
你花了多少时间选 LLM?
GPT-4o、Claude、Gemini,文档翻了一遍,benchmark 比较过,价格算清楚了。
然后你的语音产品上线,第一个用户反馈是:说话慢一点,它才跟得上。
问题不在 LLM。从来不在。
NVIDIA 悄悄放出了一个模型:Nemotron-3.5-ASR。
600M 参数,40 种语言,纯 CPU 能跑,速度是官方 runtime 的 2.5 倍。
如果你做过实时语音产品,这几个数字会让你重新看一遍。
这不像一个工具发布。更像是有人把语音识别这件事,悄悄变成了基础设施。
它是什么
先说 ASR 是什么:Automatic Speech Recognition,就是"把人说的话转成文字"这件事。你对 Siri 说话、用讯飞语音打字、开会用飞书自动转录——背后都是 ASR 在工作。
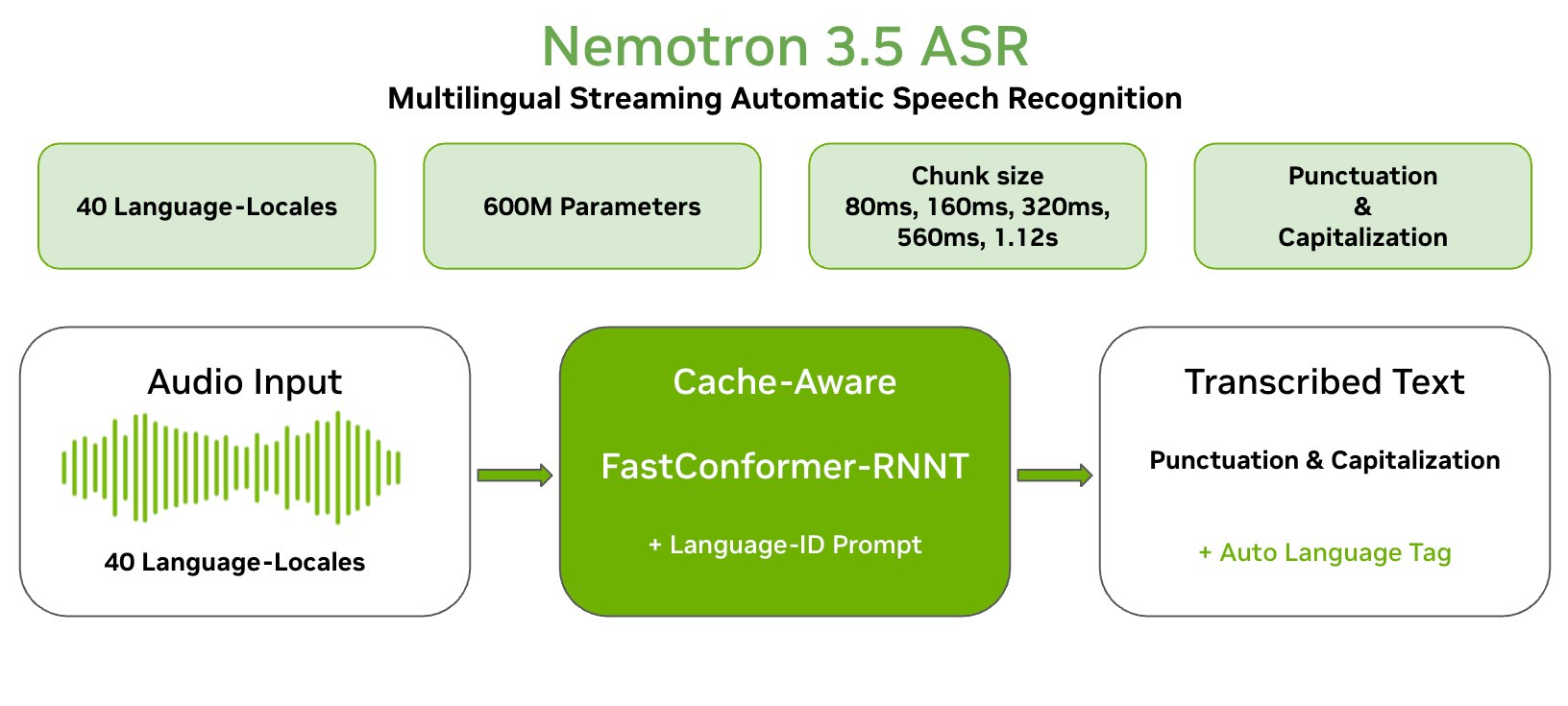
Nemotron-3.5-ASR 是 NVIDIA 发布的多语言流式语音识别模型。
核心参数:
- 600M 参数
- 支持 40 个语言区域(包括英语、中文、日语、西班牙语、法语、德语等主流语言)
- 原生流式识别,边说边转
- 自带标点和大小写,不需要后处理
- 支持自动语言检测,不用手动指定
- 延迟可以在 80ms 到 1.12s 之间调
- 开源权重,可自部署,可 fine-tune,可商用
它不是 Whisper 的替代品。定位完全不同。
以前做语音 AI,一般是这条链路:
人说话 → ASR 转文字 → LLM 理解 → TTS 说出来
这里最容易被忽略的一环,就是 ASR。
因为大家会觉得:"语音转文字嘛,Whisper 不就行了?"
