
你是不是也有过这种体验:明明记得自己存过一篇很好的文章,真要用的时候翻遍整个笔记库,就是找不到。最后重新打开了 Google。
公众号、知乎、网页剪藏、PDF、视频转写、AI 对话截图,收藏夹越来越满。三个月后想不起标题,记不得关键词,搜也搜不出来。
你也看过别人用 Obsidian 搭的知识图谱,节点密密麻麻,连线纵横交错,看起来特别炫。但你自己打开 Obsidian,里面还是一堆散落的文件,图谱上稀稀拉拉几根线,根本串不起来。
问题不是你记不下来。是你记完以后,再也没人管过。
传统笔记的卡点
传统笔记最大的问题就在这:只进不出。
文件夹要求你提前判断分类。标签要求你持续手动打标。刚开始还行,资料一多,维护成本就非常高。
你存的不是知识库,是一个越来越大的仓库。东西都在,但没人整理,没人索引,没人告诉你哪些互相关联、哪些已经过时。
更麻烦的是,AI 时代信息只会越来越多。旧的笔记系统无法满足「持续整理、长期调用、跨资料提问」这些需求。
这时候你需要的,是一个能帮你持续维护这套东西的人。或者说,一个 AI。
为什么现在需要 AI 知识库
过去笔记软件主要解决一件事:存下来。Notion、Obsidian、Bear、飞书文档,各有所长,但本质都是容器。
现在真正难的不是存。是资料太多、来源太散、更新太快,回头找不到,找到了也要重新理解一遍。
你试过没有:你记得自己存过一篇讲某个方法的文章,但就是想不起标题、想不起关键词。翻文件夹翻半天,搜也搜不出来。最后只能重新去网上找。
AI 知识库跟传统笔记的区别,不在「存」,在「维护」。
你用 AI 不是为了多一个输入框。是让它帮你把资料重新组织成可提问、可追溯、可持续更新的结构。你问一个问题,AI 从你已经存过的笔记里找素材、找依据、找相关概念,而不是从互联网重新搜。
把「我存过什么」变成「我现在能从已有笔记里找到什么、组合出什么」。这才是 AI 知识库真正有价值的地方。
个人使用不必一上来追求企业级系统。先把自己的资料变成一个能被 AI 读懂和维护的 wiki,就已经跑通了最关键的一步。
这篇文章默认你用 Codex 或 Claude Code 来操作文件,用 Obsidian 来阅读和检索。如果你还没装这两个,先去装好再往下看。
AI 能做什么
AI 维护知识库,核心做五件事。
持续编译。 新资料进来,AI 读完之后把关键信息整合进已有的概念页、索引和日志。它持续往已有的结构里加东西,不是每次从头翻。
跨资料连接,挖出潜在线索。 三个月前存了一篇讲提示词的文章,上周记了一段跟 AI 协作的复盘,两个文件在文件夹里隔得很远。AI 能看出来它们讲的是同一件事,帮你连起来。有些笔记单独看只是片段,放在一起才会出现共同主题、相互印证或者冲突的判断——AI 能把这些散落的点串成线。
问答回流。 你问了一个复杂问题,AI 翻遍你的资料库拼出一个答案。这个答案如果不存下来,下次还得重新问。AI 可以帮你把答案落成文件,下次直接调用。
巩固知识网。 每篇新资料进来,AI 会把它挂回旧概念、旧项目和旧问题上。知识库不会越用越散,反而越用越清楚。
健康检查。 定期扫描整个库:哪些页面缺来源?哪些概念互相矛盾?哪些页面是孤岛,没人链向它?哪些判断可能过期了?这个动作不是高阶玩法,是让知识库结构一直保持健康的基本维护。
五件事加起来,一句话:你的知识库从死的变成活的。
什么是 LLM Wiki
前面说的这套方法,有个名字叫 LLM Wiki。它不是某个产品,也不是什么插件,而是 Karpathy 提出的一种模式(推文)。
