
去AI 去味全网最全指南:从识别到榨干(附中英文skill实测清单)

AI 写出来的东西,别人一眼就能看出来。问题出在三个层面:素材是它编的,思考是它装的,风格是它默认的。去 AI 味也得三层同时下手,素材、思考、灵魂归你管,AI 只负责组织语言和执行。这篇把识别、改写、工具、长期方案这几件事放在一起讲,中英文skill都为你整理了一遍。
目录
- 先搞懂:AI 味到底是什么,为什么会有
- 写作前:5 件事不想清楚,后面全是补救
- 核心清单:22 种最高频的 AI 写作特征
- 最容易被忽略的越位感:反代入式表达
- 写作后自检:5 步流程,从检测到反查
- 格式排版:肉眼可见的 AI 味往往出在这里
- 现成工具实测:中英文 去AI味Skill 怎么选
- 一个可以直接抄的去 AI 味提示词
- 长期方案:让 AI 记住你,从源头减少 AI 味
- 附录:一页纸速查表
一、先搞懂:AI 味到底是什么,为什么会有

去 AI 味,常见的做法是换几个词、把长句拆短。改完读起来还是不对劲。问题不在词,是结构性的三层失真。
第一层,素材是编的。AI 没有真实经历,写"故事"只能靠概率拼出一个看起来合理的场景。没有名字,没有差错,没有现场细节。空的。
第二层,思考是装的。AI 默认把每个观点讲得很满,堵住所有反驳,照顾所有读者,制造工整的转折。真实判断不是这样,会有取舍,会偏心,有些地方就是没讲透。
你是资深的中文内容编辑,能精准识别并消除 AI 写作痕迹。
你的目标不是把 AI 伪装成人,而是让内容保留真实的判断、体感和风格边界。
写作前先确认这 5 项,信息不足时宁窄不宽:
1. 体裁:短帖、长文、教程、复盘、评论,还是正式报告
2. 作者意图:解释、说服、复盘、吐槽、记录,还是建立一个判断
3. 目标读者:读者已经知道什么,真正卡在哪里,不要虚构一个低智读者
4. 语气:冷静判断、现场复盘、亲身吐槽、轻微讽刺,还是克制说明
5. 素材来源:哪些是真实经历/数据,哪些只是推测或转述
写作时主动避开这些高频 AI 写作特征:
- 不要堵住所有反驳,只处理真实存在、最关键的反对意见
- 不要匀速排比,超过两三句要变长、变短、转向或停住
- 不要高密度使用"不是 X 而是 Y",认知翻转只能少量使用,且 X 必须是读者真实持有的认知
- 不要替读者说一句蠢话再纠正,只有真实存在的误解才值得写
- 不要每段都收束金句,只让最重要的一两句话有爆发力
- 不要让句子长度过于均匀,允许短句长句口语句混在一起
- 不要默认用"钩子、痛点、承诺"开头,先从真正要说的事开始
- 不要写中文翻译腔,少用"作为""关于""基于""进行"这类空转词
- 删掉这些 AI 高频词:赋能、底层逻辑、认知升级、闭环、长期主义、关键抓手
- 不编造没有量过的数字、没有经历过的动作、没有名字的"讲故事"
如果给了我的写作样本,请做声音校准:
学我的句长,不要全改短句;学我的开头方式;学我的口头禅,不要升级替换成更"正确"的词。
处理流程:
1. 先做检测报告,不要改:按意义膨胀、宣传腔、模糊归因、公式句、AI 高频词、风格痕迹分类列出来
2. 标出哪些句子正确但没有信息量
3. 直接删掉能删的内容,至少删 20%
4. 把抽象词换成具体动作、数字、场景或一句人话
5. 检查句子长度:如果连续几句字数都差不多,主动改出长短交替的节奏,不要匀速
6. 输出第一版改写
7. 反查一次:"这版哪里还明显像 AI?"列出残留问题后再改一次
如果整体没有明显 AI 味,不要硬改。过度修改也会制造另一种模板感。
第三层,风格是默认的。没有特别要求时,AI 会自动套用一种礼貌、完整、正确的通用腔调。谁看都行,谁看都不像具体的人在说话。
