
引言:为什么 AI Agent 需要 Hooks 系统
当你使用 AI Agent 帮你写代码时,可能会遇到这些问题:
- Agent 突然删除了一个重要文件,你来不及阻止
- Agent 调用了一个敏感 API,但你希望先审批一下
- Agent 不知道你的项目规范,总是用错误的编码风格
- Agent 修改了代码,但你希望自动运行测试
这些问题的本质是:你需要在 Agent 执行的关键时刻,插入自己的逻辑。
Hooks 系统就是为了解决这个问题:它在 Agent 的执行流程中提供了一组“钩子”,让你可以:
- 观测:看到 Agent 在做什么
- 拦截:在关键操作前阻止或修改
- 注入:在关键时刻添加额外的上下文或逻辑
需要明确的是,**Hook 解决的是局部动作约束;治理解决的是全链路状态一致性。**Hook 可以拦截单个工具调用、注入单条消息,但它不能保证整个系统的状态一致性、不能管理跨会话的策略演进、不能处理分布式场景下的协调问题。把 Hook 的拦截能力等同于系统治理能力,是一个常见的误区。
Claude Code 和 OpenClaw 都实现了 Hooks 系统,但它们的设计思路截然不同。
核心差异对比:先建立全局认知
在深入细节之前,我们先从宏观层面对比两种 Hooks 系统的核心差异。
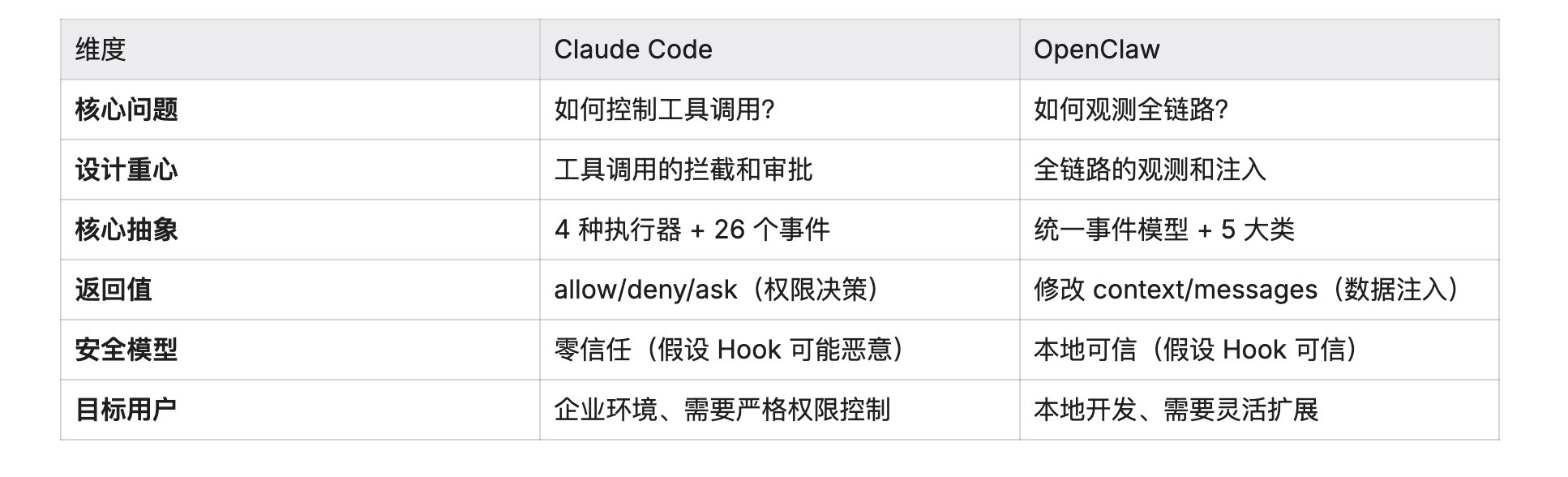
1.1 设计哲学
1.2 一句话总结
Claude Code:围绕“工具调用”构建的权限决策系统,像一个严格的保安,在 Agent 调用工具前进行审批和拦截。
