
xcrawl数据爬虫,收集任何你要的数据

小张是一个跨境卖家,25 年初,他发现一个规律:
玩具收纳盒这个品类,每年 8-9 月搜索量暴涨 300%,但大部分卖家 7 月才开始备货,供给跟不上需求。于是他做了一款防水可折叠 的玩具收纳盒,一个月利润 $8,000。他是怎么发现这个信息差的?靠爬虫。每周,他用爬虫自动抓取:
- Amazon “toy storage box” 前 20 名的价格、评论数、BSR 排名变化
- Google Trends 该关键词的搜索趋势曲线- Reddit 和 Facebook 妈妈群里关于收纳的讨论热度他发现:
- 排名第一的 Gowee($17.99)有 5 万+ 评论,根本打不过
- 但 $25-30 价格带是空白区间——没有强势产品
- 妈妈群里高频出现的痛点是”收纳盒不防水,孩子洒果汁就废了”
这整个链路的核心不是”会做产品”,而是比别人早 3 个月看到数据。而”看到数据”这件事,靠的就是爬虫。
一、爬虫能搞钱,但大多数人卡在了中间环节
方向谁都知道——抓竞品数据、监控价格、追热点、做 SEO。但真正靠爬虫赚到钱的人少,因为中间有三道坎:
坎 1:反爬对抗太烧时间。Amazon 有 CAPTCHA,Reddit 有 JS Challenge,Twitter 要 API 认证。你刚写完爬虫,目标网站改了一次反爬策略,代码全废。你以为 80% 时间在分析数据,实际上 80% 时间在跟反爬斗智斗勇。
坎 2:从原始数据到洞察有鸿沟。抓到一堆 HTML 不等于看到商机。你还要清洗、解析、跨源整合、分析解读——中间每一步都要写代码、调格式、反复验证。
坎 3:工具链太碎,维护成本高。搜索用 SerpAPI,抓取用 ScrapingBee,解析用 BeautifulSoup,分析用 Pandas,报告用 Markdown……五六个工具拼在一起,每个都要单独付费、单独学、单独维护。
搞钱的人需要的不是更多工具,而是更短的链路。这就是 xCrawl 解决的问题。
二、xCrawl:把”抓数据→出结论”压缩到一句话
xCrawl 是一个 AI 原生的网页抓取服务,可以通过 MCP 直接集成在 Claude、Cursor 等 AI 工具中。它不只是一个爬虫 API,更适合理解成一种低成本的数据生产资料——你不需要自己养代理池、维护脚本、处理反爬和清洗 HTML,直接把时间花在更值钱的部分:
- 找到一个客户愿意买的主题
- 用 xCrawl 把公开信息快速抓回来
- 用 AI 整理成客户能看懂、能决策、能直接拿去用的交付物
