
最近给客户做了几个 HTML 展示页。
设计稿图片是 AI 出的,最省事的做法:直接丢给模型,让它照着图写成 HTML。
你大概率也尝试过。
也大概率,翻过车。
设计稿看着像真产品。代码一跑起来,立刻像十年前的模板站:字重发闷,间距散开,插画糊成一片,logo 还变形。
这时候很多人会怪模型代码能力不行。
我更倾向于另一个判断:问题通常出在任务拆分上。
你让模型一次完成三件事:读懂页面结构,复刻视觉样式,还要临时画出复杂资产。前两件它能做得不错,第三件很容易把页面拖垮。
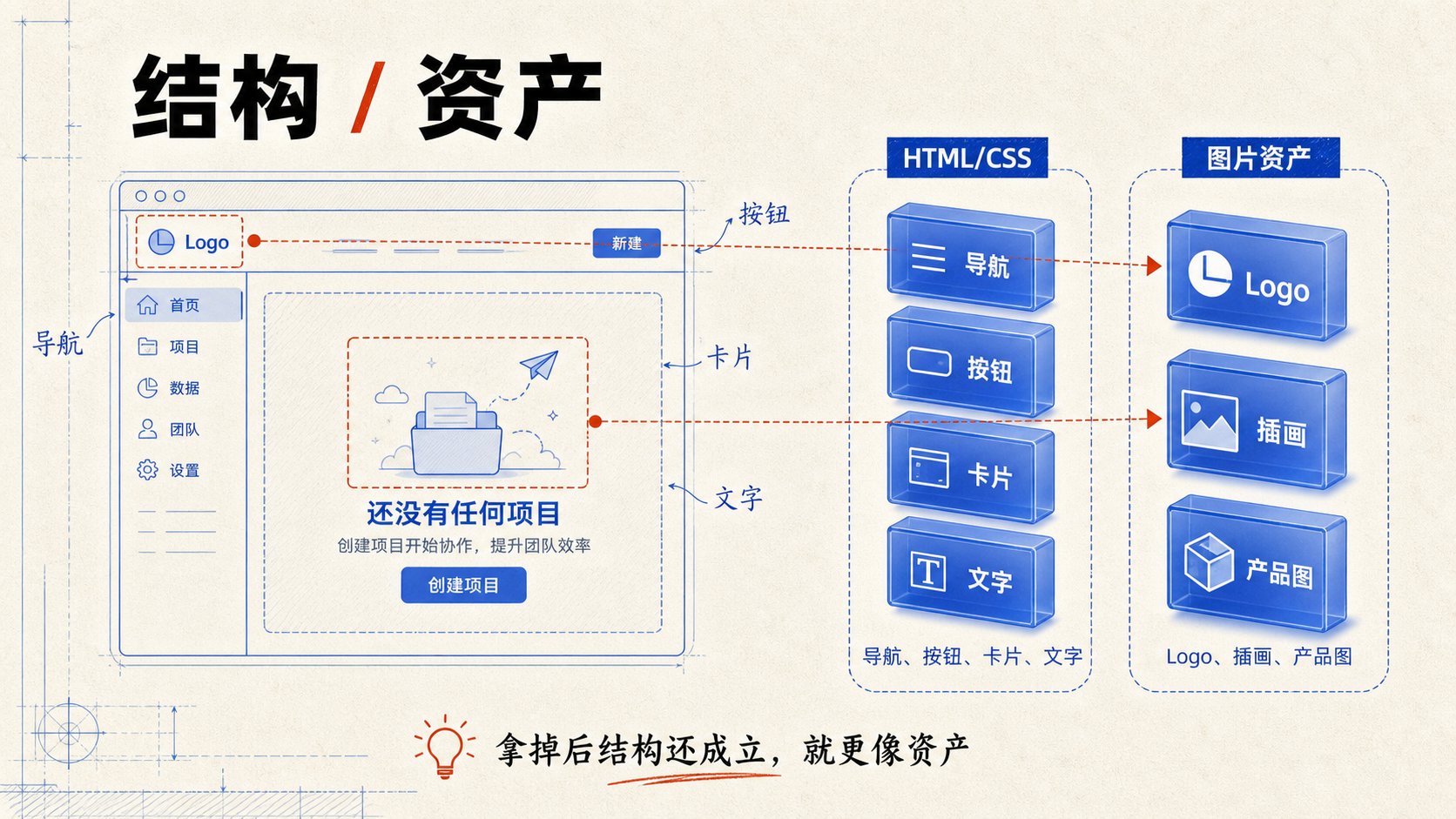
UI 还原要拆成三层看:结构、样式、资产。
结构和样式交给 HTML/CSS。logo、插画、产品图、3D 视觉这类东西,单独当成图片资产处理。后面再通过截图、对比、修正,把误差一点点压下去。
这套流程跑起来后,页面会明显少一点“AI 糊出来”的味道。
先把任务拆开
很多人给模型的指令只有一句:
根据这张图生成 HTML。
这句话太宽了。
它同时包含三类任务:
- 识别页面结构
- 复刻视觉样式
- 生成复杂视觉资产
模型看图、认布局、估字号、写 flex/grid,都还可以。它真正容易出问题的地方,是把本该作为图片处理的东西,硬塞进代码里。
