
警告:建完这个Karpathy知识系统后,你会彻底告别信息焦虑

最终的数据是沉淀在飞书多维表和飞书文档当中,如果需要打通本地和云端的数据,Karpathy的知识库逻辑一定是宇宙超强第二大脑外挂。
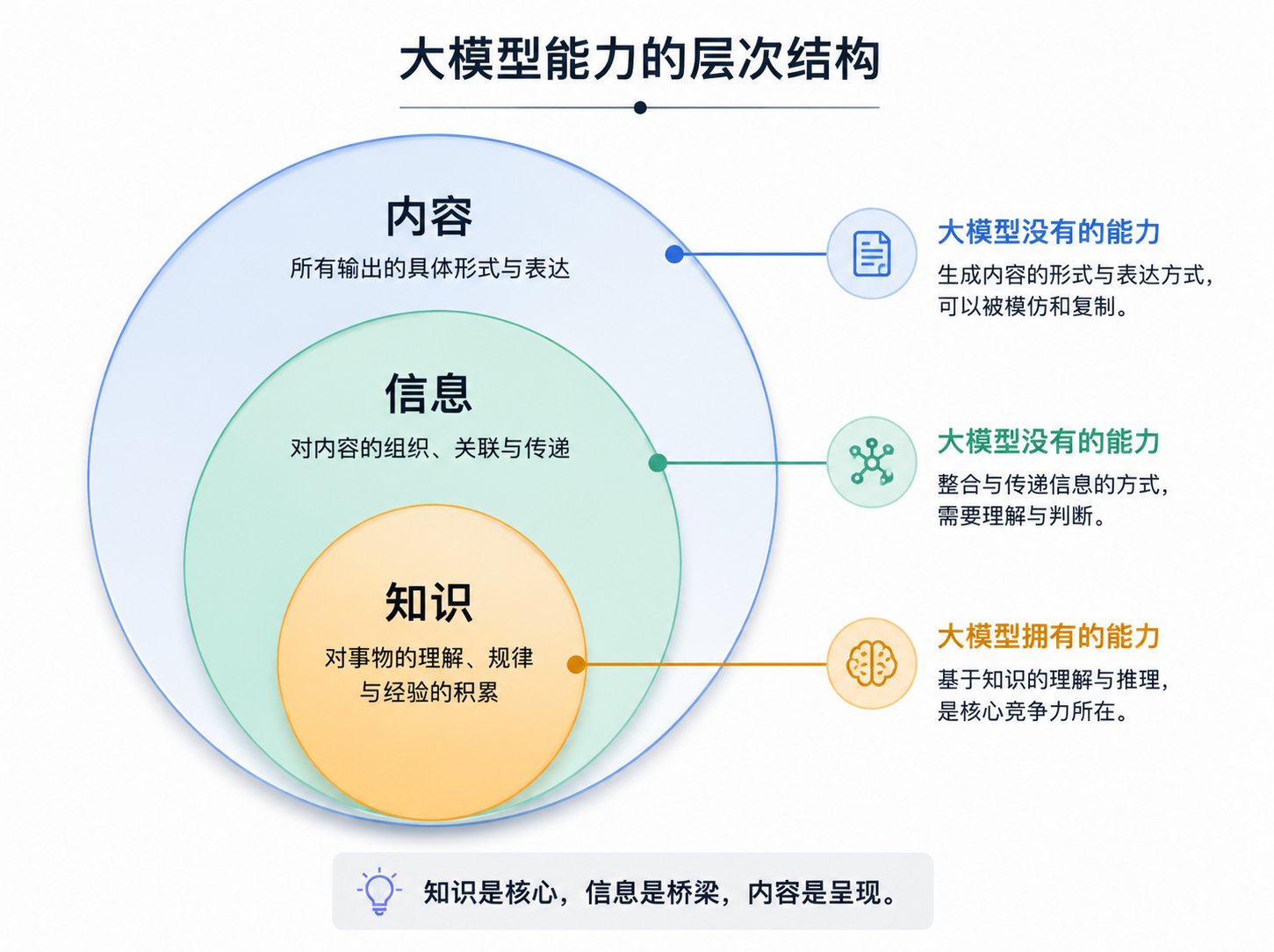
在搭建知识库前,我想有必要区分下内容、信息、知识这3个概念。
在当下大模型快速发展、能力逐渐趋同的背景下,模型本身越来越像「底层算力」,而真正拉开差距的,是谁能把「内容 → 信息 → 知识」这条链路打通,并沉淀成属于自己的知识基座。
先上结论
- 内容(Content):呈现出来的“东西”本身,是载体。
- 信息(Information):从内容里“读出来的、有意义的差异”。
- 知识(Knowledge):被验证、可复用的规律和共识。
举个栗子🌰
第一层:内容层(Content)
- 最大的那一圈:
所有被制作出来的文字、图片、音视频,统统叫内容 - 对创作者来说:
你首先是在「生产内容」
第二层:信息层(Information)
- 从内容中「读」出来的有用事实:
一份简历 → 读到:教育背景、工作经历、技能标签
一条新闻 → 读到:发生了什么、谁参与、时间地点 - 同一份内容,不同人能提取出不同信息
