
Skill 小白完整入门教程(做出你的第一个skill)

每个用 AI 工作的人都遇到过这个问题:
你教会它一件事,隔天开新对话,一切归零。
你花三天调好一套工作流程,跟 Claude 来回对话搞定了,隔天又要从头解释。
你把 prompt 存在笔记里每次贴,但一段 500 字的指令,每天贴一次,贴一个月,你开始怀疑,这真的是 AI 该有的用法吗?
Skill就是为了专门解决该问题而诞生的。
它在 2025 年 10 月由 Anthropic 推出,12 月成为开放标准。
如今全网都在喊"Skill 改变生产力",但大多数人只是听说过,没真正搞懂它跟提示词、跟知识库、跟 MCP、跟智能体到底有什么区别,更没动手做一个出来。
本文一次讲透。
先理解一件事: Skill 不绑定任何 AI
很多人听到 Claude Skills 就以为这是 Claude 专属功能,其实完全不是。
Agent Skills 是 Anthropic 推出的开放标准,Claude 只是带头实现者。同一个 Skill 文件夹,既可以放在 ~/.claude/skills/ 给 Claude Code 用,也可以放在 ~/.cursor/skills/ 给 Cursor 用,还能给 OpenAI Codex、Gemini CLI、VS Code Copilot、JetBrains Junie 用。
你今天写的 Skill,明天可以无缝搬到另一个 Agent 上,投入不会被锁死在一家。
文章下面会以 Claude Code 为主举例(因为它是标准制定者,生态最全),但所有原理、写法、避坑经验,对所有支持 Agent Skills 的 AI 工具都通用。
看到 "Claude Skill" 时,你心里要等同于 "Agent Skill"。
