
我用 Obsidian + AI 搭了一套个人内容知识库:从安装到内容工作流完整教程

前段时间,我重新整理了一遍自己的资料。
里面有上千篇过去写过的文章,还有项目记录、聊天内容、网页收藏、AI 对话、选题、复盘和各种临时想法。
文件很多,但真到写文章的时候,还是经常找不到。
有些内容我明明写过,想不起来放在哪里;有些项目踩过坑,下一次又重新踩一遍;还有不少选题散落在几十个文档里,记完就再也没有打开。
我以前也用过不少笔记工具。它们解决了“把东西存进去”的问题,却没有解决另外几个更现实的问题:
1、资料进来以后放哪里?
2、原文、笔记和准备发布的文章怎么区分?
3、AI 怎么知道哪些能改,哪些不能动?
4、写新文章时,怎么让过去积累的资料真正参与进来?
5、换一个 AI 工具以后,这套系统还能不能继续用?
后来我用 Obsidian 管文件,再让 Codex、WorkBuddy 这类 Agent 直接操作知识库,才慢慢搭出现在这套系统。
它不是一个装满笔记的仓库。
它更像一个本地内容工作台:资料可以进来,AI 可以整理,人负责判断,最后还能继续产出文章。这篇我会从零开始,把安装、目录、规则、AI 接入和内容工作流全部拆开讲一遍。
如果你只想抄一个能马上使用的版本,照着前半部分操作就够了。后半部分是我自己用了一段时间后,逐渐补上的进阶做法。
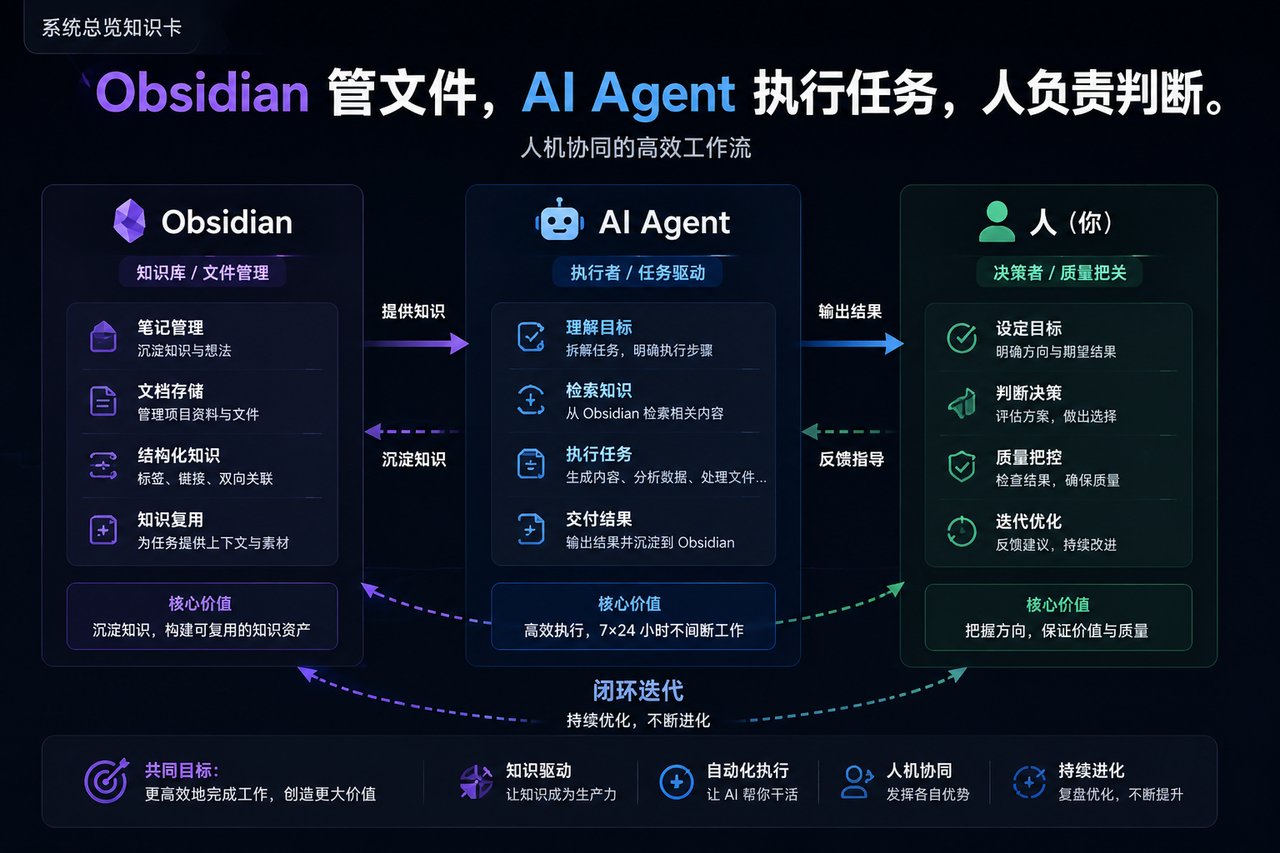
一、先说清楚:Obsidian 和 AI 各自负责什么
这套系统最容易被误解的地方,是把它当成“在 Obsidian 里装一个 AI 插件”。
我做的不是这个。
在我的系统里,Obsidian 和 AI 是两层:
Obsidian 是文件和知识层。文章、项目、素材、规则、日志,本质上都是本地 Markdown 文件。
即使某一天某个 AI 工具不能用了,这些文件仍然在我的电脑里,可以继续搜索、编辑和迁移。
Codex、WorkBuddy、TRAE 这类 Agent 是操作层。它们可以读取一个文件夹里的内容,根据规则搜索资料、修改 Markdown、创建文章、运行脚本、检查链接。
所以,真正重要的不是一定要用哪一个 AI,而是满足下面三个条件:
- 能打开或访问你的知识库目录;
- 能读取和修改本地 Markdown 文件;
- 能遵守项目里的长期规则。
我现在会用 Codex,也用过 WorkBuddy。你也可以换成 TRAE、Claude Code,或者其他具备本地文件操作能力的 Agent。