- 信息是否有价值,取决于:对当前决策是否有帮助
第三层:知识层(Knowledge)
- 在大量信息之上,进行:
归纳 → 抽象 → 验证 → 形成规律、模型、方法论 - 知识可以迁移、可以教学、可以形成系统化表达
用一句易懂的话总结:
内容是外壳, 信息是内容里那一点「有用的具体事实」, 知识是从无数信息中归纳出的「可复用的规律」。
知识系统
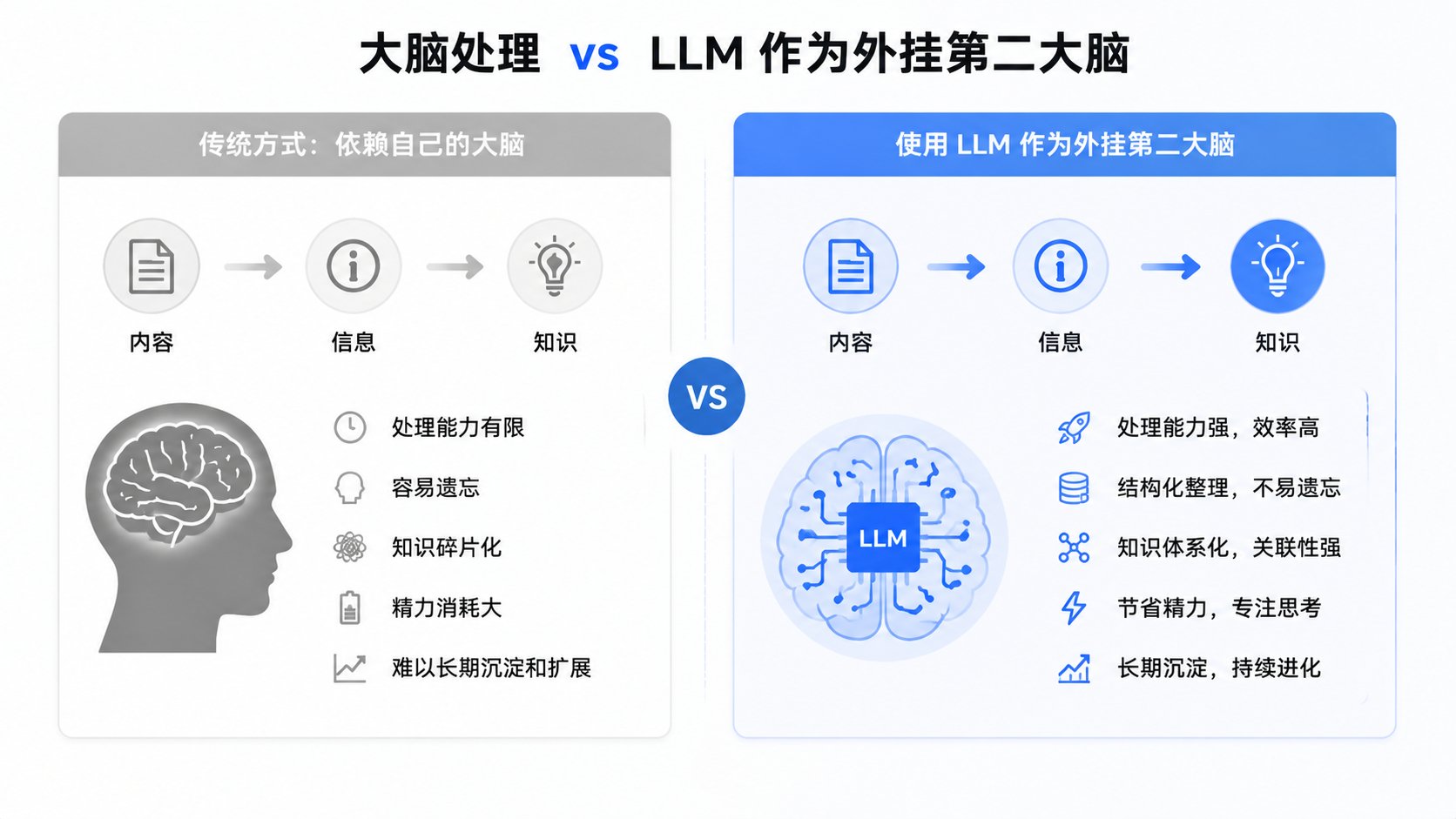
简单来说,知识系统就是一个「内容 → 信息 → 知识」的提炼与沉淀过程。在 AI 出现之前,这个过程完全依赖我们的头脑🧠去处理和整合。而 Karpathy 的方法,则提供了一个完美方案:用 LLM 作为外挂,让你的第二大脑高效运转。
知识系统搭建方式
三个核心结论:
第一,用 Obsidian 加 Claude Code/Codex 搭建 LLM Wiki,知识自动收录、自动生成卡片、一键输出文章。
第二,所有内容本地存储,不依赖任何大模型账户的稳定性,你的知识永久属于你。
第三,碎片内容持续收录,知识库越用越厚,后续调取和创作效率指数级提升。
问题来了,这套系统到底怎么运作的?