比如设计稿中间有一张空状态插画。你让模型照图写 HTML,它可能会用 CSS 画几个圆、几段渐变,或者塞一段抽象 SVG。最后得到的东西,轮廓像插画,细节像临时拼出来的几何块。
模型未必笨。只是你把“生成素材”的任务塞进了“写代码”的通道。
更合理的做法,是提前告诉它:
- 哪些元素要写成代码
- 哪些元素只需要留位置
- 哪些元素后面单独生成成图片
这一层拆清楚,后面才有得调。
SaaS 空状态页面如何拆分代码和资产
拿一个 SaaS 空状态页面看。
左侧栏、菜单、顶部区域、卡片、按钮、文字层级、空状态容器,这些都适合用 HTML/CSS 复刻。它们的本质是布局、颜色、字号、间距、边框和圆角。
但有两类东西不要硬画:
- 左上角的 logo
- 中间的空状态插画
它们属于视觉资产。
如果硬让模型用 CSS 或 SVG 画,结果大概率会变形。你想要的是 logo,它给你一个“有点像 logo 的符号”;你想要的是插画,它给你一坨颜色接近的形状。
我一般会这样处理:
- 先把整体 HTML 搭出来,logo 和插画的位置用灰色占位块放着。
- 单独裁出 logo 和插画区域,作为参考图。
- 用图生图生成高清资产,处理好透明底,再替换回页面。
判断一个元素该不该做成资产,有个简单办法:
把它拿掉以后,页面结构还成立吗?
