
大多数人做研究的方式都一样。
开十几个标签页,看视频,读文章,随手记点笔记。一小时过去,打开了二十个标签页,笔记软件里三行字,什么都没整理好。
有更好的办法。
这篇文章教你用 Claude Code、NotebookLM 和 Obsidian 搭一套研究系统,能自动调查任何话题——市场趋势、新兴技术、加密生态、内容赛道——而且越用越顺手。
搭建时间:30 分钟以内。
这套系统为什么有效
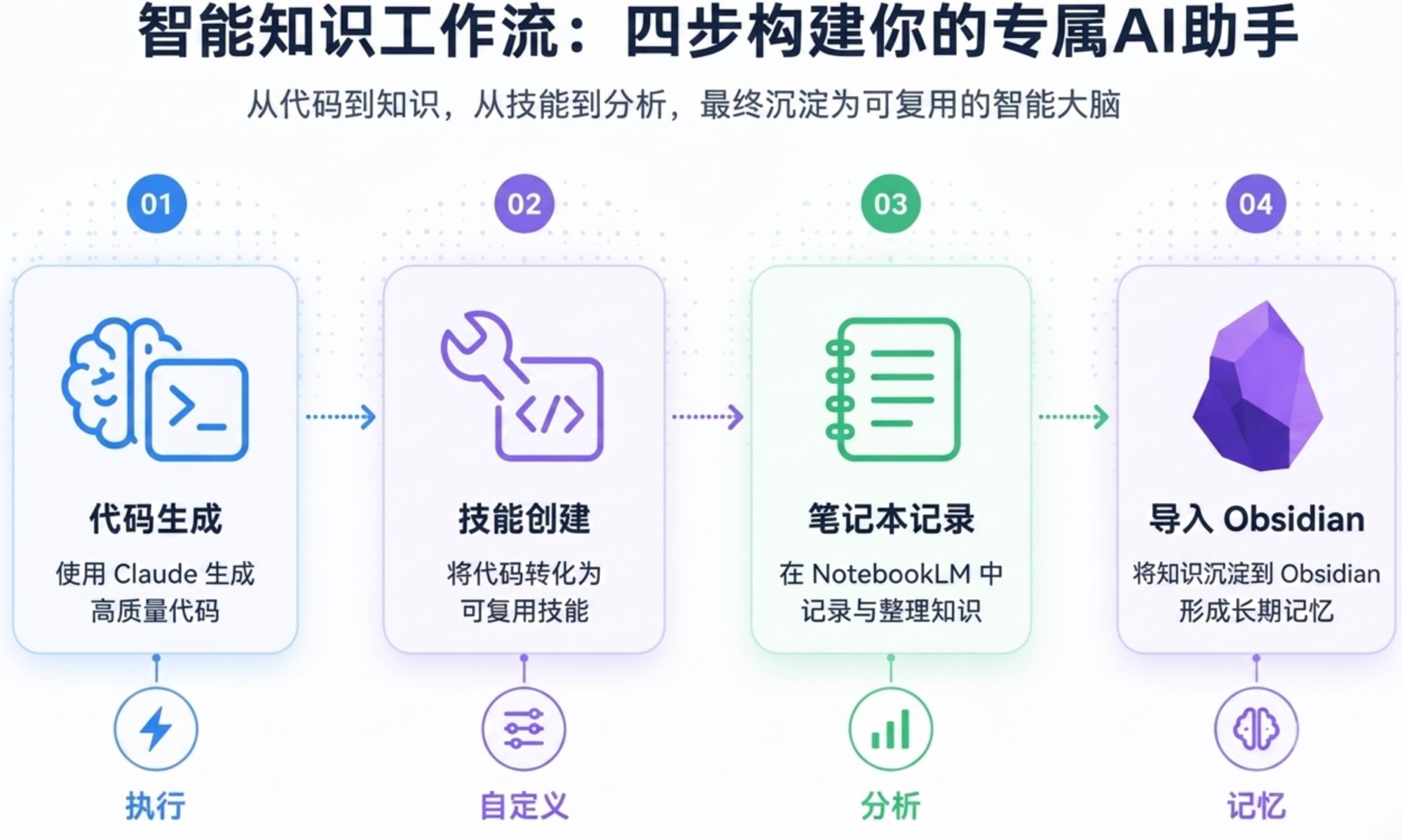
四个工具,各管一层。
Claude Code——执行层。用自然语言告诉它要做什么,它会运行命令、调用技能、管理文件,把整个流程跑起来。
Skill Creator——定制层。Claude Code 的插件,让你用人话描述想要什么功能,它帮你生成并安装对应的技能(Skill,类似手机的 App,装上之后就多了一个可用命令)。不需要写代码。
NotebookLM——分析层。谷歌的 AI 研究工具,能读取你的来源资料,生成深度分析、摘要、信息图、闪卡、播客脚本。关键是:把分析任务交给 NotebookLM,用的是谷歌的算力,不消耗你的 Claude 额度。