这是个案例:收录两篇卡兹克的文章后,要求输出关于卡兹克的相关内容:
GIF
具体搭建步骤
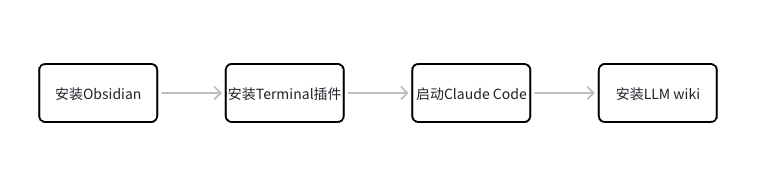
1️⃣ 安装Obsidian,搜索官网即可,暂略
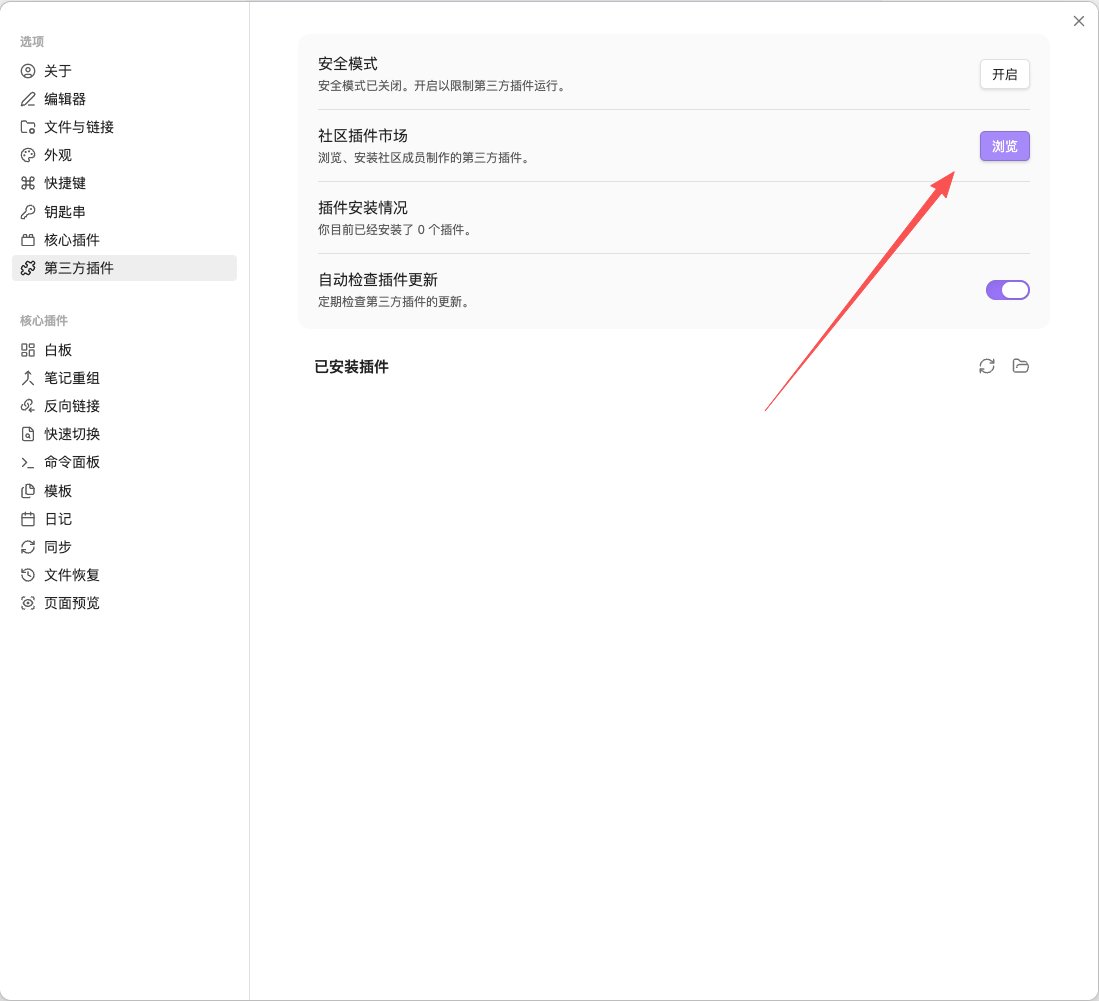
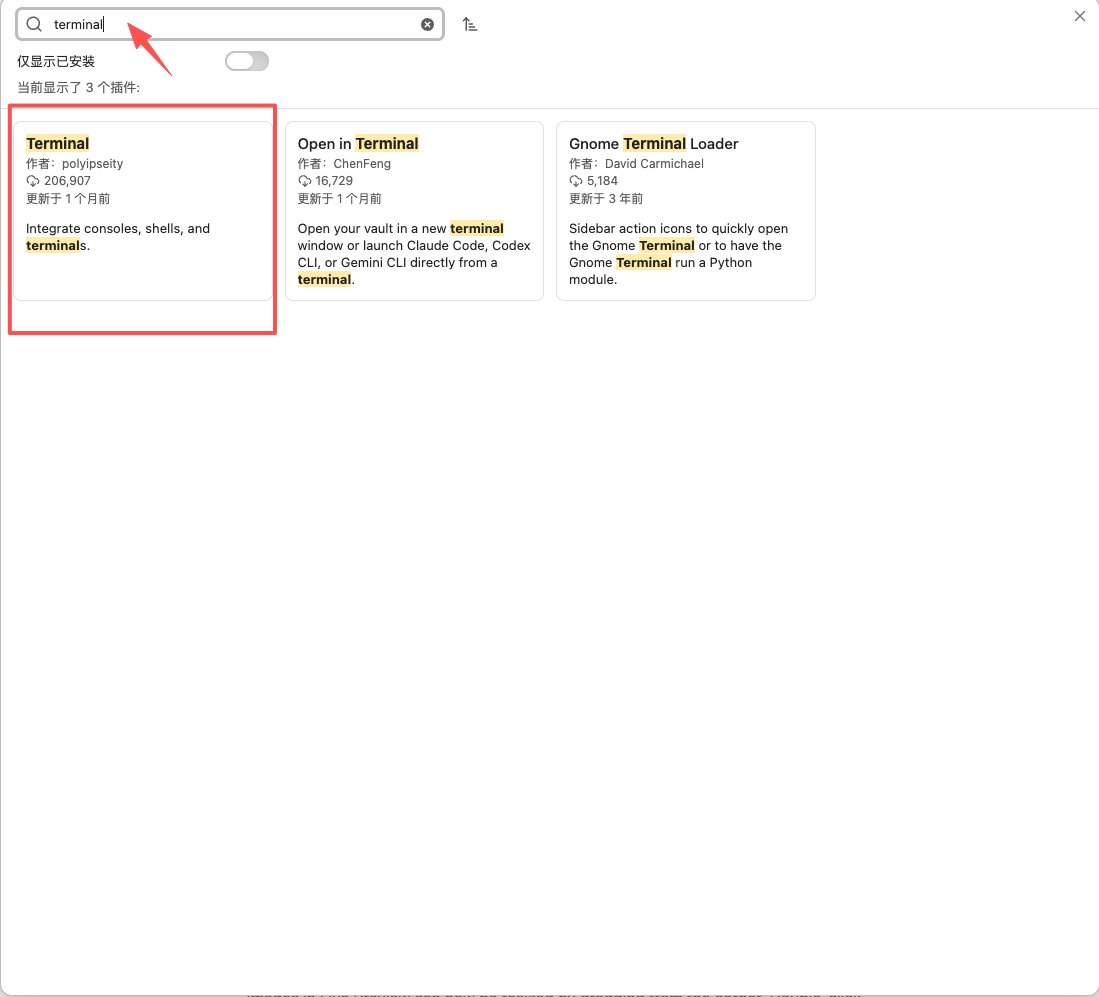
