
一句话版本:Memory 和 Session 共享同一个上下文窗口,OpenClaw 在它们之间建了一条"生死通道"——Session 快死的时候,会把重要信息抢救到 Memory 里。
开场:你的 Agent 也"失忆"过吗?

明明昨天聊过的事,今天 Agent 却一脸茫然
"我们之前不是定好了方案 B 吗?" "抱歉,我没有关于这个决定的记录。"
这不是 bug,是所有 AI Agent 的结构性困境——Context Window 是有限的。对话越长,旧信息就会被挤出去。如果没有机制把重要内容"搬"到安全的地方,那些决策、教训、踩过的坑,就真的永远消失了。
OpenClaw 给这个问题设计了一条"生死通道"。
接下来我们拆解这条通道是怎么工作的。
先搞清两个概念:白板和日记本

在聊技术细节之前,我们先建立一个直觉:
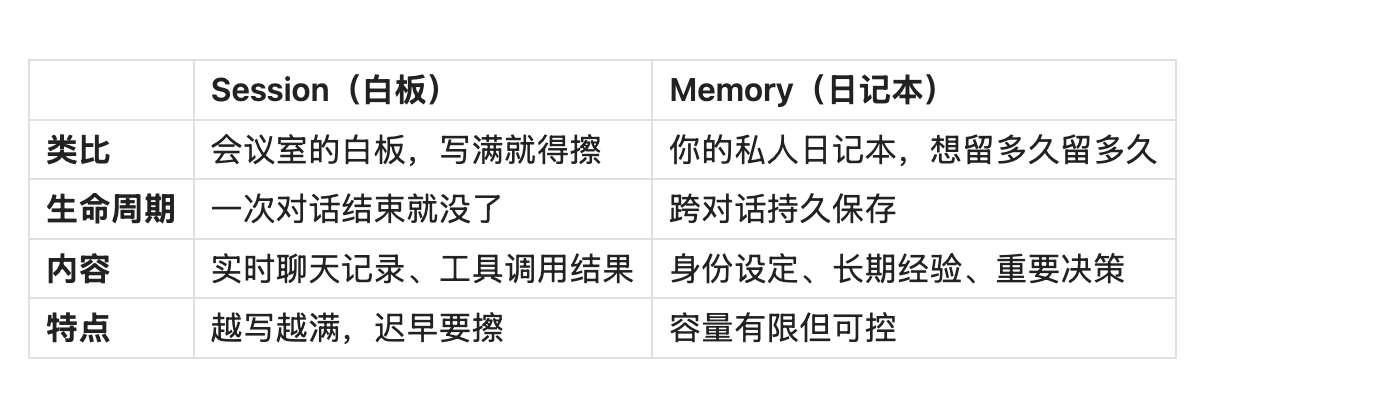
一句话:Session 管"我在做什么",Memory 管"我是谁"。
第一层:它们在抢同一块蛋糕