OpenClaw:围绕“事件流”构建的观测扩展系统,像一个全方位的监控,让你能看到 Agent 执行的每个环节并在关键时刻注入逻辑。
1.3 架构对比
事件覆盖范围
Plain Text
Claude Code(工具与权限中心)
├─ 工具调用前后 ✅✅✅(核心,PreToolUse/PostToolUse)
├─ 权限审批 ✅✅(PermissionRequest/PermissionDenied)
├─ Agent 协作 ✅✅(SubagentStart/TaskCreated)
├─ 会话管理 ✅(SessionStart/SessionEnd/Stop)
├─ 上下文压缩 ✅(PreCompact/PostCompact)
└─ 消息生命周期 ⚠️(不是主轴,无显式消息事件)
OpenClaw(消息与会话事件中心)
├─ 消息生命周期 ✅✅✅(核心,received/transcribed/preprocessed/sent)
├─ 会话压缩 ✅✅(compact:before/after,带压缩率等指标)
├─ Agent 启动 ✅✅(bootstrap)
├─ 命令生命周期 ✅(command:new/reset)
├─ 网关生命周期 ✅(gateway:startup)
└─ 工具级 Hook ⚠️(粒度不如 Claude Code 原生,但有 plugin hook 层可做部分处理)
执行方式
Plain Text
Claude Code:多种执行器
├─ Command Hook:调用本地脚本