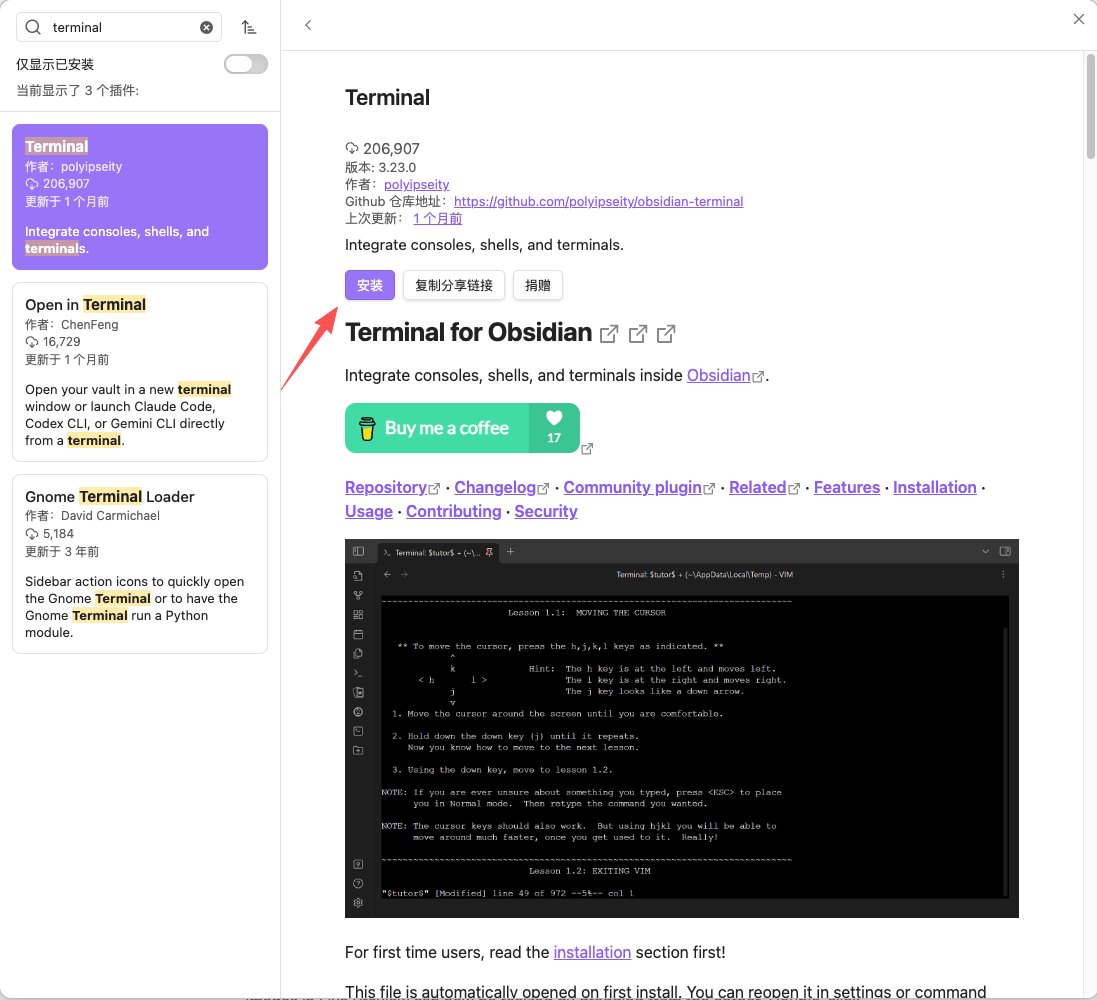
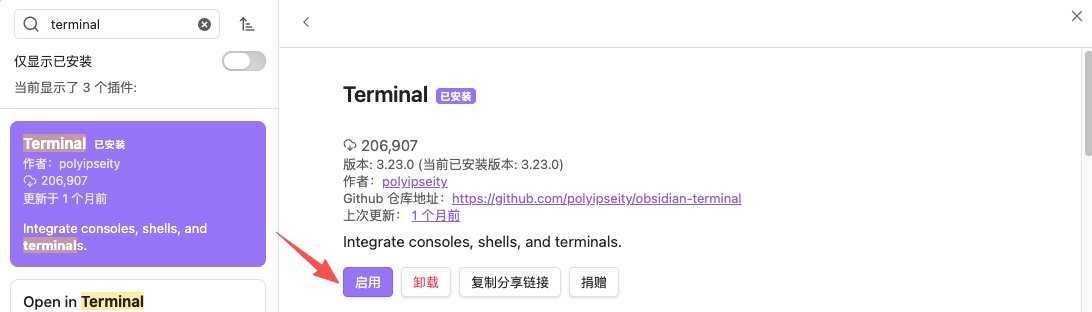
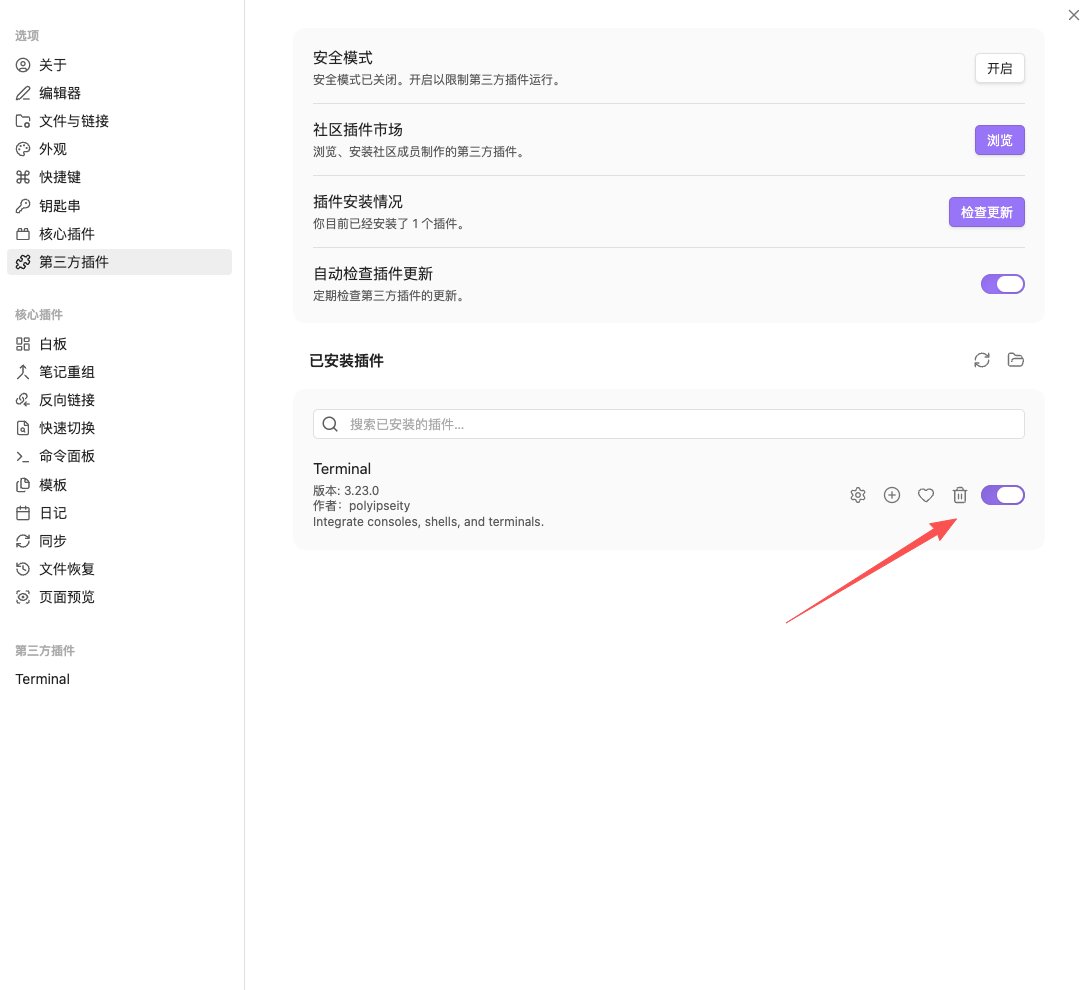
2️⃣ 安装Terminal插件,即在Obsidian的界面中驱动LLM用p