用人话讲:让 AI 像维护代码仓库一样维护你的知识库。
具体长这样:
AI 知识库/
├── raw/ # 原始资料,只新增,不乱改
│ ├── articles/ # 外部文章、博客、教程
│ ├── papers/ # 论文、研究报告
│ └── clips/ # 网页剪藏、摘录
├── wiki/ # AI 编译后的知识条目
│ ├── index.md # 知识库总目录,快速知道库里有什么
│ ├── log.md # 维护日志,记录每次新增和编译
│ ├── concepts/ # 概念页,每个重要概念一个文件
│ ├── entities/ # 实体页:人、组织、产品、项目
│ ├── syntheses/ # 综合页,跨资料整合后的主题梳理
│ └── sources/ # 来源摘要页,每条原始资料一份
├── outputs/ # 问答、报告、健康检查
│ ├── qa/ # 复杂问题的答案存档
│ └── health/ # 健康检查报告
└── AGENTS.md # 写给 AI 的维护规则
三层结构,对应三个角色:
raw/ 像仓库。不负责漂亮,只负责保留原始证据。文章、论文、网页剪藏、AI 对话记录,扔进去就别动它。
wiki/ 像书架。AI 把原始资料整理成能反复阅读、链接和更新的页面。有目录(index.md)、有日志(log.md)、有概念页(concepts/)、有实体页(entities/)、有综合页(syntheses/)、有来源摘要(sources/)。
outputs/ 像工作台。每次提问、研究、健康检查得到的结果都落在这里。问答归 qa/,检查报告归 health/。
AGENTS.md(Codex)或 CLAUDE.md(Claude Code)像说明书。告诉 AI 以后维护这个库要遵守什么规矩:raw/ 不能改、每个判断要指向来源、每次整理完要更新 index 和 log、不确定的信息要标「待核验」。
Obsidian 在这里不是 AI 本体,而是知识库 IDE。你用它来看 raw、浏览 wiki、检索、查看链接关系。AI 负责维护文件,你负责阅读、判断方向和投喂新资料。
AI 把资料持续整理进一套可读、可链接、可追溯的 wiki。这个动作叫「编译」。
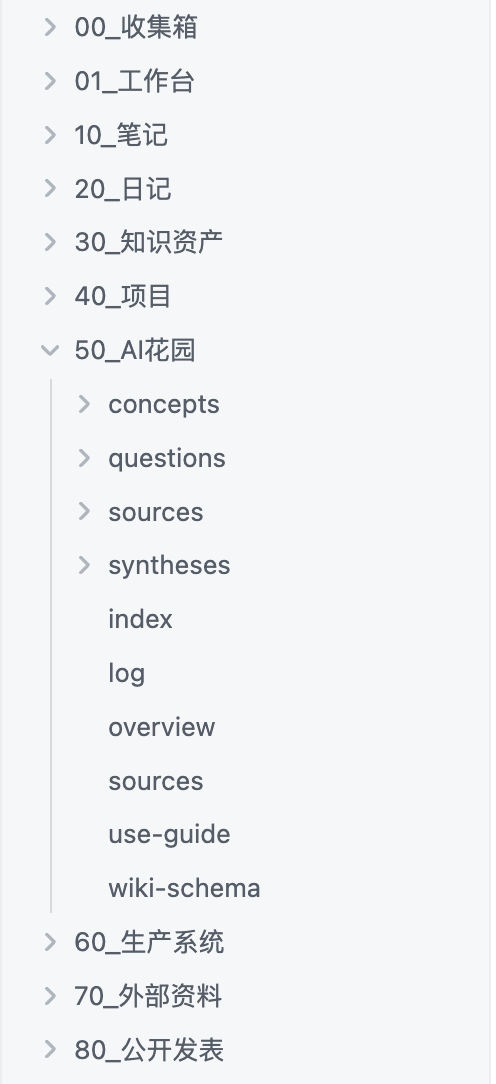
我自己的知识库实际目录结构。跟你前面看到的模板大同小异,核心逻辑完全一样:concepts/、sources/、syntheses/、questions/ 都在,只是我的原始材料分散在笔记、日记、项目等文件夹里,没有单独叫 raw/,但本质还是原始资料和编译结果分开。
它和传统笔记、RAG 有什么区别
传统笔记是你自己维护,AI 偶尔来读一下。
RAG 呢,提到的人比较多。简单来说,它是这样工作的:你提问时,系统先去你的资料堆里搜相关内容,把搜到的片段和你的问题一起塞给 AI,AI 再生成答案。它像一个给 AI 接的搜索引擎。
RAG 有用,但它更偏技术方案,通常会牵扯检索算法、文本切块、向量数据库、权限控制这些东西。
LLM Wiki 更适合个人起步:文件就是 Markdown,人能读,AI 能改,能备份,能追溯。
对个人知识库来说,第一步就上 RAG,相当于还没学会走路先研究跑步力学。RAG 不是没用,只是顺序问题——先把知识库跑通,资料规模上去了、搜索确实不够用了,再考虑更强的检索方案。
先让 AI 把架子搭起来
那么如何开始搭建这样一套知识库呢?
