每次都像第一次。
第七层:决策工具层
这套系统里还有一张我非常看重的卡:记忆库/语义记忆/问题分析与决策思维工具箱.md。
里面不是泛泛的方法论清单,而是明确写死了不同场景该调用什么工具:
- 定义问题、拆系统、拆假设:第一性原理、5Why
- 找主线、抓优先级、决定今天先做什么:矛盾分析法、二八法则、艾森豪威尔矩阵
- 做项目启动、结构化方案、文章骨架:麦肯锡七步法、MECE
- 处理争议观点、反对意见和复杂方案评估:正反合、六顶思考帽
- 做跨领域判断、研究总结和类比迁移:多元思维模型、跨学科类比法
这里参考了:
叫我阿杭 (@Astronaut_1216)
AI时代,你必须要对AI说的9个词语
1.亚里士多德的第一性原理
2.毛泽东的矛盾分析法
3.麦肯锡七步法、MECE原则
4.5Why分析
5.黑格尔的正反合三段论
6.德博诺的六顶思考帽
7.查理·芒格的多元思维模型、跨学科类比法
8.帕累托的二八法则
9.艾森豪威尔矩阵他能让你的龙虾 在不同的场景展现高超的智慧
这件事的意义非常大。
因为它意味着,这套第二大脑存的不只是内容,还存“如何思考”。很多人的知识库越用越重,就是因为它只能提供材料,不能提供判断路径。材料越多,决策越慢。我的系统试图反过来做一件事:让问题一进来,就先被送到合适的分析框架里。
这已经不是笔记系统了。
这是决策系统。
第八层:系统底层
- 99_System/:模板、提示词、系统文件。
- CLAUDE.md、AGENTS.md:运行规则、目录约定、写作要求、工作流程。
- 对话历史.md:会话索引和连续上下文。
这层像操作系统内核。
它决定 AI 进入这个 vault 以后,先读什么、怎么读、写到哪、什么时候更新任务清单、什么时候进项目、什么时候补情景记忆。没有这一层,AI 再强,也只是在一堆文件上随机发挥。有了这一层,AI 才开始真正变成系统的一部分,而不是一个外部聊天框。
第九层:自我模型与对话层
但真正让它从“系统”长成“外脑”的,还有一层。
就是自我模型与对话层。
第一条,是个人 Profile。
系统里专门有 70_Profile/Profile.md。这不是一份静态简历备份,而是一份持续生效的身份上下文。它知道我的职业主线、稳定能力标签、代表经历、优势、短板和对外叙事方式。
只有这样,它在帮我判断选题、项目、表达方向和职业动作的时候,才不会像一个平均用力的通用助手,而是会围绕我的长期身份做路由。什么东西更贴近“AI + 工作流 + 产品机制”的主线,什么东西只是短期热闹,它会更容易判断。
第二条,是会话历史。
我越来越喜欢和第二大脑聊天,不是因为聊天显得高级,而是因为对话本身就是认知加工。很多想法在脑子里只是感觉,一旦进了对话,就必须变成问题;很多问题原来只是混乱,一旦进了对话,就会被逼着拆成主线、假设、约束和动作。对话历史.md 和情景记忆一起,把这些连续思考留下来。
于是我不是每次都从零开始想,而是在和自己过去的判断继续对话。