工具可以换,知识库的目录、规则和内容资产不要跟着工具一起换。## 二、第一步:安装 Obsidian,建立本地知识库
Obsidian 官网:obsidian.md/download
下载安装后,第一次打开会看到创建仓库的入口。Obsidian 把一个知识库文件夹叫作 Vault。
点击“创建新仓库”,给它起一个名字,再选择本地保存位置。
建议不要一开始放进层级很深的目录,也不要使用一个随时会被清理的临时文件夹。
创建完成后,你在 Obsidian 里写的每一篇笔记,其实都是这个文件夹里的 .md 文件。图片也是普通图片文件。
这也是我选择 Obsidian 的主要原因:
数据在本地;文件格式简单;不绑定某个笔记平台;AI 和脚本容易读取;Git、网盘和移动硬盘都可以备份。
三、第二步:搭建五层目录
很多知识库后来变乱,不是因为文件太多,而是不同性质的内容混在了一起。
收藏的外部文章、自己写的原稿、提炼出的观点、待发布文章和系统规则,全都放在同一层。时间一长,人和 AI 都不知道哪个才是可以相信的版本。
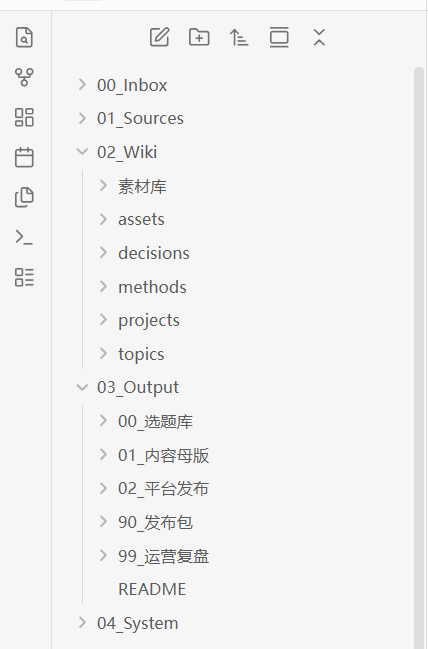
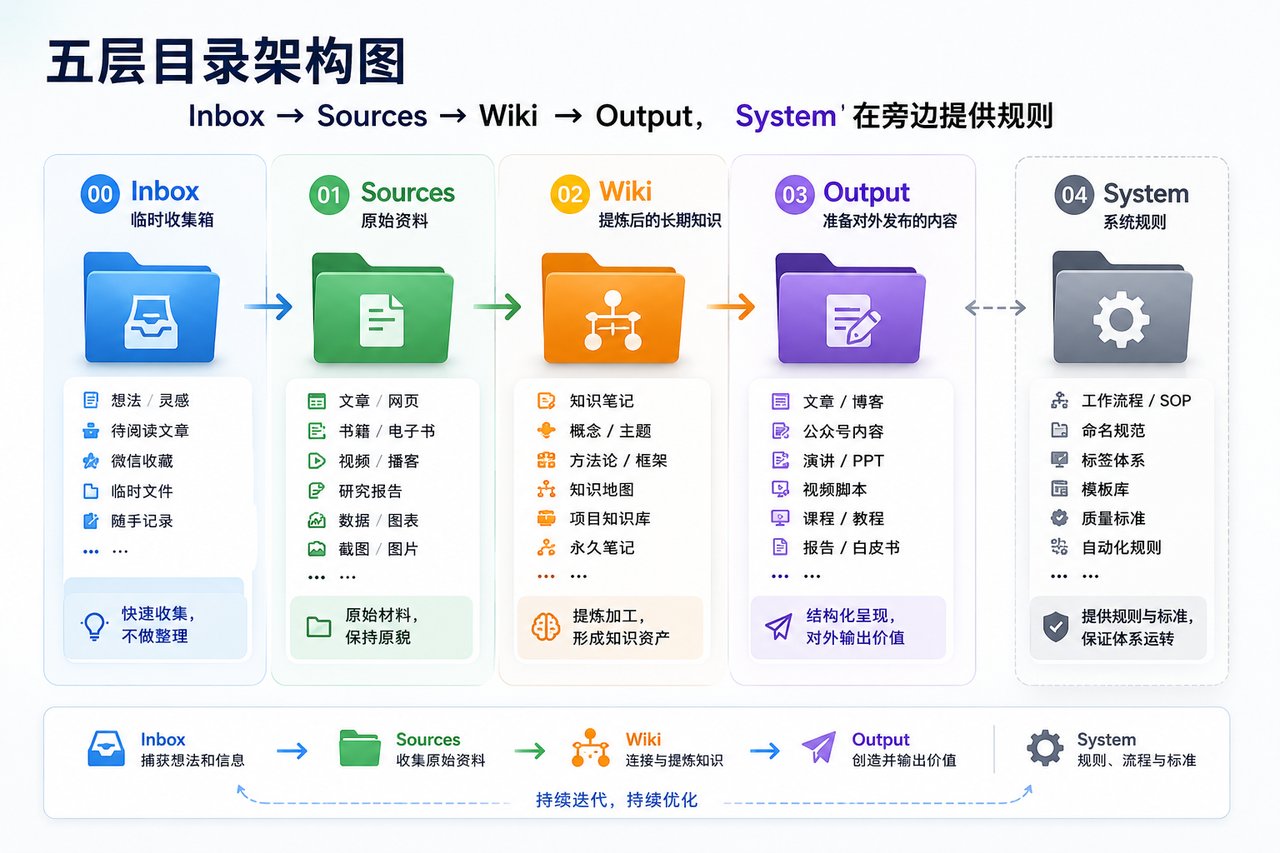
我现在使用的是下面五层结构:
00_Inbox/
01_Sources/
02_Wiki/
03_Output/
04_System/
00_Inbox:临时收集箱刚收进来、还没有判断放在哪里的内容,先放这里。
例如:一张截图;一段聊天记录;一个临时想法;刚导出的飞书文档;还没来得及处理的网页内容。
Inbox 的作用是降低收集门槛,但不能变成永久垃圾场。
我会定期让 AI 检查这里的内容:该归档的归档,该提炼的提炼,没有长期价值的只保留原始记录。
01_Sources:原始资料Sources 保存原文和证据。
例如:
我过去写过的完整文章;项目原始记录;AI 对话;用户反馈;外部文章;课程笔记;原始截图。
这里最重要的规则是:尽量保留原貌,不要让 AI 为了“整理得更漂亮”擅自改写原文。因为你以后写文章、复盘项目或者检查事实,最后都要能回到原始资料。
02_Wiki:提炼后的长期知识Wiki 不保存一篇又一篇完整文章,而是保存可以反复使用的东西。
我的 Wiki 主要分成:
02_Wiki/
├─ projects/ 项目经验
