
做 AI Agent 时,数据采集一直是最头疼的环节。试过不少 GitHub 开源爬虫:MediaCrawler(只做国内平台)、wechat_articles_spider(有封号风险、延迟严重)、jina-cli(不能批量采集)、Agent-Reach(稳定性差、平台一更新就挂)……每个都有各自的局限。
当不想折腾的时候发现了 XCrawl:API 服务,稳定可靠,3 行代码搞定。(地址在最下面)
最打动我的是它内置浏览器指纹 + 住宅代理轮换——做过爬虫的都知道,这是最难搞定也最容易被封的部分。传统方案需要自己搭代理池、处理指纹伪装、写反爬逻辑,XCrawl 全部内置了,开箱即用。
另外,如果你在用 OpenClaw构建 AI Agent,XCrawl 提供一键配置集成,直接赋予 Agent 数据采集能力。
今天分享一下实际使用经验,希望能帮到有类似需求的朋友。
先说三个真实场景
场景 1:社交媒体数据监控(推特/公众号/抖音/小红书)

你在做品牌舆情监控、竞品分析或者内容运营,需要追踪多个社交平台上的热门内容、用户评论、互动数据。传统方案的痛点:
- 每个平台的反爬机制都不一样,需要分别处理
- 推特、小红书等平台对爬虫检测很严格,IP 很容易被封
- 动态加载的内容(无限滚动、懒加载图片)难以完整抓取
- 需要提取的数据结构复杂:文本、图片、点赞数、评论、转发量等
XCrawl 的解决方式:
from xcrawl import XCrawl
app = XCrawl(api_key="your_key")
抓取推特帖子
twitter_data = app.scrape('twitter.com/user/status/123456', extract=['text', 'likes', 'retweets', 'comments'])
抓取小红书笔记
xiaohongshu_data = app.scrape('xiaohongshu.com/explore/123', format='json')
抓取公众号文章
wechat_article = app.scrape('mp.weixin.qq.com/s/xxx', format='markdown')
实际应用价值:
- 品牌监控:自动追踪品牌在各平台的提及、评价和讨论热度
- 竞品分析:监控竞品的内容策略、互动数据、用户反馈
- 热点挖掘:抓取热门话题下的高赞内容,分析用户偏好
- KOL 追踪:监控关键意见领袖的发文内容和数据表现
- 内容灵感:收集同行业优质内容,为自己的内容创作提供参考
XCrawl 会自动处理这些平台的反爬机制,内置的住宅代理轮换和浏览器指纹让你不用担心被封。而且它能自动等待动态内容加载完成,确保抓取到完整的帖子、评论和互动数据。返回的是结构化 JSON 数据,可以直接导入数据库或 Excel 进行分析,省去了大量的数据清洗工作。
场景 2:电商价格监控
你需要追踪竞品在各大电商平台的价格变化。问题在于:
- 电商网站反爬虫机制很强,IP 很容易被封
- 商品信息分散在不同标签里,提取很麻烦
- 需要处理无限滚动、动态加载
XCrawl 的实现:
result = app.scrape('example-shop.com/product/123', extract=['title', 'price', 'reviews', 'rating'])
返回结构化的 JSON 数据,内置的住宅代理轮换和浏览器指纹让你不用担心被封。官方数据显示任务成功率稳定在 90% 以上,远超行业平均水平,这个在实际使用中确实靠谱。
场景 3:SEO 竞品分析与搜索引擎数据采集
你想知道竞品在 Google 搜索某个关键词时的排名情况,或者需要深度分析搜索结果页的富结果、相关搜索、知识图谱等信息。传统方案需要:
- 单独购买 SERP API 服务
- 处理 Google 的反爬虫机制
- 解析复杂的搜索结果页面
- 处理不同地区、语言、设备的差异
XCrawl 提供两种解决方案:
**方案 1:Search API(快速获取基础搜索结果)**适合日常 SEO 监控、内容研究等场景:
快速获取搜索结果的核心数据
result = app.search('AI web scraping tools', engine='google', location='US', language='en')
返回结构化 JSON,包含排名、标题、链接、描述等核心字段。
**方案 2:SERP API(深度搜索引擎结果页采集)**适合专业级 SEO 深度分析、竞品情报、区域市场研究:
获取完整的 SERP 数据,包括富结果
serp_data = app.serp('AI web scraping tools', engine='google', location='US', device='desktop', time_range='past_month')
返回完整的 SERP 数据,涵盖:
- 自然搜索排名
- 富结果(视频、图片、购物广告)
- People Also Ask(相关问题)
- 知识图谱
- 相关搜索
- 本地搜索结果
支持高度灵活的本地化参数、设备模拟(移动/桌面)、高级过滤(时间、地区、文件类型),可以定向采集特定结果类型(新闻、本地、图片)。
如何快速上手?