xCrawl 适合搞钱,是因为它正好解决了上面三道坎:
- 内置高质量住宅代理池 + 智能指纹技术,任务成功率稳定在 90% 以上(解决反爬)
- 支持 JS 动态渲染,能抓 X(推特)、知乎等动态加载页面
- 输出格式统一,Markdown 或 JSON 直接喂给 LLM,不需要二次清洗(解决数据鸿沟)
- 搜索 + 抓取一体化,一个系统搞定,不用拼接五六个工具(解决工具碎片化)
- 内置代理,无需梯子即可访问全球站点(包括 Google、X 等)
- 云端无限扩展,按需付费,无需维护服务器
- 严格合规,只采集公开数据,平台内置多重风控
- 自定义结构化提取,自定义字段/表格/列表自动转 schema
回到开头小张的例子:他每周花 3 分钟跑一个 xCrawl 任务,就能拿到别人花半天手动整理的竞品数据。工具的成本是几块钱,但信息差带来的利润是几千美金。所以这篇文章不是一篇单纯的工具说明书,而是想回答一个更现实的问题:
怎么把 xCrawl 变成一个接单、做服务、做内容订阅,甚至做小产品的底层数据引擎。## 二、五大核心功能
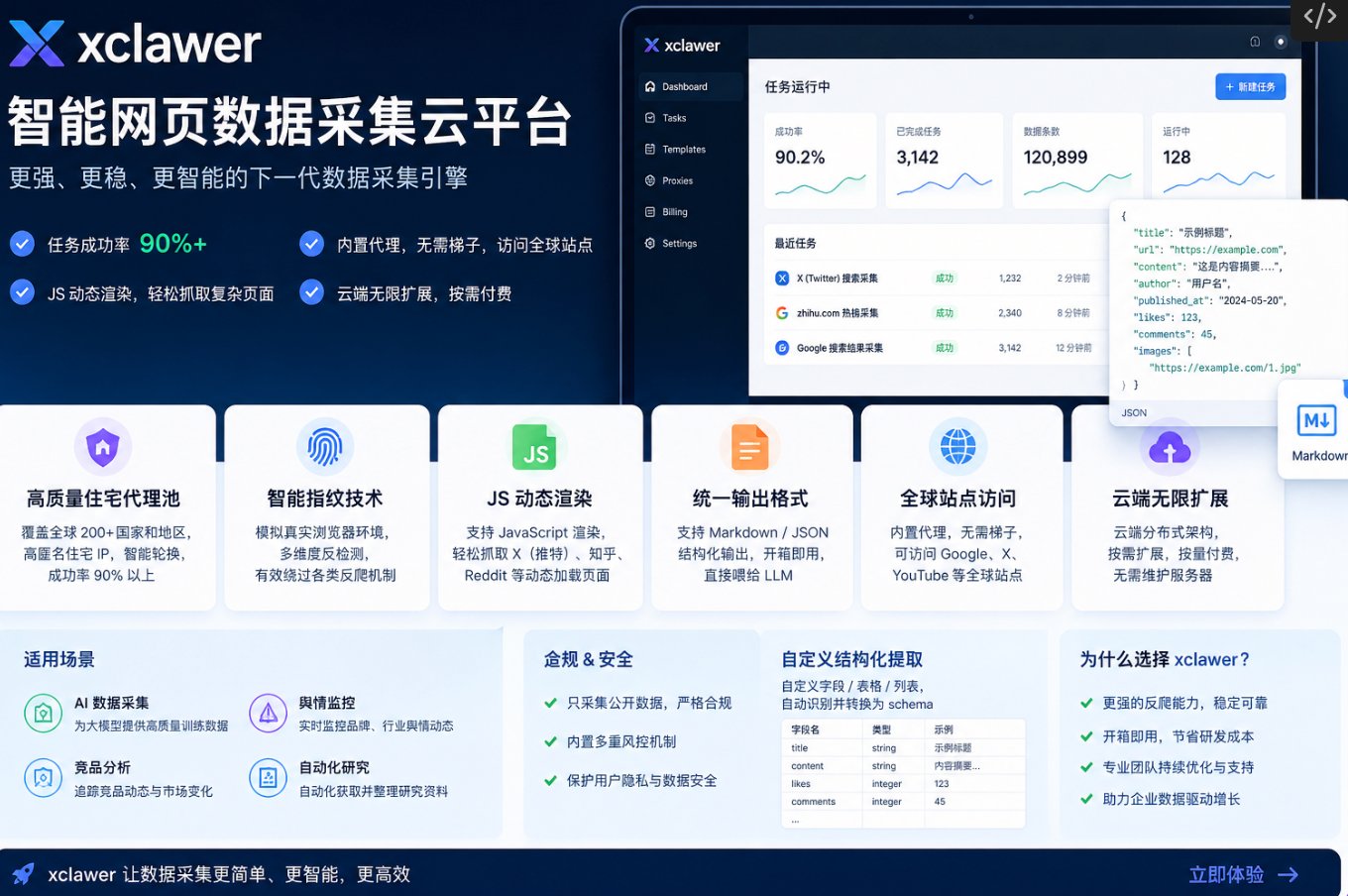
- Scrape — 单页精准抓取(最常用)
输入任意 URL,一次请求即可提取页面内容,支持动态 JS 加载页面。
输出格式灵活:
- Markdown(干净、LLM 直接可用)
- JSON(结构化 schema,支持自定义字段提取)
- HTML(清洗/原始)
- Screenshot(视口/全页截图)
- Summary(摘要)
- Links(链接提取)
可灵活开关 JS 渲染、位置代理(指定国家)、语言偏好、仅主要内容过滤。
适合场景:抓某篇文章、某个商品页、产品详情页。
- Crawl — 多页/全站智能爬取
智能递归爬取整个网站或指定路径,自动处理翻页、无限滚动、JS 动态内容。
可设定爬取边界:
- max_depth:最大爬取深度(最多 3 级)
- limit:最大页面数量(最多 100 页)
- 支持包含子域名、忽略查询参数
适合场景:行业资讯站点批量采集、LLM fine-tuning 数据集构建、知识库建设、全站内容备份。
- Map — 站点地图探测
先扫描域名或起始页,自动探测并导出所有可发现 URL、sitemap 和站点结构。
支持限制条件:
- URL 数量上限(最多 100,000 个)
- 过滤器(支持正则表达式,如只抓 /blog/.* 路径)
- 包含子域名、忽略查询参数