├─ topics/ 主题理解
├─ methods/ 方法和流程
├─ decisions/ 重要决策
└─ assets/ 案例、金句、写作素材
例如,我做完一个小程序,不会把整个开发日志复制进 Wiki,而是提炼成:
这个项目解决了什么问题;
哪些做法有效;哪些坑下次不要再踩;哪些案例以后可以写进文章;哪些判断已经被真实数据验证。
03_Output:准备对外发布的内容Output 放正在生产和准备发布的东西:
公众号文章;X 帖子;小红书笔记;视频口播稿;课程大纲;产品方案。
这里可以继续细分成:
03_Output/
├─ 00_选题库/
├─ 01_内容母版/
├─ 02_平台发布/
└─ 99_运营复盘/
这样,原始资料不会和文章草稿混在一起,不同平台版本也不会互相覆盖。
04_System:系统规则这个目录不放业务内容,放系统本身:
AI 操作说明;目录规则;写作风格;模板;索引;操作日志;脚本说明。
它相当于知识库的说明书。
四、第三步:让 AI 进入知识库
Obsidian 准备好以后,接下来需要一个能操作本地文件的 AI Agent。
这里不展开做某一个工具的完整安装教程,只讲接入思路。
方案一:CodexCodex 可以把整个知识库目录作为一个工作区打开,然后直接让它搜索、读取和修改文件。
官方入口:developers.openai.com/codex/
使用时,把刚才创建的 Vault 根目录作为工作目录。
第一次不要直接说“帮我整理整个知识库”,而是给一个边界清楚的小任务:
请先读取根目录中的 AGENTS.md 和 AI-START.md。
然后检查 00_Inbox 中的 test.md。
不要修改原文,只告诉我它应该归档到哪里,以及能提炼出什么长期知识。
先确认它能找到文件、理解规则,再逐渐让它执行写入。
方案二:WorkBuddyWorkBuddy 更偏桌面 AI 助手,适合不想经常使用命令行的人。
官网:www.codebuddy.cn/events/invite?inviteCode=k765t3x7sa9
你可以给它指定本地项目或知识库目录,再让它处理文档、建立笔记、运行重复任务。
我自己使用时,比较看重的是它能直接处理电脑里的文件,而不是只在聊天框里给一段答案。
方案三:TRAE 或其他 Agent 编辑器TRAE、Claude Code 等工具也可以使用同样的方法。