但真做实时产品会发现,问题不在于"最后能不能转出来",而在于:
- 能不能边说边转?
- 能不能低延迟?
- 能不能多语言?
- 能不能本地跑?
- 能不能不用每分钟给 API 付钱?
- 能不能在很多并发用户下还稳定?
Nemotron-3.5-ASR 解决的就是这几个问题。
它为什么牛
第一:它是真流式,不是假流式
很多 ASR 的"流式",本质上是把音频切成一段一段,然后反复处理重叠窗口。
比如前 1 秒处理一次,后面再加 1 秒,又把前面的音频重新处理一遍。
这会浪费大量计算。人少的时候还行。一旦做成语音客服、会议助手、实时字幕、AI 电话助手,就会明显吃不消。
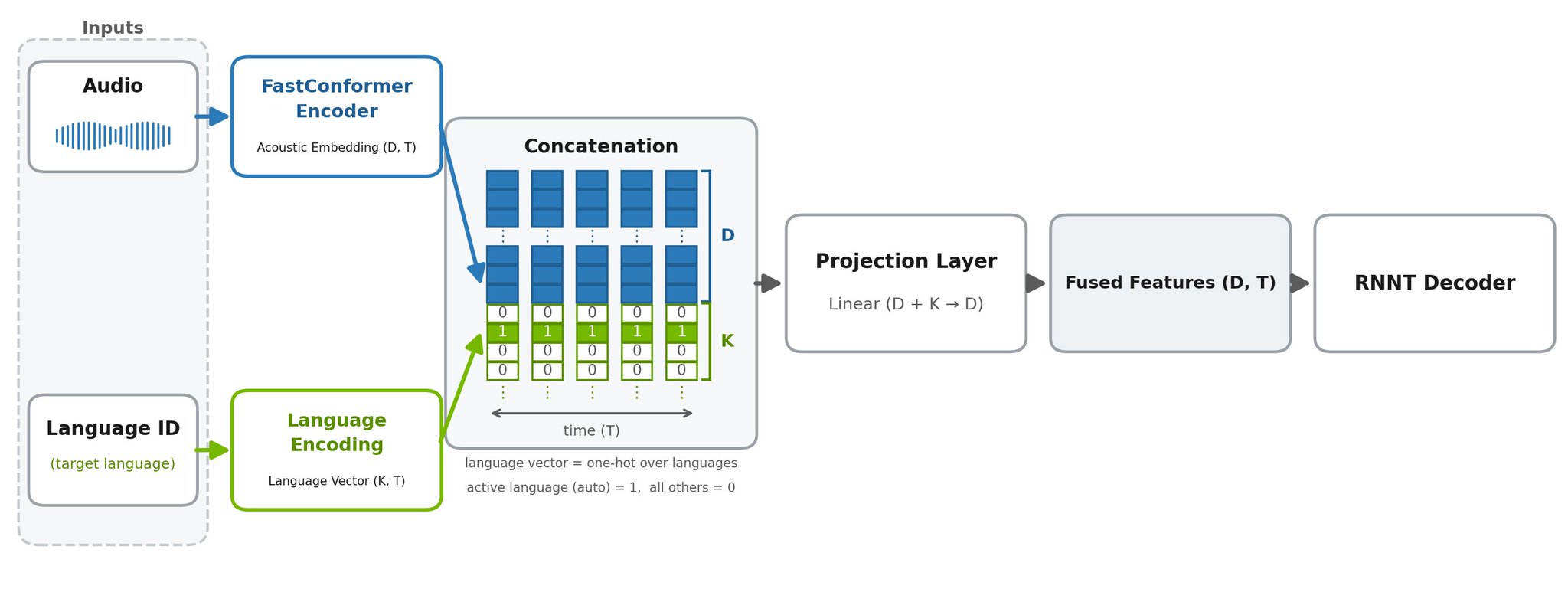
底层用了一个叫 Cache-Aware FastConformer-RNNT 的架构——名字复杂,原理不难理解:它会记住前面已经听过的音频状态,新音频进来时只处理新的部分,不反复计算旧的部分。