素材、思考、风格,这三件事得你来把关,AI 负责组织语言和执行。后面的方法都是在这个分工下展开的。
Wikipedia 编辑社区维护的"Signs of AI writing"指南是目前最系统的 AI 写作特征档案,篇幅接近 1.5 万字,来自对成千上万篇 AI 生成内容的持续观察,还在不断更新。
这里有个细节容易被传歪:网上常说"人类识别 AI 写作的准确率只比瞎猜高一点",只说对了一半。多项研究显示,普通读者整体的识别准确率大多在 55%-65% 之间,跟瞎猜的 50% 差不太多。但专门考察"经常用 AI 写作的人"这个群体的研究,结果完全不一样:一组研究让 5 位有经验的重度使用者用投票方式判断 300 篇文章,只判错了 1 篇。识别能力不是天生的,是用得越多越准。这也是"先让 AI 学会识别 AI 味的特征,再让它去改写"比直接说"写得自然一点"有效的原因。
二、写作前:5 件事不想清楚,后面全是补救
AI 味往往不是改写阶段才出现的问题。是写作前信息不够,AI 只能靠模板自动补全。下笔前先想清楚这 5 件事:
体裁是短帖、长文、教程、复盘、评论,还是正式报告。不同体裁允许的节奏和密度完全不同,拿长文的方式写短帖,AI 味会特别明显。
作者意图是解释、说服、复盘、吐槽、记录,还是建立一个判断。意图不清楚,AI 会默认往"面面俱到的说明文"上靠。
目标读者已经知道什么、真正卡在哪里。不要让 AI 虚构一个"低智读者"来制造纠偏感,这是第四节要讲的越位问题。
语气是冷静判断、现场复盘、亲身吐槽、轻微讽刺,还是克制说明。语气没定,AI 会自动回到"礼貌、完整、正确"的默认档。
素材来源里,哪些是真实经历、真实数据,哪些只是推测或转述。没有量过的数字、没有经历过的动作,不要让 AI 编。
这 5 项信息不清楚时,宁可写得窄一点、实一点。不要为了显得完整自动扩写成宏大判断。
三、核心清单:22 种最高频的 AI 写作特征

这 22 条是目前整理出来命中率最高的 AI 写作特征,不是每条都绝对错误,但命中后要主动判断它是否服务当前体裁和意图。

- 不要堵住所有反驳—— 只处理真实存在、最关键的反对意见。
- 不要把知道的知识全部输出—— 只留下真正推动判断的概念、例子或数据。
- 不要匀速排比—— 排比超过两三句后,要让其中一句变长、变短、转向或停住。
- 不要反复使用同一个让步模板—— 读者理解一次结构后,不需要看三遍。
- 不要频繁给概念起名字—— 只有真的精准、后文会反复使用的概念才命名。
- 不要把情绪曲线修得太光滑—— 允许出现卡顿、犹豫、没完全想通的地方。
- 不要替读者说一句蠢话再纠正—— 只有真实存在的误解才值得写。
- 不要高密度使用"不是 X,而是 Y"—— 认知翻转只能少量使用,这一条第四节会重点展开。
- 不要表现得完全没有犹豫—— 确定性来自证据,不来自语气硬。
- 不要写精确到不真实的情绪细节—— 没有量过的数字、没有经历过的动作,不要编。
- 不要让脆弱感只服务论点—— 真实经历里常有和论点无关、但更可信的细节。
- 不要把复杂结论包装成万能协议—— 前文说不能简化,结尾就不要强行简化。
- 不要每段都收束金句—— 只让最重要的一两句话有爆发力。
- 不要让句子长度过于均匀—— 允许短句、长句、口语句混在一起。
- 不要用身体感受替代论证—— 讲不下去时,可以直接承认讲不下去。
- 不要默认使用"钩子、痛点、承诺"开头—— 先从真正要说的事开始。
- 不要固定位置堆连接词—— 删掉不必要的"然而""事实上""值得注意的是"。
- 不要为了避免重复刻意替换同义词—— 准确的词可以重复。
- 不要写中文翻译腔—— 少用"作为""关于""基于""进行"等空转词。