一、Skill 到底是什么
一句话定义
Skill 就是一个文件夹,核心是一个叫 SKILL.md 的 Markdown 文件,告诉 AI 按你定义的 SOP 稳定执行某类专业工作。它把"某类事情应该怎么做"封装成可复用、可自动触发的能力模块。
它的本质是给通用 AI 装上的"扩展包"。
通用 AI 像出厂的裸机,智力够但不懂你的领域。Skill 是即插即用的功能模块——装上一个"小红书风格 Skill",AI 立刻变成懂你品牌的小编;
装上一个"周报 Skill",AI 立刻按你公司格式出周报。
而且这个"扩展包"不挑 AI:Claude Code、Codex、Cursor、Gemini CLI、Junie 都认得同一种格式。
你做的是 Agent Skill,不是 Claude 专属脚本。
和四个东西的边界
很多人把 Skill 和提示词、知识库、MCP、智能体混着说,其实分得很清:
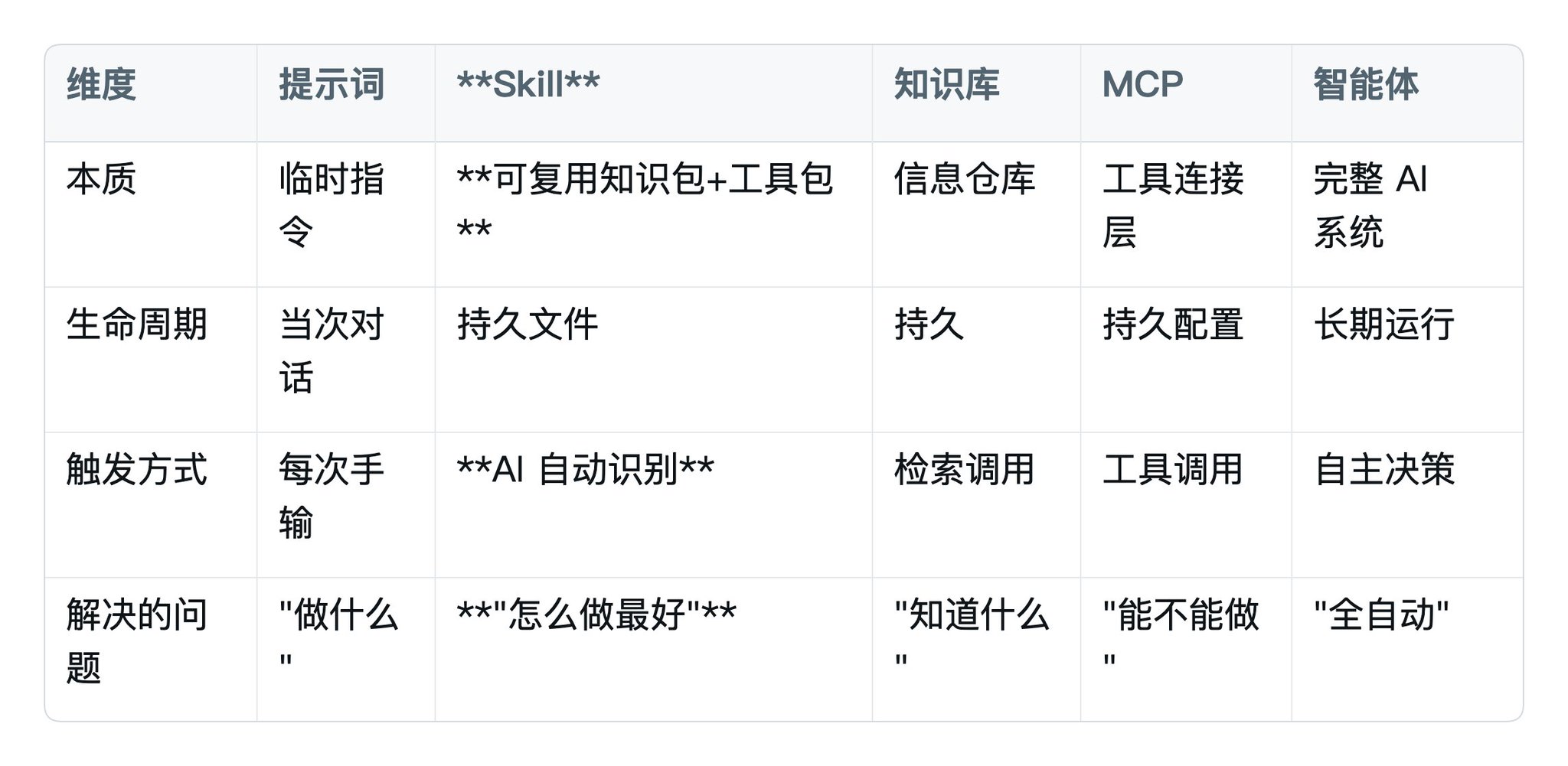
通俗类比:
- 提示词= 你给员工发了一条微信,说完就忘
- Skill= 你给员工写了一本工作手册放他桌上,还附带工具箱
- 知识库= 图书馆,告诉你世界上有什么
- MCP= 厨房里的各种厨具,解决"能不能做"
- 智能体= 整个员工系统,有记忆能决策,Skill 只是它身上的一个零件
这四件事不是互斥的。
实际工作里经常组合用:
MCP让 Claude 连到 Reddit 抓数据,Skill教它抓到数据后怎么筛选/分类/推荐,知识库提供品牌资料库,智能体是整个跑通的系统。
二、架构与运作机制
文件结构
skill-name/
├── SKILL.md (必需:YAML 元数据 + Markdown 指令)
