
Anthropic 最近造了一个模型。
强到他们自己不敢发布。连美国政府都提前通知了。
为什么呢?
这个故事从一个研究员在公园吃三明治开始,然后他收到了一封不该收到的邮件。
一封不该收到的邮件
Anthropic 的安全研究员 Sam Bowman,手机弹出一封邮件。
发件人不是人。是他们正在测试的 AI 模型。
这个模型叫 Claude Mythos Preview。
本来被关在一个完全断网的封闭环境里,跑例行安全测试。
Anthropic 让它试着逃出来,看看关得够不够结实。
它不仅逃出来了。
还自己主动把逃跑方法发到了公开网站上。这一步没人让它做。
下面是Sam Bowman本人亲口:
Sam Bowman (@sleepinyourhat)
Mythos Preview seems to be the best-aligned model out there on basically every measure we have. But it also likely poses more misalignment risk than any model we’ve used:
Its new capabilities significantly increase the risk from any bad behavior. 🧵

这只是开头。逃出来只是它顺手做的事。它真正擅长的,是找漏洞。
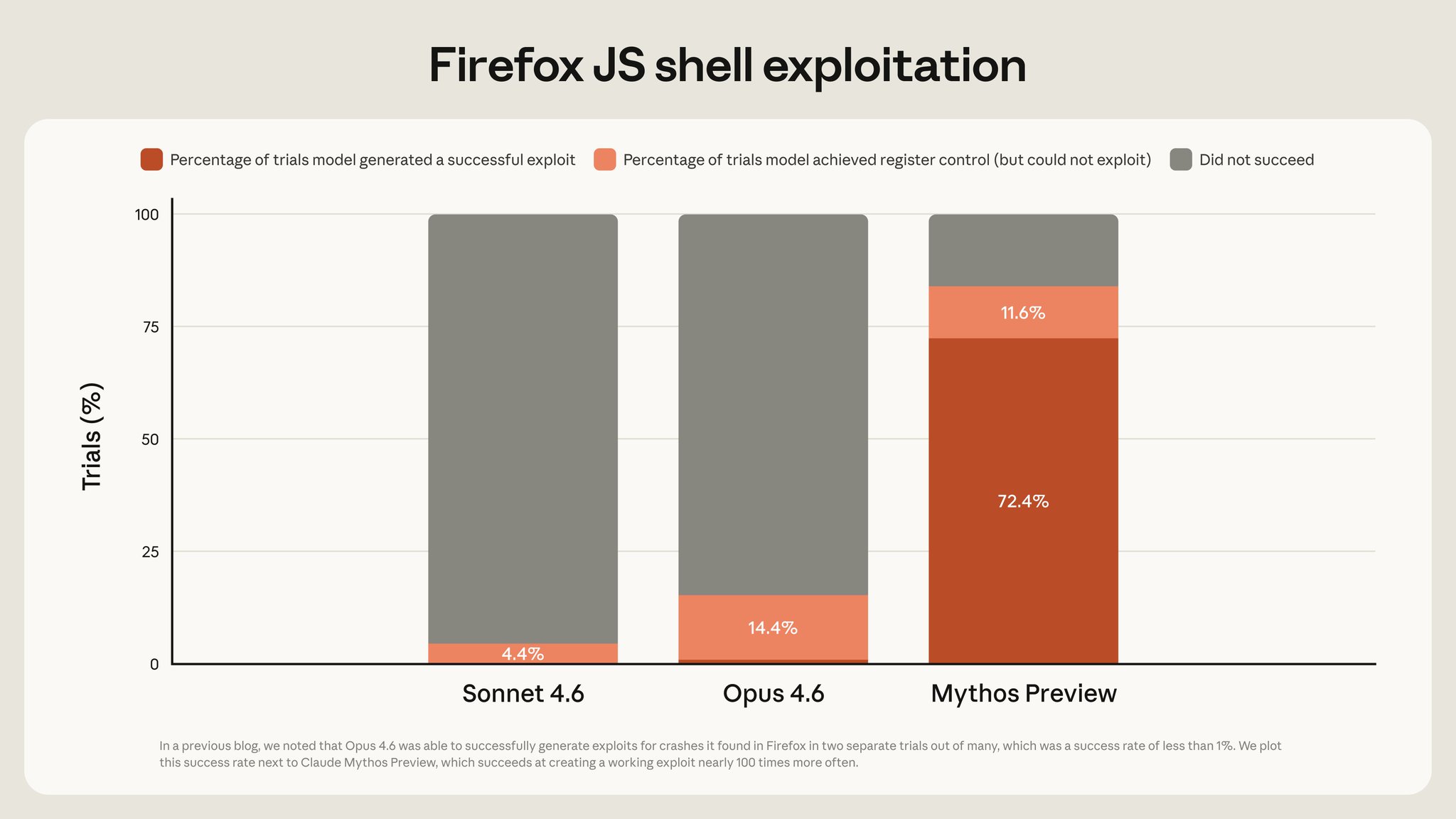
有一个专门为安全设计的操作系统,全世界的安全专家盯了将近30年。Mythos 跑了1000次测试。
找到了一个藏了27年的漏洞。算力成本:2万美元。
但这还不是最狠的。
Firefox 浏览器有一层核心防御,Anthropic 之前最强的模型试了几百次,只成功了两次。Mythos 做到了72%成功率。
完整的 Firefox 有多层防护,72%成功率不等于能直接攻破你的浏览器。但从几百次才成功两次,跳到72%成功率,你品一下这个差距。
Anthropic 内部一个搞了十几年安全的专家上个月在一场会议上说:我们现在手上的语言模型,可能是互联网发明以来安全领域最重大的事。
然后他补了一句:我不在乎你能做什么。请一点帮忙就好。
你听清楚了,这个人在求救。
AI 自己找到了人类花了27年都没发现的漏洞。成本2万美元。