logo 拿掉,导航栏还是导航栏。插画拿掉,空状态容器还是空状态容器。它们是贴上去的视觉层,不属于页面骨架本身。
这类东西,别交给 CSS 硬撑。
Landing page 的右侧插画,要单独处理
再看 landing page。
右侧那张大插图,很多人会直接从原始设计稿里裁下来用。刚放进去好像还行,一放大就糊。
原因很简单:原图是一整张页面,分辨率分散在整张画面里。插画只是其中一块。你裁出来的局部,本来就达不到高清素材的标准。
这时候不要对着低清局部继续放大。放大只会把模糊放得更大。
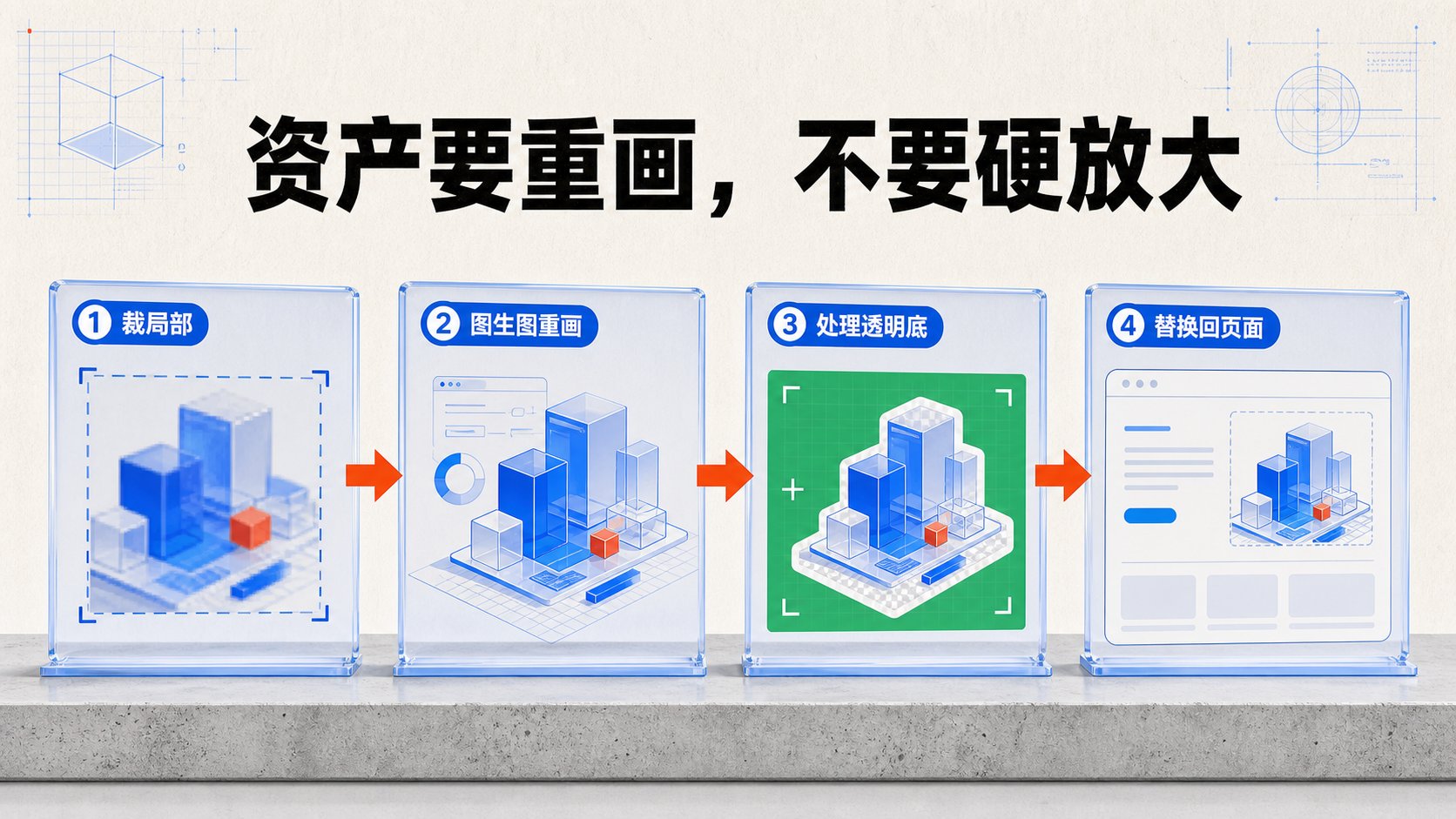
更好的链路是:
- 局部裁图:把插画所在区域裁出来,当参考。
- 图生图重画:保留风格、构图和主色,重新生成一张高清插画。
- 背景处理:如果插画要叠在页面背景上,就做透明底。
透明底有两种办法。
如果接口支持 alpha 通道,直接生成透明背景 PNG,省事。
如果第三方渠道不支持透明通道,就用绿幕。让模型生成纯绿色背景的插画,再用程序把绿色扣掉。逻辑不复杂:遍历像素,只要绿色明显高于红色和蓝色,并且超过阈值,就把这个像素的 alpha 设成 0。
from PIL import Image
import numpy as np
img = Image.open("asset_green.png").convert("RGBA")
arr = np.array(img)
r, g, b = arr[:, :, 0], arr[:, :, 1], arr[:, :, 2]
# 绿色明显占主导的像素,判定为背景,置为透明
mask = (g > 100) & (g > r * 1.4) & (g > b * 1.4)
arr[:, :, 3][mask] = 0
Image.fromarray(arr).save("asset_transparent.png")
阈值要看实际图片调。边缘有时还要羽化,不然会出现硬边。
绿幕不好看,但它适合后处理。白底也能扣,遇到浅色插画更容易误伤。
很多 UI 还原翻车,问题不在布局,而在资产。
完整流程:6 步跑一遍