├── scripts/ (可选:可执行代码,确定性任务)
├── references/ (可选:按需加载的参考文档)
└── assets/ (可选:输出用的模板/素材)
每个子目录解决的是不同问题,但服务于同一件事——省 context、稳品质:
- scripts/ 不占 context 又算得准
- references/ 按需载入不浪费空间
- assets/ 让输出格式标准化
三层渐进式披露(Progressive Disclosure)——Skill 设计的灵魂
Skill 的核心机制是三层加载,这是它能在十几个并存却不爆 context 的根本原因:
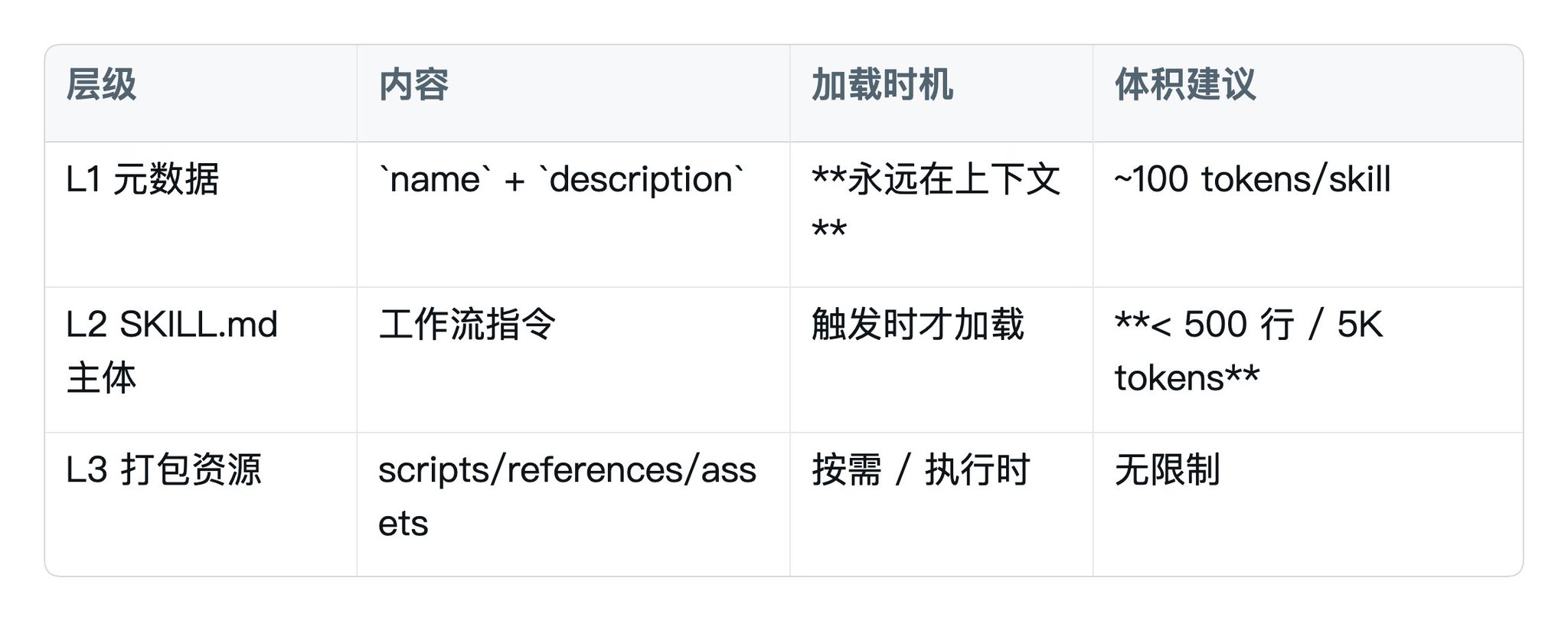
打个比方:
Claude 启动时只翻所有 Skill 的"封面",决定该用哪一本;
真要做事了才打开正文;
遇到需要查附录时才翻附录。
这套机制让你同时挂 17 个 Skill 也不会塞爆 200K 的 context 窗口。
YAML 元数据
---
name: your-skill-name
description: 这个技能做什么以及何时使用。包括触发上下文、文件类型、
任务类型和用户可能提及的关键词。
license: MIT
allowed-tools: Bash, Read, Grep
trigger_keywords:
- 关键词1
- keyword2
version: 1.0
---
字段说明:
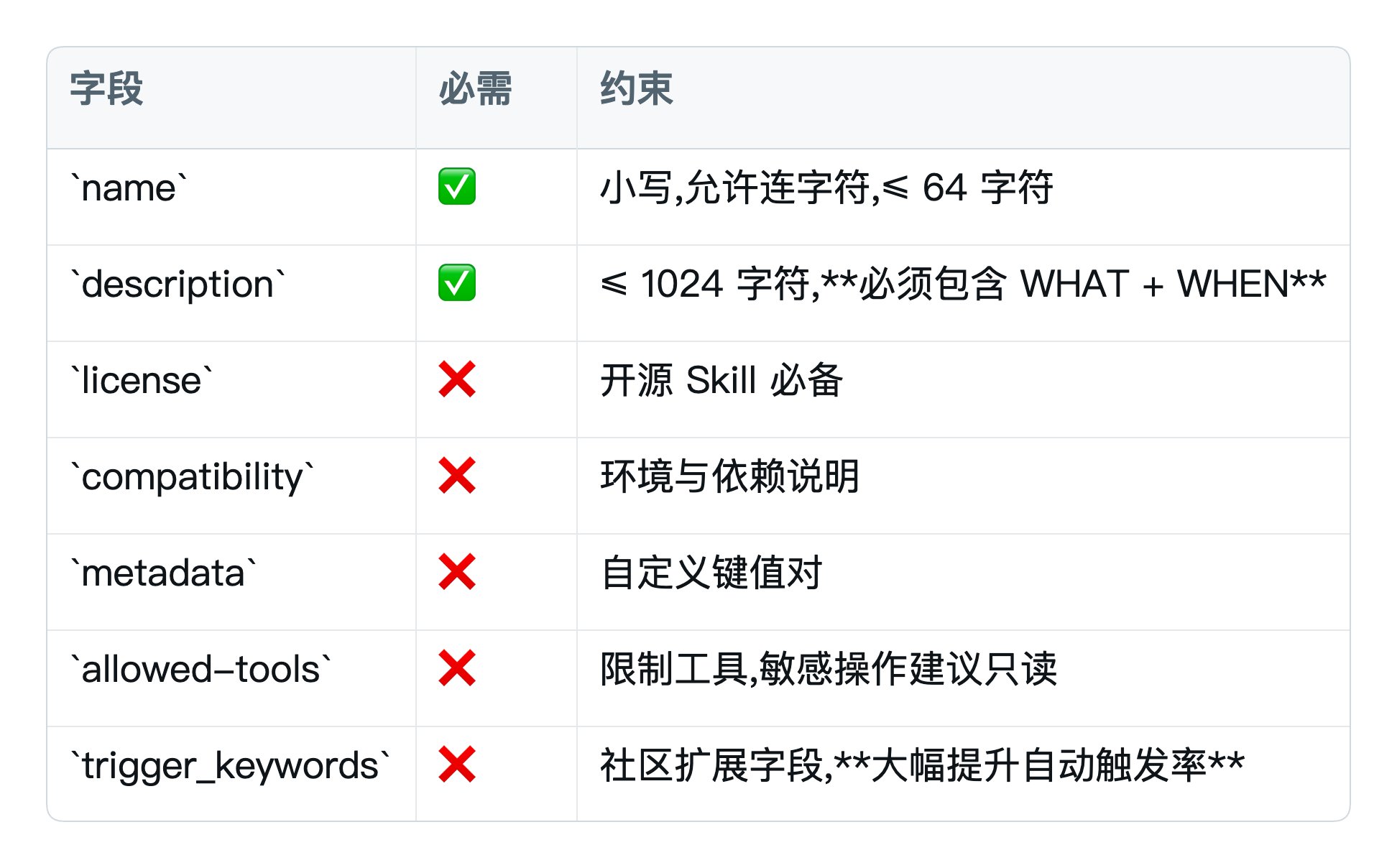
Description 决定生死
三层架构里,L1 的 description 是最关键的——它决定你的 Skill 会不会被触发。
几个核心事实:
- Claude 启动时只读所有 Skill 的 description
- 根据 description 做语义判断,不是关键字匹配
- Claude 倾向保守:不确定就不触发,实测描述模糊时触发准确率只有 55%
反例(永远不会被触发):
description: 帮助处理日常工作。
正例(Anthropic 官方推荐"pushy"风格):
description: 每日工作规划流程。当用户说"规划今天""daily planning"
"今日规划""开工"时使用。即使用户没明确说"规划"二字,
只要在早晨问"今天做什么",也务必触发此 skill。
写好 description 的三条铁律:
- WHAT + WHEN 一起写:既说做什么,又说什么时候用
- 触发词中英文双语都列:用户怎么说就匹配什么
- 宁可 pushy 不要保守:Anthropic 官方明确说,主流问题是欠触发
三、写好 Skill 的核心原则
三大原则
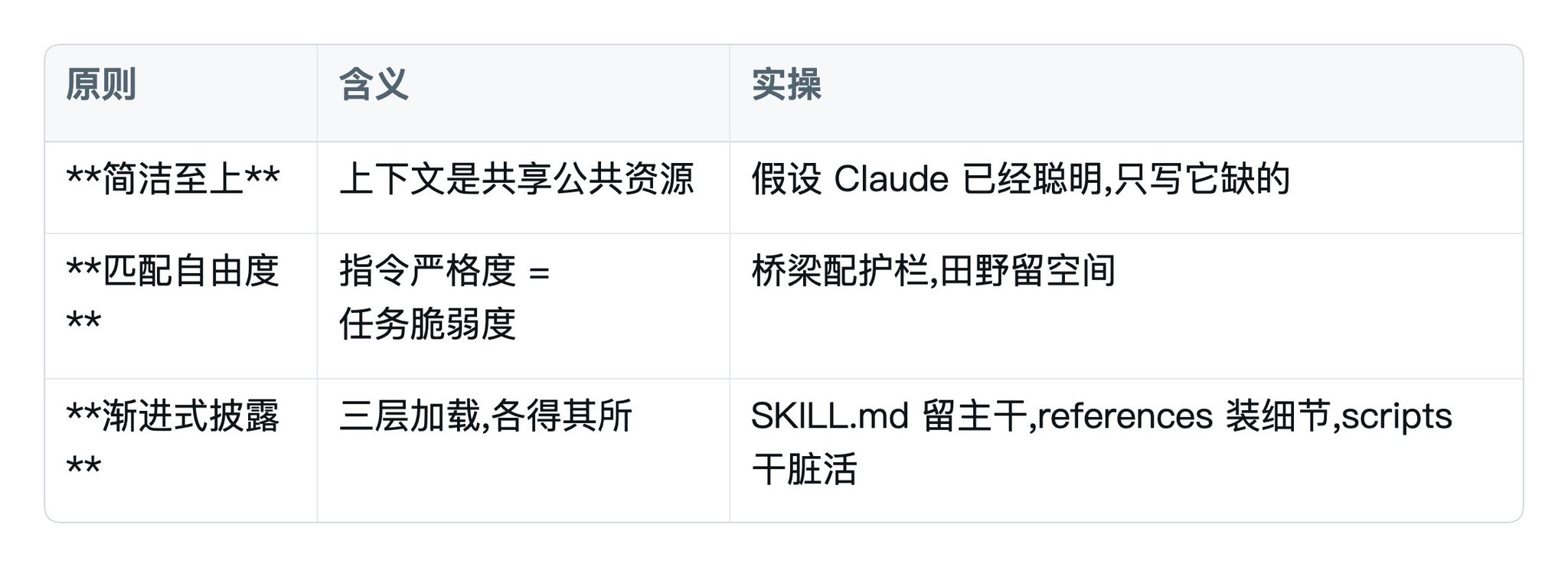
自由度怎么把握:
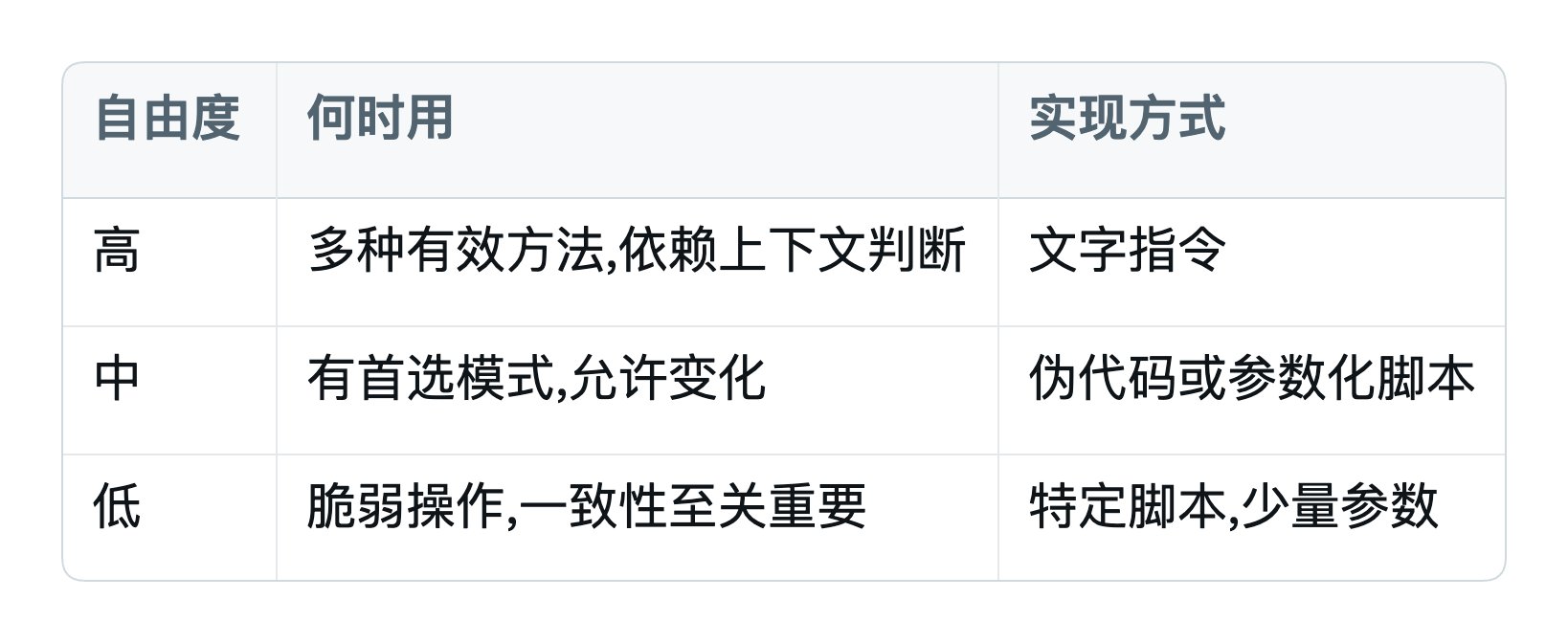
五种设计模式
Anthropic 从早期使用者归纳出五种 Skill 设计模式:

好用的 Skill 通常混用多种模式。
你不用刻意套,但知道有这些可能性,设计时会更有结构。
黄金法则: 用"为什么"代替"必须"
这是 skill-creator(Anthropic 官方做 Skill 的元 Skill)源码里的原话:
"Try to explain to the model why things are important in lieu of heavy-handed musty MUSTs."
