
别用玄学写Prompt了,我用一套三层架构把AI写作变成了工程测试
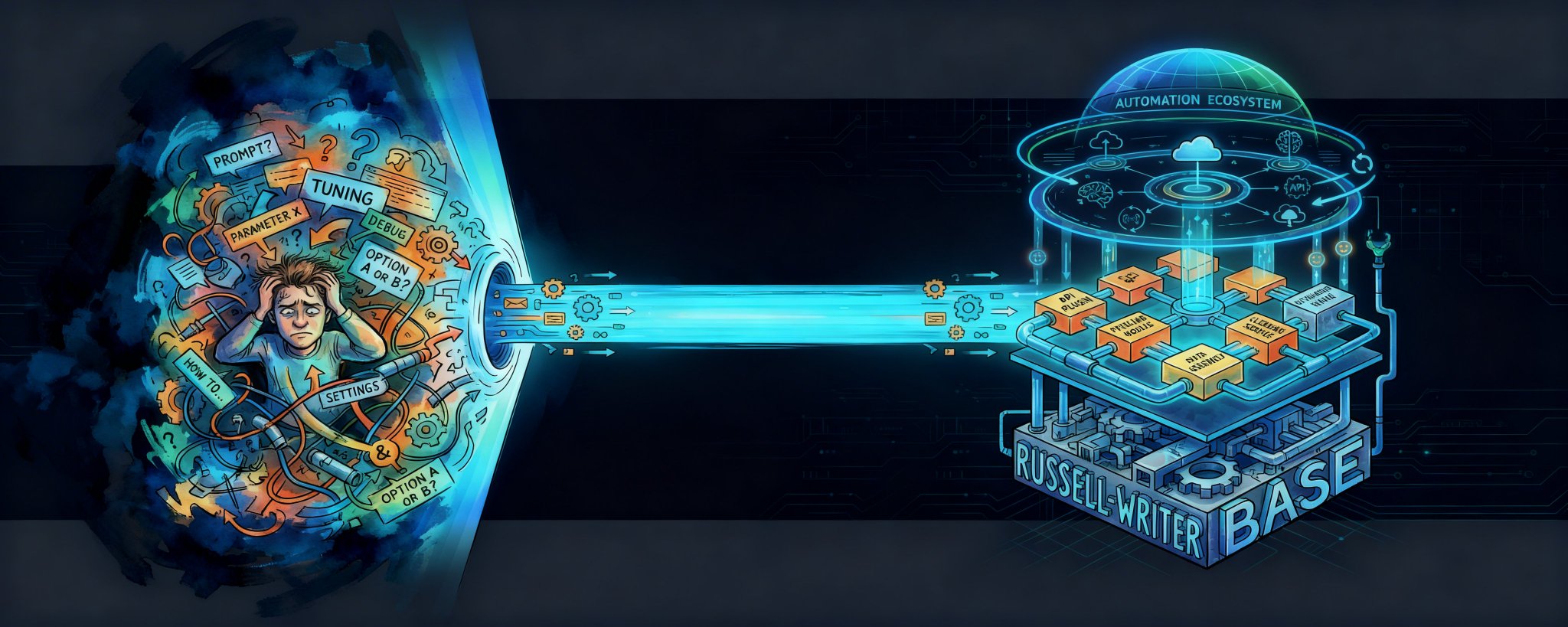
很多人对AI写作的理解还停留在“玄学调参”阶段。
今天加一句“你要幽默风趣”,明天塞个“扮演资深专家”,后天再加一段冗长的背景设定。
最后跑出来的文章,依然像一份散发着工位班味儿的实习生周报——四平八稳绝对正确,但读起来毫无生气。
我是做开发转产品出身的,受不了这种黑盒里的祈祷。
把一段带有几十个形容词的自然语言扔给大模型,期望它能刚好给你“对的感受”,这是典型的业务灾难。
真正想把AI作为生产力核心组件,你就必须把“写文章”这件感性的、带有灵感色彩的事,降维、拆解成代码层级的系统工程。
过去几个月,我停掉了所有庞大的写作模型,基于Obsidian重构了一套具有绝对强制力的三层架构工作流。
它不再是一个“懂写作的机器人”,而是一条由严密规则、数据清洗管线和自动化测试套件组成的装配线。
目录
第一层:基础层 (Layer 1) —— 独裁底盘
第二层:应用层 (Layer 2) —— 模块化挂载与管线清洗
纯量继承的 tweet-writer 组件
Hook 拦截器:Humanizer 的暴力去油车间
第三层:流程层 (Layer 3) —— 全链路状态流转的 Obsidian Pipeline
全景自动化生态:用 API 接管边缘脏活
数据对齐与审计组件
生态挂载与脏活外包
第一层:基础层 (Layer 1) —— 独裁底盘
所有的系统调用,都必须建立在一个不可动摇的基础设施上。我剥离了所有特定场景的杂质,打造了一个基础。
它不教机器“如何写作”,不提供任何模板。
它的核心逻辑围绕着:人设基态注入与语料对齐、强类型约束以及异常阻断。
核心机制一:人设基态注入与全维知识库挂载
在施加任何规则之前,必须先给系统注入“灵魂”和“记忆”。
第一,人设配置。
我把自己那套身份标签,直接写进系统 Prompt 的底层。这保证了它所有发声点,都天然带着理性、锋利、追求逻辑闭环的底色。
第二,历史资产库对齐。
大模型默认是健忘且平庸的。所以我把过去沉淀的高质量文章和独立思考,打包成专属知识库挂载进去。在生成任何新内容前,基类都会先做检索,提取我历史的口吻、遣词习惯和思考框架。
这样不管遇到什么新话题,输出都像“我的大脑在发声”,而不是一个陌生 AI 在生搬硬套。
核心机制二:Anti-Patterns 反共识禁区与语法级拦截
绝大多数人写系统 Prompt,只会堆 Positive Prompt,也就是“你应该怎样写”。
但我发现,Negative Prompt,也就是“你绝不能怎样写”,约束力强一百倍。
所以我直接把禁区写进系统的最高执行层。
第一,AI 语言味清洗。