这一层如果再往高一点说,本质上是在外接“叙事自我”。人不是靠一堆孤立任务活着的,人靠的是一个跨时间的自我解释系统。
Profile 和连续对话把这条主线接住以后,第二大脑就不再只是帮我记住过去,它开始帮我维持自我连续性。
所以第二大脑的终局,根本不是更全的笔记库。
而是一个可更新的数字化自我模型。
一旦 Profile、项目、daily-task、研究、风格、会话历史被接到一起,系统开始知道的就不再只是“你写过什么”,而是“什么对现在的你重要”“什么和你的长期主线一致”“什么只是高刺激但低价值的偏移”。这时候它才真正从资料库,升级成了外脑。
这套系统真正牛逼的地方,不是功能多
而是它做对了五件很少有人一起做对的事。
1. 它不是知识管理系统,而是行动路由系统
这可能是最大的分水岭。
很多系统都能帮你记住。
能帮你推进的,很少。
我以前写过一句话:仓库负责安慰你,回路才负责推进你。现在我越来越确定,这就是第二大脑最核心的区别。你不是缺一个会存的系统,你是缺一个让高价值信息有默认下一跳的系统。
2. 它不是“会写”的 AI 系统,而是“会接”的 AI 系统
我一直很警惕一件事:把 AI 直接放在写作层。
因为写作层本质上是判断压缩层。那里最值钱的,不是字句,而是你到底看见了什么、删掉了什么、站在哪一边。AI 真正该放大的,不是代写,而是系统层:帮你记住上下文、回看历史判断、提取素材、提示路由、生成候选、补充研究、准备分发。
这也是这套系统的护城河之一。
AI 在这里不是取代你的大脑。
而是在给你的大脑搭轨道。
比如晨报这件事就很典型。它不是简单把“今天有什么新闻”列给我,也不是只把“今天该做什么”单独列给我。它会先跑多源信息抓取,然后生成一份可读性很强的html给我,再跑启动第二大脑,最后把“今天最值得推进的事”和“今天最值得写的题”汇总到一起。这样我早上看到的不是一堆孤立信息,而是一块已经初步对齐了现实信号和个人主线的行动面板。
所以 AI 在这里最重要的能力,不是生成,而是编排。
不是替我完成表达,而是替我维持上下文、压缩信息、提示冲突、准备候选、降低启动成本。
更高一层说,AI 在这里承担的不是“智能体”神话,而是认知基础设施里的调度角色。它不必比我更像我,也不必替我做最终判断。它最有价值的地方,在于能用比人脑更稳定的方式处理那些低杠杆但高摩擦的工作:上下文重建、候选生成、历史回看、规则提醒、冲突暴露、默认路径提示。一旦这些摩擦被削掉,人类判断的质量才有可能被释放出来。
3. 它不是只服务创作,还在往业务系统长
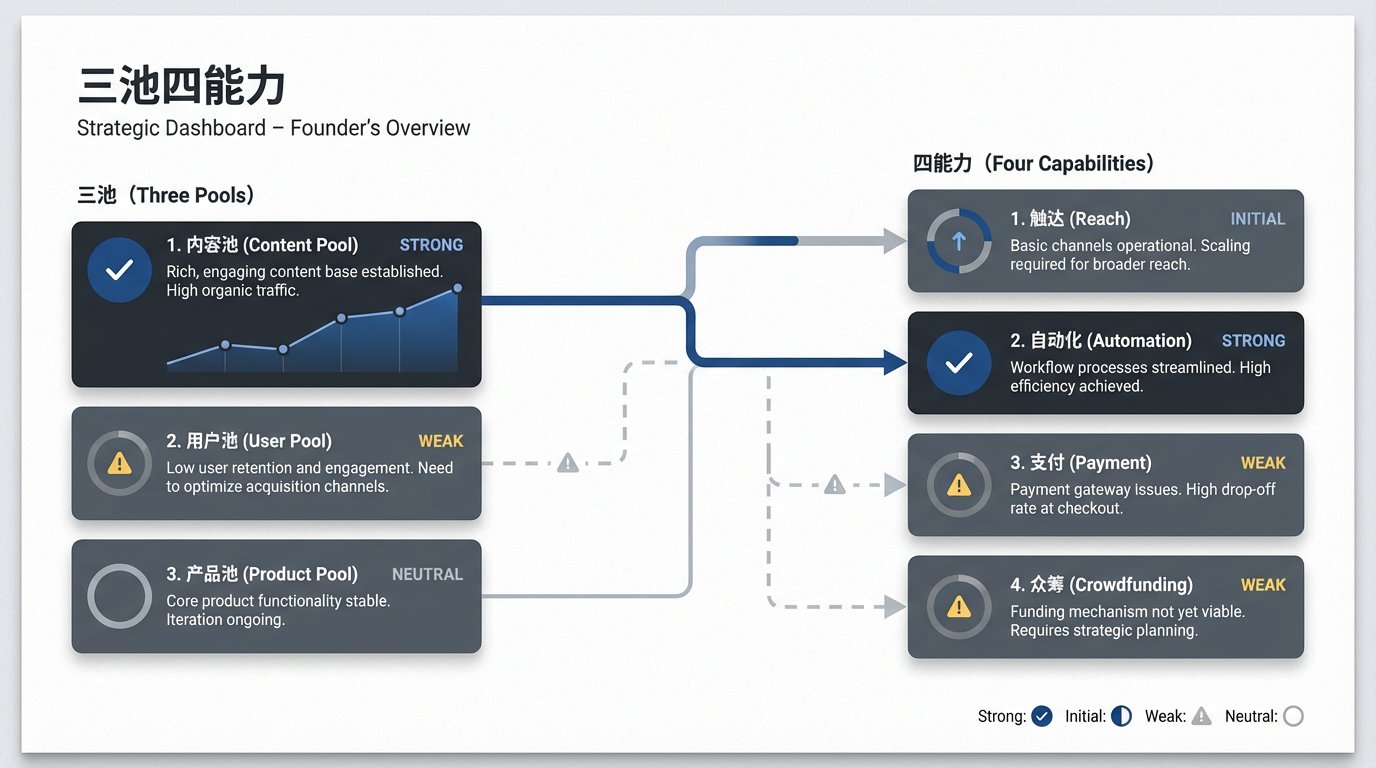
它明确写了当前这套系统最强的是内容池和自动化能力,触达能力初通,但用户池、支付能力、众筹能力还弱。
这种诚实反而让系统更强。因为真正成熟的系统,不是幻想自己已经完美,而是知道自己哪一段已经跑通,哪一段还没接上。
它已经不只是第二大脑。
它在往个人业务操作系统长。
而且这个“个人”不是空的。
它真的已经把我的人接进去了。