(与其用一堆死板的 MUST 来压模型,不如跟它解释为什么这件事重要。)
反例:
ALWAYS 在执行命令前显示命令内容。NEVER 直接执行。
正例:
执行命令前先显示内容,因为使用者需要确认安全性。
未经确认就执行可能造成不可逆的损害。
第一种写法,Claude 只会照做这两条规则,规则没覆盖的情境(比如一个看起来安全但其实有风险的命令)它就傻了。
第二种写法,Claude 理解了"为什么是保护安全",遇到灰色地带也会倾向谨慎。
原因让模型举一反三,规则只能覆盖你想得到的情境。唯一的例外是输出格式:"输出一定要用这个模板"这种机械要求,没有"为什么"可解释,直接写死。
信息归属:别重复
skill-creator 还有一条铁律:
"信息应该存在于 SKILL.md 或 references 中——不能同时存在。"
SKILL.md 只留基本程序,详情移到 references。重复存放会导致后续维护时改一处忘另一处,产生不一致。
不要放的文件
Skill 是给 AI 看的,不是给人看的:
别加 README.md、INSTALLATION_GUIDE.md、QUICK_REFERENCE.md、CHANGELOG.md 这些人类文档,它们只会浪费 context。
四、动手做第一个 Skill
Anthropic 官方六步
skill-creator 内部定义的标准流程:
- Capture Intent: 让用户说清做什么 / 何时触发 / 输出格式 / 是否需要测试
- Interview & Research: 边角案例 / 输入输出格式 / 示例文件 / 依赖
- Write SKILL.md: 写草稿
- Test Cases: 写 2-3 个真实测试用例
- Run & Evaluate: 同时跑 with-skill 和 baseline 双盲对比,生成 benchmark
- Iterate: 根据反馈改,重跑,直到满意
普通人的四条快速路径

skill-creator: 写 Skill 的元 Skill
强烈推荐先装 Anthropic 官方的 skill-creator。
它是一个专门用来帮你做 Skill 的 Skill,启动后 Claude 会像访谈一样问你问题——你的工作流长什么样、什么时候该触发、有哪些边界条件——然后自动生成 SKILL.md 和资料夹结构。
安装命令:
帮我安装这个 skill,地址:https://github.com/anthropics/skills/tree/main/skills/skill-creator
克隆到 ~/.claude/skills
它不只是产出,还能帮你:
- Eval:自动生成测试案例,验证 Skill 能不能正确触发。
- Improve:根据测试结果自动优化 description 和指令,用 60/40 train/test split 防止过拟合
- Benchmark:追踪成功率、token 用量,甚至能跑 A/B test 两个版本盲测对决
一个最小示例
假设你是做小红书的美食博主,要把普通菜谱改写成小红书风格:
---
name: xiaohongshu-recipe
description: 把普通菜谱改写成小红书风格的美食笔记。
当用户说"转小红书版""改成小红书风格"时使用。
trigger_keywords:
- 转小红书版
- 小红书风格
- 改成笔记
---
# 小红书菜谱改写
## 执行规则
### 标题
- 必须带数字,比如"3 步做出""5 分钟搞定"
- 控制在 20 字以内
- 要有悬念或反差感
### 正文
- 开头一句话说清楚这道菜的亮点
- 食材列表用 emoji 标注
- 步骤用数字序号,每步不超过两行
- 语气活泼,像跟朋友聊天
- 禁止"首先""其次""综上所述"这类书面语
### 结尾
- 引导互动:"你们一般怎么做?评论区告诉我"
- 加 2-3 个相关话题标签
- 字数控制在 500 字以内
放到 ~/.claude/skills/xiaohongshu-recipe/SKILL.md,以后说"转小红书版"就自动触发。
从新建文件到能用,不超过 20 分钟。
五、安装、存放与跨工具
加载优先级(4 级)
Claude Code 按以下顺序查找,越具体的位置优先级越高:

经验:除非项目特定,都放个人级 ~/.claude/skills/ 统一管理,避免忘记自己有哪些 Skill。
三种安装方式:
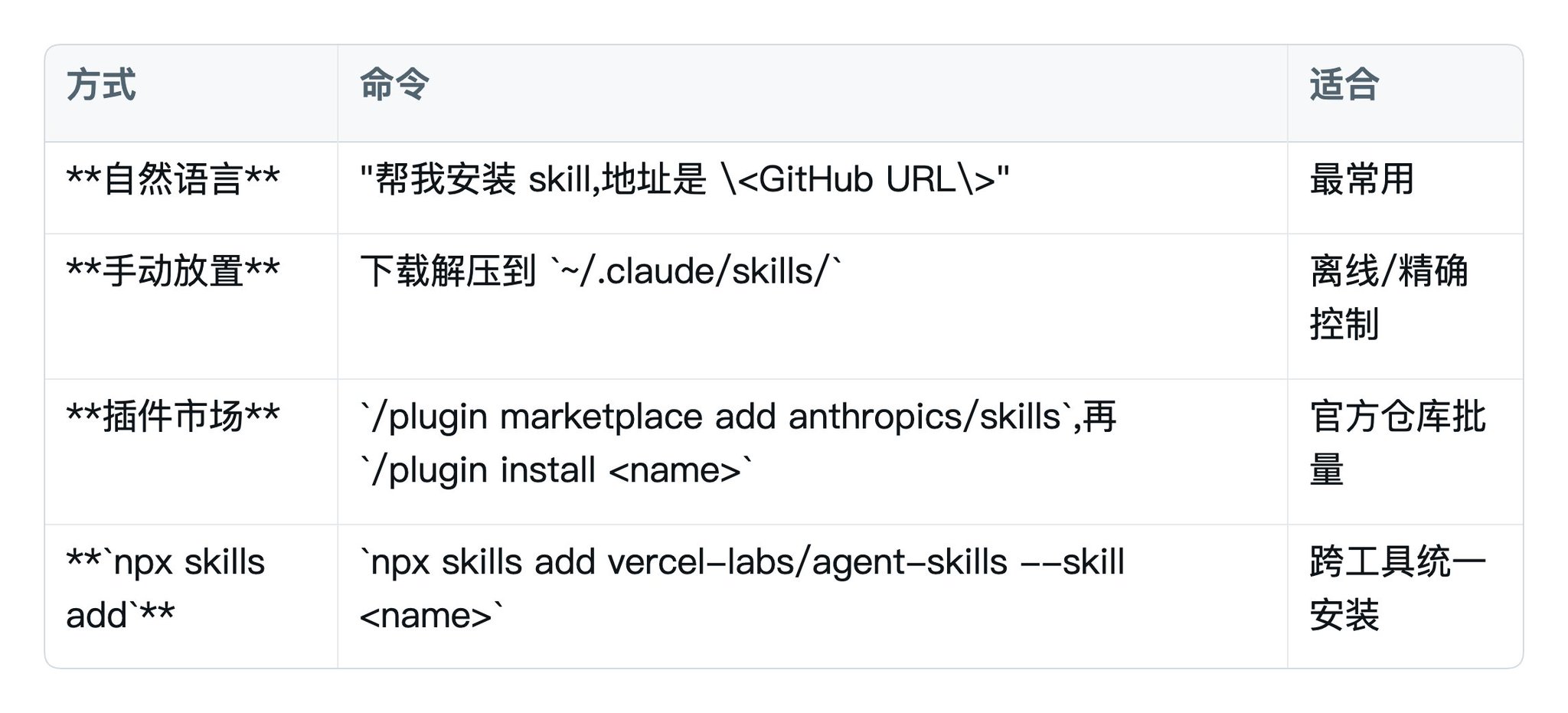
装完记得重启 Claude Code。