Obsidian——记忆层。本地的 Markdown 知识库,存储系统产出的所有内容。用得越久,Claude Code 对你的思维方式了解越深,输出越贴近你真正想要的结果。
四个工具组合在一起:一条能执行、能分析、能自我改进的研究流水线。
第一步:安装 Skill Creator
打开 Claude Code。确保你在 Obsidian vault(本地笔记库文件夹)里——这一步很关键,Claude Code 生成的文件才能被 Obsidian 识别到。
运行命令:
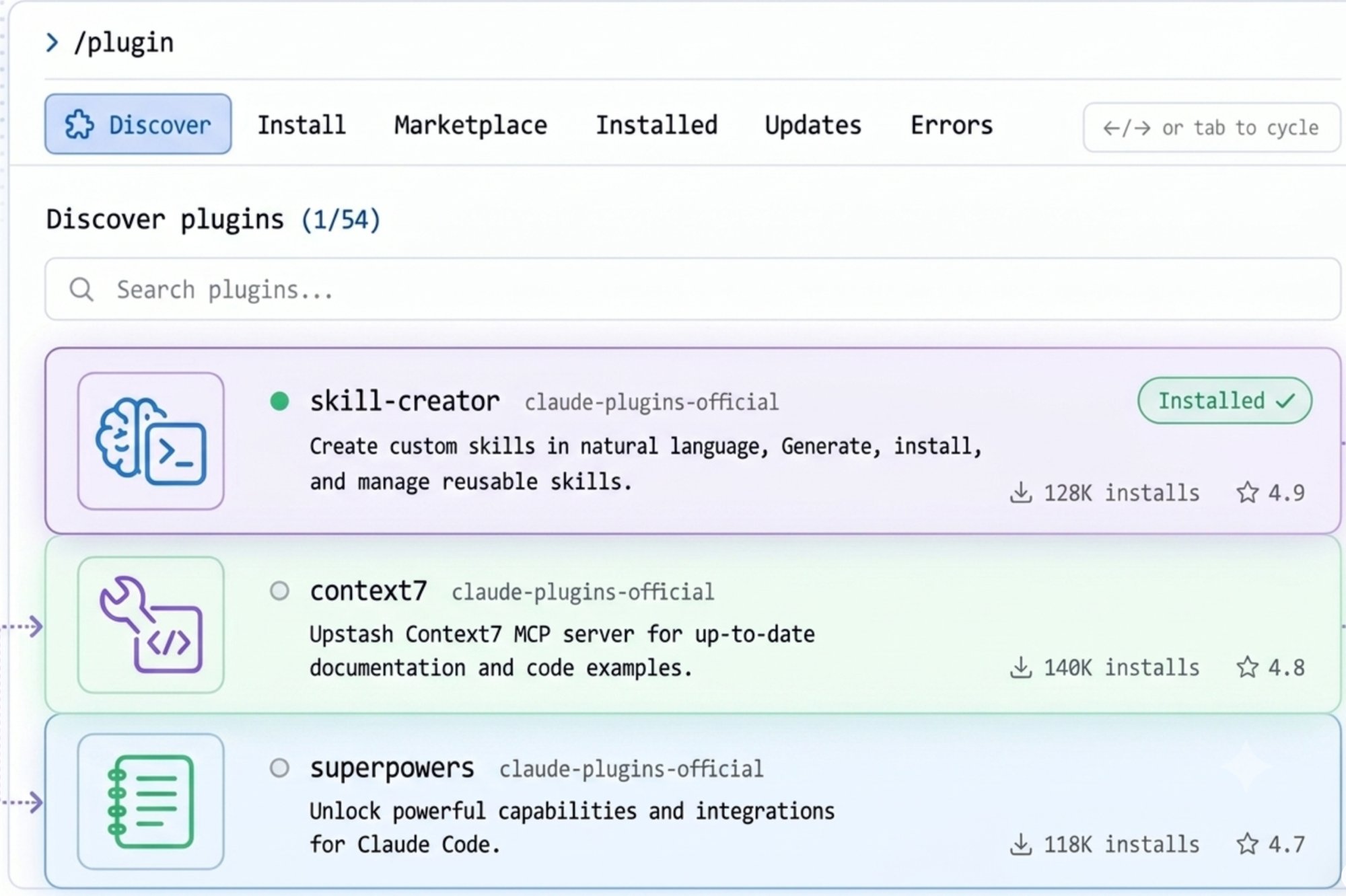
/plugin
搜索 skill-creator,安装,退出 Claude Code,重启 Claude Code。
完成之后,你就能用自然语言描述功能,Claude Code 帮你创建任何技能。
第二步:创建 YouTube 搜索技能
这个技能让 Claude Code 能搜索 YouTube,抓回结构化的视频数据——标题、频道名、订阅量、播放量、上传时间、链接、互动比率。
在 Claude Code 里运行:
/skill-creator 我想创建一个搜索 YouTube 并返回结构化视频结果的技能。