核心动作只有一个:打开知识库根目录,让 Agent 看到规则文件和 Markdown 内容。不同工具的按钮、权限提示和模型选择会变化,但知识库本身不需要重建。
五、第四步:给 AI 写一份说明书
只让 AI 看到文件夹还不够。
没有规则时,AI 很容易做出一些“看起来很勤快,实际上很麻烦”的事情:
全量扫描所有文件,浪费时间;
把完整文章塞进 Wiki;
遇到相似主题就创建新页面;
为了格式统一改写原始资料;
输出一篇文章,却不更新选题和状态;
在错误的目录里再建一套新系统。
我的做法是在根目录放三类入口文件。
1. AGENTS.md:长期操作规则它告诉 Agent 这个项目是什么、目录怎么用、哪些事不能做。
一个最小版本可以这样写:
# 个人知识库 AI 操作规则
这是一个基于 Obsidian 和 Markdown 的个人知识库。
目录规则:
- 00_Inbox:临时收集
- 01_Sources:原始资料,尽量不改写
- 02_Wiki:提炼后的长期知识
- 03_Output:准备发布或交付的内容
- 04_System:规则、模板、索引和日志
核心原则:
- Source、Wiki 和 Output 不要混在一起
- 优先更新已有页面,不重复创建同义页面
- 不擅自删除或改写原始资料
- 重要修改后更新 04_System/log.md
执行任务前:
1. 先说明任务类型
2. 说明准备读取哪些文件
3. 说明预计修改哪些目录
4. 说明完成标准
执行后:
- 汇报实际修改的文件
- 检查索引、日志、状态和来源链接
Codex 官方也把 AGENTS.md 作为项目级长期指导文件使用。换到其他 Agent 时,如果它不自动识别这个文件,就在首次对话里明确要求它先读取。
2. SOURCE_OF_TRUTH.md:谁才是最新规则系统用久以后,最麻烦的不是没有文档,而是同一件事有三份文档,彼此还不一致。
所以我增加了一份“真源说明”:
# Source of Truth
- 目录规则以 AGENTS.md 为准
- AI 接入顺序以 AI-START.md 为准
- 写作流程以 04_System/AI写作工作流.md 为准
- 发布状态以 03_Output 中的文章元信息为准
- 原始文章以 01_Sources 中的文件为准
发生冲突时,不要自行合并,先报告冲突。
这份文件的作用,是防止 AI 看见旧说明后继续按旧流程工作。
3. AI-START.md:每次从哪里开始AI-START 不需要写得很长,只负责导航。