每次模型运行时,上下文窗口里塞的是这些东西:
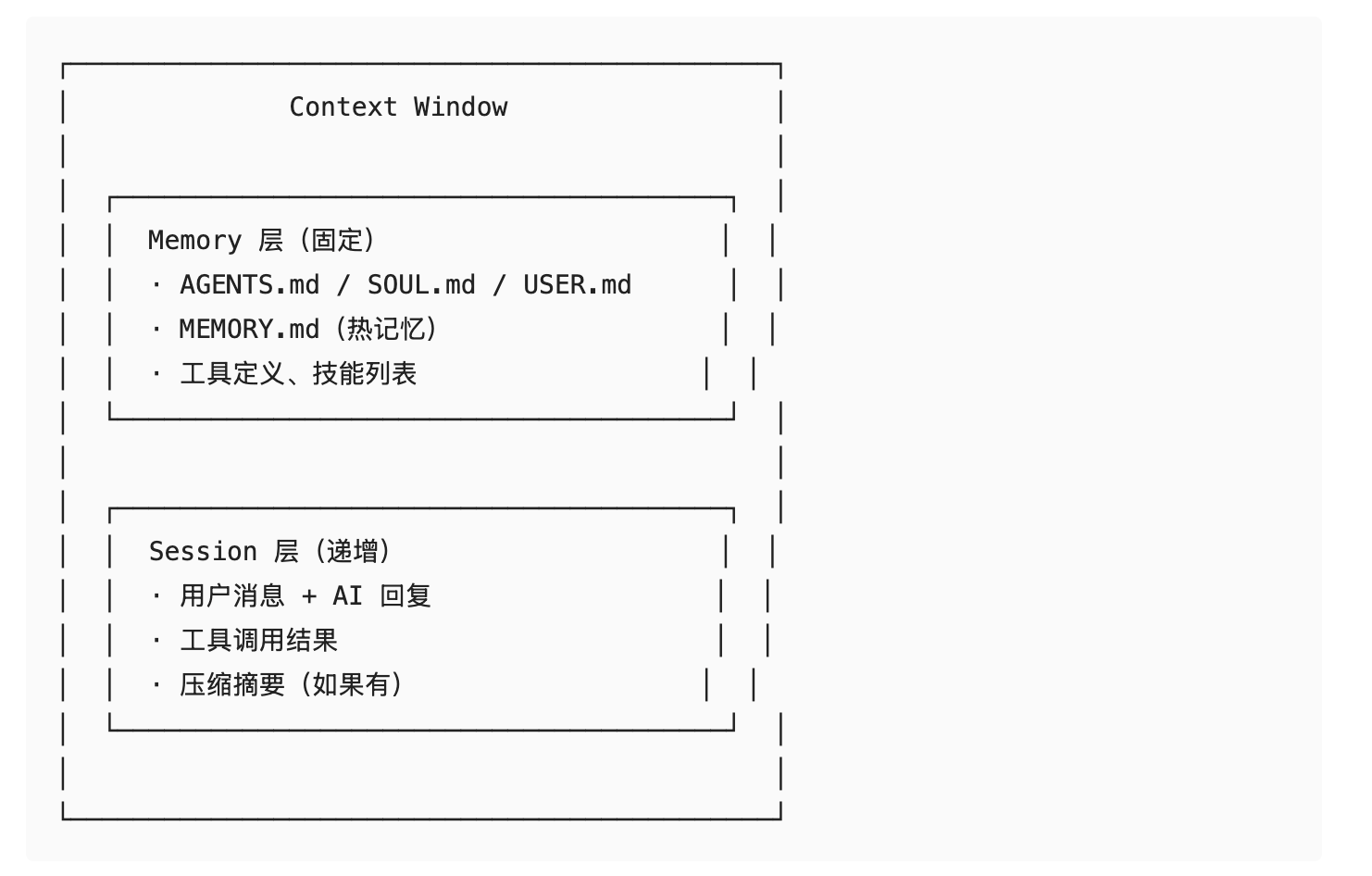
关键洞察:MEMORY.md 越大,留给对话的空间越小;对话越长,Memory 的影响力越被稀释。

用 ASCII 画出来更直观——随着对话进行,两者的占比变化:

Memory 是固定税——不管你聊不聊天,每次都要交。
Session 是递增税——越聊越多,直到塞满。
💡 实战启示:MEMORY.md 控制在 150 行以内。多一行就是每次对话都多交的"认知税"。超了就把旧内容归档到 memory/archive/。
第二层:生死通道(Memory Flush)

这是整个设计里最精彩的部分。
想象一下:你的白板快写满了,马上要被擦干净。这时候你会怎么做?——赶紧把重要的东西抄到日记本里。
OpenClaw 做的就是这件事,叫 Memory Flush。
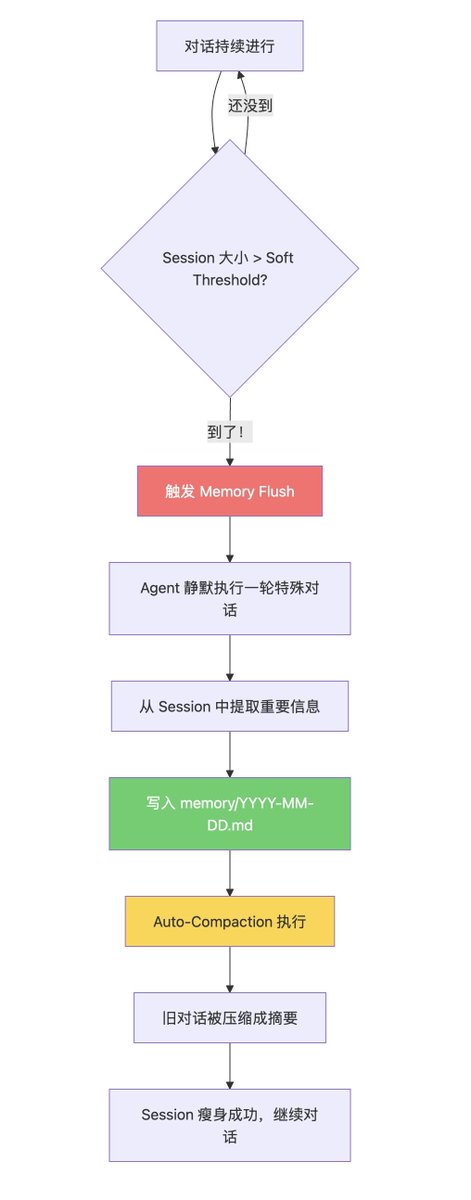
这里面有几个关键细节
1. Soft Threshold(软阈值)
不是等到窗口真的爆了才抢救——那就来不及了。OpenClaw 设了一个"软阈值",大概在窗口容量的 80% 左右触发。留出余量,让 Agent 有时间做"临终抢救"。
2. 静默的一轮对话
Memory Flush 对用户是无感的。Agent 会悄悄执行一轮内部对话,审视当前 Session 里的内容,判断哪些值得保留,然后写到文件里。
3. 然后才压缩
写完日记之后,Auto-Compaction 才会执行——把冗长的对话历史压缩成简短的摘要。压缩意味着细节丢失,但重要信息已经安全着陆了。
💡 实战启示:不要等系统帮你触发 Memory Flush。在完成一个阶段性任务后(写完文章、修完 bug),主动执行 /compact,让 Agent 自己决定哪些信息值得留下。这比被动触发的效果好得多。
第三层:信息的生命周期

