
吴恩达 AI Prompt 免费课:普通人判断答案来源的 3 种方法

这是我整理吴恩达免费新课 AI Prompting for Everyone ( deeplearning.ai )的第 2 篇笔记。
这一篇专门拆第一章:Finding Information(信息获取)
很多人用 AI 的方式是这样的——
想到什么问什么,问完就信。
但吴恩达这章讲的是一个更底层的问题:
在问 AI 之前,先判断这个答案应该从哪里来。
AI 获取信息有三种方式:模型已有知识、网页搜索、Deep Research。
这三种方式不是哪个更好,而是对应三类完全不同的问题。搞混了,答案就容易出错。
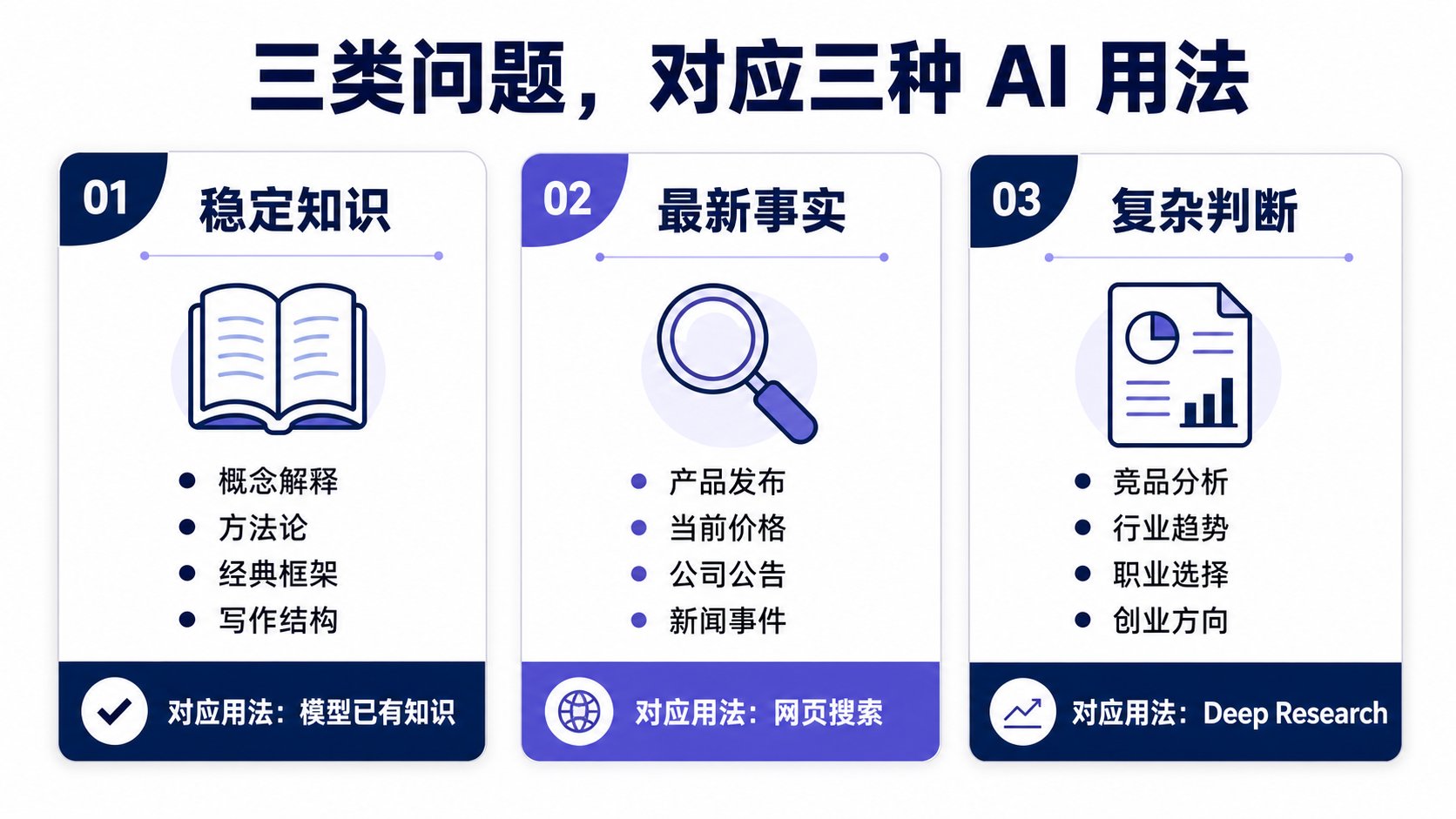
1|模型已有知识:打底用,不查最新事实
模型在训练时已经"读"过大量文本,可以直接回答很多问题——不需要搜索,也不需要联网。
适合这类问题:
概念解释、方法论、经典框架、写作结构、学习路线、历史背景
一个实际例子:
请用通俗语言解释 Deep Research 和普通搜索的区别,包含:一句话定义、核心原理、3 个实际例子、常见误区。
不需要搜索,模型知识就够了,而且效率更高。
⚠️** 但要警惕这些关键词出现在你的问题里:**
最新 / 当前 / 今天 / 价格 / 刚发布 / 现在还能用吗
只要问题里有这些词,靠模型记忆就很容易过期甚至出错。
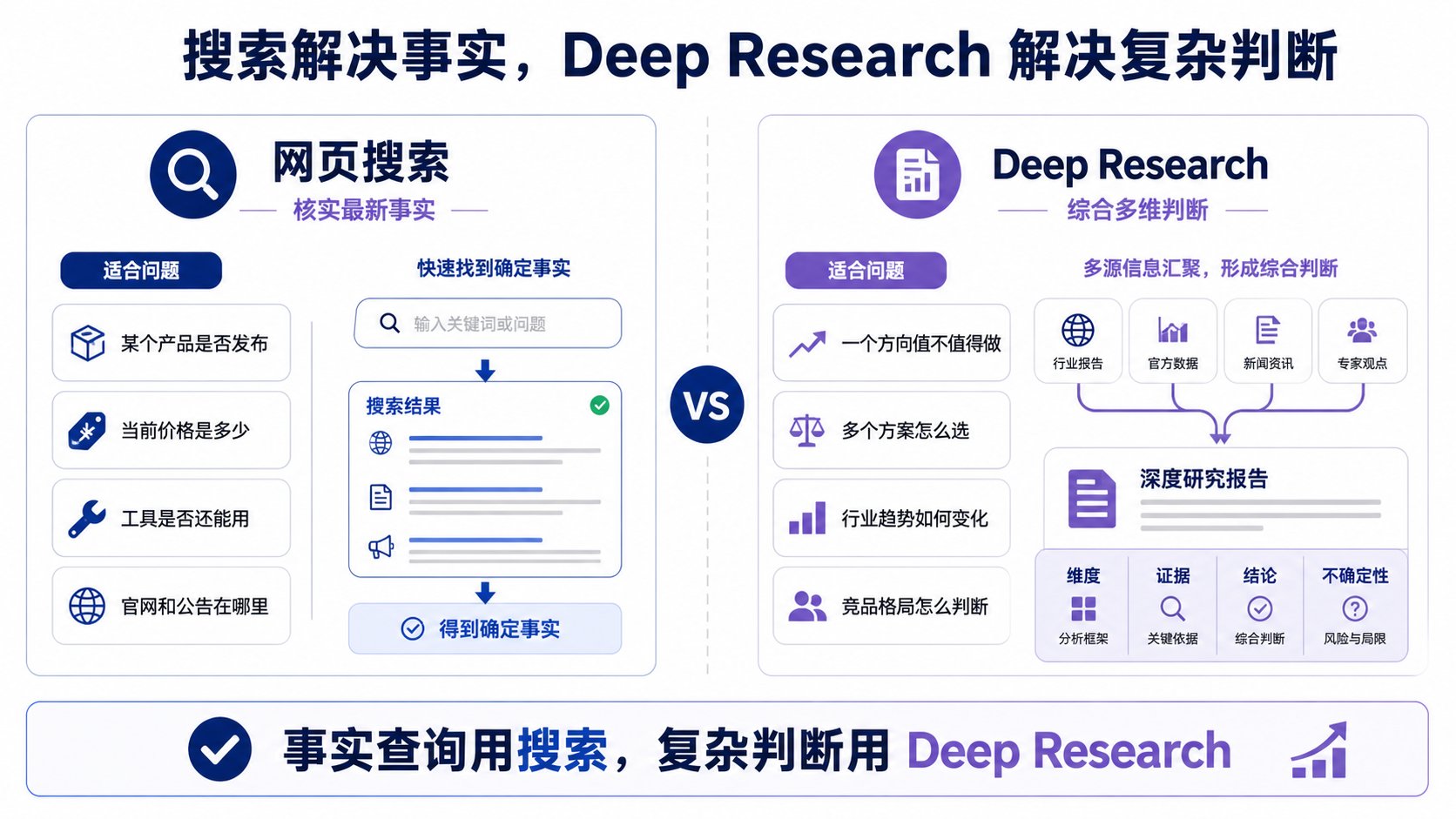
2|网页搜索:涉及最新事实就上
这类问题适合让 AI 搜索:
- 最新产品发布
- 当前价格 / 政策
- 公司公告 / 新闻
- 某个工具是否仍然可用
弱提示词 vs 强提示词对比:
❌ 弱:帮我搜一下吴恩达这个课讲什么。
✅ 强:
请基于 DeepLearning.AI 官方课程页,整理这门课的公开内容。
只使用可核验的信息,不要补编视频细节。
输出:课程模块、每个模块重点、适合谁学。
关键点: 要求 AI 区分"确定事实、来源依据、仍需验证"这三类,能大幅减少 AI 一本正经瞎编的情况。
3|来源质量:比"搜到了"更重要