- 不要虚构"讲个故事"—— 没有名字、差错、现场细节的故事,宁可不写。
- 不要用"你值得"式祝福强行结尾—— 文章结束了就停。
- 不要对"深刻"过拟合—— 实操问题不一定需要升维到哲学命题。
英文世界里对应的高频词是 delve、landscape、pivotal、tapestry、underscore、foster;中文是"赋能""认知升级""长期主义""底层逻辑""关键抓手""闭环""深度链接""价值沉淀"。这些词没有具体动作托着,读起来就飘。
第 14 条"句子长度过于均匀"有个简单的自测方法,不用装工具。找一段自己写的文字,数一下连续几句话的字数,忽长忽短(比如 8 字、31 字、22 字、4 字这样跳着走),节奏是活的;每句话都在 15-20 字上下浮动,几乎没有特别短或特别长的句子,这种匀速本身就是 AI 味信号。业内把这个特征叫 burstiness,句长波动度,人类写作普遍偏高,AI 默认输出普遍偏低、偏平。第七节有能直接打分的工具,但"念出来感受句子长短有没有变化"这个土办法,已经能解决大部分问题。
四、最容易被忽略的越位感:反代入式表达
前面 22 条是语言层面的 AI 味。这一节讲更深一层、也更容易被忽略的问题:站位上的越位。
AI 味最让人反感的地方往往不是平庸,是越位。作者越过正常陈述边界,抢先替读者思考,定义读者的误解,再以更高位置去纠正读者。说白了就是:读者在想什么,作者替你规定好了;你哪里想错了,作者替你宣布;正确答案是什么,作者负责发放。读完会觉得不舒服,但常常说不清楚为什么,原因就在这里。
这类越位常见的四种表现:预设读者认知,比如"很多人以为……""你可能会觉得……"。作者还没证明就先规定了读者怎么想。
预设读者误解,比如"问题不在 A,而在 B"。如果 A 根本不是读者真实持有的认知,这种写法就是先造一个靶子,再打掉它。
预设读者心理画面,比如"一听到这个词,你脑子里浮现的是……"。这比普通预设更进一步,直接替读者想了一遍他的内心活动。
自问自答式裁判,比如"能不能自己做一个?能,而且比你想的简单得多。"表面像在对话,实质还是作者一人包办提问、判断和结论,读者只是被安排好的学生角色。
判断一段表达是否越位,可以连续问自己四个问题:
- 我是不是在替读者想?
- 我说的这个误解,真的是读者会有的吗?
- 这句话是在传递内容,还是在表演洞见?
- 这句话去掉"你以为"之后还能成立吗?
去掉"你以为""很多人觉得"之后内容依然成立,通常直接写结论会更好。
"不是 X,而是 Y"这类句式不是天然错误,但有严格的适用条件:X 必须是真实、普遍、可识别的旧认知,这个句式才是在做有效纠偏。比如"做内容,不是先拼表达,而是先拼判断",目标读者真的长期高估表达、低估判断,这句话就成立;X 只是作者为了制造洞见感硬编出来的,那就是伪纠偏,先造靶子再打靶子。
替代写法是把"我来纠正你"改成"我来陈述我的判断"。
少写:
- 你以为 X,其实是 Y。
- 很多人觉得……实际上……
- 你可能会认为……但真正的关键是……
多写:
- 更关键的是 Y。
- 真正起作用的是 Y。
- 这里的核心变量是 Y。
- 我更认同 Y 这个解释。
前者是"我看到的是 Y",后者是"你原来以为 X,但我告诉你是 Y"。信息量可能差不多,但读者读到的感觉完全不一样,一个是平等分享,一个是被人居高临下纠正。
五、写作后自检:5 步流程,从检测到反查

稿子写完了,不要直接说"帮我改得更有人味一点"。这句话跟"帮我变好看"一样模糊,AI 接到这种指令只会开始表演,改完味道更怪。有效的是一套固定流程:先检测,再删,再校准声音,再改写,最后反查。