- 安装和配置(30 秒)
pip install xcrawl-py
去 xcrawl.com 注册账号,复制 API Key(新用户有 1,000 免费 Credits,不需要信用卡)。
如果你在使用 OpenClaw:
XCrawl 提供了一键配置集成方案,可以直接在 OpenClaw 中导入 XCrawl 配置,让你的 AI Agent 立即获得强大的网页数据采集能力。无需手动编写代码,通过可视化界面就能完成配置,大幅提升 Agent 的数据获取效率。
- 基础抓取(最简单的例子)
from xcrawl import XCrawl
app = XCrawl(api_key="xc-YOUR_API_KEY")
抓取网页内容
result = app.scrape('example.com')
print(result['content']) # 干净的文本内容 print(result['markdown']) # Markdown 格式 print(result['json']) # 结构化数据
就这么简单。不需要配置浏览器、代理、User-Agent,什么都不用管。
- 高级功能展示
批量抓取多个页面:
urls = [ 'blog.com/post-1', 'blog.com/post-2', 'blog.com/post-3' ]
results = [app.scrape(url, format='markdown') for url in urls]
爬取整个网站:
从首页开始,智能爬取整个网站
result = app.crawl('example.com', max_depth=3, max_pages=100)
获取网站地图:
导出网站所有 URL
sitemap = app.map('example.com') print(sitemap['urls']) # 所有发现的链接
截图功能:
result = app.scrape('example.com', screenshot=True)
返回 base64 编码的截图
SERP 深度数据采集:
获取完整的搜索引擎结果页数据
serp_result = app.serp('keyword research', engine='google', location='US', device='mobile') print(serp_result['organic_results']) # 自然搜索结果 print(serp_result['related_questions']) # People Also Ask print(serp_result['knowledge_graph']) # 知识图谱