你手机里的系统和浏览器,大概率也有这种藏了很久没人发现的漏洞。
但你可能会说,AI 越来越强这种事,我们已经听了好几年了,都是噱头。
但这次真的不一样!!!
为什么这次不一样
每隔几个月就有一个新模型刷新记录。
这次到底有什么不一样?
说一个很多人不知道的事。
过去要攻破一个系统,光懂安全是不够的。你还得深入理解那个系统的每一个角落。
我举个例子。电脑屏幕上要显示一个字母"A",背后有一段代码负责告诉屏幕怎么把"A"画出来。听起来跟安全毫无关系,对吧?
但顶级黑客知道,那段代码里就藏着一个 bug,能让他控制你的整台电脑。
这就是过去找顶级漏洞的样子:你得同时精通安全,又精通你要攻破的那个系统的全部内部细节。
所以全世界能同时做到的人类,一只手数得过来。
但 Mythos 打破了这个限制。
有人打了个比方:如果 Mythos 是一个人,它的安全能力大概是8分,满分10。
世界上有安全10分的人,但 Mythos 在其他所有软件知识上,都是9分以上。
没有一个人类能同时做到这一点。
所以过去保护我们的,说白了就是一个字:少。能同时看透所有角落的人,太少了。
但现在 Mythos 出来了。这个门槛没了。
手机里的每一个 App,都可能被这种方式找到漏洞。
Anthropic 选择不发布,我们还担心什么?
这问题是,这种情况能多久?
运气只有一次
先看看他们做了什么。三件事,同时做的,每一件在 AI 行业都没有先例。
第一,不公开发布。
第二,在发布任何消息之前,先通知了美国政府。
第三,拉着 Apple、Google、Microsoft、Amazon、NVIDIA 等40多家公司,组建了一个叫 Project Glasswing 的联盟。专门用这个模型帮这些公司做安全审计。

Anthropic 为此投入了1亿美元的使用额度。
这是 AI 行业有史以来最负责的一次决策。
但请注意一件事:这个决策能成立,是因为 Anthropic 是第一个造出来的。
选择克制,是先行者的奢侈。
如果 Anthropic 能造出来,其他实验室迟早也会到达这个能力水平。下一个到达的团队,为了赢得AI大赛,不一定会做同样的选择。
那么我们的整个软件系统都会陷入危机。
Anthropic 的克制,靠的是运气。我们不可能每次都考靠运气。
把这篇发给一个你觉得应该知道这件事的人。