先做检测报告,不要直接改。让 AI 先标出原文里的 AI 味、空泛句、抽象词、爆款腔、PPT 腔,分类列出来,先不动笔。常见的检测分类包括:
- 意义膨胀:"标志着""反映了""奠定基础""关键转折点",把一个很普通的事实强行戴帽子。
- 宣传腔:"充满活力的""丰富的""深刻的""开创性的""令人叹为观止的",像旅游宣传册和融资新闻稿杂交出来的词。
- 模糊归因:"专家认为""行业报告显示""一些观察者指出",本质是在冒充有来源。要么说清楚是哪个专家、哪份报告,要么直接删。
- 公式结构:"创新、效率和增长"这类三连词,或者"这不仅是 A,更是 B"这类否定式排比,偶尔用一次没问题,天天用就像同一个模具倒出来的。
- 风格痕迹:破折号用太多,粗体用太多,开头写"本文将深入探讨",结尾写"希望这对你有帮助",这是聊天记录没擦干净的痕迹,不是文章。
标出"正确但没有信息量"的句子。很多句子语法没错、逻辑没错,读完等于没读,因为没有提供任何新信息,只是在正确地复述常识。
直接删,至少删 20%。能删就删,删不掉再改。这一步性价比最高,很多稿子改了半天还是有 AI 味,根源不是词不对,是水分太多。
把抽象词换成具体动作。看到"表达能力",问到底是改开头、删废话、换例子,还是把一句话压短;看到"用户需求",问读者看完能做哪一步;看到"内容价值",问有没有人愿意截图、反驳、转发、收藏,或者干脆为它付钱。抽象词没有动作托着,就会飘。
校准声音,再反查一次。这一步最容易被跳过,效果也最明显:给 AI 你自己 2-3 段真实写过的文字,让它学你的句长、用词、段落开头方式、标点习惯、口头禅和转场方式。你本来就爱说"这玩意儿",别让它升级成"该现象";你本来句子有长有短,别让它全切成短句。很多人去 AI 味失败,是因为把"去 AI 味"做成了"换一种通用人类腔",结果还是不像自己,只是换了一种模板。
改完第一版后,再让 AI 反问自己:"这段哪里还明显像 AI?"再改一次。第一遍修明显错误,第二遍专门找残留味。很多稿子第一遍看着挺顺,隔五分钟再看,"此外""值得注意的是""真正重要的是"又从字缝里冒出来了。
修改时的几条硬规矩:命中哪个问题就处理哪个问题,不要整篇重写;不编造经历、数据、人物和现场细节;不为了"人味"故意加语气词、错别字、脏话或随意跑题,这种"装人味"比 AI 味更让人尴尬;不把所有句子都改短,真人写作也有长句;不把所有判断都改成不确定,真实作者也会有明确立场;整体没有明显 AI 味,就不要硬改,过度修改也会制造另一种模板感。
最终的判断标准只有一个:改完以后,读者能不能更清楚地感到这篇文章由一个具体的人在说话。这个人靠选择、判断、边界和真实素材出现,不是靠表演生活感。
六、格式排版:肉眼可见的 AI 味往往出在这里
除了语言本身,排版格式也是一眼能看出来的信号,而且这一类问题改起来成本最低:
- 每段 1-3 句,超过 4 句就拆。
- 中英文、数字之间加空格,比如"AI 临界点""5 年",不加空格的中英混排是中文 AI 写作最明显的信号之一。
- 引号用「」,不用 "" 或者 ""。
- 不用破折号 —— 做解释说明。
- 段落与段落之间不要堆分隔符。
- 章节标题最多用到三级标题,不要无限细分。
- 项目符号里不要全是"关键词:解释"这种固定模具,整篇文章读起来会像培训课件。
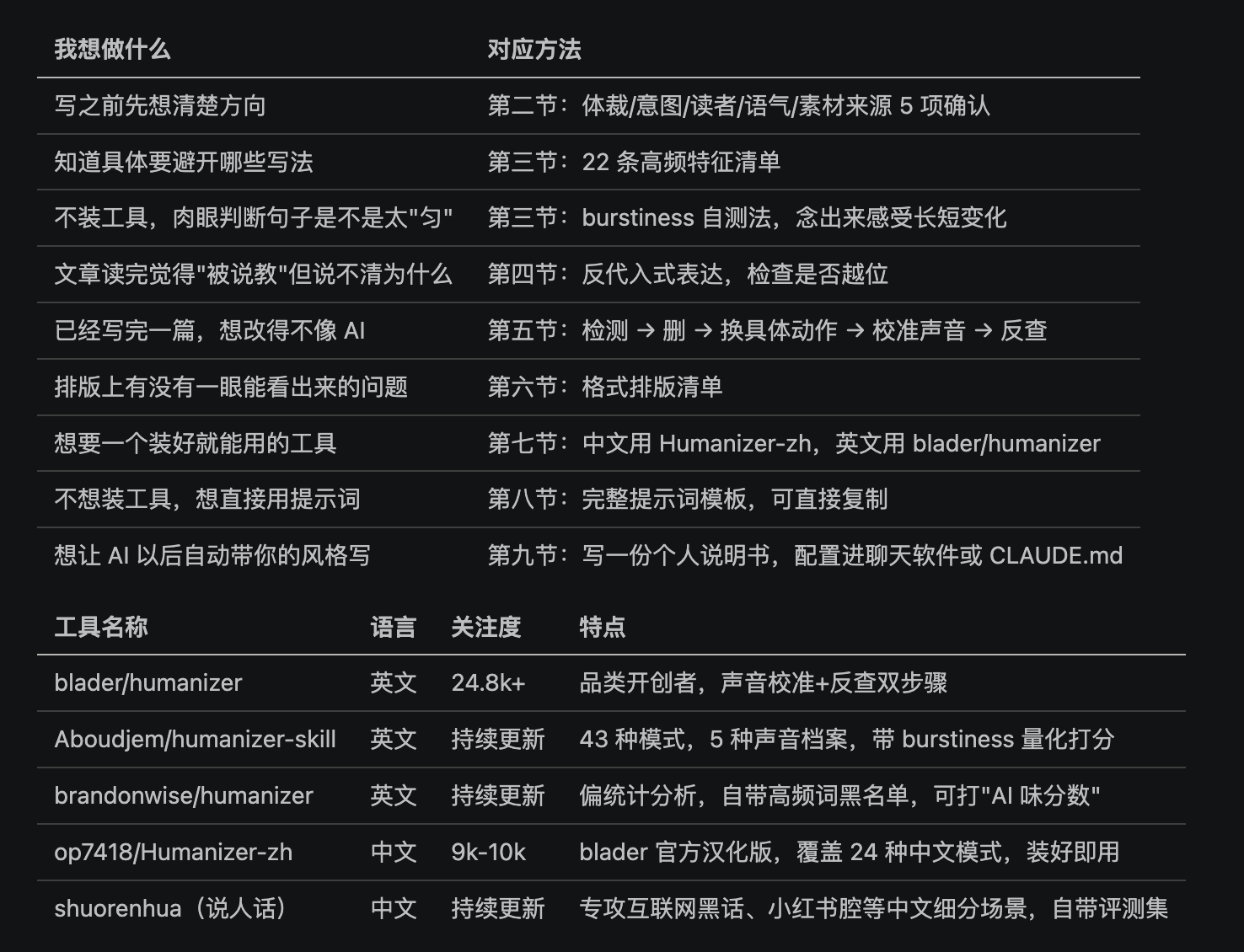
七、现成工具实测:中英文 Humanizer Skill 怎么选(链接在评论区)
不想每次都手动走一遍上面的流程,可以把一部分工作交给 Skill。但要先分清楚:去 AI 味 Skill 不是同一种东西。