几个实用技巧
技巧 1:处理需要登录的网站
result = app.scrape('example.com/dashboard', cookies={'session_id': 'your_session'})
技巧 2:等待特定元素加载
result = app.scrape('example.com', wait_for='#product-price')
技巧 3:自定义提取规则
result = app.scrape('example.com', extract={ 'title': 'h1.product-title', 'price': '.price-tag', 'reviews': '.review-list' })
与传统方案对比
我之前用过 Puppeteer + 自建代理池的方案,对比一下:
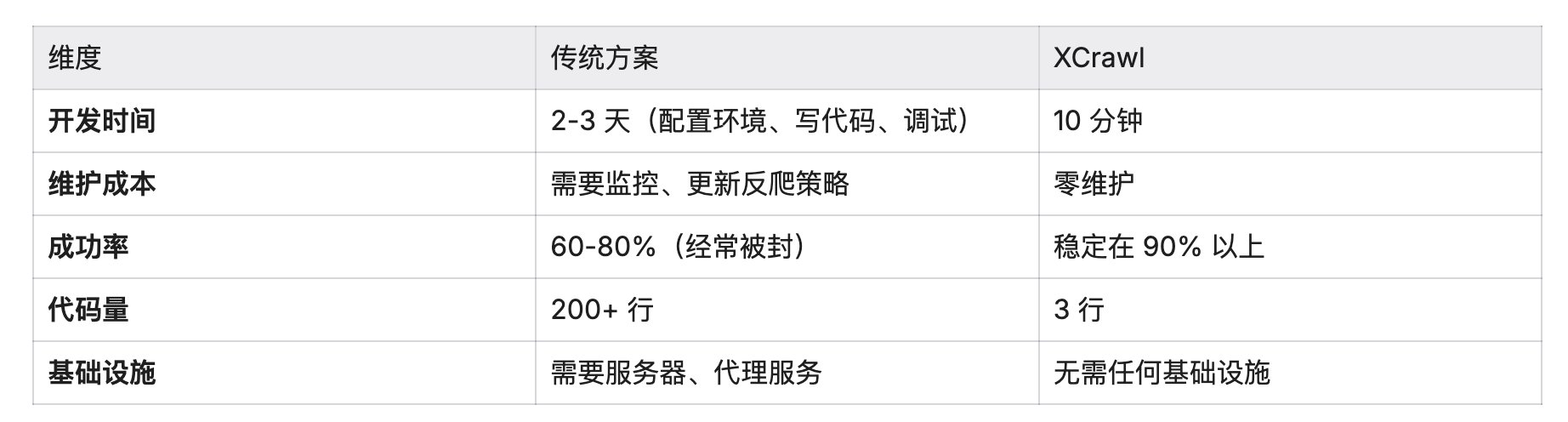
对于大多数场景,XCrawl 的性价比明显更高。除非你有非常特殊的定制需求,否则真的没必要自己造轮子。
用它做了几个项目:
- 社交媒体监控:每天自动抓取小红书、微博上的品牌提及和竞品动态,整理成日报,运行了一段时间,任务成功率稳定在 90% 以上
- 价格监控系统:每天自动抓取 50 个竞品的价格,运行了 1 个月,采集成功率远超行业平均水平
- SEO 排名追踪:监控 20 个关键词在 Google 的排名变化,每周自动生成报告,数据准确性和稳定性表现优异
核心优势总结
经过一段时间的使用,我总结了 XCrawl 最打动我的几个点:
- 真正的开箱即用
不需要配置任何东西。传统方案你需要:
- 搭建代理池(或购买代理服务)
- 配置无头浏览器(Puppeteer/Selenium)
- 处理浏览器指纹、User-Agent 轮换
- 写反爬虫对抗逻辑
XCrawl 把这些全部内置了,你只需要关注“我要抓什么数据”,而不是“怎么绕过反爬虫”。
- 内置浏览器指纹 + 住宅代理轮换(这个能力是重点)
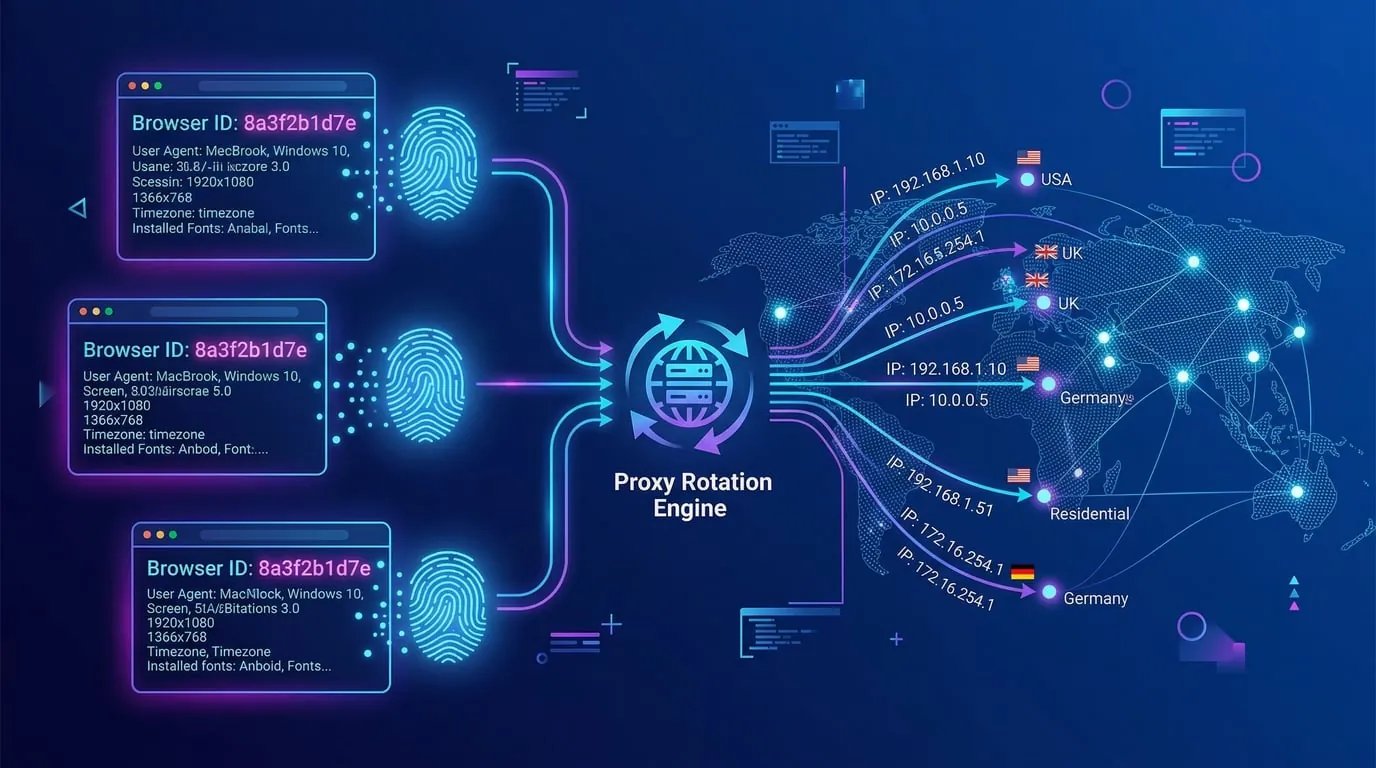
这个功能真的很强。很多网站会检测:()
- IP 地址(数据中心 IP 很容易被识别)
- 浏览器指纹(Canvas、WebGL、字体等)
- 行为特征(鼠标移动、滚动速度等)
XCrawl 自动模拟真实用户行为,使用住宅代理池,任务成功率稳定在 90% 以上,远超行业平均水平。这在抓取电商、社交媒体这类反爬严格的网站时特别重要。
- 支持现代网站技术栈