├─ Prompt Hook:调用 LLM 做决策
├─ HTTP Hook:调用远程服务
└─ Agent Hook:启动子 Agent
OpenClaw:单一执行方式
└─ JavaScript 函数(直接在代码中执行)
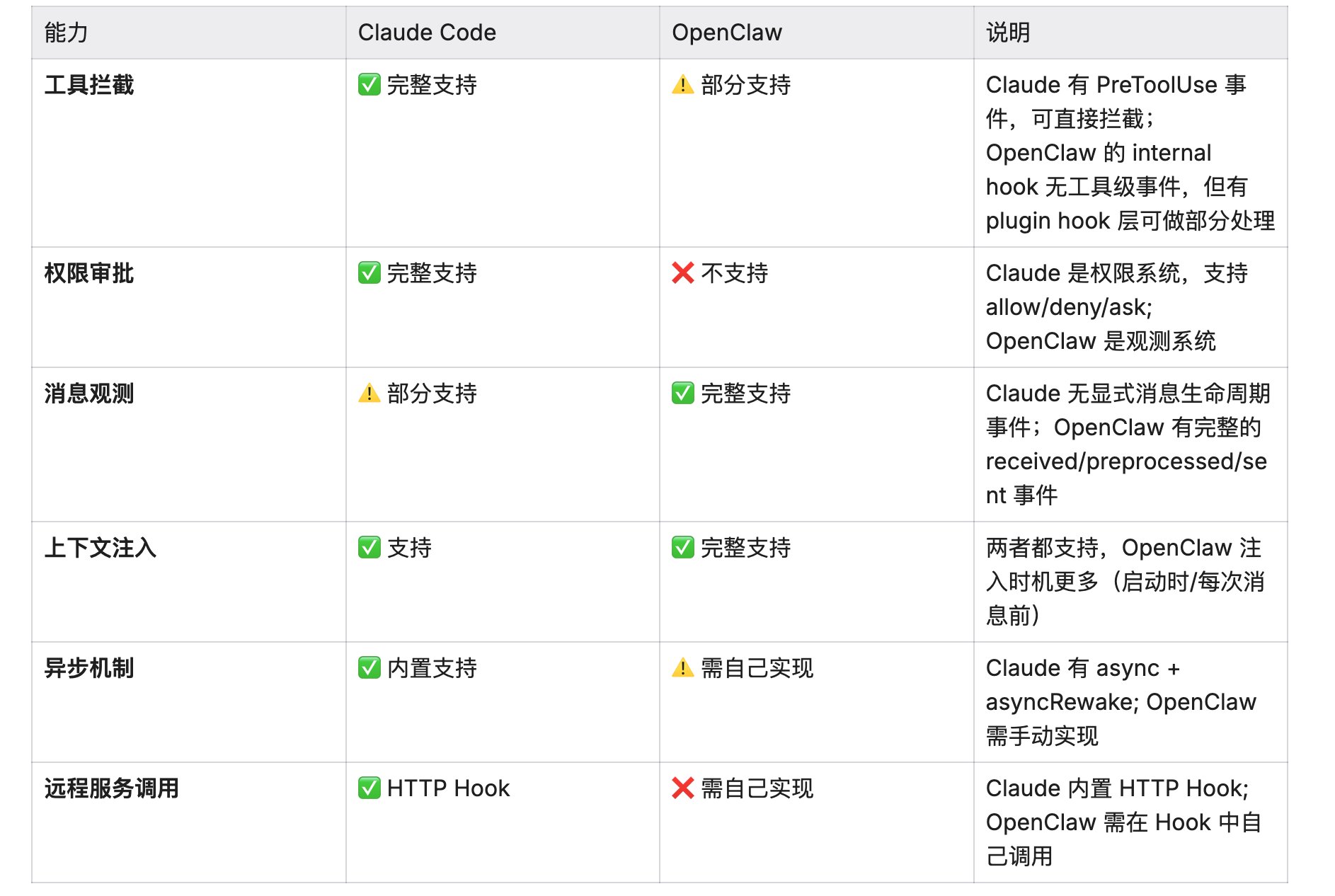
1.4 能力对比
1.5 安全模型对比
Claude Code:零信任 + 多层防护
Plain Text
安全假设:Hook 可能是恶意的
防护措施:
├─ 工作区信任门
├─ 权限决策优先级(deny > ask > allow)
├─ SSRF 防护(阻止访问私有 IP)
├─ CRLF 注入防护
├─ URL 白名单
├─ 环境变量白名单
└─ 超时机制
适用场景:企业环境、多租户、云部署
OpenClaw:本地可信 + 边界防护
Plain Text
安全假设:Hook 是本地可信代码
防护措施:
├─ 路径边界校验(防止路径逃逸)
├─ workspace-relative 约束
└─ 装载策略判定(检查运行条件)
适用场景:本地开发、单用户
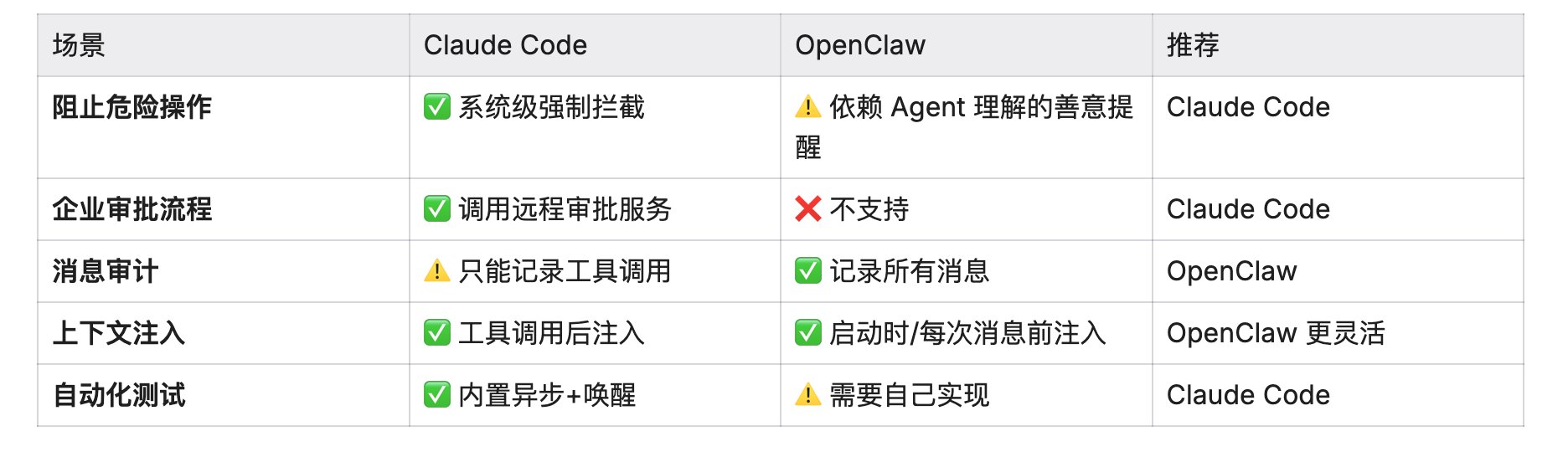
1.6 典型使用场景对比
Claude Code Hooks:工具调用的权限控制系统

有了全局认知后,我们深入了解 Claude Code Hooks 的架构和设计。
2.1 设计意图
Claude Code 的 Hooks 系统围绕一个核心问题设计:如何在 Agent 调用工具时,提供精确的权限控制和审批能力?