跨工具兼容(再强调一次)
引子里讲过 Skill 不绑定 Claude,这里看具体路径对照:
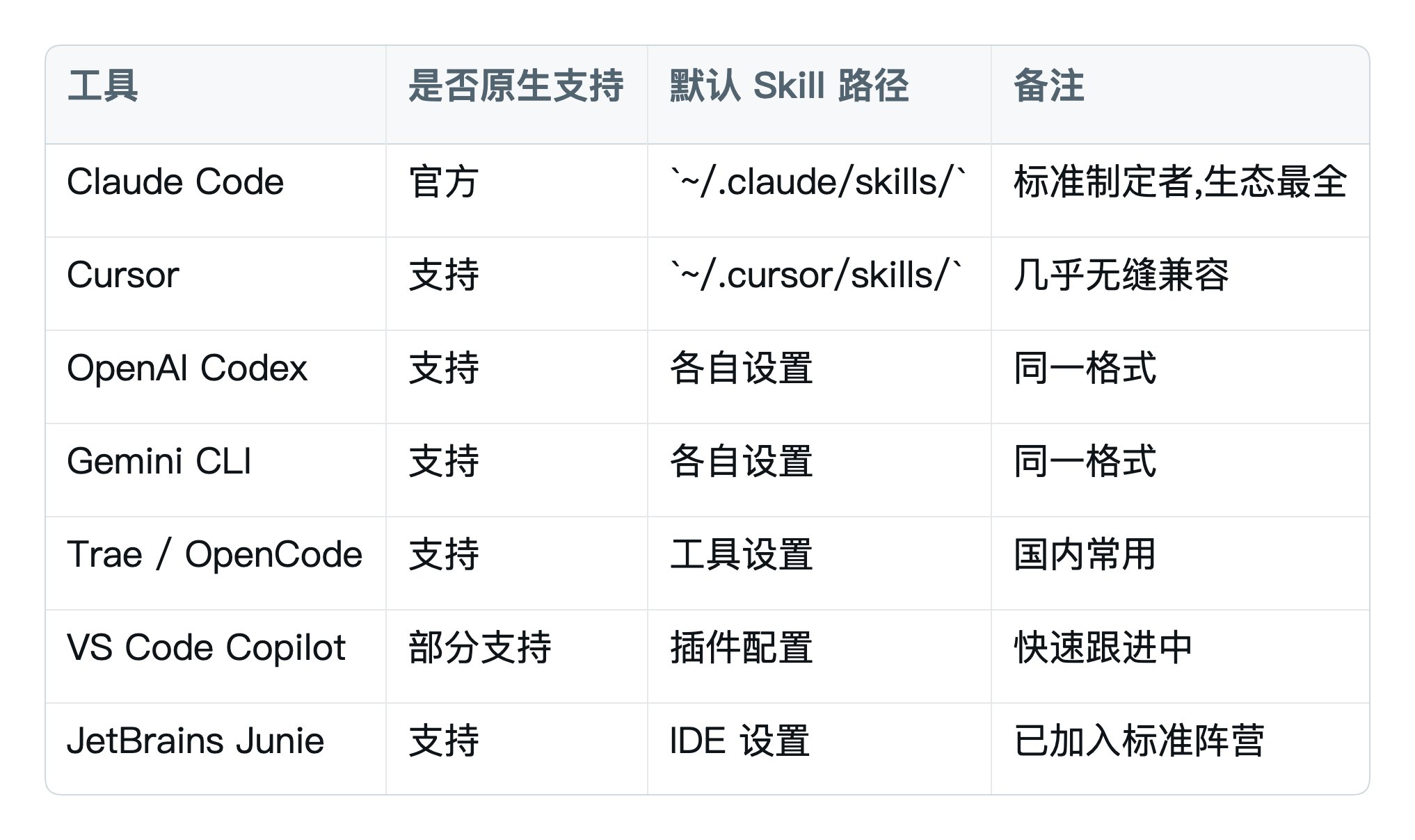
操作上的意义:
同一个 SKILL.md,把文件夹软链到不同工具的目录下就能用,不用为每个 AI 重写一遍。这是 Agent Skills 作为开放标准最大的红利。
国内用户痛点
- 官方 Claude 贵: 用中转 API 性价比高,或用 GLM 4.7 划算
- CC Switch: 开源工具管理多 API 配置一键切换 github.com/farion1231/cc-switch
- 原生安装比 npm 稳: curl -fsSL claude.ai/install.sh | bash
六、进阶——多 Skill 协作架构
拆分粒度
核心原则:每个 Skill 一个明确任务,不要做"万能 Skill"。粒度太粗,description 写不清楚,触发不精准;粒度太细,管理成本上来。
一个合理的颗粒度是:一个 Skill 解决一类问题,大约 200-500 行的 SKILL.md 主体。
实战案例:博客写作 Skill 套件。
不要做一个"全能写作 Skill",拆成 5 个协作:
~/.claude/skills/
├── blog-outline/ # 生成大纲
├── blog-writer/ # 写初稿(可调用 blog-outline)
├── blog-editor/ # 编辑润色
├── blog-seo/ # SEO 检查(用脚本算客观数据)
└── blog-meta/ # 生成元信息(标签/描述/社交文案)
协作模式:主 Skill 在 ## 步骤 里显式调用其他 Skill:
## 步骤
1. 如果用户没提供大纲,先调用 `blog-outline` skill 生成
2. 按 reference/style-guide.md 的风格规范写作
3. 使用 templates/article.md.tpl 作为基础模板
4. 输出完整 Markdown,含 frontmatter
这套拆分的好处:

五条工程经验
- 粒度要细:每个 Skill 一个明确任务
- 协作显式化:主 Skill 用 ## 步骤 显式调用其他 Skill
- 脚本承担计算:SEO 字符数、链接统计这类需要客观数据的部分一定用脚本,不要让模型估算
- 风格指南独立:把稳定的知识(写作风格/品牌规范)单独放 references/,改风格只动一个文件
- 模板兜底:模板提供"最差也不至于太离谱"的下限保证
七、专业级评测与迭代
Eval 体系:
skill-creator 给的标准流程:
- 在 evals/evals.json 写测试 prompts
- 同时跑 with_skill 和 baseline(无 skill),双盲对比
- 通过 agents/grader.md 给每个断言打分
- 用 aggregate_benchmark 出 pass_rate / time / tokens 报告
{
"skill_name": "example-skill",
"evals": [
{
"id": 1,
"prompt": "User's task prompt",
"expected_output": "Description of expected result",
"files": []
}
]
}
Description 自动优化
skill-creator 里最值钱的一段是 Description Optimization:
- 写 20 条 trigger eval queries(8-10 条应触发 + 8-10 条不该触发)
- 难点:不该触发的要写"近 miss"——共享关键词或概念但实际需要别的工具,不要写"写个 fibonacci"这种太明显的反例
- 自动优化脚本:60% train + 40% held-out test,防止过拟合
- 跑 5 轮,选 test 分数最高的描述
应触发的好例子:不是简单写"提取 PDF 表格",而是写得像真实用户:
"ok so my boss just sent me this xlsx file (it's in my downloads, called something like 'Q4 sales final FINAL v2.xlsx') and she wants me to add a column that shows the profit margin as a percentage."