设置——第三方插件——社区插件市场——搜索“Terminal”——安装——启用
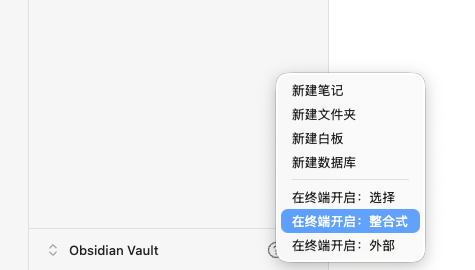
3️⃣ 在Terminal中启动Claude Code
🖱鼠标右键——在终端开启:整合式——启动Claude(需提前安装,可参照
卡兹克:从0开始,在国内用上Claude Code的终极保姆教程来了。)
GIF
4️⃣ 安装LLM wiki的系统
安装 github.com/AgriciDaniel/claude-obsidian
GIF
安装好后,可能会提示安装一些辅助插件
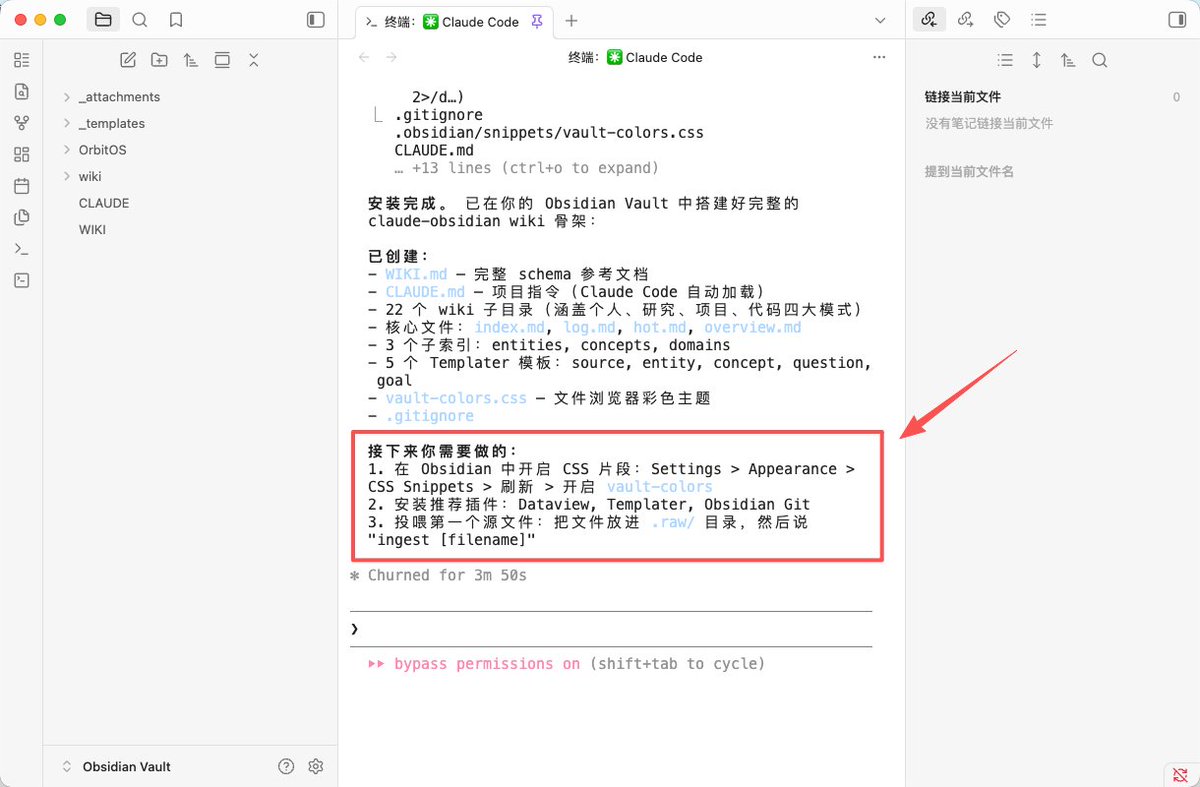
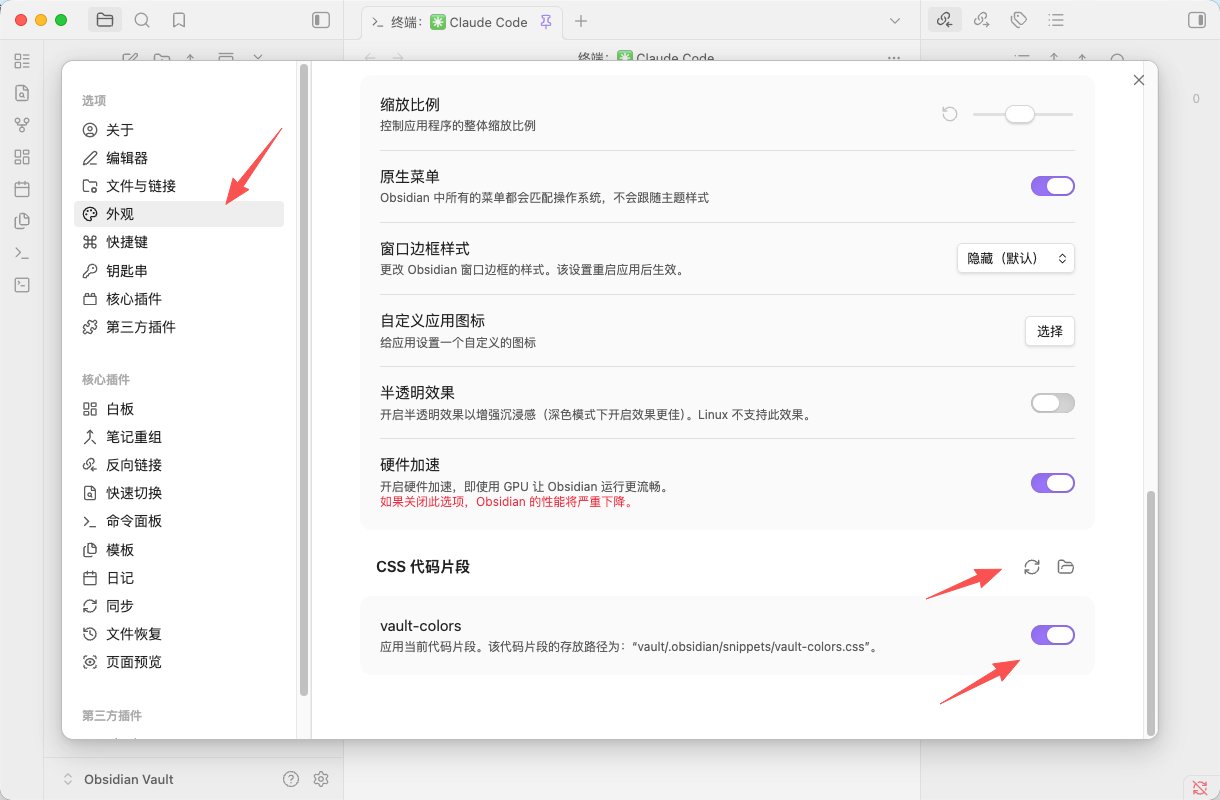
Dataview, Templater, Obsidian Gi