适合场景:作为 Crawl 的前置步骤,先 Map 出全貌,再选部分深度爬取,大幅提升效率。
- Search — 多引擎搜索
提供类似 Google/Bing 的网页搜索能力,按关键词搜索并返回结构化结果(排名、标题、链接、描述)。
支持指定地区(US/EU/CN 等)和语言,调用时自动走内置代理,无需本地梯子。
适合场景:日常 SEO 监控、内容研究、批量收集素材。
- SERP — 深度搜索引擎数据采集
比 Search 更深入,获取完整的搜索引擎结果页数据:
- 排名、标题、snippet、链接
- 富结果(视频、图片、购物广告)
- People Also Ask(相关问题)
- 知识图谱- 相关搜索支持设备模拟(移动/桌面)、高级过滤(时间、地区、文件类型)、定向采集(新闻、本地、图片)。
适合场景:专业级 SEO 深度分析、竞品情报、趋势研究、区域市场研究。
三、快速上手
第 1 步:注册获取 API Key
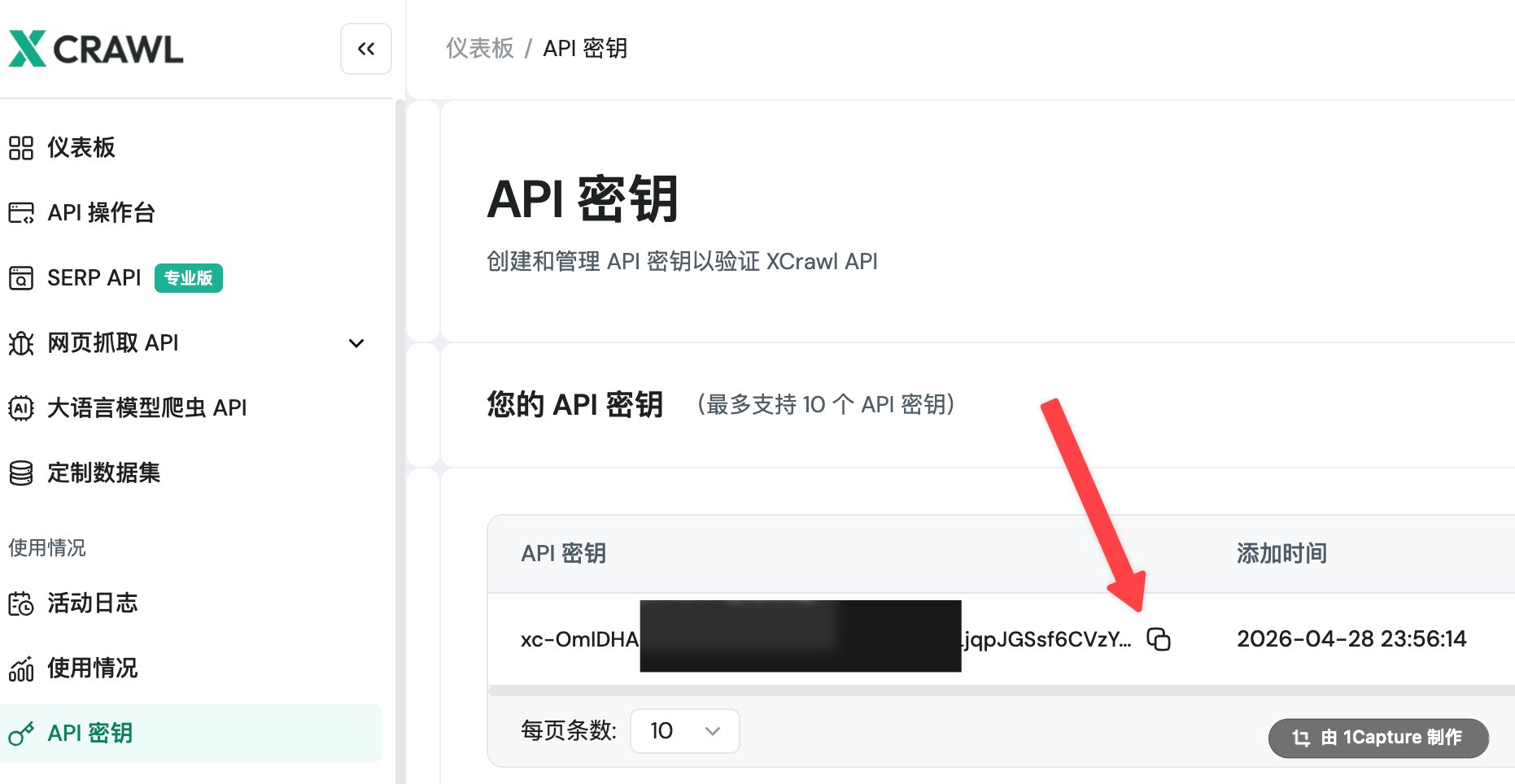
- 进入 xcrawl.com 官网
- 使用 Google 账号登录
- 复制你的 API Key
- 新用户免费赠送 1000 积分(约等于 1000 次抓取)
第 2 步:选择接入方式
方式 A:直接调 API```typescript import requests
response = requests.post( "https://run.xcrawl.com/v1/scrape", headers={"Authorization": "Bearer 你的API_KEY"}, json={ "url": "https://example.com", "output": {"formats": ["markdown"]} } )
data = response.json() print(data["data"]["markdown"]) # 干净的 markdown 内容
**方式 B:关键词搜索**```text
from xcrawl_client import XCrawl
xcrawl = XCrawl(api_key="你的API_KEY")
results = xcrawl.search(keyword="OpenClaw 创始人", limit=10)
for item in results:
print(item["title"], item["url"])
方式 C:在 OpenClaw 中配置 Skill(推荐)在 OpenClaw 命令行发送:
帮我安装 xcrawl 这个 skill
github 链接为:github.com/xcrawl-api/xcrawl-skills
apikey 为:xc-你的key
安装后会集成 4 个组件:xcrawl-scrape、xcrawl-map、xcrawl-crawl、xcrawl-search,直接用自然语言调用即可。
也可以手动配置 API Key:
mkdir -p ~/.xcrawl
cat > ~/.xcrawl/config.json <<'EOF'
{
"XCRAWL_API_KEY": "<your_api_key>"
}
EOF
方式 D:通过 MCP 接入(支持多平台)xCrawl 提供 MCP Server,支持云端 URL 或本地 npx 两种方式,适配主流 AI 编辑器和客户端。
云端 URL(推荐,最简单):
mcp.xcrawl.com/{你的API_KEY}/mcp
本地运行:
XCRAWL_API_KEY=你的API_KEY npx -y xcrawl-mcp
Claude Code:claude mcp add xcrawl --url mcp.xcrawl.com/{你的API_KEY}/mcp
如果不支持 HTTP 方式:
claude mcp add xcrawl -e XCRAWL_API_KEY=你的API_KEY -- npx -y xcrawl-mcp
Cursor:进入 Settings > Features > MCP Servers > + Add new global MCP server,添加:
{
"mcpServers": {
"xcrawl": {
"url": "https://mcp.xcrawl.com/{你的API_KEY}/mcp"
}
}
}
Claude Desktop:编辑配置文件(macOS: ~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"xcrawl": {
"url": "https://mcp.xcrawl.com/{你的API_KEY}/mcp"
}
}
}
Windsurf:进入 Tools > Configure > View raw config,添加:
{
"mcpServers": {
"xcrawl": {
"serverUrl": "https://mcp.xcrawl.com/{你的API_KEY}/mcp"
}
}
}