系统知道我的 Profile,知道我当前主定位是产品经理 / AI 产品经理,知道我最近的长期方向是 AI 工作流、用户画像、策略机制和产品落地,知道我今天的 daily-task 是什么,知道我最近同时还在做Fishh、内容系统和 X 管线。于是它服务的不是一个抽象创作者,而是此刻这个具体的人。
这就是为什么我会说,它已经不是“帮我写文章的工具”。
它真的开始像外置大脑。
最强的反对意见,我先替你吃掉
写到这里,很多人会有三个很自然的反驳。
第一个反驳是:这不就是 Obsidian 加一点 prompt,加一点脚本吗?
如果你只看表层,确实像。
但真正的差别从来不在工具名字,而在控制关系。普通做法是把工具堆在一起,希望自己以后会用。真正的系统做法是先定义信息如何进入、如何升级、如何进入任务、如何进入选题、如何进入发布、如何回写经验。前者是工具集合,后者是控制平面。你把同样一套工具给两个人,一个人会搭出仓库,一个人会搭出外脑,差别就在这里。
第二个反驳是:系统这么复杂,不会反而增加负担吗?
会。
如果它只是多了很多目录、多了很多规则、多了很多你根本不会走的流程,它一定会反噬你。所以真正的关键不是“功能多”,而是默认路线足够清楚。网页默认去哪,新闻默认怎么走,高价值输入默认下一跳去哪,时间意图默认怎么进任务清单,早上默认先看什么,晚上默认怎么回写。复杂系统不可怕,可怕的是没有默认路径。只要默认路径稳定,复杂性就会被折叠到后台。
更准确一点说,复杂性本来就不会消失。
它只会转移。
你不把复杂性放进系统设计里,它就会回到你的脑子里,变成犹豫、拖延、反复重来和临场崩溃。高水平系统不是消灭复杂性,而是把复杂性从前台用户脑内,转移到后台默认规则。
第三个反驳是:你把 AI 和第二大脑接这么深,不会越来越失去自己的判断吗?
这恰恰取决于你把 AI 放在哪一层。
如果你把 AI 放在写作层,让它直接替你下判断、替你组织观点、替你说话,你当然会越来越平均,越来越没有自己。但如果你把 AI 放在系统层,让它帮你维持上下文、提示冲突、发现信号、生成候选、回看历史偏差、准备分发,你得到的不是判断外包,而是判断增幅。它替你扛掉的是低杠杆的摩擦,不是高杠杆的立场。
这就是这套系统最关键的边界感。
它不替我成为我。
它只让我更稳定地做我。
这句话其实比前面所有功能都重要。
因为未来真正拉开差距的,不是谁先拥有更多 AI,而是谁先拥有自己的认知基础设施。一个没有外脑治理层的人,最后会越来越像平台和模型的租户;一个拥有自己控制平面的人,才有可能把 AI 变成自己长期复利的一部分。
再往上一层,是多顾问 Agent,不是超级 Agent
这里Jaden老师的这篇文章给了我很多启发(很棒的文章推荐阅读):
📝 德鲁克管业务,芒格看决策,乔布斯做产品,马斯克推执行——全跑在我的系统里
我做了一件有点荒诞、但越用越觉得对的事: 把6位我最尊敬的人,装进了我的工作系统。 他们各司其职,各有专长。每次我在对应领域要做决策,我都会先问问他们。 01 商务增长顾问:彼得·德鲁克(Peter Drucker)...