这对语音 Agent 非常关键。
因为语音 Agent 最怕的不是"最终转录结果不够准",而是:用户说完一句话,系统还在等。
实时交互里,200ms、500ms、1s 的差距,体感完全不一样。
第二:延迟可以自己调
它暴露了一个参数:att_context_size(注意上下文大小)
用它控制延迟和准确率的平衡:
配置 延迟 适合场景 [56,0] 80ms 实时语音 Agent [56,1] 160ms 语音助手 [56,3] 320ms 直播字幕、客服 [56,6] 560ms 会议纪要 [56,13] 1.12s 批量转录
第二个数字越大,延迟越高,但识别准确率通常更好。
重点是:不用重新训练模型。同一个 checkpoint,部署时根据场景调参数。
- 做 AI 电话客服,优先低延迟,选 160ms
- 做播客转录,优先准确率,选 1.12s
- 做会议纪要,选中间的 560ms
第三:一个模型支持多语言
一个 checkpoint 支持 40 个语言区域,可以指定语言,也可以直接设 target_lang=auto,让模型自动判断。
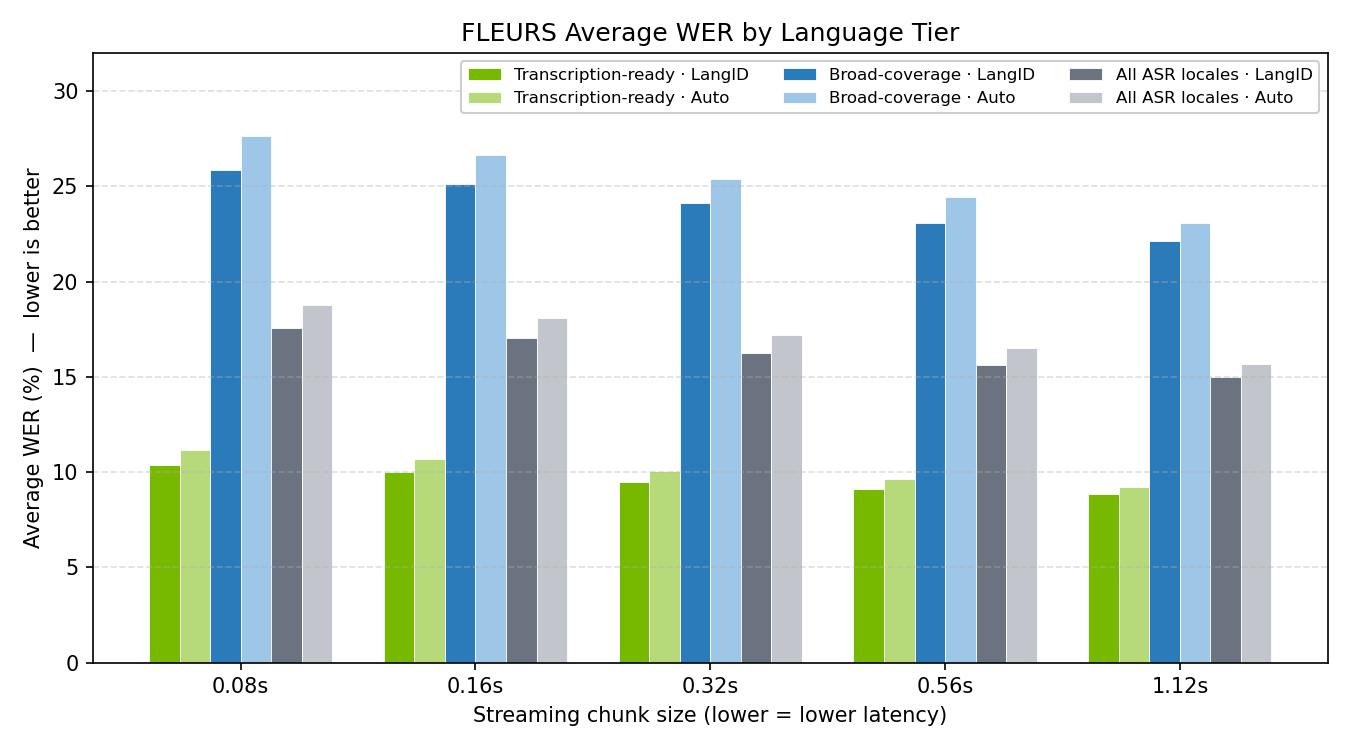
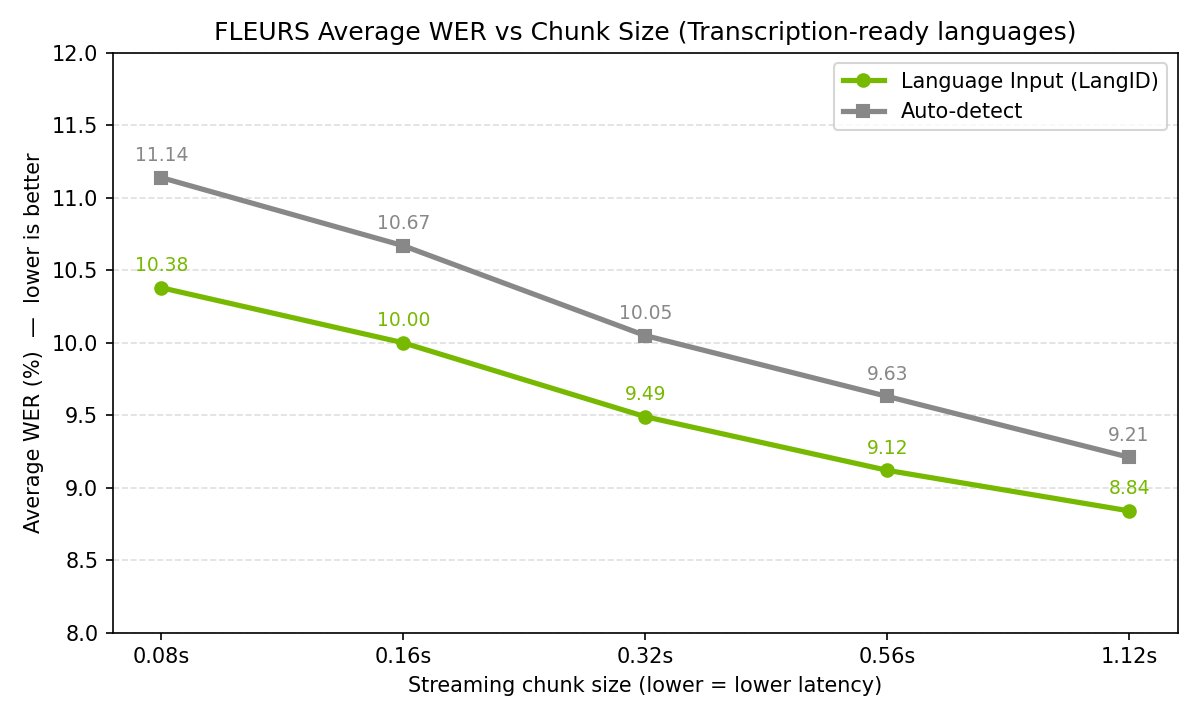
官方把语言分三档:
transcription-ready(开箱即用,准确率最高)
英语、西班牙语、法语、意大利语、葡萄牙语、德语、土耳其语、俄语、阿拉伯语、印地语、日语、韩语、越南语、乌克兰语等。
broad-coverage(能用,建议实测)
普通话 zh-CN、波兰语、瑞典语、捷克语、芬兰语、丹麦语、匈牙利语、罗马尼亚语等。
adaptation-ready(建议 fine-tune 后再用)
希腊语、希伯来语、泰语、立陶宛语、拉脱维亚语、马耳他语、斯洛文尼亚语等。
target_lang=auto 时,输出会在句子后加语言标签,比如 This is a test.