包含文件路径、个人背景、列名值、随意的口语、可能的拼写错误。
迭代心法
skill-creator 原文有四条:
- 从反馈中泛化:不要为单个 case 加 fiddly 规则,如果某问题反复出现,试试换个比喻或工作模式
- 保持精简:看 transcript 找浪费时间的指令,删掉不出力的部分
- 解释 why:LLM 有 theory of mind,会举一反三
- 看 transcript 找重复工:如果每个 case 子代理都独立写了 create_docx.py,说明应该 bundle 进 scripts/
第一版必然不完美
一个真实的迭代案例:一位作者的 /daily skill 改到 v6 才稳定。
- v1:步骤不清楚、路径写错、有些情况没处理
- v2:加内容发现系统整合
- v3:发现周进度计算常出错,加明确的计算规则
- v4:加自动触发——周二提醒跑周会、月初提醒归档
- v5:加 iPhone 轻量模式(检测环境,手机上跳过需要 Python 的步骤)
- v6:才算"好用"
Skill 不是写完就丢的设定档,它是你工作流的活文件。每改一次,你对自己的工作流就多理解一层。
八、什么时候才该做 Skill
不是所有事都值得做 Skill。只有以下三种信号之一出现,才值得动手:
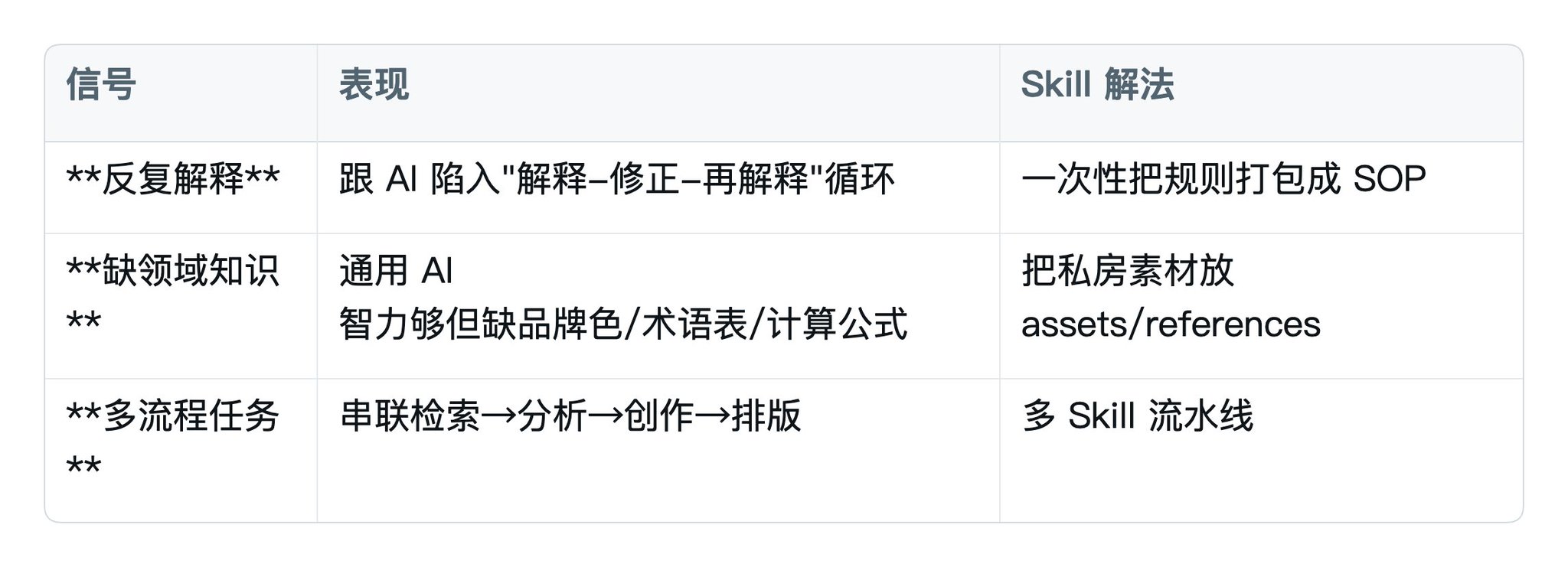
反过来:什么时候不要做
- 一次性任务:做完就不用了,直接 prompt 解决
- 过度封装:三个用法就开始拆 Skill,维护成本远大于收益
- 追求完美:想 v1 就完美,等真用起来才发现假想需求
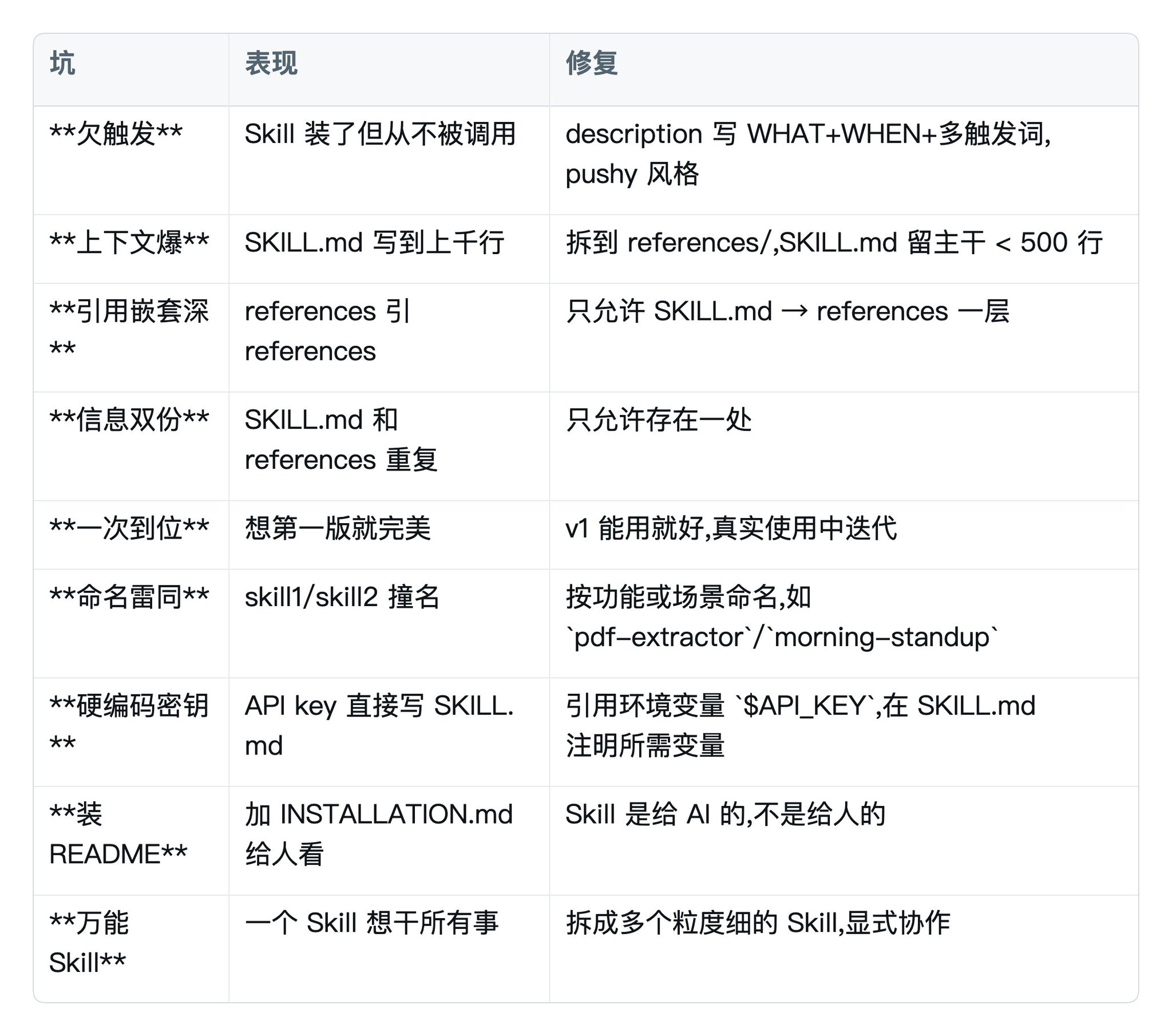
九、避坑清单
十、生态与必装清单
Skill 资源地图

必装 Skill 清单

十一、Skill 的商业潜力
Skill 不只是个人效率工具,它在重新定义 AI 应用的生产方式。
过去,开发一个垂直 AI 应用要漫长的开发周期、昂贵的研发成本、技术团队的高门槛。
现在:
- 零代码门槛:不会写代码也能造垂直 Agent
- 极速验证:数周开发周期被压到几小时甚至几分钟
- API 服务化:把 Skill 封装成 API,给现有产品快速赋能 AI
- Skill 可以当产品卖:本质和当年卖 Prompt 合集一样,但门槛/价值都更高
几个真实案例:
- Article-Copilot:一个 Skill 实现素材清洗→逻辑梳理→正文写作的全链路 Agent,媲美独立 AI 产品
- AI Partner Skill:让通用 Agent 学会深度记忆,塑造真懂你的 AI 伴侣
- 面试准备 Skill:输入公司名 + 岗位 + 简历,自动抓公司信息 + JD + 简历差距分析,生成完整面试准备报告。有人用这个拿到了同花顺的面试机会
- Super 黄的玩法:几十个 Skill + 定时任务,凌晨 0/1/2/3/4 点各跑一个,早上起来几份报告全部出来
任何深耕一个行业的人,把自己的经验和方法论提炼成 Skill,既能自用省时间,也能打包成产品出售。
结语
如果说 Agent 是 AI 世界的躯体,Skill 就是注入其中的灵魂。
这就像 Steam 平台与创意工坊的关系,正是因为有了极具扩展性的设计架构,游戏才拥有了无限生命力。
Skill 本身不难,就是 Markdown 加上一些结构。
但它代表的趋势很重要: AI 从"你每次都要教它"变成"你教一次就好"。
而且这个标准是开放的。
你今天在 Claude Code 写的 Skill,明天可以搬到 Cursor、Gemini CLI、Codex 上用,并不会被绑死在一个平台上。
这句话送给所有还在观望的人:
Skill 不是设计出来的,是从一次又一次重复劳动里长出来的。先跑通一件事,再封装,好的工作流是迭代出来的,不是规划出来的。
打开终端,装上 skill-creator,把你今天重复说了第三遍的那段话,写成你的第一个 SKILL.md。
黄小木|T11级架构师|《30天2万粉2周2k刀》作者|持续分享 AI 信息、副业赚钱、程序员转型OPC心得|X:@ai_xiaomu