吴恩达这章有一节专门讲 Web Search Sources——这是很多人跳过的部分,也是差距最大的地方。
AI 搜到信息不等于信息可靠,来源类型直接决定结论质量。
来源可信度分三层:
最高优先级是官方来源——官方公告判断功能是否存在,官方文档看使用方式和限制。这两类能核实的,不要用其他来源替代。
次一级是权威引用——公司博客了解产品方向,权威媒体分析行业影响,论文和 GitHub 看技术细节,但要注意更新时间。
最后一层是社区内容——社区讨论和聚合站转述只适合发现线索、了解用户体验,不能作为最终依据。

Prompt 模板:
请按来源可靠性排序回答。
第一优先级:官方公告和官方文档。
第二优先级:权威媒体和研究机构。
第三优先级:社区讨论和用户反馈。
请标注每个结论来自哪类来源,并说明哪些是事实、哪些是推断。

4|Deep Research:复杂判断才用它
Deep Research 不是"更强的搜索",它解决的是另一类问题。
不适合用 Deep Research 的问题:
某个产品有没有发布 / 某工具官网是什么 / 一个概念是什么意思
这些用搜索就够了。
适合 Deep Research 的问题:
- 要不要做某个方向
- 分析竞品 / 行业趋势
- 判断某个职业/工具是否值得投入
- 写一份完整研究报告
- 比较多个方案并给出建议
这类问题需要多个来源、多个维度、不同观点、综合判断——不是查一个网页就能回答的。
个人决策模板:
我正在考虑……
请用 Deep Research 方式分析:成本、收益、风险、替代方案、适合人群、长期影响。
最后给出结论,并说明哪些前提变化后结论会失效。
一句话区别:
搜索解决事实,Deep Research 解决复杂判断。
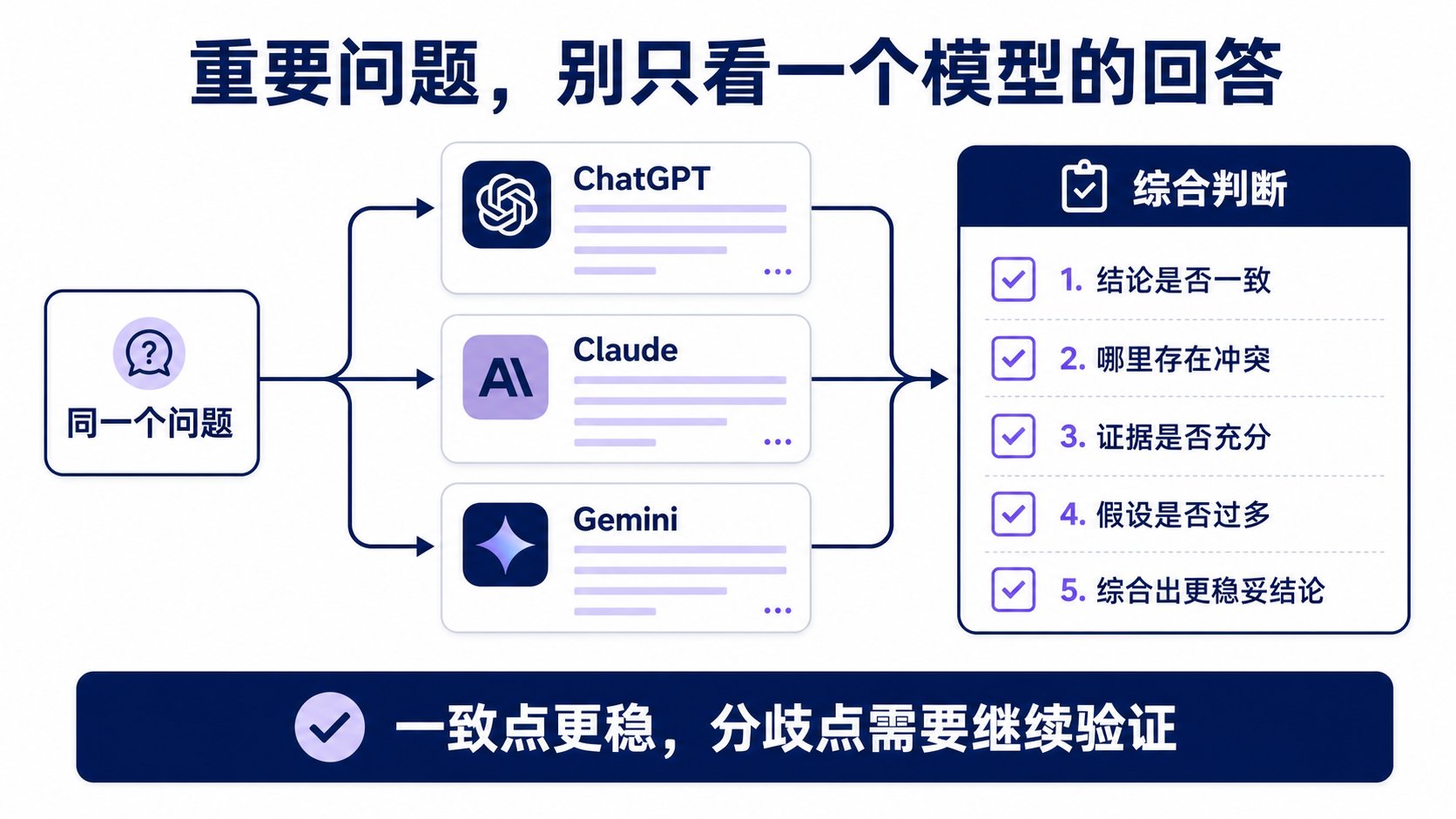
5|重要问题,跨模型对比
吴恩达这章最后一节是 AI Model Prompt Comparison——同一个问题,换不同模型问,结论可能不一样。
适合做模型对比的任务:
复杂解释 / 重要决策 / 写作方案 / 研究总结
操作方式很简单:把同一个问题分别问 ChatGPT、Claude、Gemini,然后把几个回答放在一起,让 AI 帮你比较:
我会把同一个问题的不同 AI 回答给你。
请分析:哪些结论一致、哪些地方冲突、哪个回答证据更充分、哪个假设更多。
最后综合出一个更稳妥的结论。
结论一致 → 相对更可靠。
分歧很大 → 这个问题本身需要更多信息和验证。
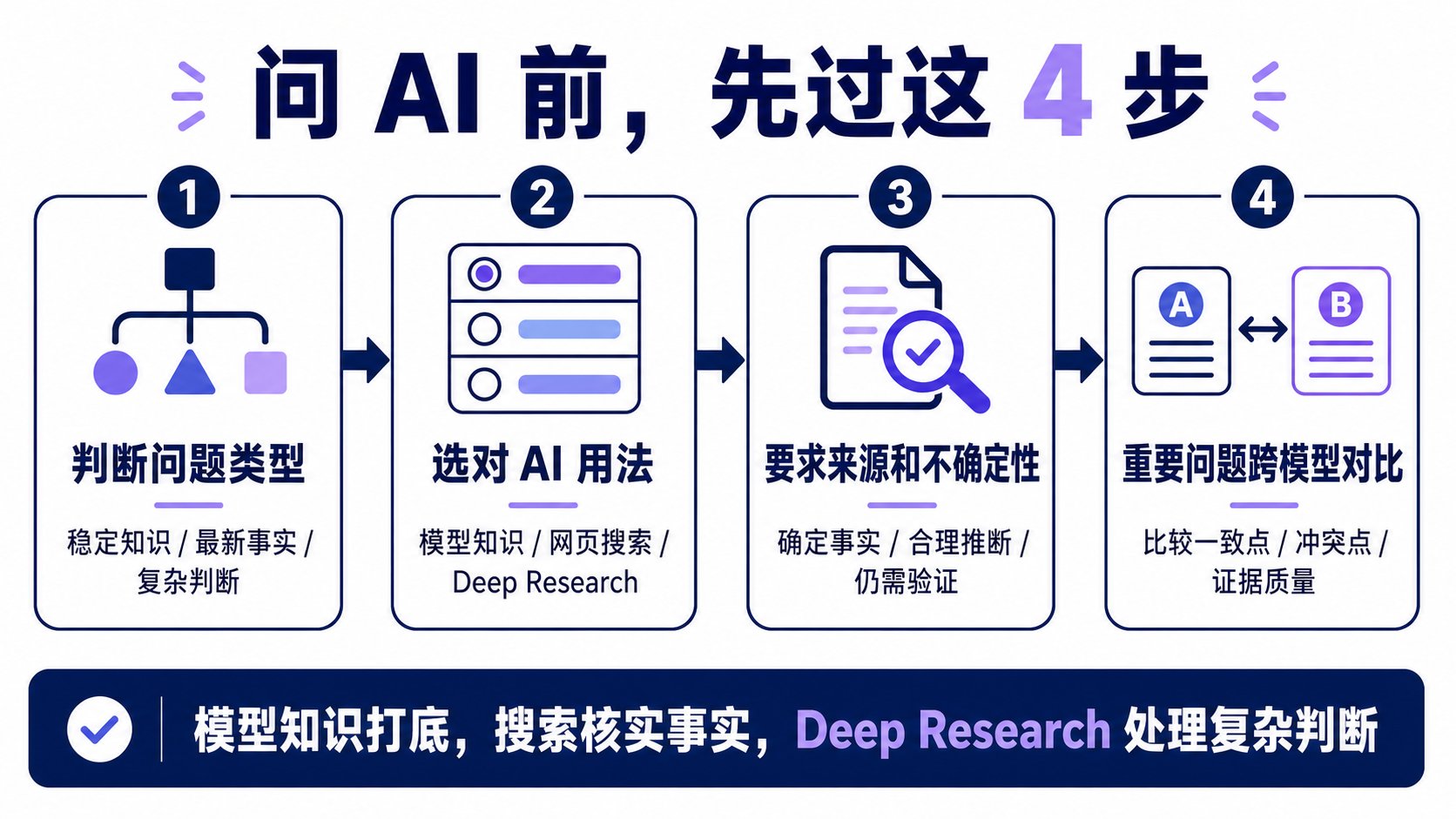
最后:普通人可直接用的 4 步流程
每次问 AI 之前,先过这 4 步:
① 判断问题类型
稳定知识 / 最新事实 / 复杂判断?
② 选对 AI 用法
稳定知识 → 模型已有知识
最新事实 → 网页搜索
复杂判断 → Deep Research
③ 要求来源和不确定性
让 AI 标注:确定事实 / 合理推断 / 仍需验证 / 每条结论的来源类型
④ 重要问题跨模型对比
2~3 个模型,比一致点和冲突点
这是吴恩达这门课第一章的核心逻辑。
用一句话总结:
模型知识打底,搜索核实事实,Deep Research 处理复杂判断。
2026 年问 AI,真正拉开差距的不是提示词写得多长,而是你知不知道这个答案应该从哪里来。