
大多数人的第二大脑,最大的问题不是记得少,是根本没有动作回路
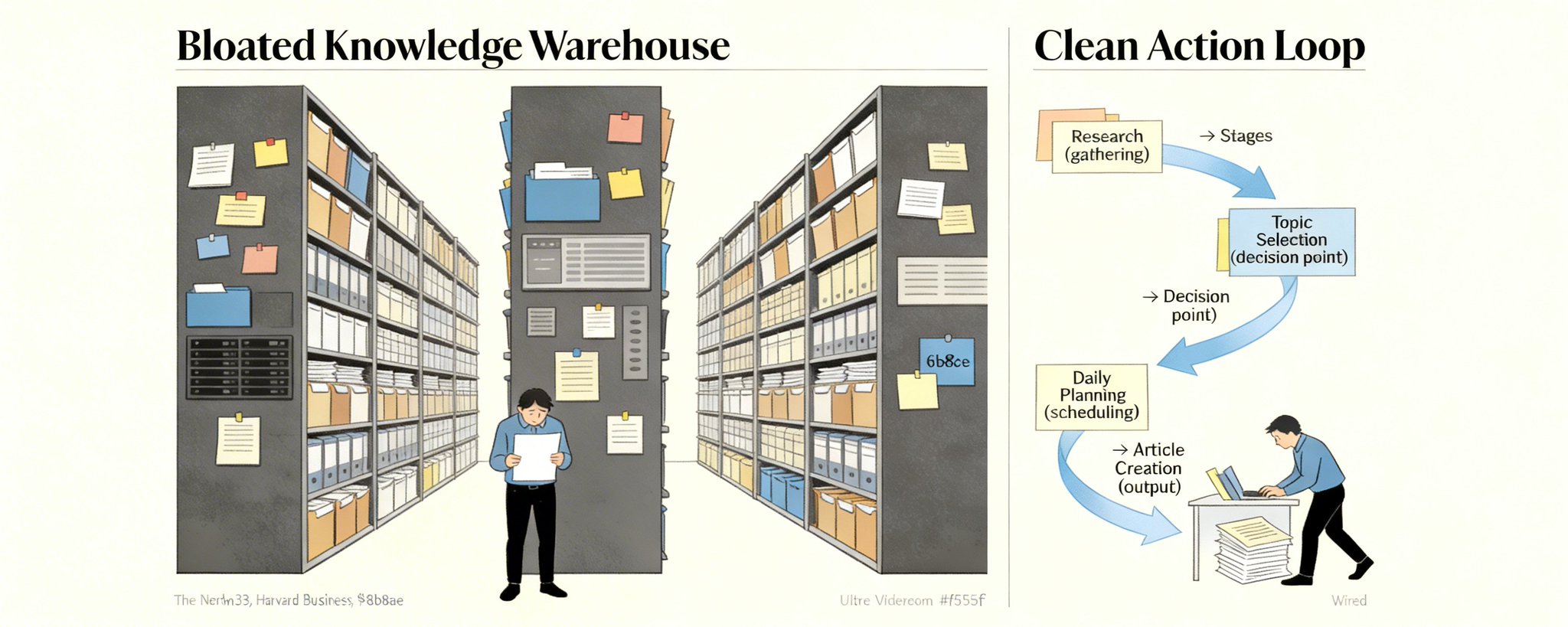
很多人的第二大脑,根本不是大脑,只是一个高级仓库。
收藏在涨,标签在涨,文件夹在涨,只有结果不涨。
真到写文章、做选题、准备分享,还是从头搜、从头想、从头焦虑。问题不在于你记得少,而在于你的系统只负责收纳,却不负责让内容继续流向决策和交付。
这件事对内容创作者尤其致命,因为创作不是输入竞赛,是转化竞赛。你存了很多爆款拆解,写标题时还是临场乱猜。你记了很多判断,发文时还是靠刷 timeline 找灵感;你开了研究区、wiki 区、素材区,真正要交付的时候,还是新建一个空白文档从零开始。
表面上你在做知识管理,实际上你在做一件更隐蔽的事:把“我已经存下来了”误以为“我以后一定调得出来”。
这里面第一个陷阱,是伪增长幻觉。
收藏、摘录、分类这些动作之所以容易上瘾,不是因为它们最有价值,而是因为它们最安全。输入不会被市场打脸,归档不会暴露你判断不够,整理还会立刻给你一种“今天没白忙”的安慰。
真正困难的动作恰恰相反。写作要承担选择,发布要承担暴露,交付要承担结果。所以很多人会不自觉地往低风险动作里滑:研究半天,不发布;整理半天,不决策;搭系统半天,不交付。系统没有提升产出,只是在更精致地延迟行动。
第二个问题,不是记忆量不够,而是调用能力太弱。
很多人把存量理解成“我收集过多少资料”,这其实是仓储思维,不是生产思维。对创作者来说,真正的存量不是文件数量,不是标签密度,而是那些能在关键节点被调出来、被重组、被压缩成新结果的判断、案例、模板和半成品。被存下来的内容,不会自动变成资产。
只有反复改变过结果的内容,才配叫资产。一句判断,今天能变题目,下周能变提纲,下个月还能进入一次产品说明,它才开始产生复利。
不会调用的人,永远都在重新开始。