# AI Start
开始任务时:
1. 读取 AGENTS.md
2. 读取 SOURCE_OF_TRUTH.md
3. 根据任务类型选择专项手册
4. 不要一开始扫描整个知识库
任务路由:
- 导入资料:04_System/资料导入手册.md
- 写文章:04_System/AI写作工作流.md
- 发布内容:04_System/发布手册.md
- 维护知识库:04_System/知识库维护手册.md
这三份文件看起来多了一点,但它们解决的是三个不同问题: - AGENTS:平时怎么做; - SOURCE_OF_TRUTH:冲突时信谁; - AI-START:这次从哪里开始。
提示词只解决一次对话,规则文件才会逐渐变成长期协作方式。## 六、第五步:先跑通一个最小任务
不要刚搭好目录,就把几千篇旧文章全部扔给 AI。
先拿一份普通资料做测试。
例如,在 00_Inbox 里放一篇你过去写的文章,然后把下面这段话发给 Agent:
请按知识库规则处理 00_Inbox/测试文章.md。
要求:
1. 原文归档到 01_Sources,不要改写正文;
2. 判断是否已有相关 Wiki 页面;
3. 有则补充,没有再新建;
4. 提炼文章中的案例、判断和可复用方法;
5. 如果能形成新选题,登记到 03_Output/00_选题库;
6. 更新必要的索引和操作日志;
7. 最后列出实际修改文件。
执行完成后,人工检查四件事:
原文有没有被改坏;
Wiki 里是不是只留下了可复用内容;
有没有重复创建同义页面;
日志和来源链接是否完整。
这一步通过以后,再批量处理。
AI 知识库最怕的不是 AI 不够聪明,而是错误流程一次执行几百遍。
先用一个文件验证,再扩大到十个,最后才是批量。
七、第六步:搭建一条内容工作流
目录和规则都只是基础。
真正让我觉得这套系统有用的,是过去积累的内容开始重新参与写作。
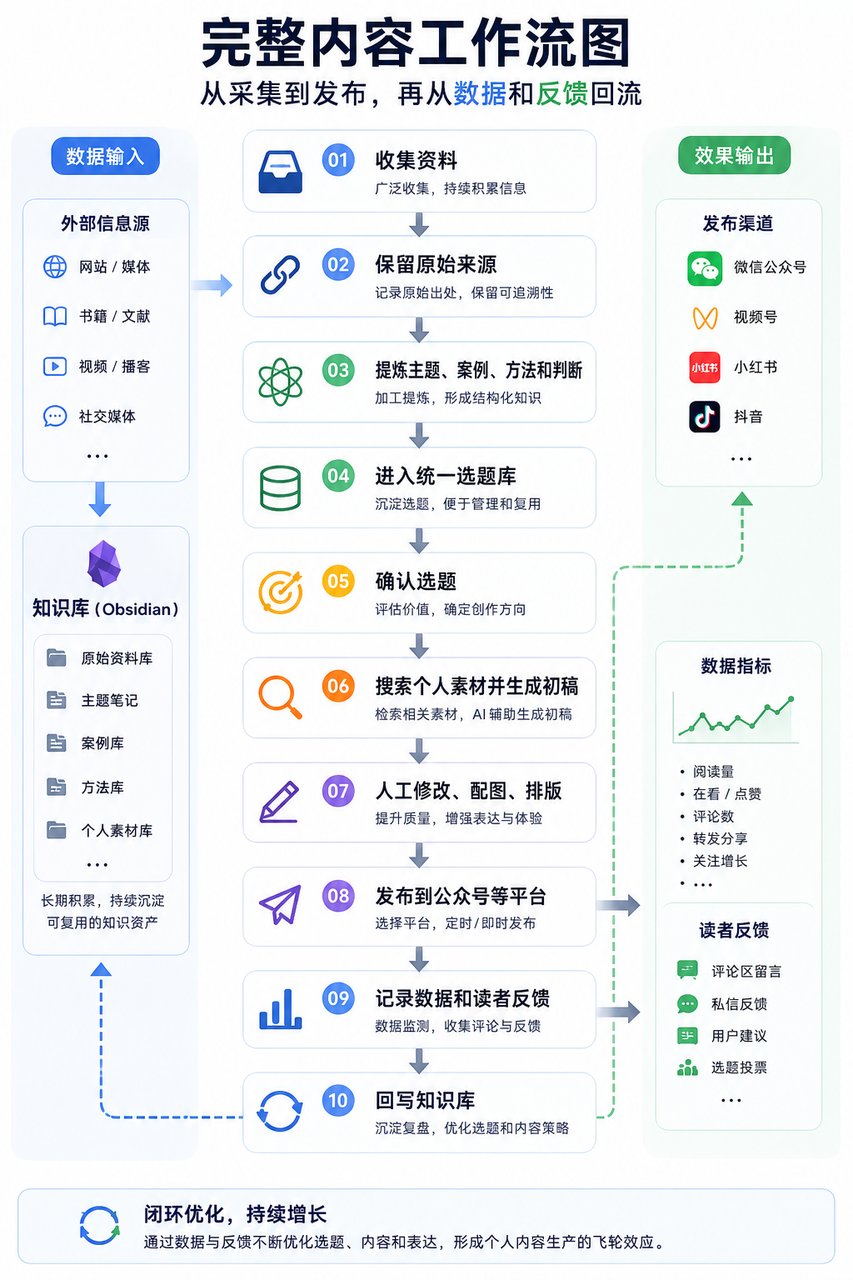
我现在的内容流程大概是这样:
收集资料
↓
保留原始来源
↓
提炼主题、案例、方法和判断
↓
进入统一选题库
↓
确认选题
↓
搜索个人素材并生成初稿
↓
人工修改、配图、排版
↓
发布到公众号等平台
↓
记录数据和读者反馈
↓
回写知识库
1. 收集:先保存,别急着提炼看到一篇好文章、一个案例或者一段对话,可以先进入 Inbox。