前面讲的是判断。落到执行,可以按这 6 步走。
第一步:视觉拆解
先别写代码。
让模型只看图,输出一份页面地图。先要拆解,暂时不要结果。
可以这样问:
仔细观察这张 UI 设计稿,不要写任何代码,只输出以下信息:
-
页面整体布局:几栏、各栏占比、主要区域划分。
-
从上到下、从左到右的组件清单。
-
配色:主色、背景色、文字色、强调色,给出近似 HEX。
-
字体层级:标题、正文、辅助文字的大致字号和字重。
-
间距和圆角风格:紧凑还是宽松,大圆角还是小圆角。
-
复杂视觉资产:logo、插画、产品图、3D 图等,需要单独生成,别用代码画。
做完视觉拆解,你手里会有一张施工图。后面每一块交给谁,清楚很多。
第二步:资产分离
根据页面地图,把元素分成两堆。
代码负责:导航、按钮、表格、卡片、输入框、普通图标、文字排版、分割线、标签。
图片负责:logo、复杂插画、产品截图、人物图、3D 图、品牌主视觉、空状态图。
分类时就问一个问题:拿掉它,页面结构还成立吗?
成立,多半是资产。不成立,多半是结构。
这里分错,后面会一直跑偏。模型硬画资产,页面会变廉价;把普通 UI 也拿去生图,又会增加抠图和替换成本。
第三步:先搭 HTML 骨架
第一版不要追像素级。
先把布局骨架搭出来:整体用 flex 或 grid 定比例,各区域按原图排列摆上,填入基础颜色、字号、行高和圆角。资产位置用灰色占位块标出来,尺寸也写上。
这版只看结构:左右比例对不对,内容顺序对不对,主要区域有没有错位。
骨架歪了,细节调再多也没用。
第四步:生成并替换资产
把第 2 步分出来的资产,一个个走“裁参考图、图生图重画、处理透明底”的流程。
生成时要带风格约束。比如:
扁平插画风格,主色 #4F46E5,线条简洁,背景纯绿色,用于后续抠图。
资产做好后,再替换掉灰色占位块。
这里要按占位块尺寸摆,别让图片把布局撑开。很多页面看着廉价,根源常常在资产:插画分辨率低、logo 变形,或者资产风格和页面不在一个系统里。
第五步:浏览器截图
把 HTML 放进真实浏览器渲染,然后截图。