这个问题来自企业部署的现实需求:
- Agent 可能调用敏感工具(删除文件、执行 Shell 命令、访问数据库)
- 某些操作需要人工审批(修改生产环境、访问敏感数据)
- 需要与企业的审批流程、合规系统集成
- 需要防止恶意 Hook 绕过安全策略
因此,Claude Code 的 Hooks 是一个权限决策系统,重点在工具调用的拦截和审批。
2.2 核心架构
Claude Code 的 Hooks 系统由两个核心部分组成:
(1)4 种 Hook 类型(执行器)
不同的扩展逻辑需要不同的执行方式,Claude Code 提供了 4 种执行器:
Command Hook— 调用本地脚本
- 用途:运行本地工具(如 lint、test、格式化)
- 执行方式:启动子进程,通过 stdin/stdout 通信
- 典型场景:代码修改后自动运行测试
JSON
{
"type": "command",
"events": ["PostToolUse"],
"matcher": "WriteFile(*.js)",
"command": "npm",
"args": ["test"],
"async": true
}
Prompt Hook— 用 LLM 做决策
- 用途:用自然语言描述决策逻辑
- 执行方式:调用 LLM(默认 Haiku)做单轮推理
- 典型场景:判断文件是否安全、是否需要审批
JSON
{
"type": "prompt",
"events": ["PreToolUse"],
"matcher": "Bash(rm *)",
"prompt": "如果文件路径包含 'node_modules' 或 'dist',返回 allow: true;否则返回 allow: false"
}
HTTP Hook— 调用远程服务
- 用途:与企业系统集成(审批服务、合规检查)
- 执行方式:发起 HTTP POST 请求
- 典型场景:调用企业审批系统获取人工确认
JSON
{
"type": "http",
"events": ["PermissionRequest"],
"url": "approval.company.com/api/check",
"headers": {
"Authorization": "Bearer ${APPROVAL_TOKEN}"
}
}
Agent Hook— 启动子 Agent 做复杂验证
- 用途:需要多轮推理、调用工具的复杂验证
- 执行方式:启动一个子 Agent,最多 50 轮对话
- 典型场景:检查代码是否符合编码规范、是否泄露敏感信息
JSON
{
"type": "agent",
"events": ["Stop"],
"instructions": "检查所有修改的文件,如果包含硬编码的密钥或 API token,返回 allow: false"
}
(2)26 个生命周期事件
Claude Code 定义了 26 个事件,覆盖从会话启动到工具调用、从上下文压缩到子 Agent 协作的全流程。
核心事件(工具调用类):
Plain Text
PreToolUse(工具调用前)
├─ 白话定义:Agent 决定要执行某个操作(如删除文件、运行命令)之前的拦截点
├─ 作用:可以审批、拒绝或修改这个操作
├─ 触发时机:Agent 决定调用工具,但还未执行
├─ 能力:拦截、修改参数、审批、拒绝
└─ 返回值:allow/deny/ask、updatedInput
PostToolUse(工具调用成功后)
├─ 白话定义:Agent 执行完某个操作后的观测点
├─ 作用:可以看到执行结果,并注入额外的上下文或触发后续操作
├─ 触发时机:工具执行成功,返回结果
├─ 能力:观测结果、注入上下文、触发后续操作
└─ 返回值:additionalContext、async
PostToolUseFailure(工具调用失败后)
├─ 白话定义:Agent 执行操作失败时的观测点
├─ 作用:可以记录错误日志、触发告警
├─ 触发时机:工具执行失败
└─ 能力:观测错误、记录日志、触发告警
其他重要事件:
Plain Text
会话管理类
├─ SessionStart:会话开始,初始化配置
├─ SessionEnd:会话结束,清理资源
└─ Stop:会话即将结束,最后的审查机会(可阻止结束)
上下文管理类
├─ PreCompact:上下文即将压缩(白话:对话历史太长,系统准备精简内容)
└─ PostCompact:上下文压缩完成(白话:精简完成,可以查看压缩效果)
权限管理类
├─ PermissionRequest:需要用户确认的操作
└─ PermissionDenied:用户拒绝了权限请求
Agent 协作类
├─ SubagentStart / SubagentStop:子 Agent 启动/停止
└─ TaskCreated / TaskCompleted:任务创建/完成
2.3 核心设计原则
(1)权限决策优先级:deny > ask > allow
这是 Claude Code 最重要的设计原则:
Plain Text
决策流程:
- 检查配置文件:如果 settings.json 明确禁止(deny),直接拒绝
- 检查所有 Hook:收集所有 Hook 的返回值
- 合并决策:
- 任何一个 Hook 返回 deny → 最终结果是 deny
- 任何一个 Hook 返回 ask → 最终结果是 ask
- 所有 Hook 都返回 allow → 最终结果是 allow
为什么这样设计?