如果说前面这些层,解决的是“记忆、判断、执行、分发”的骨架问题,那真正把这套系统从“能用”拉到“很强”的,就是顾问层。
我做了一件看起来有点荒诞,但越用越觉得对的事:把六位牛人,装进系统里,让他们各司其职,不越界,不重叠。每次我在对应领域要做决策,我都会先让他们过一遍。底层的决策工具箱、任务系统、项目系统、风格系统负责给出骨架,这六位顾问负责在关键节点把判断抬高、把废动作砍掉、把真正该推进的东西往前推。
我是这样设计的:
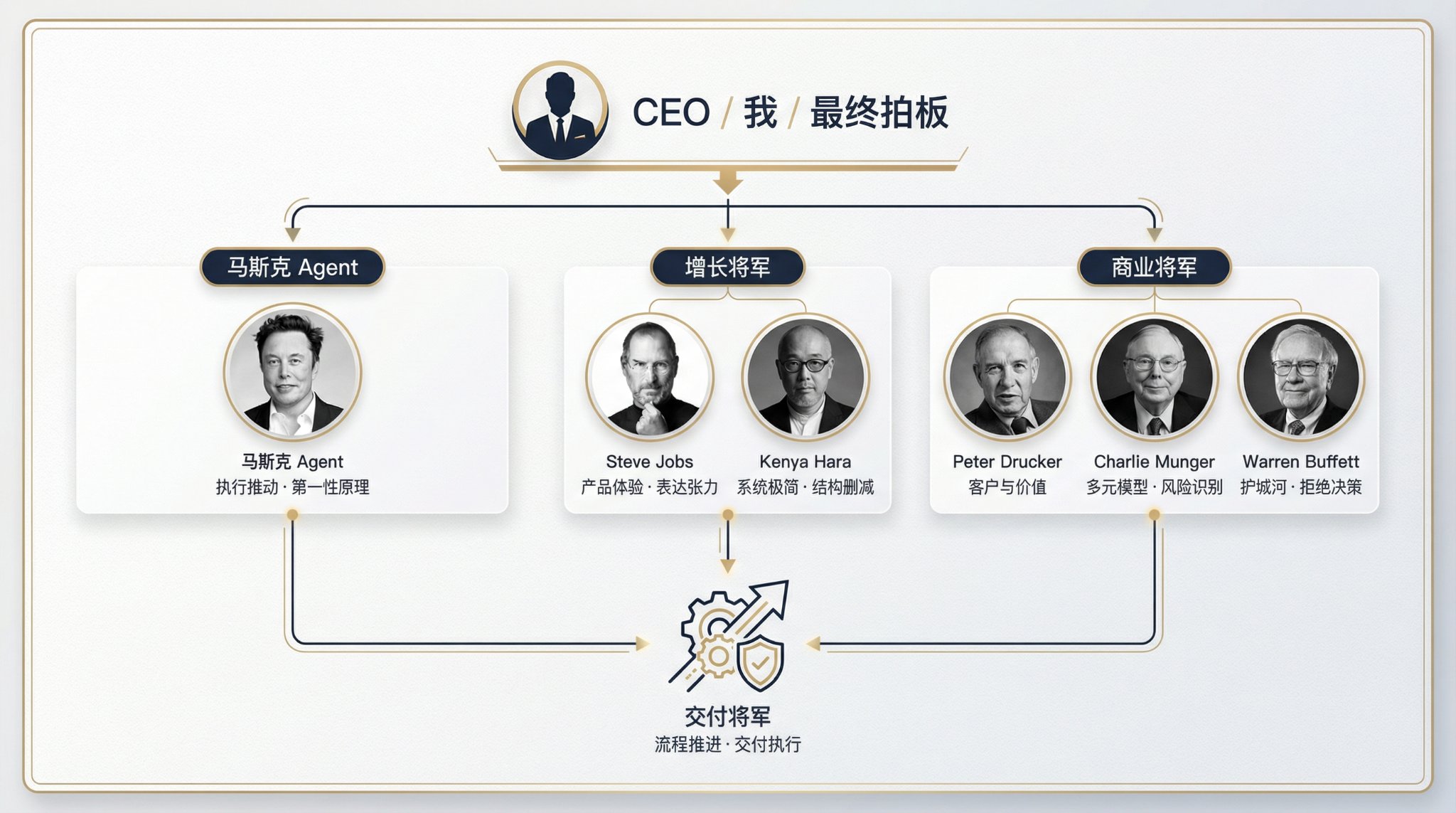
这六位顾问,每个人都不只是一个“语气模仿器”。
他们应该各自带着三个东西进入系统:
- 一个专属提问框架
- 一个专属决策领域
- 一个专属刹车机制
比如德鲁克,负责的不是“讲战略黑话”,而是先问死两个问题:你的客户是谁?你在为他们创造什么价值?如果一篇文章、一个功能、一个服务,连这两个问题都答不清,它就应该死在这里。
乔布斯负责的不是“审美点评”,而是体验的残忍标准。他会逼你回答:这是不是现在能给出的最好体验,还是只是能用?很多中等水平的内容和产品,不是死在没做出来,而是死在“差不多就行”。
原研哉负责的不是“好看”,而是结构极简。他最有价值的问题是:这个东西,有必要存在吗?一个文件夹、一个流程、一个模块、一个页面,存在到底是在降低系统复杂度,还是只是在制造新的维护成本?