如果是外部内容,要记录公开链接、作者和时间。
如果是自己的内容,保留原始版本,尤其不要让 AI 覆盖。
2. 提炼:不要只让 AI 写摘要“帮我总结一下”通常只能得到一份更短的原文。
更有用的问法是:
请从这份资料中提取:
- 可以长期使用的判断
- 有现场感的案例
- 能复用的方法
- 存在争议或需要验证的观点
- 可以继续发展的选题
每一项保留来源链接,不要把外部观点写成我的经历。
这样提炼出来的东西,才适合进入 Wiki。
3. 选题:不要让选题散落在几十个文件里我的选题库会给每个选题一个状态:
待判断;待写;已成稿;已发布;暂停;不做。
除了标题,还会记录:
写给谁;解决什么问题;为什么由我来写;可用素材;发过哪些平台;发布链接;
阅读、点赞、收藏、咨询等数据。
这样,AI 下次推荐选题时能先检查“有没有写过、发过”,不会换个标题又推荐一遍。
4. 写作:先找自己的材料,再生成正文确认一个选题以后,不要马上让 AI 凭空写。
先让它搜索:
自己过去写过的相关文章;相关项目;
真实数据;反面案例;
已经发布过的同类内容;
写作风格和反感表达。
例如:
我要写“普通人如何搭建 AI 知识库”。
先不要写正文。
请先搜索:
1. 我过去关于 Obsidian、Codex、WorkBuddy 的文章;
2. 当前知识库的真实目录和规则;
3. 我实际使用中的问题、数据和案例;
4. 已发布或已成稿的同类选题,判断如何避免重复。
先给我三个切入角度和素材清单。
你会发现,文章质量真正拉开差距的地方,不是模型会不会写,而是它能不能找到只属于你的材料。5. 成稿:自动分段、加小标题和重点我的旧文章不少是连续长段落,直接搬到公众号阅读体验很差。
所以在成稿环节,我会让 AI 做这些机械工作:
增加自然的小标题;把过长段落拆开;
检查是否缺少前置条件和步骤;给重要结论加粗;
给关键数字、风险和操作条件做重点标记;
检查 AI 套话;列出需要补充的真实截图。
但重点不能满屏都是。
观点文重点标判断、反差和行动结论;实操文重点标参数、风险、关键步骤和验收结果。全文到处加粗,等于什么都没有强调。
6. 发布:Markdown 只是内容母版Markdown 确认以后,再转换成公众号 HTML,生成封面、正文知识卡片和发布素材。
这个阶段要人工检查:
标题和摘要;封面;正文图片;手机端段落;
重点颜色;外部链接;原创声明;是否真的进入草稿箱;
是否已经公开发布。
进入草稿箱不等于已发布。