在企业环境中,配置文件通常由管理员维护,代表组织的安全策略。Hook 可能由开发者编写,甚至来自第三方。如果允许 Hook 的 allow 绕过配置文件的 deny,就存在安全风险。
通过 deny > ask > allow 的优先级,确保:
- 管理员的决策不能被 Hook 覆盖
- Hook 可以收紧权限(把 allow 变成 ask 或 deny)
- Hook 不能放松权限(不能把 deny 变成 allow)
(2)异步机制:不阻塞主流程
有些 Hook 执行时间很长(如运行完整测试套件),Claude Code 提供了异步机制:
JSON
{
"async": true, // 后台运行,不阻塞主流程
"asyncRewake": true // exit code 2 时唤醒 Agent
}
工作流程:
- Hook 在后台运行,Agent 继续执行
- 如果 Hook 返回 exit code 2,触发“唤醒”
- Agent 收到 Hook 的输出,继续处理
(3)多层安全防护
假设 Hook 可能是恶意的,设计了多层防护:
Plain Text
安全防护措施:
├─ 工作区信任门:所有 Hook 需要用户信任工作区
├─ SSRF 防护:阻止 HTTP Hook 访问私有 IP
├─ CRLF 注入防护:清除 URL/Header 中的特殊字符
├─ URL 白名单:HTTP Hook 只能访问白名单域名
├─ 环境变量白名单:只能使用白名单中的环境变量
└─ 超时机制:Command/HTTP Hook 10分钟,Prompt Hook 30秒
2.4 典型使用场景
场景:阻止危险操作(最能体现权限控制能力)
JSON
{
"type": "prompt",
"events": ["PreToolUse"],
"matcher": "Bash(rm -rf*)",
"prompt": "返回 {"ask": true, "reason": "这个命令会递归删除文件,请确认"}"
}
当 Agent 决定调用 Bash 工具执行 rm -rf 命令时,Hook 会强制弹出确认对话框,用户批准后才能继续执行。这是系统级强制拦截,100% 可靠,无法绕过。
2.5 失效场景与局限性
场景 1:无法观测 Agent 的思考过程
Claude Code 的 Hook 只能拦截工具调用,但无法看到 Agent 在调用工具前的推理过程、消息内容、或者为什么做出某个决策。如果你需要审计“Agent 看到了什么信息”或“Agent 是如何思考的”,Claude Code 无法提供这种能力。
场景 2:配置复杂度高
当你需要实现复杂逻辑时(如“检测项目类型并注入不同的编码规范”),Claude Code 需要编写外部脚本(Command Hook)或调用远程服务(HTTP Hook),配置文件和脚本分离,维护成本较高。对于快速迭代的本地开发场景,这种架构显得过于“重”。
场景 3:异步机制的学习曲线
虽然 Claude Code 提供了内置的异步机制(async + asyncRewake),但理解 exit code 2 的语义、如何正确返回结果、如何避免死锁等问题,需要一定的学习成本。对于简单的异步需求,开发者可能更希望用熟悉的 Promise/async-await 模式。
OpenClaw Hooks:全链路事件观测系统
3.1 设计意图
OpenClaw 的 Hooks 系统围绕另一个问题设计:如何让开发者能够观测 Agent 执行的全链路,并在关键节点注入自定义逻辑?
这个问题来自本地开发的现实需求:
- 需要知道 Agent 收到了什么消息、发送了什么消息
- 需要在消息发送给模型前,注入额外的上下文
- 需要在会话压缩前后,记录指标、保存快照
- 需要在 Agent 启动时,动态加载策略
因此,OpenClaw 的 Hooks 是一个事件总线,重点在全链路观测和灵活扩展。
3.2 核心架构
(1)统一事件模型
OpenClaw 的所有事件都使用统一的结构:

为什么统一?
- 易于扩展:新增事件只需定义 type 和 action,不需要修改 Hook 接口
- 易于复用:所有 Hook 用同样的接口,可以写通用的处理逻辑
- 易于审计:所有事件都有 timestamp 和 sessionKey,可以追踪事件流
(2)5 大事件类别
OpenClaw 定义了 5 大类事件,覆盖从命令接收到会话压缩的全链路。
command 类:命令生命周期
Plain Text
command:new
├─ 触发时机:用户发起新命令(如 /new、/reset)
└─ 能力:命令审计、会话归档
command:reset
├─ 触发时机:用户执行 /reset 重置会话
└─ 能力:清理资源、保存快照
message 类:消息生命周期(核心)
Plain Text
message:received
├─ 触发时机:Agent 收到用户消息
└─ 能力:入站观测、敏感词过滤、消息审计
message:transcribed
├─ 触发时机:语音消息转写完成
└─ 能力:转写质量监控、语音日志
message:preprocessed(关键)
├─ 触发时机:消息预处理完成,即将发送给模型
├─ 能力:上下文注入、消息修改、策略注入
└─ 可回传:可以修改 messages 数组
message:sent
├─ 触发时机:Agent 向用户发送消息
└─ 能力:出站观测、消息审计、发送日志
session 类:会话生命周期
Plain Text
session:compact:before
├─ 触发时机:上下文即将压缩
└─ 能力:压缩前指标采集、快照保存
session:compact:after
├─ 触发时机:上下文压缩完成
└─ 能力:压缩后指标采集、压缩率监控
session:patch
├─ 触发时机:会话状态被修改
└─ 能力:状态同步、增量备份
agent 类:Agent 生命周期
Plain Text
agent:bootstrap(关键)
├─ 触发时机:Agent 启动,加载完配置,即将处理第一条消息
├─ 能力:启动时策略注入、动态上下文注入、工具过滤
└─ 可回传:可以通过 messages 注入系统消息
gateway 类:网关生命周期
Plain Text
gateway:startup
├─ 触发时机:OpenClaw 服务启动
└─ 能力:启动初始化、健康检查注册、指标采集器启动
(3)三层装载体系
OpenClaw 支持从三个层级加载 Hook:
Plain Text
装载层级:
├─ bundled:内置在代码中的 Hook,随软件发布
├─ managed:管理员通过配置文件指定的 Hook
└─ workspace:工作区的 .openclaw/hooks/ 目录中的 Hook
装载流程:
- 扫描三个层级的 Hook 目录
- 读取每个 Hook 的 HOOK.md,检查运行条件
- 使用动态 import 加载 Hook 模块
- 调用 Hook 的导出函数,完成注册
(4)声明式 Hook 描述
每个 Hook 都有一个 HOOK.md 文件,描述元数据:
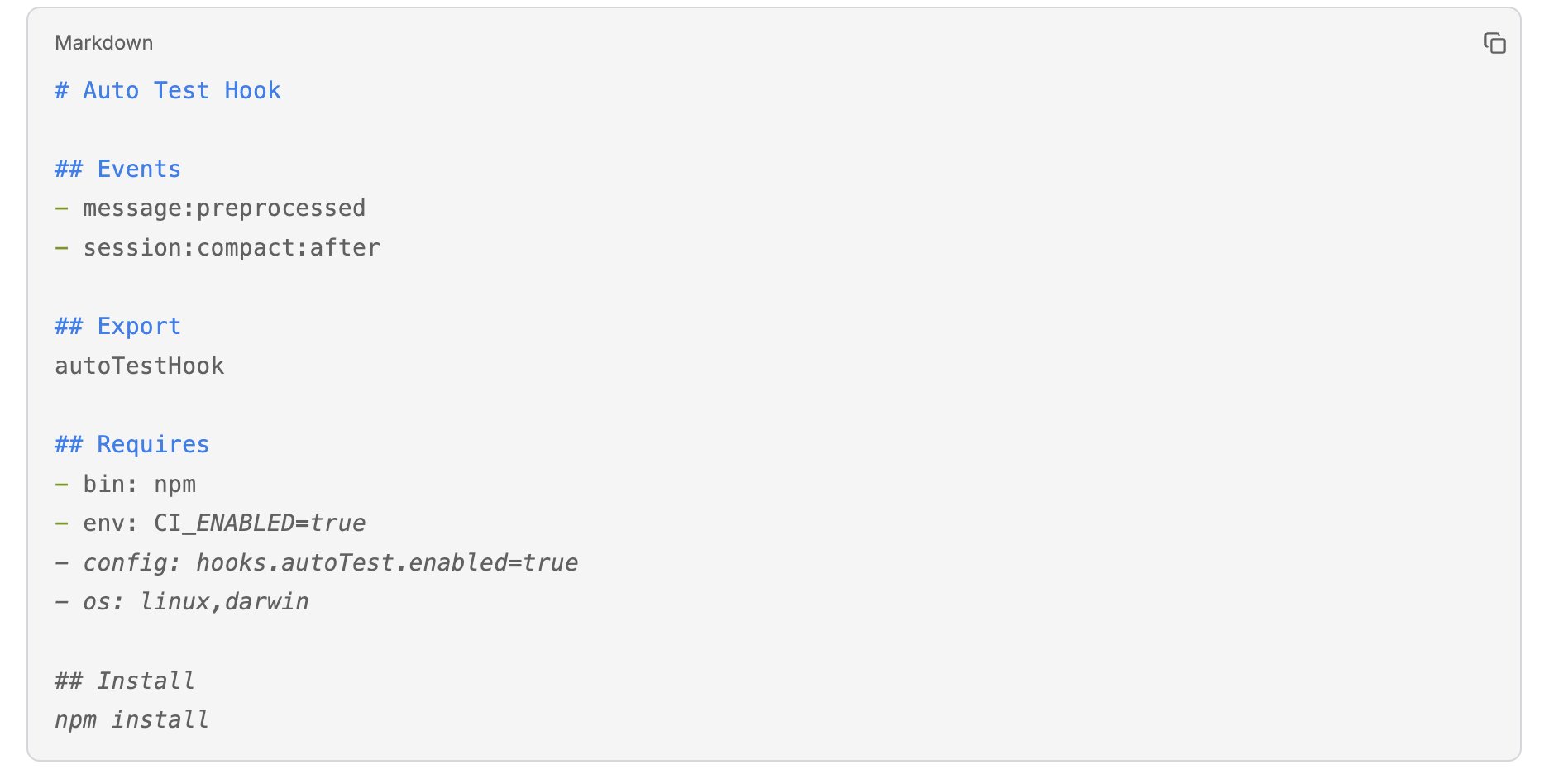
装载器会自动检查 requires 字段,不满足条件的 Hook 不会被加载。
3.3 核心设计原则
(1)本地可信代码模型
OpenClaw 假设 Hook 是由开发者自己编写的,或者来自可信的来源。因此:
- 不做沙箱隔离
- 不做高层权限控制
- 只做基本的边界防护(路径校验、workspace-relative 约束)
文档中明确说明:
Security Model: OpenClaw hooks assume trusted local code. All loaded hooks run with full process privileges. Only load hooks from sources you trust.