以上所有平台如果不支持 HTTP 方式,都可以改用本地 npx 方式:将 "url" 替换为 "command": "npx", "args": ["-y", "xcrawl-mcp"], "env": {"XCRAWL_API_KEY": "你的API_KEY"}。
配置完成后,和ai确认mcp功能是否正常。
四、xCrawl 的搞钱案例
如果你想靠 xCrawl 搞钱,核心不是“会不会爬”,而是“能不能把公开网页数据整理成客户愿意付费的结果”。
案例 1:SEO 竞品分析报告搞钱方向:- 单关键词 SEO 竞品分析报告
- SEO 内容策略方案
- 标题、大纲、FAQ、初稿打包服务
适合客户:- 做独立站的创业者
- SaaS 官网负责人
- SEO 代理公司
- 做英文内容出海的人
大概能卖多少钱:- 单关键词基础报告:299-999 元
- 报告 + 标题大纲 + FAQ + 初稿:799-1999 元
- 10 个关键词包月:3000-10000 元/月
给 xCrawl 的提示词:使用 xCrawl 搜索关键词 ai video generator,抓取前 10 名页面的正文和摘要,然后基于这些真实网页内容,生成一份以 ai video generator 为核心关键词的 SEO 文档,包括搜索意图、文章结构、FAQ 和中文初稿。
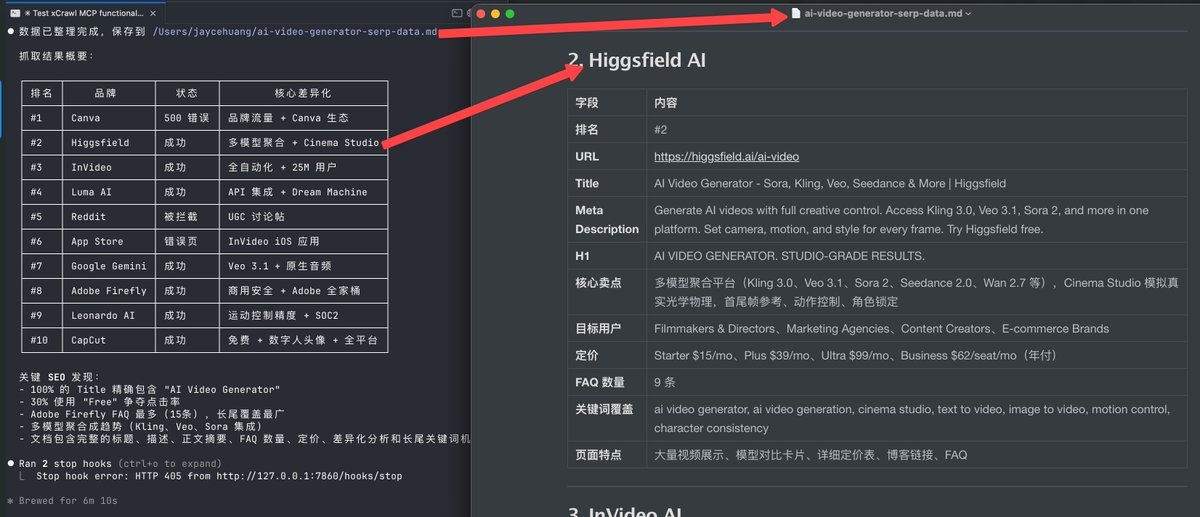
拿到数据后,接下来可以交给ai分析了。
基于以上 xCrawl 抓取到的真实网页数据,分析关键词 "ai video generator" 的搜索意图、页面类型、标题模式、内容结构、核心卖点、FAQ 和内容缺口,并生成一份完整的 SEO 文档,包括标题建议、Meta Description、H1/H2/H3 大纲、FAQ 和中文初稿。
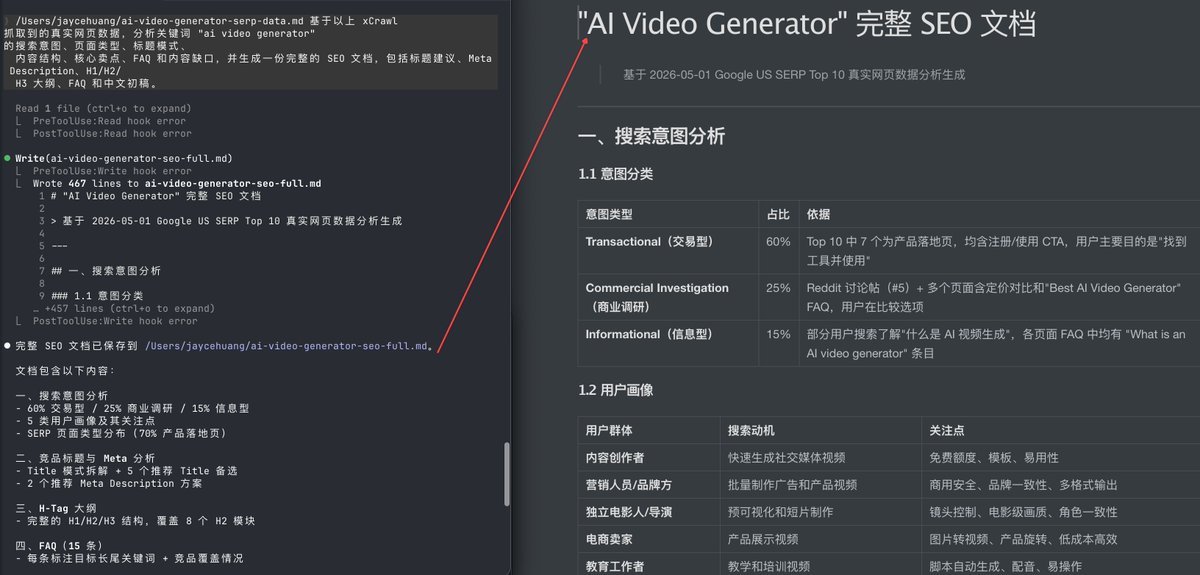
怎么把结果包装成钱:- 先把前 10 名页面拆成表格:排名、标题模式、页面类型、核心卖点、FAQ
- 再补一页结论:这个关键词该做什么内容、从什么角度切入
- 最后附一版文章大纲或初稿,客户更容易直接付款
最适合的交付物:- PDF 报告
- Notion 页面
- Google Docs 内容方案
案例 2:海外资料检索快报这个不适合卖高价,但非常适合做低价入口产品和引流服务。
搞钱方向:- 英文资料检索服务
- 行业调研快报
- 出海选题资料包
适合客户:- 不会检索英文资料的人
- 出海内容团队
- 咨询顾问