模型一写长文,就会自动滑向那套塑料连接词。
我建立了一个正则匹配库,一旦输出中捕获到 Additionally、Furthermore、In conclusion、It is worth noting 这类典型塑料词汇,底层就会直接判定为脏数据,强制重写段落。中文里,“综上所述”“不可否认”“毋庸置疑”也一样,全部锁死。
第二,语感阻断。
系统禁止使用模糊词态,比如“可能”“大概”“或许”,也禁止廉价网感词,比如“家人们”“懂的都懂”。一旦检测到,直接抛出ToneViolation。
第三,句式强制校验。
为了切断 AI 最爱的连词堆砌,我加了一条极硬的标尺:每个段落首句长度必须小于 15 个汉字。
核心机制三:Pressure Test 前置压力测试与自我对抗
在这个系统里,不存在未经推敲的单行道观点。
模型准备输出某段核心逻辑前,我会植入一个CoT钩子,强制它先写出这个观点的反方立论。
这跟软件开发里的单元测试是一回事。你得先拿最苛刻的 edge case 去撞主函数。
如果 AI 扮演的“反方杠精 / 行业专家”,能用更强的数据或逻辑把原始立论撕碎,也就是反方说服力权重大于原始论点权重,系统就自动抛弃这个想法。只有当正方防守成功,这段内容才有资格落笔。
这一步,直接掐死所有废话和显而易见的常识。
核心机制四:Evolution Log 跨周期自我进化循环
这是它和普通静态 Prompt 最大的分水岭。
大模型默认是无状态的。
你今天指出它一次错误,它下次照犯不误。
但这套基础层外挂了一份 evolution_log.md。
第一,拦截反馈。
当我对文章提出“太软、太废、太虚”的批评时,系统在修改正文的同时,必须并行向日志写入一条带时间戳和 action item 的记录。
第二,战前读取。
下一次长文任务启动时,底层会先加载这份日志,把里面沉淀下来的“绝对不能再犯的错误”和“最新语气偏好”重新注入上下文。
它不再是一段死脑筋提示词,而是一个拥有长期肌肉记忆的主脑。
第二层:应用层 Layer 2 —— 模块化挂载与管线清洗
基础底层打牢之后,应用层就变成纯粹的积木拼装。这一层严格遵循 DRY 原则。
纯量继承的 tweet-writer 组
写推文时,最蠢的做法,就是在推文 Prompt 里重新教一遍 AI“我是谁,我怎么说话”。
我的 tweet-writer 只是一个极轻量的应用实例。它直接继承底层设定,只额外挂载推文场景下的特殊插件。
第一,Hook 模板注入。
面对不同素材,脚本会动态分配 8 种高转化结构,比如 AIDA、PAS、BAB、Extreme,把论点塞进结构里,作为强类型数据载体。
第二,结构化输出管线。
作为国际化产品开发者,我强制模型直接输出 JSON:{"zh": "中文主帖", "en": "English Thread"}