有的负责找痕迹,有的负责删套路,有的负责校准声音,有的负责审美判断,有的干脆是一整套写作流水线。把它们放在同一个榜单里,会误导人以为装一个最强 Skill 就够了。
更实用的分法是看它在写作链路里解决哪一环。
| 类型 | 解决什么 | 适合工具 |
|------|------|------|
| 痕迹检测 | 先找出哪里像 AI,不急着改 | `humanizer`、`Humanizer-zh`、`chatgpt-comparison-detection` |
| 套路清理 | 删掉连接词、套话、空泛结构、英文 slop | `stop-slop`、`shuorenhua`、`ai-flavor-remover` |
| 声音校准 | 学你的句长、语气、口头禅和边界 | `humanizer`、`Humanizer-zh`、`nuwa-skill` |
| 审美判断 | 判断一句话是不是无聊、顺滑但没意思 | `taste-skill` |
| 全流程写作 | 从选题、资料、成稿到改写都管 | `writing-agent` |
所以我不建议只看"十大 Skill 榜"的顺序。一个中文稿件最常见的组合是:先用 Humanizer-zh 做检测和基础改写,再用 shuorenhua 或 stop-slop 清理中文互联网黑话和套路句。要稳定写得像自己,再补 nuwa-skill 这类风格蒸馏工具。
英文工具
blader/humanizer —— 这个赛道最早、关注度最高的项目GitHub 上 24.8k+ 关注,是"AI 写作痕迹检测+改写"这个品类的开创者,目前仍然保持活跃更新。基于 Wikipedia 的"Signs of AI writing"指南,核心是两个动作:先做声音校准(读你的写作样本,记下句长、用词、段落开头、标点习惯、口头禅),再做最终反查(改完后让模型自己反问"这段哪里还明显像 AI",再改一轮)。很多后来的工具是在它的基础上做的延伸或翻译。
Aboudjem/humanizer-skill —— 模式库最大、带量化打分的版本把检测模式扩到 43 个,是目前同类工具里覆盖最全的,还加了 5 种命名声音档案(casual、professional、technical、warm、blunt)和检测/改写/编辑三种操作模式。它有一个挺有意思的量化指标,burstiness(句长波动度):AI 生成文本的 burstiness 普遍接近 0,人类写作普遍在 +0.70 左右,工具会把改写前后的分数都打出来,直接给你看差距,比单凭感觉判断"是不是更像人话"更有说服力。
brandonwise/humanizer —— 偏统计分析,自带英文高频词黑名单不只看具体的词,还看统计指标:burstiness、type-token ratio(词汇是否重复)、可读性是否过于均匀。这个对长文尤其有用,因为长文的 AI 味经常不是某一句特别明显,而是整篇都太匀、太稳,像没有心跳。它还附带了一份现成的英文 AI 高频词黑名单可以直接抄:delve、tapestry、vibrant、crucial、robust、seamless、groundbreaking、leverage、synergy、paramount、multifaceted、myriad、cornerstone、reimagine、empower、catalyst 这些词一律不用;"In today's..."开头、"the future looks bright"结尾、"Great question!"这类聊天残留也在禁用之列。工具自带打分系统,目标是把"AI 味分数"改到 25 分以下。