信息不是静态的,它在 Session 和 Memory 之间有一条清晰的流动路径

这是一个循环:

- Session → 原始日志:对话中的信息先沉淀为当天的日志文件
- 原始日志 → 冷记忆:定期整理,把日志浓缩成月度归档
- 冷记忆 → 热记忆:最有价值的教训和决策,提炼进 MEMORY.md
- 热记忆 → 下一次 Session:MEMORY.md 在每次新对话时注入系统提示词
Session 是信息的入口,Memory 是信息的沉淀,而 Memory 又反哺下一次 Session。
用更生活化的比喻:这就像你每天经历很多事(Session),晚上写日记记录(日志),月底回顾日记做总结(冷记忆),年底从总结里提炼出人生经验(热记忆),然后这些经验又影响你明天的判断(注入新 Session)。
💡 实战启示:建立自己的"记忆整理节奏"。日常变更写 memory/YYYY-MM-DD.md,每周花一次时间把值得长期保留的内容提炼进 MEMORY.md。不要每天改 MEMORY.md——它每次对话都会被注入,频繁变更会破坏 prompt cache,浪费钱。
第四层:成本结构的隐形陷阱

很多人不注意这个:Memory 膨胀的隐性成本比 Session 更高
为什么?因为成本结构不同:

MEMORY.md 多 100 行 ≈ 每次对话多花约 400 token。听起来不多?如果你每天跑 50 次对话,那就是每天多花 2 万 token——而且这个成本是永久的,只要你不精简 MEMORY.md,它就一直在那里。
反过来,Session 的旧内容虽然也占空间,但可以被 Compaction 压缩或裁剪。它是"一次性"的成本。
这就引出一个反直觉的结论:Memory 虽然是"缓存友好"的(内容稳定,prompt cache 命中率高),但一旦膨胀,它的复利效应比 Session 更可怕。
💡 实战启示:定期给 MEMORY.md 做"体检"。问自己:这一行信息,值得每次对话都带上吗?如果不值得,就搬到 memory/archive/ 里。MEMORY.md 的黄金法则:≤ 150 行。
第五层:边界模糊化(实验性功能)