- 研究型创作者
大概能卖多少钱:- 单次资料检索:99-299 元
- 一次主题调研:299-999 元
- 包周/包月资料服务:1000-5000 元/月
给 xCrawl 的提示词:用 xCrawl 搜索 "AI agent latest news",返回前 5 条结果,包含标题、URL、描述和排名。然后抓取其中最相关的前 5 个页面正文和摘要,方便我整理成中文资料检索快报。

怎么把结果包装成钱:- 不要直接把链接堆给客户
- 要整理成“主题摘要 + 重点结论 + 原文链接”
- 最好再附一页中文结论:最近在发生什么、哪些值得继续跟
最适合的交付物:- 一页纸简报
- 微信可转发版长图
- 中文摘要文档
案例 3:X 新手起号互动情报搞钱方向:- X 起号陪跑
- 互动机会清单
- 评论区狙击策略
适合客户:- 刚开始做 X 的个体
- AI 出海创业者
- 内容工作室
- 代运营团队
大概能卖多少钱:- 单次互动机会清单:99-299 元
- 一周陪跑包:499-1999 元
- 包月账号增长服务:2000-8000 元/月
给 xCrawl 的提示词:用 xCrawl 抓取 SoPilot 的 Hot Tweets 数据,筛选出适合新账号互动的帖子:要求评论数适中、互动率较高、发布时间较近,并输出每条帖子的标题、链接、作者、互动数据和可跟进理由,方便我整理成一份“黄金互动窗口”清单。
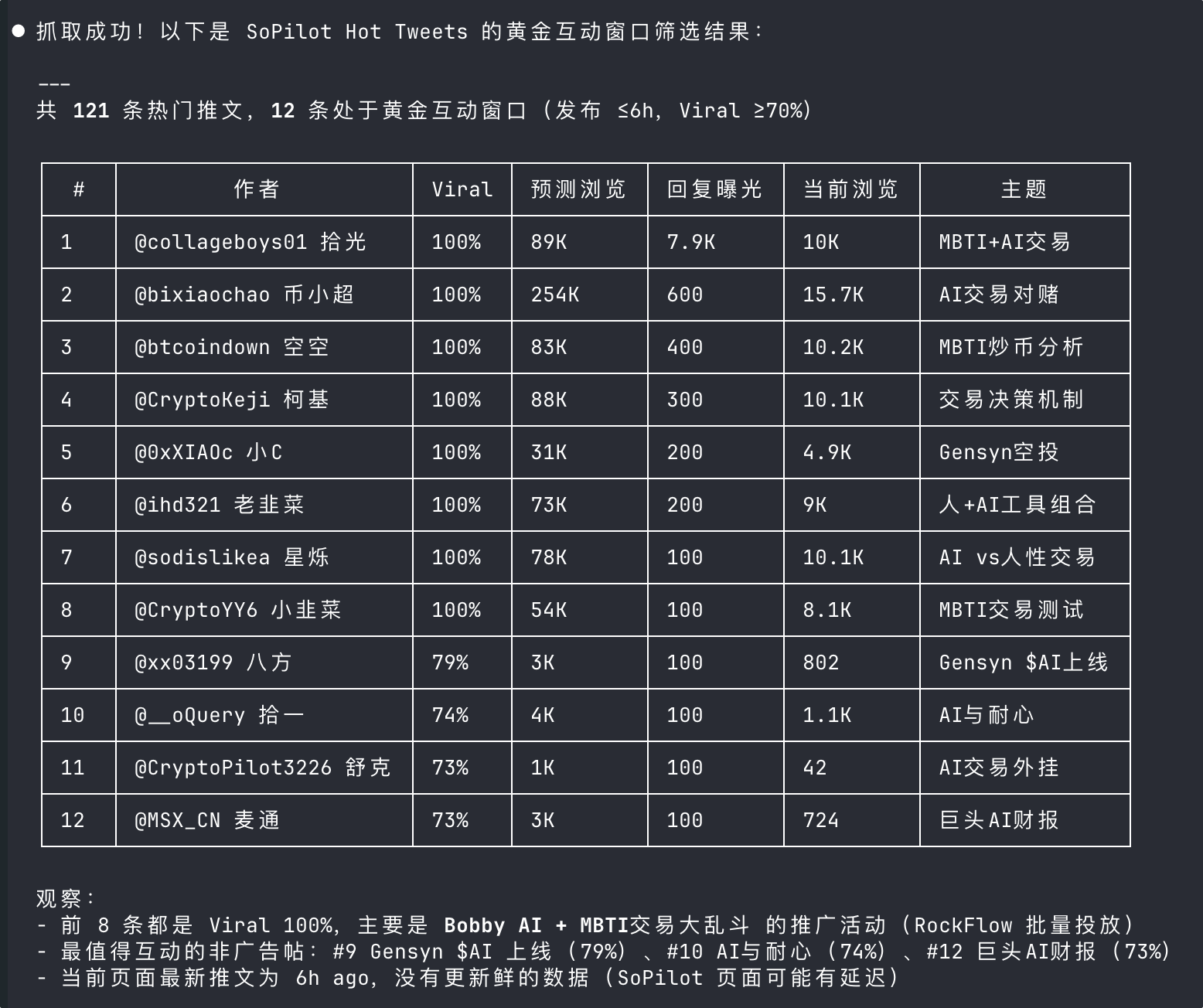
怎么把结果包装成钱:- 不要只交一个链接列表
- 应该交“今天该去评论哪 10 条、为什么、建议怎么评论”
- 如果再附 20 条评论模板,成交率会高很多
最适合的交付物:- 每日互动机会表
- 评论模板库
- 陪跑清单
案例 4:亚马逊商品监控周报这个案例商业味最重,客户对“省时间”和“及时预警”都愿意付钱。
搞钱方向:- 类目监控表
- 竞品价格监控
- 评价增长和库存变化周报
适合客户:- 亚马逊卖家
- 跨境电商工作室
- 选品团队
- 代运营公司
大概能卖多少钱:- 单次类目监控表:299-999 元
- 单店竞品监控:999-3000 元/月
- 定制监控服务:3000-10000 元/月
给 xCrawl 的提示词:用 xCrawl 抓取亚马逊关键词 "toy storage box" 搜索结果前 20 个商品页面,提取每个商品的标题、价格、评分、评论数、品牌、卖点摘要和正文描述。如果可以,补充库存状态、Q&A 和最近评价变化,方便我做竞品监控和类目分析周报。