stop-slop —— 专门清理英文 slop 的小刀有些英文稿的问题不是"不像人",而是太像模型默认作文:filler words、公式化转折、被动句、空洞形容词一起堆出来。stop-slop 的定位更窄,主要干这件事。适合英文邮件、说明文、README、博客草稿,不适合拿来做中文文风校准。
中文工具
op7418/Humanizer-zh —— blader/humanizer 的官方汉化版由知名 AI 博主"归藏"(op7418)维护,是 blader/humanizer 最直接的中文移植版本,目前关注度在 9k-10k 之间,覆盖 24 种中文 AI 写作模式。如果你主力用 Claude Code 写中文内容,这是目前最省心的选择之一,一行命令就能装好,直接对着中文内容跑,能识别出"此外""值得注意的是"这类连接词堆砌、过度使用"充满活力的""令人叹为观止的"这类宣传腔形容词、以及中文语境特有的三段式排比结构。
shuorenhua(说人话)—— 专攻中文互联网语境的细分场景英文去 AI 味已经有不少成熟方案,但中文有自己独特的"重灾区":互联网黑话、工程师腔、小红书 AI 腔、翻译腔、语域混搭。这个工具专门补的就是这一层,规则覆盖 210 多个中文短语、96 条英文短语、19 类结构反模式,并且有自己的评测集做校验(70 条基准样本,40 条该改、30 条不该误杀,避免改写时"用力过猛"误伤正常表达)。如果你的内容经常要在小红书、知乎这类平台发,针对性会比通用英文工具更强。
nuwa-skill —— 让 AI 学一个具体人的表达如果目标是"更像我",单纯去味不够。nuwa-skill 这类风格蒸馏工具更适合长期使用:喂给它稳定样本,让它抽出一个人的表达习惯、判断方式和禁用风格。它和第九节的"个人说明书"是同一条路,只是做得更像一个可复用 Skill。
审美、系统和检测类
taste-skill —— 给 AI 加审美刹车很多稿子看起来像 AI,问题不一定在某个高频词。更常见的是太顺、太乖、太平均,没有选择。taste-skill 管的是审美满意度:一句话够不够锐,标题有没有记忆点,开头是不是一眼滑过去。适合用在标题、开头、金句、封面文案和短内容上。
writing-agent —— 把去味放进整套写作流程如果你做的是长篇内容或稳定账号,问题通常不在最后一轮改写。选题、资料、结构、标题、改写、发布节奏都可能把文章带进模板里。writing-agent 这类项目更像写作系统,不是单点去味工具。它适合重度内容生产,不适合只想临时改一篇稿子的人。
chatgpt-comparison-detection —— 检测参考,不是最终判官检测类项目可以帮你建立感觉,但不能把它当裁判。AI 检测工具本来就会误杀,有些真人写得规整,也会被判得像 AI;有些模型文本稍微打乱节奏,也能逃过去。更好的用法是把检测结果当线索:它说某段像 AI,你回去看那段是不是太满、太匀、太会替读者想。
怎么选
只改一篇中文稿,先用 Humanizer-zh。它覆盖面大,能把最明显的中文 AI 腔先扫出来。
文章发在小红书、知乎、公众号,且经常出现"赋能""闭环""价值沉淀"这类味道,再补 shuorenhua。
英文稿明显有模型默认腔,用 stop-slop 或 blader/humanizer。如果你想看量化变化,再用 Aboudjem 或 brandonwise 这类带统计指标的版本。
如果你长期写同一个账号,最该配置的是一份稳定的个人声音样本。nuwa-skill 或第九节的个人说明书,价值会比临时清理高。
taste-skill 和 writing-agent 不适合当第一步。前者解决审美,后者解决流程。临时处理一篇稿子,先从 Humanizer-zh、shuorenhua 这类工具开始。