信息收录过程
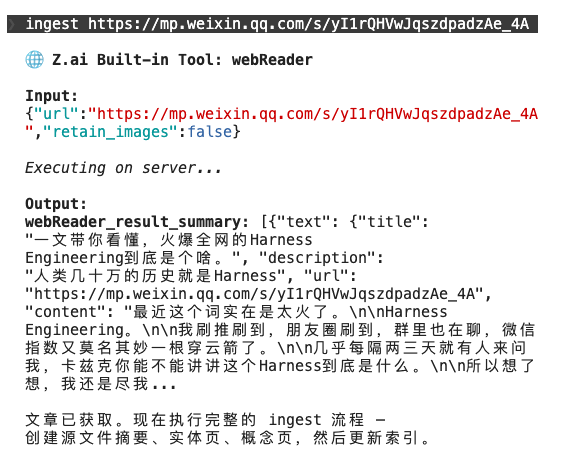
1、输入信息源文章
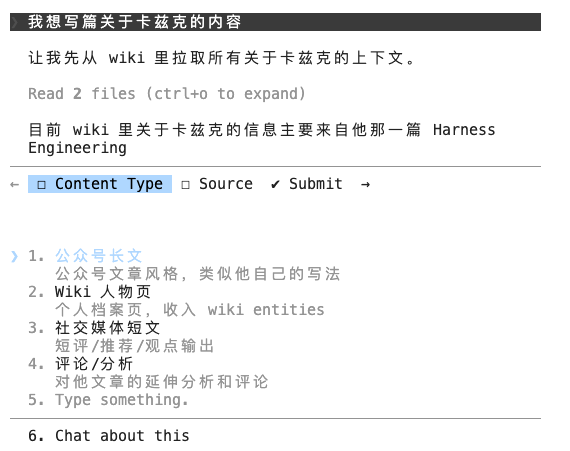
2、给出输出需求
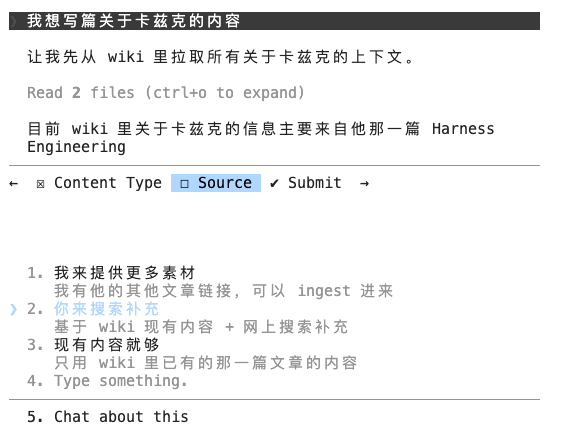
3、写好的文章会存档在Obsidian本地