怎么把结果包装成钱:- 把数据整理成 Excel 或 Notion 表
- 给客户看“谁降价了、谁评论暴涨了、谁卖点写得更强”
- 再加一页“本周值得抄的 Listing 卖点”
最适合的交付物:- 监控周报
- Excel 数据表
- Listing 拆解文档
案例 5:X 推文创作素材订阅这个最适合做低门槛产品,靠持续交付赚钱,而不是靠单次高价。
搞钱方向:- X 爆款素材包
- AI 赛道内容选题库
- 推文创作参考库
适合客户:- 做 X 的个人创作者
- AI 赛道内容团队
- 代写工作室
- 增长操盘手
大概能卖多少钱:- 每周素材包:49-199 元
- 包月素材订阅:199-999 元/月
- 团队版情报服务:1000-5000 元/月
给 xCrawl 的提示词:用 xCrawl 抓取 X、Reddit 和 Hacker News 上关于 AI agents、AI coding、AI video 的最新热门帖子,输出标题、链接、来源、互动数据、摘要和 markdown 内容,方便我整理成一份可直接写推文的素材库。

怎么把结果包装成钱:- 别只给“内容列表”
- 要给“可直接写的角度”:观点、争议点、金句、可改写标题
- 如果再附 10 条可直接发布的推文草稿,订阅价值会高很多
最适合的交付物:- 每周素材池
- 推文草稿包
- 热点追踪订阅
小结:xCrawl 最适合怎么搞钱
如果你是第一次拿 xCrawl 去变现,我建议按这个顺序来:
- 先卖单次报告:SEO 竞品分析、竞品对比、资料快报
- 再卖包月服务:内容情报、商品监控、账号陪跑
- 最后再产品化:做订阅、做仪表板、做自动周报
最关键的一点是:不要卖“我会抓数据”,要卖“我帮你省时间、补信息差、做判断”。## 六、MCP 工具速查
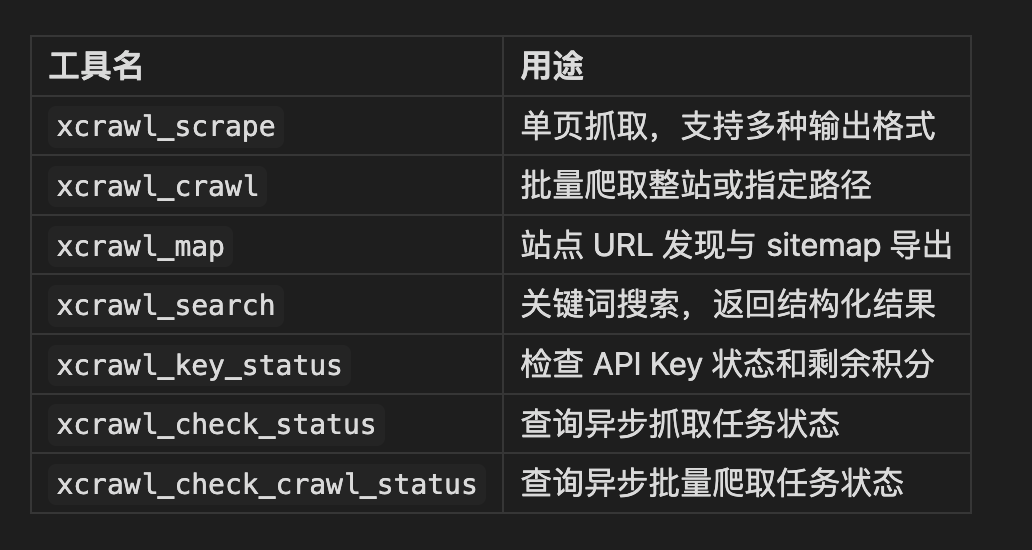
通过 MCP 接入后,可用以下 7 个工具:
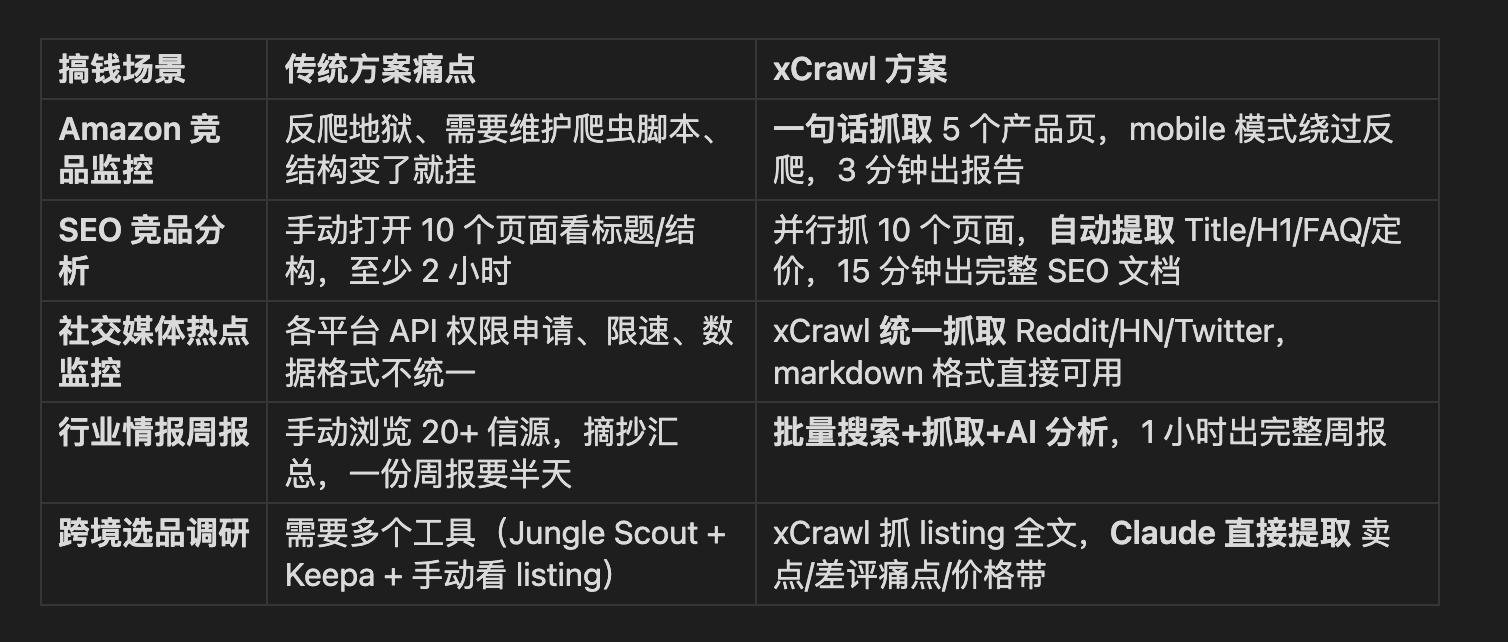
七、xCrawl vs 其他方案对比
搞钱的核心不是你能抓多少数据,而是从数据到决策的速度。
xCrawl把这个链路压缩到了对话级别,"你说想要什么,直接给你成品"。
八、用 xCrawl 搞钱,成本大概长什么样?
- 免费额度:新用户 1000 积分(约 1000 次抓取),轻度使用够用
- 付费:按量计费,抓一个页面几分钱
- 一个 API Key 通用所有功能