使用 yt-dlp 按关键词搜索,默认返回前 20 条结果,
每条视频包含:标题、频道名、订阅量、播放量、时长、上传日期和链接。
默认过滤最近 6 个月的内容,支持 --months 参数调整时间范围。
额外计算播放量/订阅量比值作为互动指标。
输出格式清晰,用分隔线分开每条结果,数字用易读格式显示。
Claude Code 会生成技能、安装、确认。之后你就有了 /yt-search 命令。
注意:需要在电脑上安装 yt-dlp。如果还没有,先装好再继续。
第三步:安装 NotebookLM-py
NotebookLM 没有公开 API。要让 Claude Code 连上 NotebookLM,用的是一个开源项目 notebooklm-py。
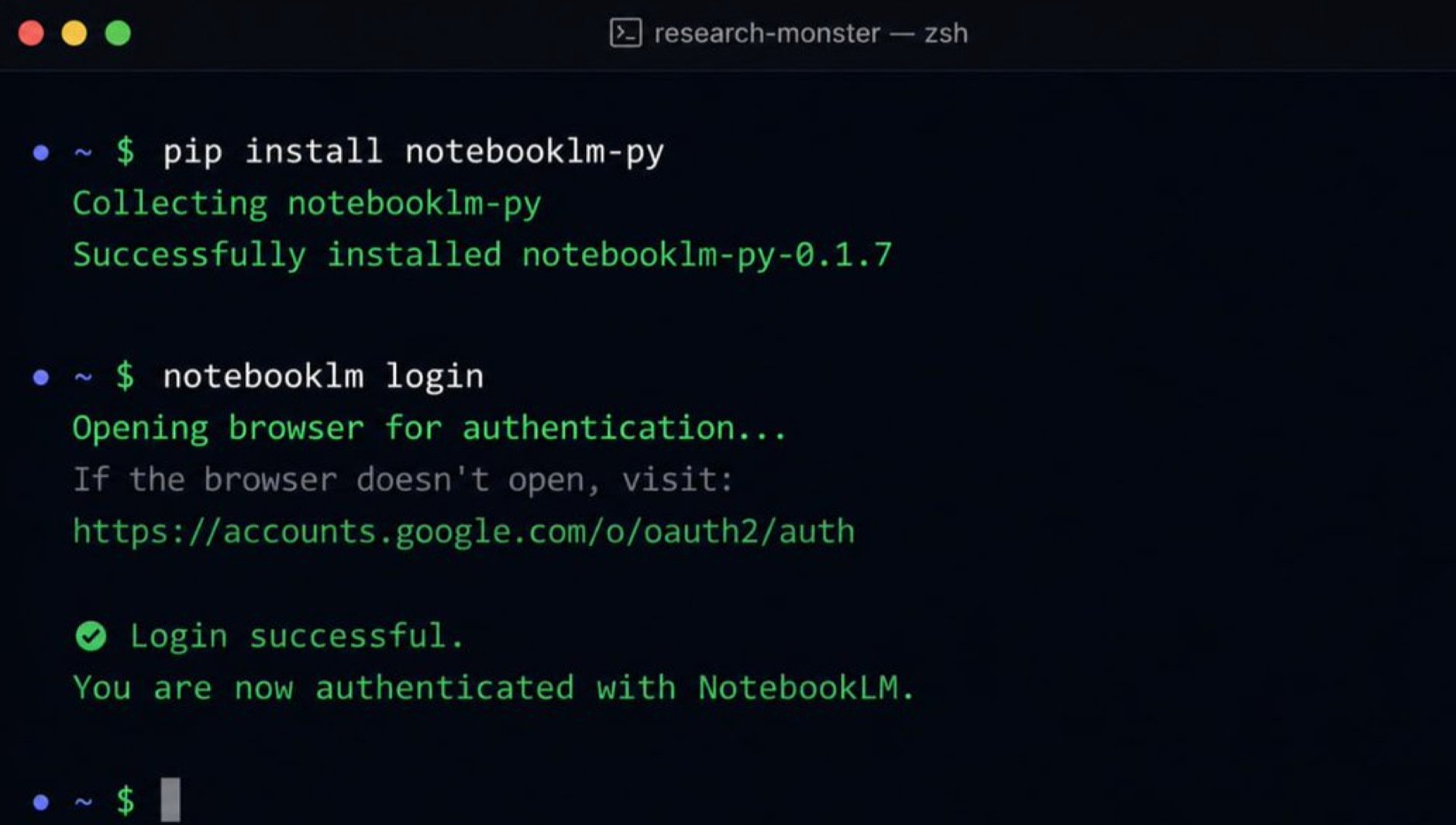
在普通终端窗口里运行(不是在 Claude Code 里):
pip install notebooklm-py
然后登录:
notebooklm login
浏览器会弹出来,登录你的谷歌账号,完成。连接建立好了。