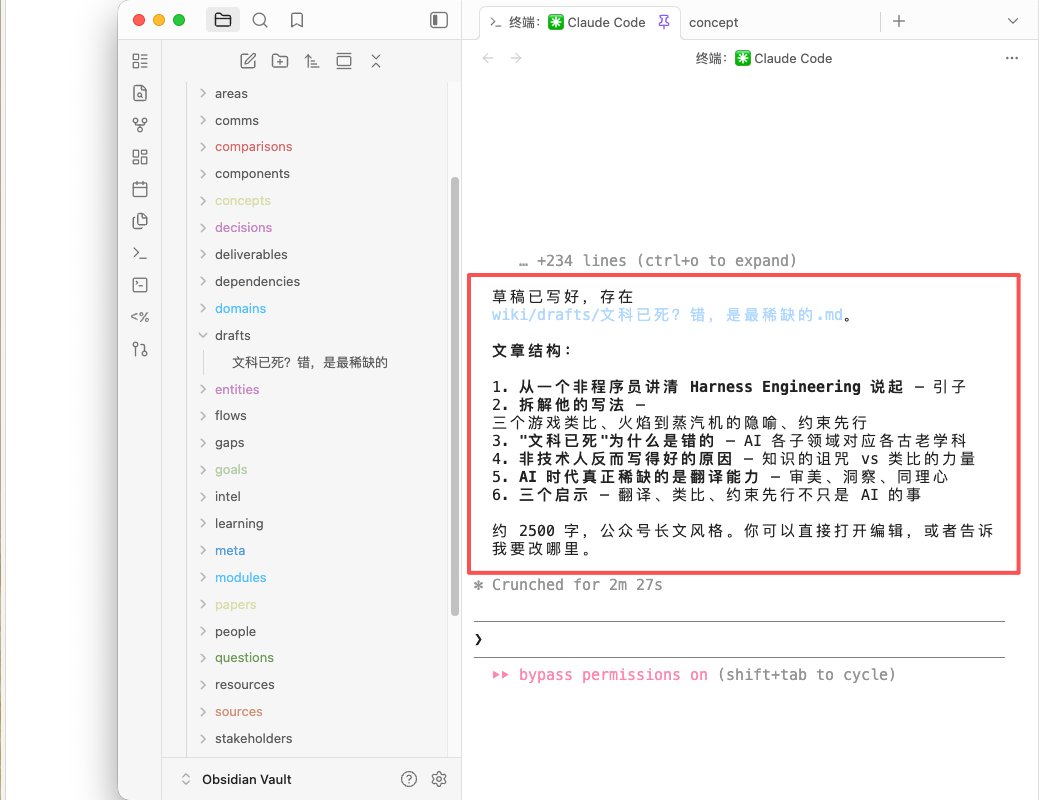
最后说一句
知识管理最大的误区是花太多时间在工具选择上,太少时间在持续输入上。
工具不重要,流程才重要。有一个稳定的、可重复的流程,哪怕工具简陋,也比收藏了 100 个 app 但从来不用强。
这套系统的核心不是某个具体工具,而是那个从收录到连接到输出的闭环。只要你建立起了这个闭环,用什么工具都能跑通。