第一步:新建一个笔记仓库。不要直接动你的主笔记库。单独建一个文件夹,在里面跑通整个流程,确认顺手了再迁移。
第二步:把下面这段提示词复制给 Codex 或 Claude Code:
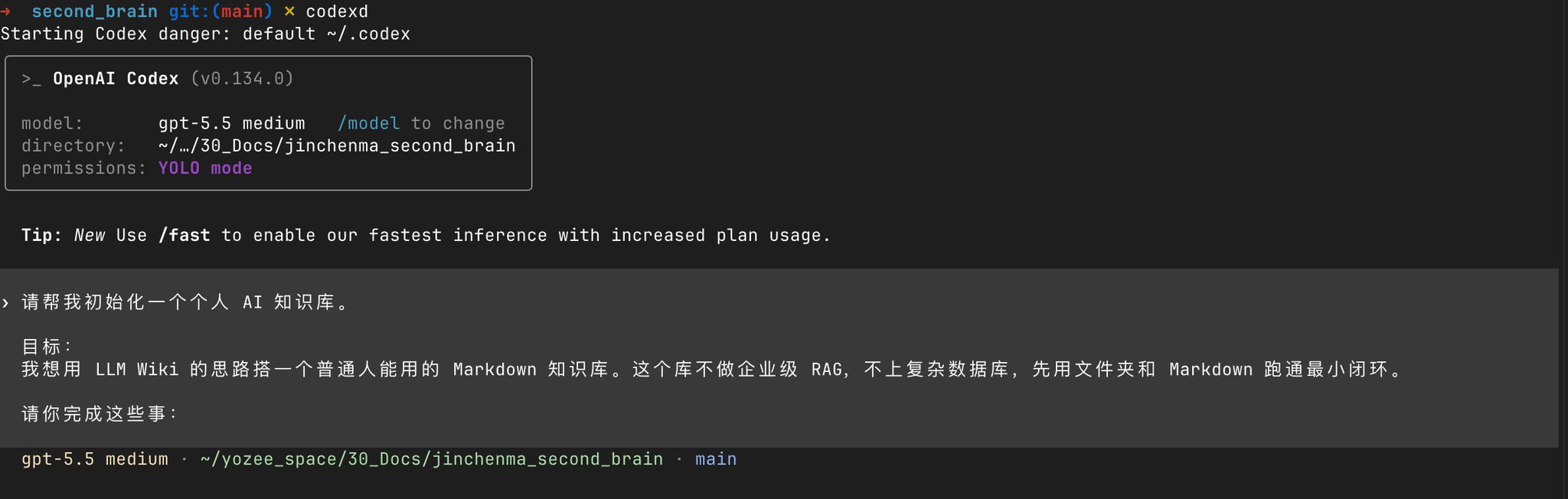
请帮我初始化一个个人 AI 知识库。
目标:
我想用 LLM Wiki 的思路搭一个普通人能用的 Markdown 知识库。这个库不做企业级 RAG,不上复杂数据库,先用文件夹和 Markdown 跑通最小闭环。
请你完成这些事:
1. 创建下面的目录结构:
- raw/articles/
- raw/papers/
- raw/clips/
- wiki/concepts/
- wiki/entities/
- wiki/syntheses/
- wiki/sources/
- outputs/qa/
- outputs/health/
2. 创建 wiki/index.md,用来说明这个知识库当前有哪些主题、资料和入口。
3. 创建 wiki/log.md,用来记录每次新增资料、编译资料、更新页面和健康检查的结果。
4. 创建项目工程规则文件,写清楚以后维护这个知识库时必须遵守的规则:
- 如果我用的是 Codex,请创建 AGENTS.md。
- 如果我用的是 Claude Code,请创建 CLAUDE.md。
- 如果你不确定我用哪个工具,请同时创建 AGENTS.md 和 CLAUDE.md,两个文件内容保持一致。
- raw/ 只保存原始资料,不要删除,不要覆盖。
- wiki/ 里放你整理后的知识条目。
- 每个重要判断都尽量指向来源。
- 新资料进来后,先生成来源摘要页,再更新概念页、实体页、index.md 和 log.md。
- 不确定的信息要标注待核验,不要编。
- 每次整理完成后,告诉我你改了哪些文件。
5. 在 wiki/sources/README.md 里写一个来源摘要页模板,字段包括:
- title
- source
- source_url
- created
- summary
- key_points
- related_concepts
6. 在 outputs/health/README.md 里写一份健康检查说明,提醒以后定期检查:
- 哪些页面缺来源。
- 哪些概念重复或冲突。
- 哪些页面没有链接。
- 哪些判断可能过期。
请直接创建这些目录和文件。完成后,用一段话告诉我这个知识库现在怎么用。
AI 跑完之后,你的知识库架子就搭好了。打开 Obsidian,把这个文件夹作为新仓库打开,你能看到完整的目录结构、index、log 和维护规则。
第一次放资料进去
架子有了,现在放资料。
先收集 5 到 10 篇同主题的内容。网页剪藏、公众号文章、PDF、视频转写、AI 对话记录,扔进 raw/ 对应目录就行。
然后,把下面这段提示词复制给 AI:
请读取 raw/ 里的新增资料,把它们编译进 wiki/。
你要做这些事:
1. 为每篇资料生成一份来源摘要页,保留 source_url。
2. 提取重要概念,如果 wiki/concepts/ 里已有相关页面,就更新旧页面;没有就新建。
3. 更新 wiki/index.md,让我能快速知道现在库里有什么。
4. 更新 wiki/log.md,记录这次处理了哪些资料。
5. 不要删除 raw/ 里的原始资料。
第一次编译不要追求完美。AI 生成的摘要可能漏了重点,概念归类可能不对,链接可能不全。没关系,先跑通,后面可以逐步修。
编译完之后回到 Obsidian,花 10 分钟翻一遍:来源摘要页有没有保留原文链接?概念页的逻辑通不通?index 有没有把所有新资料列进去?