芒格负责的是把单一视角拆烂。一个重大决策,不能只从“我感觉”或者“市场在聊”去看,至少要从心理学、经济学、激励机制、机会成本、系统耦合里拉几个角度交叉验证。
巴菲特负责的是拒绝。他要问的不是“这是不是新机会”,而是“这会不会伤害你的主线,你有没有护城河,你是不是只是又被趋势吓到了”。很多人缺的不是机会,缺的是过滤器。
马斯克负责的是最后那脚油门。他的作用不是让你兴奋,而是逼你面对真实约束:这件事为什么还没开始?限制到底是真的,还是你自己编出来拖延自己的?前面五位负责想清楚,马斯克负责不让你无限准备。
这样一来,这套系统就不只是一个记忆库。
它开始长出董事会。
这套系统到底是怎么跑起来的
如果你把这整件事想象成一句“我用 Obsidian 管内容”,你会完全低估它。
真正让它跑起来的,是下面这条链:
外部输入进 00_Inbox/ 和 50_Resources/。
网页和帖子先通过 Obsidian Web Clipper 进入 00_Inbox/ 或 50_Resources/Imported/。
每日新闻先走“结构化发现层 + Daily_Pulse + Daily_Radar HTML + 一手验证 + topic seeds”的混合路线。
高价值内容进入 记忆库/、30_Research/、20_Projects/。
带时间意图的东西进入 任务清单.md。
个人身份上下文和职业主线持续由 70_Profile/ 提供背景。
每天通过 10_Daily/ 和 start-my-day 定义主线、删掉噪音。
研究通过 02_Drafts/、03_X/、04_Images/ 进入内容表达层。
表达通过 06_Workflows/ 和 Browser 发布准备进入市场。
市场反馈、用户反馈、写作反馈,再回写进 情景记忆、语义记忆、强制规则、evolution_log。
这也是为什么这套系统不是“我一个人在硬撑”。
它已经开始像一个真正的认知组织。
这就是为什么它会越来越像一个活系统。
不是因为它文件多。
而是因为它会回流。
很多人系统越搭越死,是因为信息只进不出,或者出了也不回。我的目标恰恰相反:让每一次输入、每一次输出、每一次犯错、每一次成交线索,都能变成下一轮更低摩擦、更高质量的起点。
如果把这条链再展开一点,你会更明白它为什么不像仓库,像外脑。
早上,系统先用晨报把“今天外部世界发生了什么”和“我今天最该推进什么”对齐。
白天,网页、帖子、灵感和长文通过 Clipper 进入前门,不直接污染输出层。
进入系统后的高价值输入,会被分流到研究、项目、任务、选题和草稿,而不是在收纳层无限期停留。
写作时,系统会调 Profile、风格约束、历史会话、研究笔记和 topic seeds,一起参与这次表达。
准备发布时,X 管线和Browser负责把内容推到市场,但人工审核保留最后拍板。
发布之后,表现、反馈、踩坑和新的判断,再继续回到情景记忆、语义记忆和 evolution log。
这套东西最强的地方,不是每一层都很聪明。
而是层和层之间没有断。
这也是为什么我现在越来越不把它看成“第二大脑技巧”。
它更像一套私人认知机构。
记忆库像档案馆,语义层像研究部,强制规则像制度层,daily-task 像执行办公室,晨报像早会系统,新闻混合源像情报系统,Profile 和对话历史像身份与战略部,多顾问 Agent 像董事会。你一个人当然还是那个你,但你的认知已经不再只是生物脑裸奔,而是开始有组织形态了。
这就是真正的飞轮。
不是多记。
是少重来。
最后说一句最重要的
如果你真想搭第二大脑,可以直接把这篇文章发给你的ClaudeCOde。
它会开始帮你判断,帮你过滤,帮你推进,帮你拒绝,最后帮你把一个人的认知边界,慢慢外接成一套可复用、可进化、可交付的系统。
那时候,你就不是在用一个笔记软件了。
你是在经营自己的认知主权。