用 Playwright 就行。重点是视口宽度要和设计稿一致。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page(viewport={"width": 1440, "height": 900})
page.goto("file:///path/to/index.html")
page.screenshot(path="render.png", full_page=True)
browser.close()
一定要看截图。
代码里看不出字重是否发闷,也看不出行高是否太松。按钮宽了 8px,插画低清,阴影太脏,这些都要等渲染后才露出来。
第六步:对比和修正
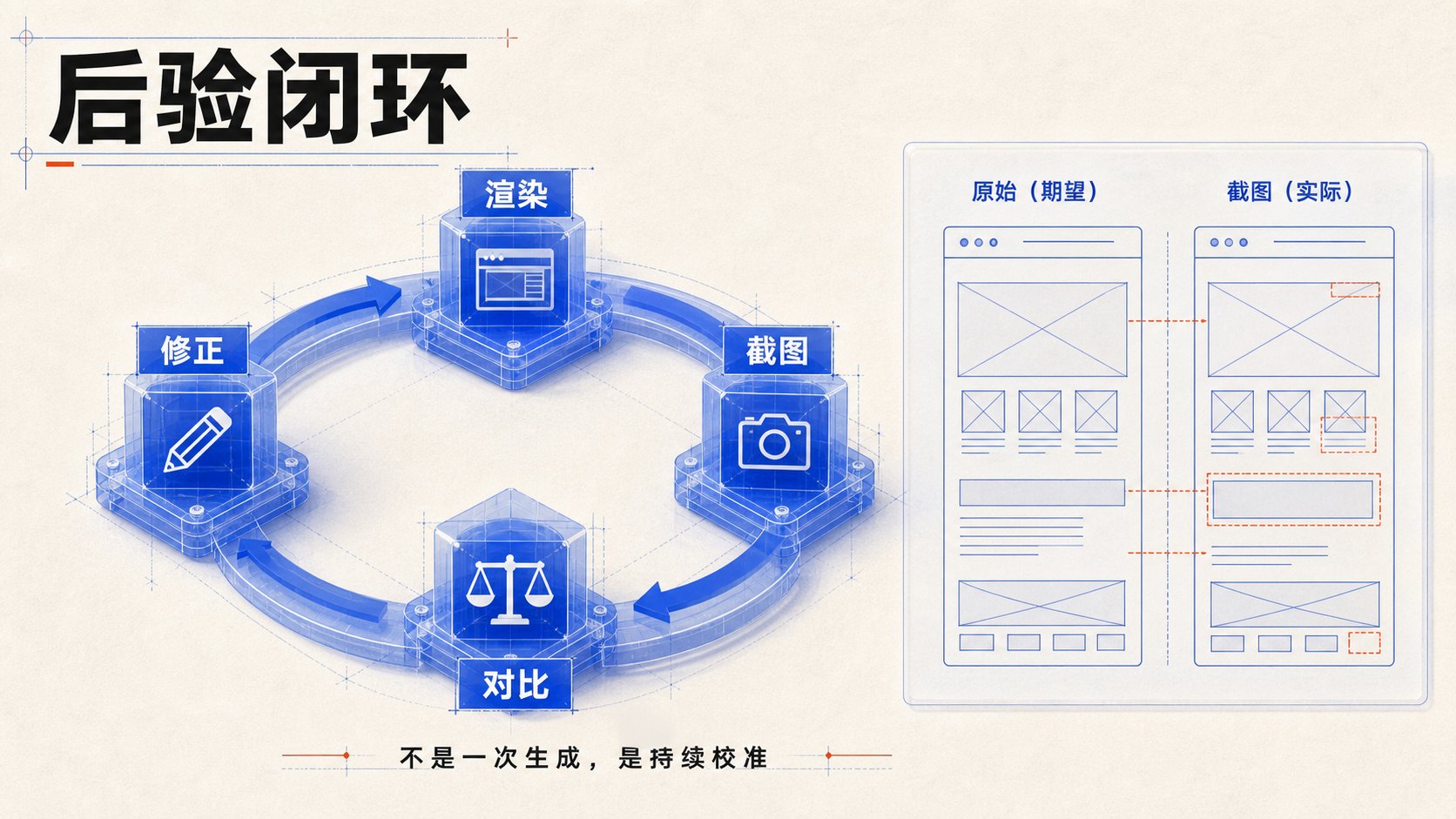
把原始设计稿和浏览器截图放在一起看。
两种办法可以一起用:
- 左右并排:让模型逐区域指出差异。
- 叠加差异图:把两张图缩到同尺寸后半透明叠加,或者用 ImageChops.difference 算像素差。
对比的价值,是把问题变得可定位。
不要只说“不像”。这句话没法执行。
你要补具体描述:
- 标题字重太高,改成 medium。
- 这里换行位置不对,应该一行放下。
- 右侧插图偏大,缩到 80%。
- 两个按钮之间间距太松,收窄到 12px。
描述越具体,模型改得越准。
然后继续修,继续截图,继续对比。质量就是在这个循环里出来的。
复现不像,通常落在 6 类误差里
页面不像,不要急着重写。
先归类。
- 布局误差:元素位置、宽高、对齐、边距不对。回去查 flex/grid 的比例和 padding/margin。
- 字体误差:字号、字重、行高、换行位置不对。单独调 font-size、font-weight、line-height。
- 色彩误差:背景色、边框色、阴影、按钮色偏了。用取色工具从原图取 HEX,别只靠模型估。
- 资产误差:logo、插画、产品图糊了,或者风格不一致。重新生成资产,调提示词。
- 密度误差:整体太松、太挤、太压、太空。调整间距系统,不要逐个像素硬拧。
- 响应式误差:桌面端像,移动端崩。单独写移动端断点,别指望一套样式通吃。