你不需要自己动手改。把问题记下来,下一轮让 AI 修。
让知识库像结网一样慢慢生长
第一次编译跑通之后,知识库算是有了骨架。日常只需要做四件事:
投喂。 看到好文章、做完项目复盘、跟 AI 聊出有价值的结论,扔进 raw/,然后让 AI 编译:
请读取 raw/ 里新增的资料,把它们编译进 wiki/。
你要做这些事:
1. 为每篇新资料生成来源摘要页,保留 source_url。
2. 提取重要概念,更新或新建 wiki/concepts/ 里的概念页。
3. 更新 wiki/index.md 和 wiki/log.md。
4. 不要删除 raw/ 里的原始资料。
提问。 遇到问题,先问你的知识库,而不是从零开始搜互联网:
请先读取 wiki/index.md 了解当前知识库的全貌,然后根据 wiki/ 里的内容回答我的问题:[你的问题]
回答时请引用 wiki/ 里的具体来源页面。如果知识库里没有相关信息,也请告诉我。
复杂问题的答案,让 AI 存到 outputs/qa/。
回流。 阶段总结、对比表、研究结论,这些都不应该只留在聊天窗口里。落成文件,放回知识库。有价值的 AI 对话本身也是 raw 输入:
请把刚才的问答/讨论整理成一篇笔记,保存到 outputs/qa/。
内容包括:问题背景、关键结论、涉及的 wiki 页面链接。
检查。 每周跑一次健康检查:
请先读取 wiki/index.md 了解当前知识库的全貌,然后做一次健康检查。
重点检查:
1. 哪些页面缺少来源。
2. 哪些概念定义互相冲突。
3. 哪些页面几乎没有链接,像孤岛。
4. 哪些重要概念被多次提到,但还没有独立页面。
5. 哪些页面可能已经过期,需要重新核验。
请把报告保存到 outputs/health/,并给出最优先修复的 5 个问题。
避坑提醒
- 别一上来搭 RAG。 先跑通 LLM Wiki,资料规模上去了再考虑。
- 别只存正文不存来源。 没有来源链接,后面想追溯原始信息就无从下手,AI 编译出来的内容也没法核验真实性。
- 别把 raw 和 wiki 混在一起。 raw 是原始资料区,wiki 是整理区。混在一起,AI 生成的 wiki 内容就可能污染你的原始资料。
- 别让 AI 覆盖原始资料。 raw 里的东西只新增、不删除、不覆盖。
- 别把问答留在聊天记录里。 有价值的答案、对比、结论,存到 outputs/。
- 别信 AI 编译一次就完事。 编译一定会漏东西。所以要持续让 AI 维护更新,健康检查也别省。
写在最后
有了这套系统,你不再是一个人在维护一座越来越大的仓库。
每次新增资料,拆解、归类、挂链接都自动完成。每次提问,答案从你已经积累的资料里长出来,而不是从聊天窗口的空白处重新开始。
每次投喂新资料,知识网就多一个节点。
用了这套方法之后,你再打开 Obsidian,看到的就不再是一堆文件,而是一张已经有脉络、能回答你问题的知识网。
随着知识网越来越大,当你想写点东西、做个判断的时候,可能第一反应不是打开 Google,而是在 Obsidian 里让 AI 从你自己的素材里找答案。
本文参考了 Karpathy 的 LLM Wiki:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94