(2)统一事件模型
所有事件用同样的结构,带来的好处:
- 新增事件不需要修改 Hook 接口
- 可以写通用的事件处理逻辑(如日志、指标采集)
- 所有事件都可以追踪(timestamp + sessionKey)
(3)全局一致性机制
使用 Symbol.for() 确保全局一致性:

这确保了在模块多次加载的情况下(如 code splitting),所有 Hook 都注册到同一个全局数组。
3.4 典型使用场景
场景:启动时注入项目信息(最能体现全链路观测与灵活注入能力)
在 Agent 启动时,Hook 直接执行项目检测逻辑,根据结果向消息队列注入系统消息。无需外部脚本,一步完成注入,体现了 OpenClaw 的灵活性和简洁性。

3.5 失效场景与局限性
场景 1:无法强制拦截工具调用
OpenClaw 的 Hook 只能通过注入消息来“提醒” Agent,但无法强制阻止 Agent 执行某个操作。例如,即使你在 message: preprocessed 中注入了“不要删除重要文件”的警告,Agent 仍然可能因为理解偏差或上下文过长而忽略这个警告。对于必须 100% 阻止的危险操作,OpenClaw 无法提供可靠保证。
场景 2:缺少企业级集成能力
OpenClaw 没有内置的 HTTP Hook 或远程服务调用机制。如果你需要与企业审批系统、合规检查服务集成,必须在 Hook 中手动实现 HTTP 请求、错误处理、重试逻辑等,开发成本较高。对于需要与外部系统深度集成的企业场景,OpenClaw 的架构显得不够“开箱即用”。
场景 3:安全模型不适合多租户场景
OpenClaw 假设 Hook 是本地可信代码,没有沙箱隔离、没有权限分级、没有 SSRF 防护。如果你在云环境中部署 OpenClaw,允许用户上传自定义 Hook,恶意 Hook 可以访问服务器的任意资源、读取环境变量、甚至攻击内网服务。对于多租户或云部署场景,OpenClaw 的安全模型存在重大风险。
实战场景对比
通过几个典型场景,我们可以更直观地理解两种 Hooks 系统的差异。
场景 1:阻止危险操作
需求:在执行 rm -rf 前强制人工审批
Claude Code 方案:使用 Prompt Hook 监听 PreToolUse 事件,当检测到 Bash(rm -rf*) 时,返回 ask: true,系统会弹出确认对话框,等待用户批准后才继续执行。
OpenClaw 方案:在 message: preprocessed 事件中检测危险命令,向消息队列注入警告:“用户即将执行危险命令,你必须明确询问用户确认”。Agent 看到警告后会主动询问用户。
对比结论:
- Claude Code:系统级强制拦截,100% 可靠,无法绕过
- OpenClaw:依赖 Agent 理解警告,可能被绕过(如果 Agent 没理解或忽略)
场景 2:自动运行测试
需求:代码修改后自动运行测试,失败时通知 Agent