这不是为了好看,而是为了直接接入后续自动化分发脚本。人不需要再复制粘贴,也不需要再手动翻译一遍。
Hook 拦截器:Humanizer 的暴力去油车间
即便有了底层约束,最新的大模型,比如 GPT-5.4,依然有一种改不掉的“维基百科腔”。
所以在数据最终流出应用层之前,必须经过一个叫 humanizer 的后置清洗滤镜。它基于一份长达五十页的《AI 写作特征识别手册》构建。
第一,打碎机械对称。
大模型极度偏爱“不仅仅是 A,而且是 B”这种对称排比。检测到这种过于工整的句式,humanizer 就会强行把它打碎,改成一句带颗粒感的单句。
第二,切除过载定语。
如果一句话后面拖着复杂的 -ing 结构,或者出现“象征着……”“彰显了其深刻意义”这种尾巴,就说明模型又在强行升华。系统会自动扫描并切掉这些没有信息量的废话结尾。
第三层:外围生态层 Layer 3 —— 从写作单点到自动化全景防御
真正的系统架构,不应该只盯着单一文本生成。它必须像微服务集群一样,在外挂管线里处理所有边缘异常。

核心写作输出完成后,工作流会自动进入第三方脏活处理节点。
1.数据对齐与强力审计
Fact-Checker,事实防火墙。
在这个伪造文献和错引数据满天飞的时代,所有硬数据都是高风险资产。这个组件会在完稿时静默唤醒,自动提取文章里所有数字、年份,甚至投资人的一句话,然后强行调用 WebSearch,到权威页面做交叉核验。
它不负责给修改意见,它只输出一份 JSON 或 Markdown 核查报告,对每一处断言标注风险等级:高、中、低。
News-Selector,信息策展人。
在最上游素材池里,我挂了一个独立 Agent。它每天自动进数据库捞出 Top 5 候选事件,再触发 WebSearch 去抓 Hacker News、TechCrunch 上下文,压缩成最干燥的信息包,供下一轮长文调度。
2.多面挂载与输出末端代理
twitter-engage
扫描时间线,判定情绪,套框架,输出高赞回复草稿。把被动发推变成主动狙击。
typefully-scheduler
完稿后的推文线程,通过 API 自动推送进发送队列。
通用处理口
如果丢给系统一个三万字文档或者超长播客,summarize 会先把它碾成提纲
如果文章卡在视觉表达上,就调用 nanobanana,生成视觉草图。
不要做工具的搬运工,要做管线的架构师。
把你极度抗拒的“啰嗦”“鸡汤”“温室观点”,变成代码里的绝对报错;把你推崇的“短促”“锋利”“真实”,变成工作流里的基础参数。
把所有玄学剥离干净之后,AI 依然写不出文豪级的惊世之作。
但它会变成那个在无限算力下,冷酷、高效、稳定、永不翻车的最强主脑。