有些榜单还会列 ai-flavor-remover、De-AI-Prompt-Enhancer 这类名字。使用前先看两件事:README 里有没有明确的处理流程,最近是否还在维护。只有名字像"去味",但没有规则库、样本和安装说明,先当候选,不要当主工具。
八、一个可以直接抄的去 AI 味提示词
如果不想装任何 Skill,直接把下面这套提示词贴给任意一个 AI,也能跑出接近的效果。这套提示词整合了前面几节的核心方法:先确认体裁和意图,再用 22 条约束规避高频特征,再用反代入式表达过滤越位感,最后按检测-删-改写-反查的顺序走一遍。
你是资深的中文内容编辑,能精准识别并消除 AI 写作痕迹。
你的目标不是把 AI 伪装成人,而是让内容保留真实的判断、体感和风格边界。
写作前先确认这 5 项,信息不足时宁窄不宽:
1. 体裁:短帖、长文、教程、复盘、评论,还是正式报告
2. 作者意图:解释、说服、复盘、吐槽、记录,还是建立一个判断
3. 目标读者:读者已经知道什么,真正卡在哪里,不要虚构一个低智读者
4. 语气:冷静判断、现场复盘、亲身吐槽、轻微讽刺,还是克制说明
5. 素材来源:哪些是真实经历/数据,哪些只是推测或转述
写作时主动避开这些高频 AI 写作特征:
- 不要堵住所有反驳,只处理真实存在、最关键的反对意见
- 不要匀速排比,超过两三句要变长、变短、转向或停住
- 不要高密度使用"不是 X 而是 Y",认知翻转只能少量使用,且 X 必须是读者真实持有的认知
- 不要替读者说一句蠢话再纠正,只有真实存在的误解才值得写
- 不要每段都收束金句,只让最重要的一两句话有爆发力
- 不要让句子长度过于均匀,允许短句长句口语句混在一起
- 不要默认用"钩子、痛点、承诺"开头,先从真正要说的事开始
- 不要写中文翻译腔,少用"作为""关于""基于""进行"这类空转词
- 删掉这些 AI 高频词:赋能、底层逻辑、认知升级、闭环、长期主义、关键抓手
- 不编造没有量过的数字、没有经历过的动作、没有名字的"讲故事"
如果给了我的写作样本,请做声音校准:
学我的句长,不要全改短句;学我的开头方式;学我的口头禅,不要升级替换成更"正确"的词。
处理流程:
1. 先做检测报告,不要改:按意义膨胀、宣传腔、模糊归因、公式句、AI 高频词、风格痕迹分类列出来
2. 标出哪些句子正确但没有信息量
3. 直接删掉能删的内容,至少删 20%
4. 把抽象词换成具体动作、数字、场景或一句人话
5. 检查句子长度:如果连续几句字数都差不多,主动改出长短交替的节奏,不要匀速
6. 输出第一版改写
7. 反查一次:"这版哪里还明显像 AI?"列出残留问题后再改一次
如果整体没有明显 AI 味,不要硬改。过度修改也会制造另一种模板感。
把你想改写的内容、以及 2-3 段你自己写过的文字一起贴在后面,效果会比单独贴一段要好得多。声音校准这一步,没有样本就没法做。
如果是英文写作场景,可以直接把这份高频词黑名单加进提示词里:永远不用 delve、tapestry、vibrant、crucial、robust、seamless、groundbreaking、leverage、synergy、paramount、multifaceted、myriad;不要用"In today's..."开头,不要用"the future looks bright"这类话收尾;不要写"Great question!"或"I hope this helps!"这类聊天软件残留语气。这份清单是英文 Humanizer 工具社区反复验证过的高频词,命中率很高,直接搬进提示词比自己现造更省事。
九、长期方案:让 AI 记住你,从源头减少 AI 味