注意:notebooklm-py 是第三方开源项目,不是 Google 官方 API。连接方式随时可能因 Google 的调整而失效,使用前确认项目仍在维护。
第四步:创建 NotebookLM 技能
现在教 Claude Code 怎么用 notebooklm-py。在 Claude Code 里运行:
/skill-creator 创建一个让我们能最好地使用 notebooklm-py 工具的技能。
参考 GitHub 仓库 github.com/teng-lin/notebooklm-py,
构建一个能够:创建新笔记本、添加来源(YouTube 链接、文本、文件)、
对来源运行分析、生成交付物(音频概述、思维导图、闪卡、信息图)的技能。
这给 Claude Code 装好了完整的 NotebookLM 技能,支持 NotebookLM 的所有操作——每个笔记本最多 50 个来源,全部交付物类型都能用。
第五步:把所有东西接成一条流水线
这一步才是整套系统真正强大的地方。
不用手动先跑 YouTube 搜索,再把结果发给 NotebookLM,再请求分析——你只需要建一个技能,一条命令把所有步骤全部跑完。
在 Claude Code 里运行:
/skill-creator 我想创建一个 YouTube 研究流水线技能,
把 yt-search 技能和 NotebookLM 技能结合起来。
使用这个流水线技能时,我希望它:
接收我想研究的主题,用 yt-search 技能在 YouTube 找 10 条相关视频,
用 NotebookLM 技能创建新笔记本,把视频来源加进去,
然后根据我输入的研究主题做分析。
另外问我要不要生成交付物——NotebookLM 可以做闪卡、信息图、思维导图、音频概述。
如果我没有指定交付物,默认不生成。
分析完成后,把所有内容以 Markdown 文件存到 vault,同时在对话里展示。
输出里包含完整的 YouTube 搜索元数据——使用的来源、播放量、频道名、互动比率。
实际跑一次是什么样
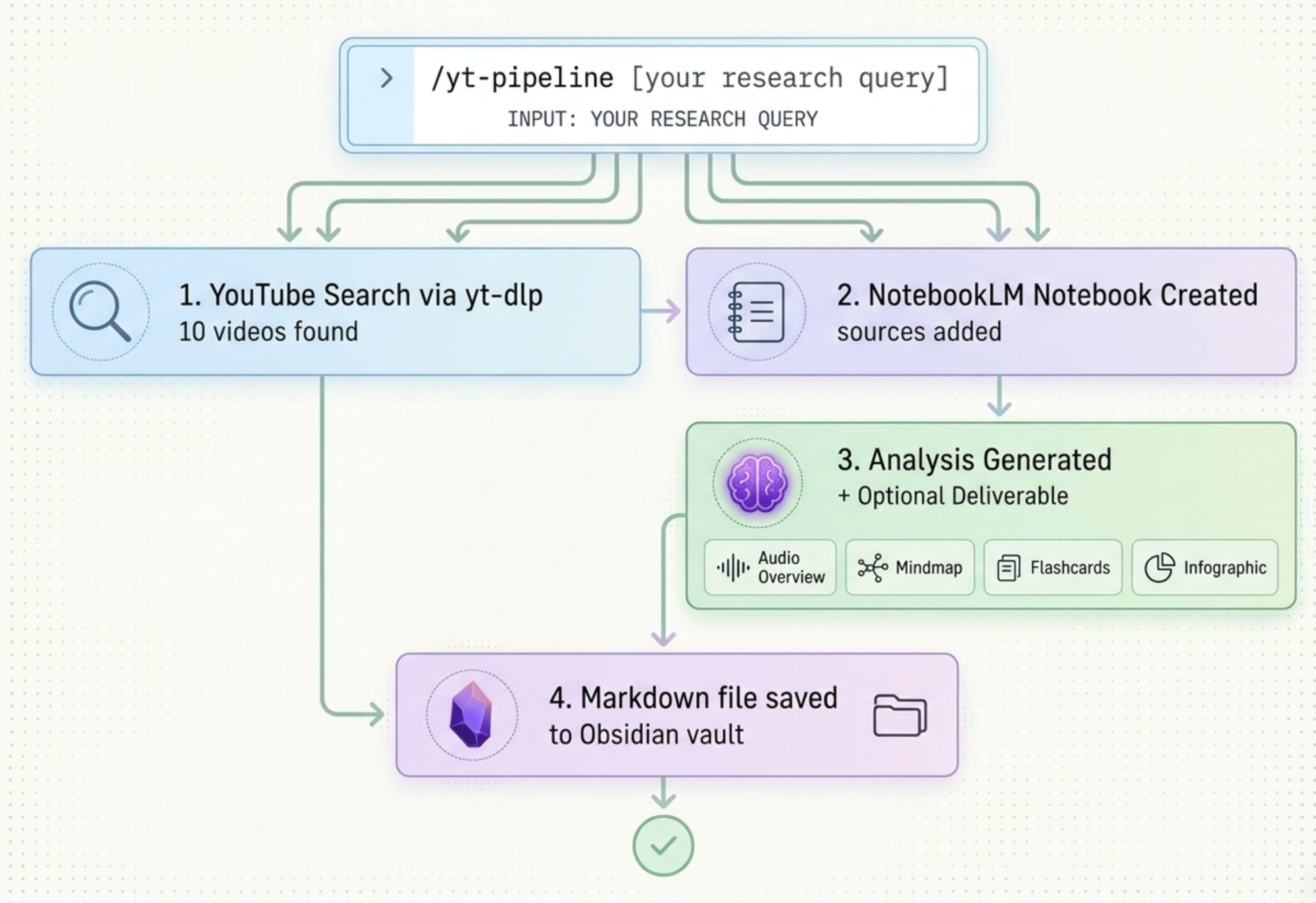
技能装好以后,假设生成的命令叫 /yt-pipeline,一次真实的研究是这样的:
/yt-pipeline 我想研究 2026 年的 AI Agent 框架。
开发者真正在用哪些框架——LangGraph、CrewAI、AutoGen、Agno,还是别的?