正式公开以后,再更新发布日期、链接和数据,避免系统错误地把草稿当成历史文章。
7. 回流:发布不是结束一篇文章发布以后,评论和数据会继续产生新材料。
例如:
大量读者在同一个步骤卡住,说明教程缺了一段;
某个案例被频繁转发,说明它适合继续扩写;
有人因为文章来咨询,说明这个问题有真实需求;
数据很差,也可能说明标题、切入角度或目标人群出了问题。
这些信息可以继续进入 Sources,再提炼回 Wiki 和选题库。
这时,知识库才不是一个只进不出的收藏夹。
八、把重复工作做成 Skill 或脚本
当一个流程已经稳定执行过几次,就不要每次重新写一大段提示词。
我现在会把两类东西固化下来。
适合做成 Skill 的事情Skill 更像给 AI 的专项操作手册,适合需要判断的流程:
如何处理一篇新资料;如何筛选旧文章;如何检查同题重复;
如何写公众号观点文;如何把文章转换成技术实操文;发布后需要更新哪些状态。
适合做成脚本的事情脚本适合规则非常明确、重复率很高的动作:
批量改文件名;生成选题面板;检查失效链接;
Markdown 转公众号 HTML;上传正文图片;同步到 Notion;
更新发布状态和日志。
我的判断标准很简单:
需要理解上下文和做判断的,交给 Agent;可以明确写成输入输出的,交给脚本。不要为了显得高级,把所有事情都自动化。
涉及删文件、公开发布、覆盖原文、修改大批量资料的操作,最好保留人工确认。
九、日常怎么使用和维护
系统搭好以后,不需要每天维护半小时。
我更推荐下面这个节奏。
每天:临时资料先进 Inbox;正在写的内容放 Output;不在收集时纠结每一条资料的最终归属。
每周:清理一次 Inbox;检查待写选题;合并重复主题;看看是否有文章状态没有更新。
每月:复盘发布数据;检查哪些 Wiki 页面被真正使用过;清理失效链接;更新 AI 规则和写作偏好;备份整个 Vault。
备份:本地文件不等于自动安全。
至少选择一种备份方式:
Obsidian Sync;
Git 私有仓库;(我用的这个,有大量更新就提交到GitHub)
可靠的网盘同步;
定期复制到移动硬盘。
如果知识库里有 API Key、Cookie 或平台密钥,不要直接写进普通 Markdown,更不要提交到公开 Git 仓库。
使用本地环境变量或被 Git 忽略的配置文件。
以上就是最近一个月使用obsidian+codex搭建AI内容知识库经验,希望对你有帮助。