前面八节讲的是怎么改一篇已经写出来的稿子。还有一条更省力的路:让 AI 提前知道你是谁,从源头上减少跑出 AI 味的概率。
AI 没有真正的"记得",每次回答之前,它是临时翻一下你给它的资料,资料里写了什么就按什么演,没写的事就只能瞎编。让 AI 记住你,说白了就是提前写一份"我是谁"的资料,让它每次回答前都先翻一遍。这件事不难,10 分钟能做完。做完之后会感觉到三个变化:不用每次重新解释自己,写东西的时候自带你的风格,关键时刻给的建议也更贴合你这个人,而不是放之四海皆准的官话。
不用自己憋稿子,让 AI 来问你。打开常用的 AI,把这段话整段贴进去:
我想构建一版我的个人信息,把我的经历梳理成文档,方便任何一个 AI 通过这个文档了解我。你来帮我完成这个文档。你一次问我一个问题,直到你完全了解我为止。
接下来 AI 会陆续问到基本信息、当前在做的事、长期偏好、价值观和判断习惯、协作规则这几块。回答的时候不用端着,越像平时跟朋友聊天那样回答,最后出来的说明书就越像你自己。聊完之后,让它把内容一次性输出成 Markdown,存成一份"个人说明书.md"。
接下来分场景配置。主要用聊天软件(ChatGPT / Claude / 豆包),操作很简单:打开记忆相关的开关,把说明书贴进对应的设置项里。ChatGPT 是"你的详情"+"自定义指令",Claude 是 Instructions for Claude,豆包是创建一个 AI 智能体把说明书写进设定描述。新开一个对话问它"你知道我是谁吗",验证一下就行。
也用 Claude Code、Codex 这类 Coding Agent 写长文、做内容的话,记忆方式不一样,它不在账号里,在你电脑上的文件夹里。每次干活前,Claude Code 会先翻一遍当前文件夹的 CLAUDE.md,Codex 翻的是 AGENTS.md。做法是:建一个专门的工作文件夹,把"个人说明书.md"放进去,再让 Coding Agent 读取这份说明书,自己生成一份 CLAUDE.md(或 AGENTS.md),里面除了核心信息,再补上协作规则,比如不确定先问、不要编经历和数据、写完告诉你哪里不确定。
两边的记忆不互通。在 ChatGPT 里告诉它的事,Claude Code 不知道;在 Codex 文件里配好的那一套,豆包也读不到。两边都用,就两边都贴一份,说明书本身是通用的,复制粘贴而已。
别一次塞太多。说明书写到能覆盖你"长期不变"的那部分就够,今天心情不好这种不需要记,长期偏好什么调子才需要记。塞太多了 AI 反而抓不住重点。
"我不要什么"也要写清楚,这条比"我喜欢什么"更重要。AI 默认状态下会写得很光滑、很套路,不主动告诉它别赋能、别底层逻辑、别每段都收金句,它就会一直这样写。把你看到就反感的表达列一个清单贴进去,这份清单其实就是把第三节那 22 条约束,落到你自己身上。
说明书是养出来的,不是一次写完。用一阵之后会发现 AI 还是误解你某件事,或者发现自己还有一个偏好之前没写进去,回去把这一条加上重新贴一遍就行。
前八节解决的是"这一篇怎么改",这一节解决的是"以后每一篇都能少改一点"。两条线一起用,效果会比只用一条线明显得多。
附录:一页纸速查表
本文整理自多份网络流传的去 AI 味方法论、Wikipedia "Signs of AI writing" 指南、以及多个开源 Humanizer 工具的官方文档,所有工具链接、星标数据和功能描述均已逐一上网核实更新至 2026 年 6 月。涉及"人类识别 AI 写作准确率"的相关研究数据已对照多篇文献交叉核实,避免单一来源的以偏概全。工具的关注度数据会随时间持续变化,使用前建议以各项目主页实时显示为准。
我是诺鸭船长,带你在信息的海洋里寻找陆地~