OpenClaw 还有一个实验功能叫 sessionMemory——它可以把 Session 的对话记录也纳入 memory_search 的索
这意味着什么?你可以用记忆搜索工具去搜索当前对话的历史内容。Session 和 Memory 之间的边界进一步模糊了。
这就像是给你的白板拍了照——白板虽然会被擦,但照片还在,你随时可以翻回去看。
💡 实战启示:如果你在用 OpenClaw 做需要频繁回溯上下文的工作(比如长期项目管理),可以考虑开启 sessionMemory。但要注意,这会增加索引的体积和搜索延迟。
总结:它们不是两个系统,是同一个系统的两个面
把全文串起来:
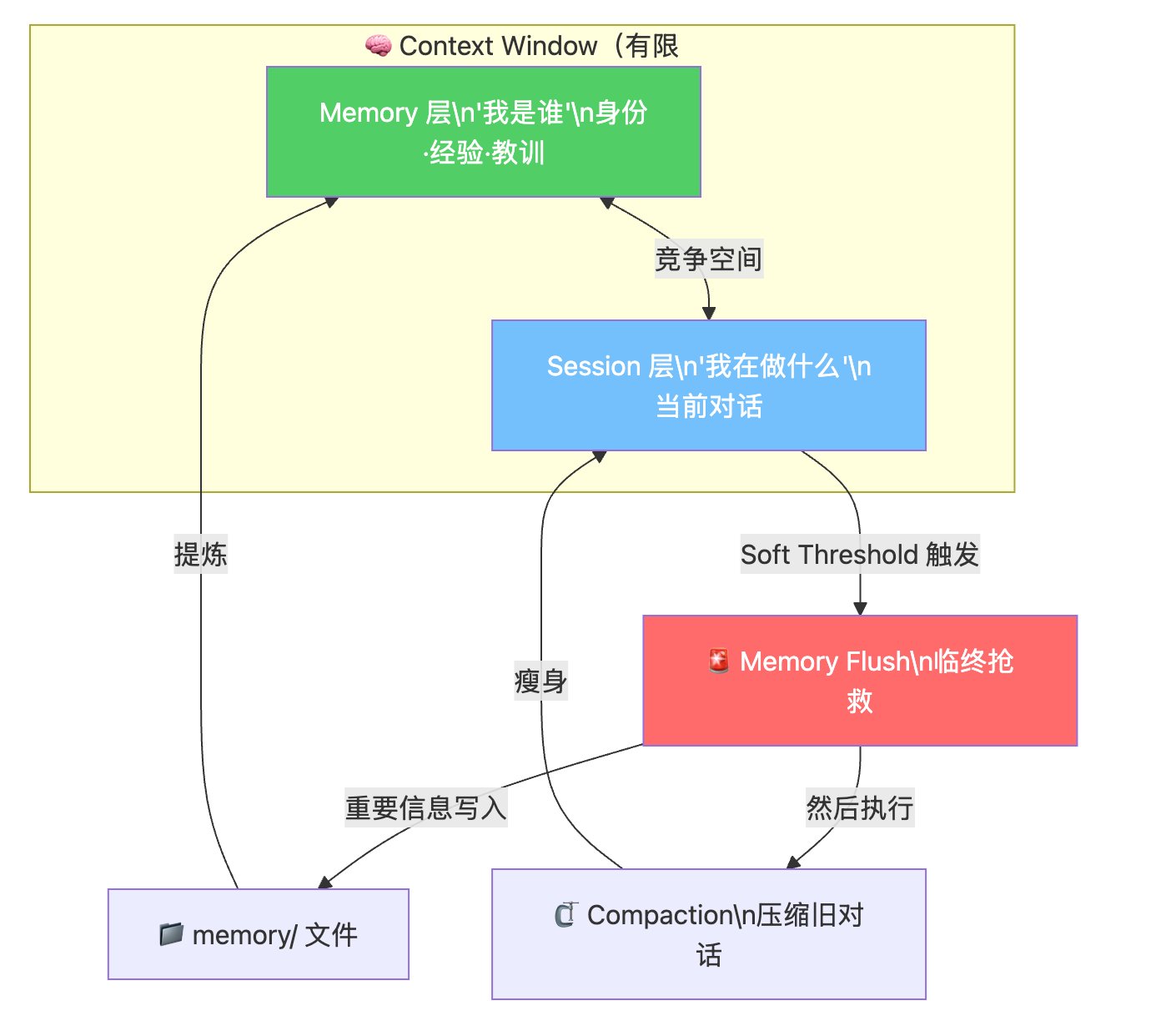
- Memory是"我是谁"——身份、经验、长期记忆
- Session是"我在做什么"——当前对话、实时上下文
- Memory Flush是它们之间的生命线——确保 Session 消亡时,重要信息能活下来
三个行动建议

如果你正在搭建或优化自己的 AI Agent,这三件事现在就可以做
- 🩺 给 Memory 做体检
打开你的 MEMORY.md(或等价的长期记忆文件),数一下行数。超过 150 行?马上精简。问自己每一行:**"这条信息值得每次对话都带上吗?"**不值得的就归档。
- 📊 建立分层记忆架构
别把所有信息都堆在一个文件里。建立三层结构:
- 热记忆(MEMORY.md):最核心的身份和经验,≤ 150 行
- 温记忆(memory/YYYY-MM-DD.md):日常日志,随用随查
- 冷记忆(memory/archive/):历史归档,需要时再翻
- 📈 监控 Context Window 使用率
养成习惯:在长对话中关注 Session 大小。完成阶段性任务后主动 compact,而不是等到系统强制触发。主动 compact 的好处是你可以在"头脑清醒"的时候让 Agent 自己判断哪些信息重要——被动触发时,Agent 已经在"喘气"了,抢救质量会下降。
好的记忆管理不是记住一切,而是知道什么值得被记住。