但调用能力还不是最底层的问题。更底层的问题是,很多人的第二大脑从设计上就没有动作回路。前一个问题说的是旧内容能不能再次出场,这一个问题说的是新内容进来之后,有没有明确下一跳。两者不是一回事。调用能力弱,你会反复从零开始;动作回路缺失,你连“从哪里继续”都不知道。
我不是说笔记系统要替你执行。执行当然要落到任务系统、日程、发布动作上。问题在于,如果一条高价值输入在进入系统的那一刻,没有被明确路由进任务、选题、研究或发布准备,它就会停在收纳层,永远进不了结果层。这样的系统整理得再漂亮,本质上也只是库存管理。它回答的是“放哪儿”,不是“接下来去哪儿”。
比如你记下一句判断:“AI 写作工具最大的价值不是提效,是降低持续输出的启动成本。”如果它只躺在笔记里,它只是资料;如果它先进入研究,再变成选题,最后进入周更文章和产品文案,它才开始替你省时间、替你赚钱、替你形成风格。第二大脑最值钱的,不是帮你记住这句话,而是让这句话在不同场景里反复再出场。
所以对创作者来说,真正该优化的不是记录量,而是转化率。一套能打的第二大脑,至少要完成四次压缩:
信息变判断,判断进任务或选题,任务推动交付,交付再反哺新的判断。
只做到第一步,你在囤货。
做到后面三步,你才开始复利。
差别不在 Obsidian,不在 AI,也不在模板。差别在于,你有没有把系统从“记忆容器”改成“结果路由器”。
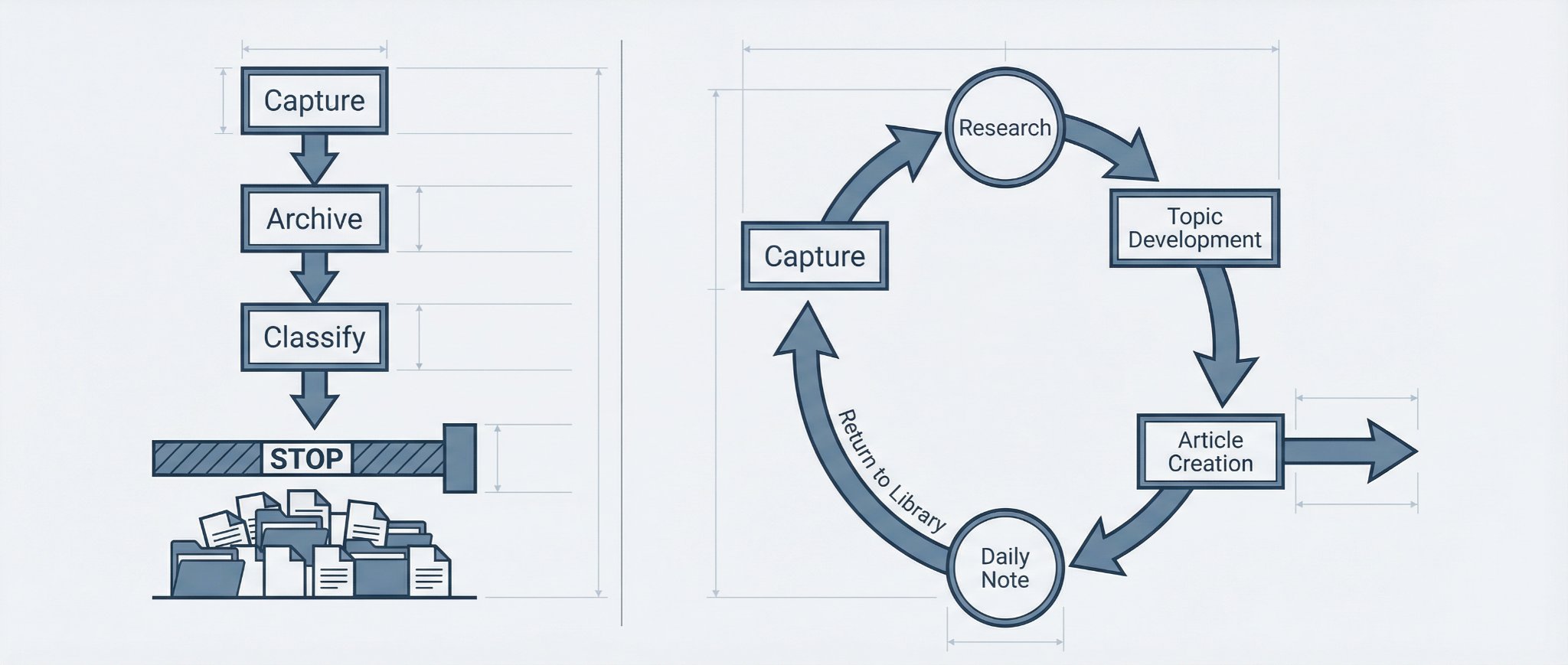
如果你想补回这个回路,不用先推倒重来,先做三件事就够了。
第一,只把能二次出场的内容算作存量。不能再次改变结果的收藏,不算资产,它最多算资料。
第二,给每条高价值输入一个默认路由。任务、选题、研究、发布准备,至少去一个;没有下一跳的内容,不允许只停在仓库。
第三,用旧东西产生了多少新结果来衡量系统,而不是用今天又记了多少来安慰自己。
看到过一句增长公式,很我觉得很适合放在这里。你的增量 = 可调用存量 × 有效动作。很多人的问题,不是没有积累,而是积累长期停在收纳层,动作长期接近于零。
你不是没有第二大脑,你只是搭了一个持续降低焦虑、却不提高产出的仓库。
仓库负责安慰你。
回路才负责推进你。