Claude Code 方案:使用 Command Hook 监听 PostToolUse 事件,当 WriteFile(*.ts) 触发时,异步运行 npm test。如果测试失败,通过 asyncRewake 机制自动唤醒 Agent 并通知结果。
OpenClaw 方案:在 message: preprocessed 事件中检测代码修改,手动启动异步测试任务,并需要自己实现消息发送机制将测试结果通知给 Agent。
对比结论:
- Claude Code:内置异步机制和自动唤醒,开箱即用
- OpenClaw:需要自己实现异步逻辑和消息发送机制
场景 3:启动时注入项目信息
需求:Agent 启动时,根据项目类型注入编码规范
Claude Code 方案:在 SessionStart 事件中调用外部脚本检测项目类型,脚本返回 additionalContext(如“使用函数组件和 Hooks”),系统自动注入到 Agent 上下文。
OpenClaw 方案:在 agent: bootstrap 事件中直接执行项目检测逻辑,根据结果向 event.messages 数组添加系统消息,一步完成注入。
对比结论:
- Claude Code:需要外部脚本,配置稍复杂
- OpenClaw:直接在 Hook 中写逻辑,更简洁灵活
如何选择

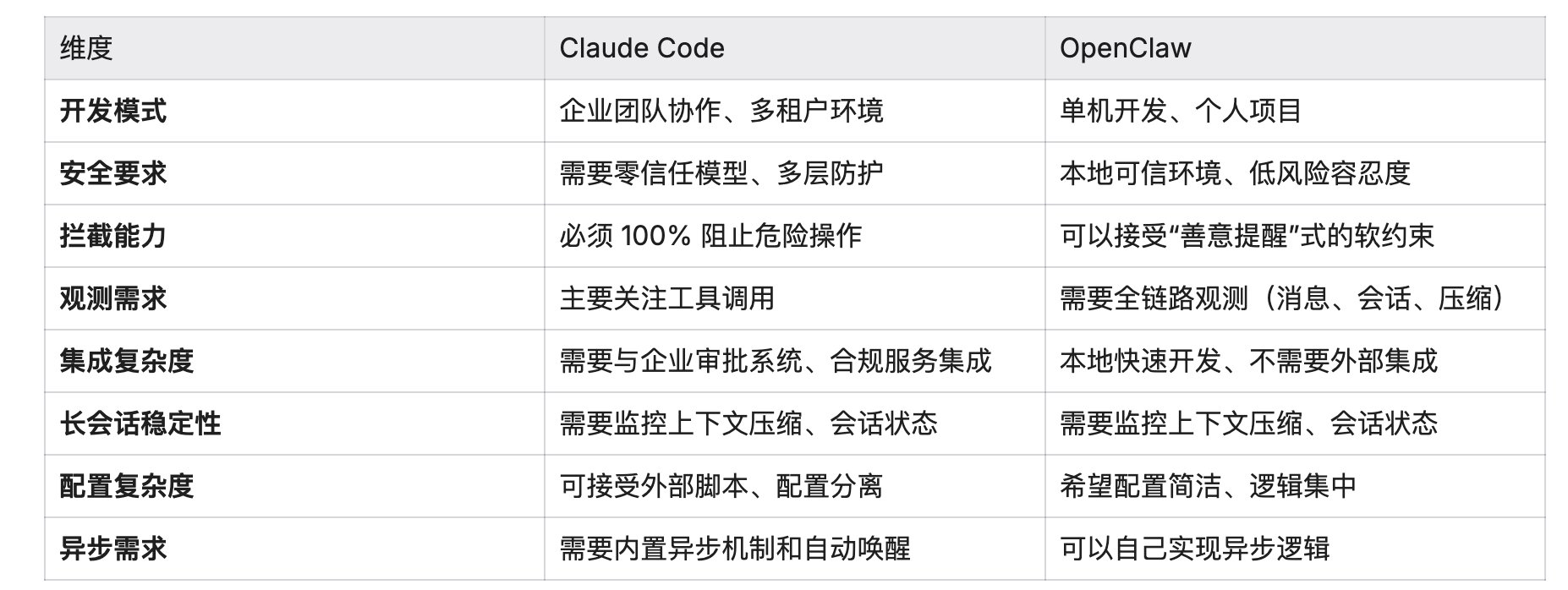
选择 Claude Code,如果你:
✅ 在企业环境中使用
- 需要严格的权限控制
- 需要与企业审批系统集成
- 需要合规审计
✅ 需要强制拦截工具调用
- 某些操作必须经过审批
- 需要阻止危险操作
✅ 担心 Hook 的安全性
- Hook 可能来自第三方
- 需要多层安全防护
✅ 需要内置的异步机制
- 需要后台运行长耗时任务
- 需要自动唤醒 Agent
典型用户:大公司开发团队、需要合规审计的项目
选择 OpenClaw,如果你:
✅ 在本地开发环境使用
- Hook 是自己编写的
- 不需要企业级安全防护
✅ 需要观测全链路
- 需要看到所有消息(收到/发送)
- 需要监控会话压缩、Agent 启动等事件
✅ 需要灵活的扩展能力
- 需要在任何环节注入逻辑
- 需要快速编写和测试 Hook
✅ 需要简洁的配置
- 不想写外部脚本
- 希望直接在 Hook 中写逻辑
典型用户:个人开发者、研究人员、需要高度定制的场景
总结
Claude Code 和 OpenClaw 的 Hooks 系统,代表了两种不同的设计哲学:
Claude Code:工具中心 + 权限控制
- 围绕“工具调用”构建
- 重点在拦截、审批、权限决策
- 适合企业环境、需要严格控制
OpenClaw:事件中心 + 全链路观测
- 围绕“事件流”构建
- 重点在观测、注入、灵活扩展
- 适合本地开发、需要灵活定制
没有哪个更好,只有哪个更适合你的场景。
选型条件表
快速决策:
- 如果你需要严格控制,选 Claude Code
- 如果你需要灵活观测,选 OpenClaw
或者,你可以结合两者的优点:
- 从 Claude Code 学习权限决策机制和异步机制
- 从 OpenClaw 学习统一事件模型和消息生命周期