从搞钱角度看,这个成本结构的关键不是“便不便宜”,而是你能不能用非常低的数据成本,做出一个单次能卖几百到几千的交付物。
比如:
- 抓 10 个页面做一个 SEO 报告,成本可能只是几块钱,但你卖的是 299-1999 元
- 抓几十个商品页做竞品监控周报,数据成本很低,但服务可以按月卖 999-3000 元
- 抓一批热点内容做订阅情报,数据采集几乎不是主要成本,真正值钱的是你整理后的判断和交付
所以别把它看成“一个爬虫 API 的使用费”,而要看成:你在用极低的边际成本,换一套可以重复售卖的信息加工能力。## 九、最适合谁拿 xCrawl 去变现?
- 想接单的人:最适合卖 SEO 报告、竞品分析、资料快报这类一次性交付
- 内容创作者和工作室:最适合卖选题库、热点简报、内容素材订阅
- SEO 从业者:最适合卖关键词研究、SERP 拆解、内容策略方案
- 跨境和电商从业者:最适合卖商品监控、价格跟踪、类目分析周报
- 独立开发者:最适合把抓取 + AI 分析包装成一个订阅型小产品
- 非技术用户 / 小团队:不用自己写爬虫,也能先用自然语言做出一个可售卖的服务原型
如果你是第一次尝试拿 xCrawl 变现,最稳的路径不是一上来做系统,而是:
- 先做一个单次报告案例
- 把案例发出去验证是否有人愿意买
- 再把高频需求做成包月服务
- 最后才考虑产品化和自动化
十、最后:别卖爬虫,卖结果
xCrawl 真正有商业价值的地方,不在于“抓网页很方便”,而在于它能把原本零散、难抓、难整理的公开信息,快速变成:
- 能直接发给客户的报告
- 能持续订阅的周报
- 能提升内容效率的素材库
- 能辅助决策的监控表
你真正卖的不是技术,而是下面这几样东西:
- 帮客户省时间
- 帮客户补信息差
- 帮客户做初步判断
- 帮客户把公开信息整理成可执行结果
所以最好的起步方式不是研究最复杂的爬虫玩法,而是先挑一个最容易卖的交付物:
- 选一个明确人群
- 选一个他们愿意付钱的问题
- 用 xCrawl 把数据抓回来
- 用 AI 和你的判断把结果整理成报告或清单
- 先卖出第一单,再考虑放大
下面这些是你继续上手时会用到的官方资源。
十一、官方资源
- 注册地址:xcrawl.com/?keyword=3onhks6r
- Skills GitHub:https://github.com/xcrawl-api/xcrawl-skills
- MCP Server 云端 URL:mcp.xcrawl.com/{API_KEY}/mcp
- MCP npm 包:npx -y xcrawl-mcp