我想了解是什么在驱动这个话题的播放量,社区里有哪些争议,
有哪些异常表现的内容,哪些角度还没有被覆盖好。
找 10 个相关来源,推送到新的 NotebookLM 笔记本,
跑完整分析,生成一张信息图展示这个生态的全貌。
Claude Code 启动流水线。调用 YouTube 搜索技能,找到 10 条视频——横跨框架教程、对比测评、开发者观点——把链接传给 NotebookLM,建好笔记本,跑分析,请求信息图。
总处理时间:原教程测试约 6 分钟,实际时间因网络和账号状态而异。
其中大部分时间是 NotebookLM 在谷歌服务器上处理,不是你的 Claude 额度。
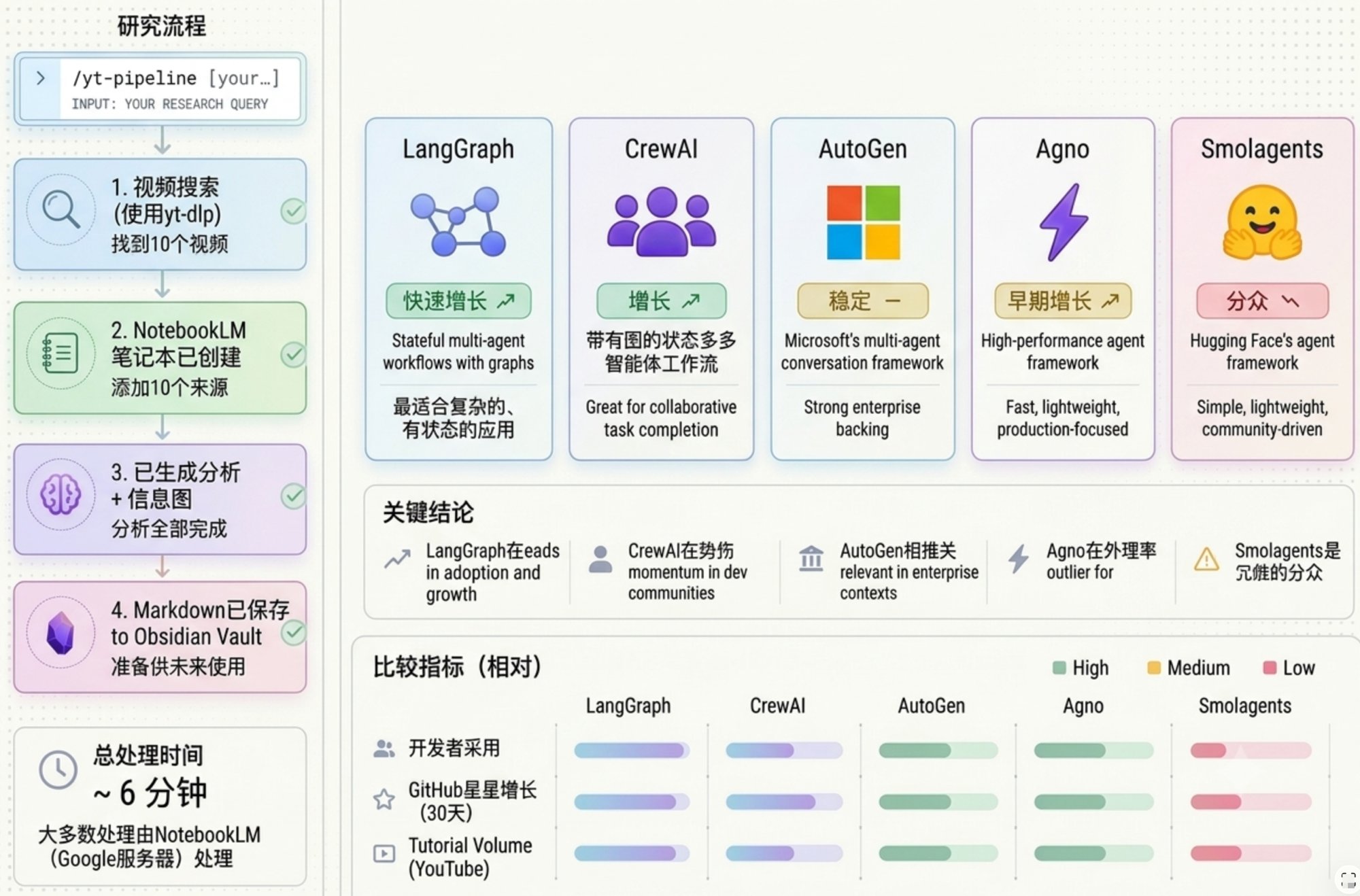
回来的结果:
- 完整分析报告——哪些框架在上升、哪些在高原期、开发者真正在抱怨什么、互动异常的内容、还没有人覆盖的内容角度
- 一张 AI Agent 框架生态信息图
- 一个直接保存进 Obsidian vault 的 Markdown 文件,结构清晰、带链接,随时可以在后续研究里引用
Obsidian 让它从工具变成系统
上面说的这些,单独用一次就是个不错的研究工具。
Obsidian 让它变成会复利的东西。
流水线产出的每个 Markdown 文件都落进你的 Obsidian vault。时间久了,你的 vault 成了一个有结构的知识语料库——话题、来源、分析、规律、结论全在里面。
Claude Code 能读取这些文件,能看到它们之间的关联,能理解你反复关注哪些话题、你觉得哪种分析有用、你喜欢什么输出格式。
vault 里的 claude.md 文件(Claude Code 的个人配置文件,相当于给 AI 设定的长期工作规矩)是让这件事变得明确的地方。它告诉 Claude Code 怎么和你配合工作——你的惯例、输出偏好、内容结构方式。
每次研究结束后,可以对 Claude Code 说:
能帮我更新 claude.md,让它更好地反映我的工作方式、分析思路和输出偏好吗?