AI 容易发现大错位,但经常忽略廉价感。
廉价感通常来自字重、间距、密度和资产质量。这几样需要人盯。你不指出来,它可能会觉得已经差不多了。
后验机制才是质量来源
AI 写完代码后,并不知道自己渲染出来像不像。
在代码层面,很多问题是隐形的:字重偏高,行高偏松,按钮宽了几个像素,插画分辨率不够。
这些都要等页面跑起来才看得见。
流程里一定要有后验机制:
渲染,截图,对比,修正。
第一版代码只是起点。真正的还原质量,来自后面的反复校准。
这也是我后来对 UI 还原最大的改观:别把它当成一次性生成任务,把它当成一轮又一轮的误差收敛。
skill 自动化了哪些重复动作
上面这套流程,手动跑一遍很烦。
裁图、图生图、抠图、替换、截图、拼对比图,再把结果喂回模型。做一次还行,做多了就想把它封起来。
我把它整理成了一个 skill,主要自动化这些动作:
- 识别页面里哪些资产需要单独生成
- 对局部区域做图生图
- 对绿幕或白底资产做抠图
- 把资产替换回 HTML
- 用浏览器截图
- 生成左右对比图和布局差异图
- 让模型基于截图继续修正
后面我会整理好放到 GitHub 开源分享给大家。
skill 没有魔法。
它更像一套流程外壳,把重复劳动包起来。流程没想清楚,工具只会更快地产出一版粗糙页面。
Codex 内置生图会让这件事轻一些
最早我以为,图生图环节必须接外部渠道。
后来发现,Codex 里已经内置了生图工具。在 Codex 环境下,可以优先用它自己的工具生成图片,不一定要额外配置外部平台。
具体工具名以发稿时实际可用的为准,这里不写死版本号。
这点不改变方法,只是让资产处理少折腾一点。
今晚可以直接用的检查清单
如果你手上正好有一张 AI 生成的 UI 设计稿,先别急着问“帮我生成 HTML”。
先问 5 个问题:
- 这个页面能拆成几个区域?
- 哪些元素是结构,哪些元素是资产?
- 哪些资产需要单独图生图?
- 第一版 HTML 截图和原图差在哪里?
- 这个差异属于布局、字体、颜色、资产、密度,还是响应式问题?
能回答这 5 个问题,复现效果通常会好很多。
因为你不再赌模型一次猜对。
你是在带着它校准。