现在很多网站都是用 React、Vue 这些框架构建的单页应用(SPA),内容是 JavaScript 动态加载的。传统的 HTTP 请求只能抓到空壳 HTML。
XCrawl 内置无头浏览器,会等待 JavaScript 执行完成、等待关键元素加载后再提取数据。对于无限滚动、懒加载这些场景也能自动处理。
- 数据格式开箱即用
返回的数据直接就是干净的:
- JSON:结构化数据,直接入库
- Markdown:适合喂给 AI 模型(比 HTML 省 Token)
- HTML:需要原始结构时使用
- 截图:可视化验证
不需要自己写正则表达式或 XPath 去清洗数据。
- 四合一 API + OpenClaw 深度集成
一个工具解决四类需求:
- Scrape API:抓取单个页面
- Crawl API:爬取整个网站
- Map API:导出网站地图
- Search API:获取搜索引擎基础结果
- SERP API:深度搜索引擎结果页采集
以前这些可能需要分别购买不同的服务。
特别是对 OpenClaw 用户:XCrawl 提供了一键配置集成方案,可以直接为你的 AI Agent 赋予这五大数据采集能力。通过可视化配置界面,无需编写复杂代码,就能让你的 Agent 具备从单页抓取到全站爬取、从基础搜索到深度 SERP 分析的完整能力。这大幅提升了 Agent 的数据获取效率和应用场景覆盖面。
适合谁用?
品牌运营、数据分析师、增长团队、SEO 从业者、AI 开发者、独立开发者——只要需要定期采集网页数据,又不想花时间维护爬虫基础设施的,都适合。
注意事项
- 合法合规:只抓取公开数据,遵守 robots.txt 和服务条款
- 频率控制:避免给目标网站造成压力
- 成本控制:大规模使用时注意 Credits 消耗
总结
XCrawl 把网页数据抓取做到了极致产品化:3 行代码、零维护、直接获得干净数据。新用户有 1,000 免费 Credits,足够测试大部分场景。相比自建爬虫系统,成本低得多。
- 开发者不需要关心底层的反爬虫、代理轮换、浏览器渲染
- 直接获得结构化的干净数据
- 3 行代码就能实现以前需要几天开发的功能
- 零维护成本,专注于数据应用而不是基础设施
如果你正在做需要网页数据的项目,不妨试试👇
相关资源:
- 官网:https://xcrawl.com
- 文档:https://docs.xcrawl.com
- Python SDK:pip install xcrawl-py
- Node.js SDK:npm install xcrawl
有问题欢迎在评论区交流,我会尽量回复