Claude Code 会读最近的对话,识别你的规律,更新文件。
一周做一次。一个月之后,输出开始贴近你真正想要的,不需要每次都详细解释。一年以后,你有了一个吸收了几百次研究会话、理解你思维方式的助手,而不是一个每次都从零开始的工具。
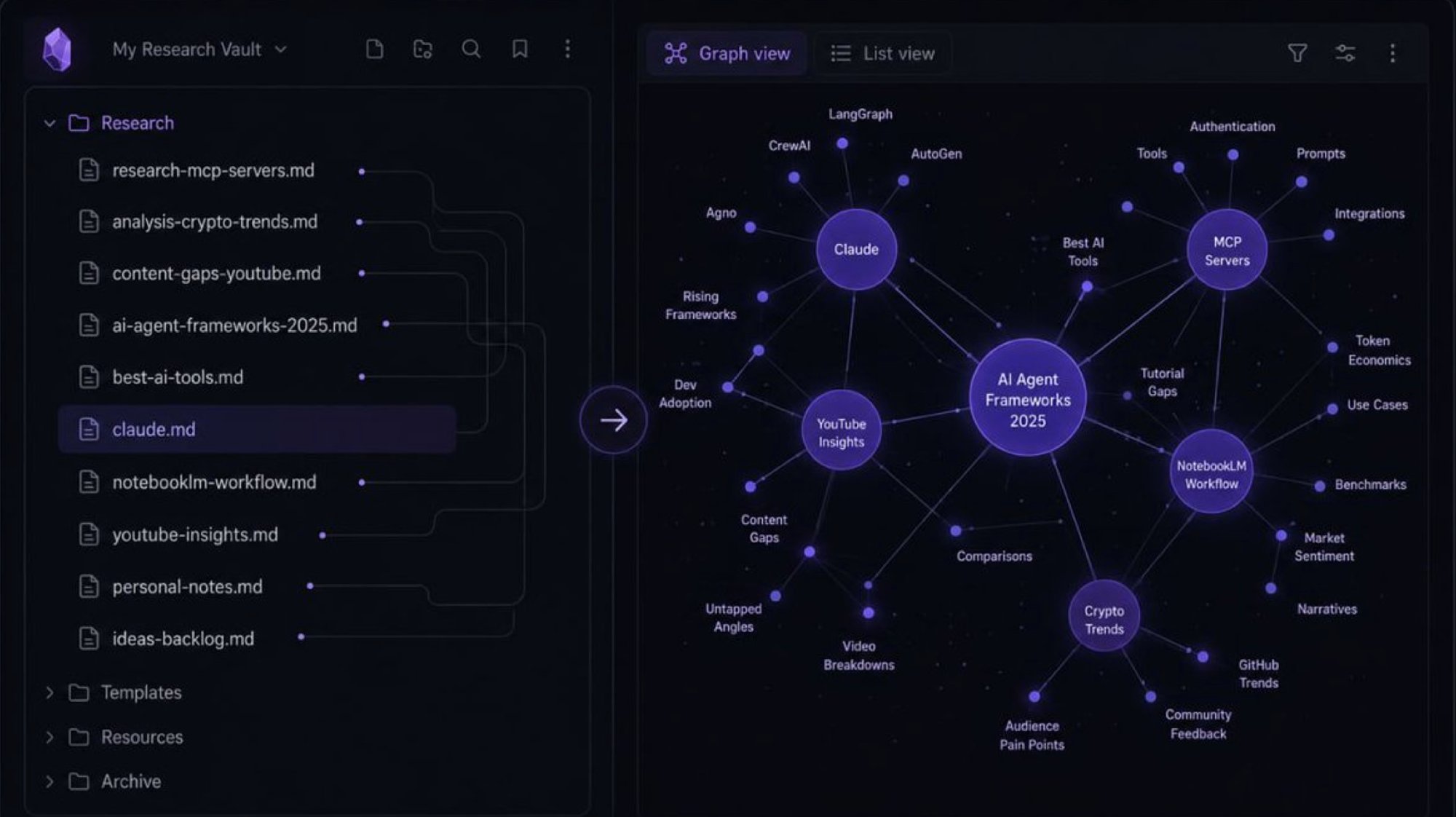
数据源可以换,框架不变
YouTube 只是其中一个数据源,不是这套系统的本质。
本质是这条流水线的结构。
你可以把 YouTube 换成任何 Claude Code 能访问的数据源:
- PDF——学术论文、行业报告、白皮书
- 公开网页——新闻文章、技术文档、博客
- 本地文件——你自己的笔记、导出数据、字幕文件
- 谷歌云端硬盘——已有的文档和表格
流水线模板不变,换源,保留结构。
研究一个加密生态,用白皮书和公开文档。分析一项新技术,用 YouTube 上的技术演讲。摸清一个内容赛道,分析哪些内容在传播。研究市场动态,用公开报告。
无论什么场景,流水线、分析层、记忆系统都是同一套。
30 分钟搭起来,第一次用就值回来了。