这对多语言客服、跨境会议、海外播客转录很有用——一边转录,一边知道这句话是什么语言,不需要再单独接一个语言检测模型。
第四:不只能在 H100 上跑
这是最容易被低估的地方。
Nemotron-3.5-ASR 只有 600M 参数,不是那种"论文很强,但普通开发者碰不到"的模型。
- 可以在云 GPU 上跑
- 可以在本地工作站跑
- 可以在 Mac(Apple Silicon)上跑
- 社区已经做了 4-bit / 8-bit 量化版本
未来很多语音 AI 产品,可能不需要把音频都发到云端 API。本地就能完成转录。对隐私、成本、延迟都很重要。
实际测试效果
先说结论:它最强的不是离线转录准确率碾压所有模型。
它最强的是:低延迟 + 流式 + 多语言 + 本地部署 + 可扩展。
测试一:并发流数 vs 延迟对比
官方数据对比 Nemotron-3.5-ASR 和 Parakeet RNNT 1.1B(同为 NVIDIA 出品)在同等硬件下的并发能力:
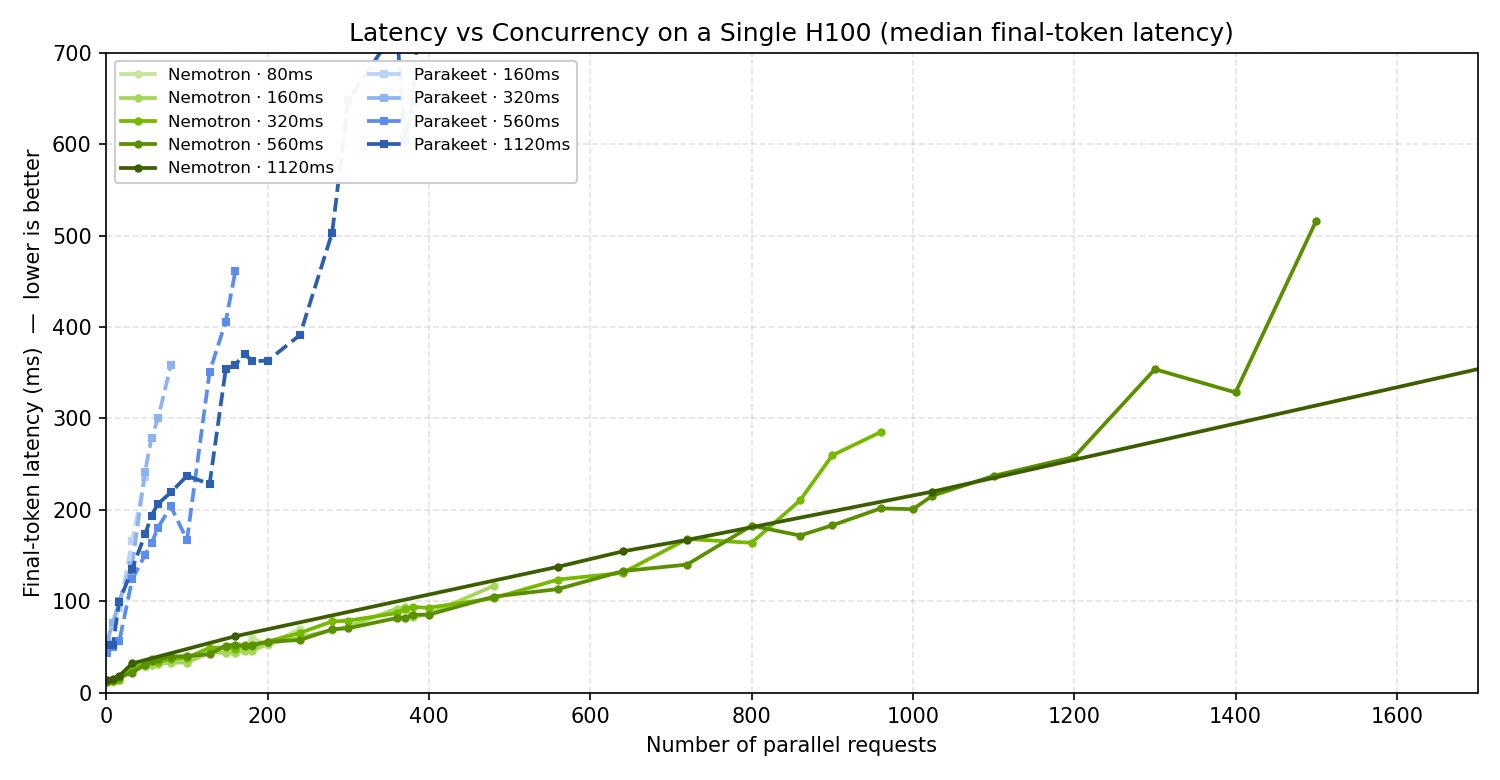
Nemotron 在 80ms 最低延迟设置下,并发流数是 Parakeet 的 17 倍(240 vs 14)。在 1.12s 设置下是 6 倍(2400 vs 400)。
参数只有对方 54%(0.6B vs 1.1B),并发却碾压——原因就是 cache-aware 架构消除了重复计算。
测试二:NVIDIA L4 上的 benchmark
有团队在 NVIDIA L4(23GB 显卡)上对比了 Whisper、Parakeet、Nemotron Speech。
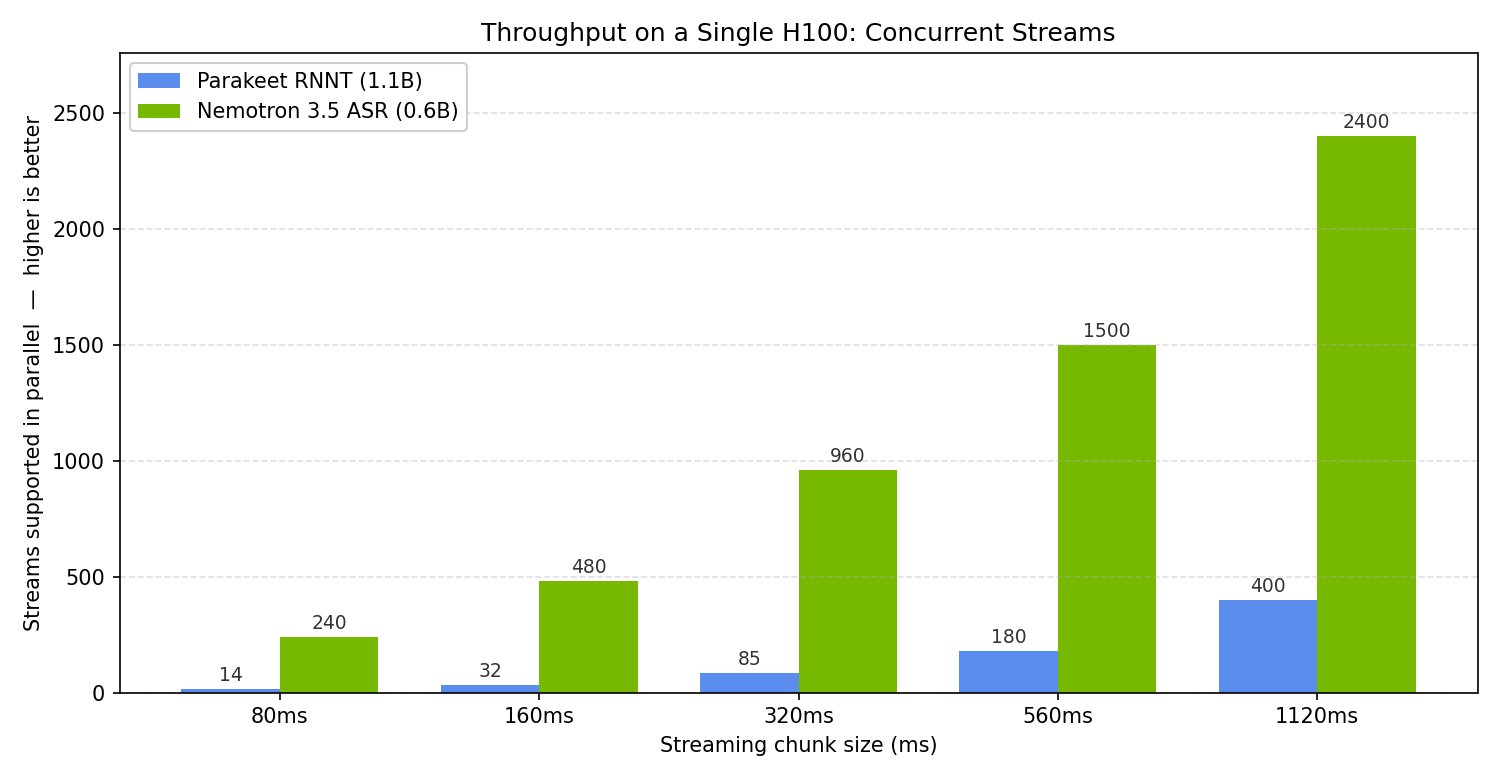
Nemotron 在 batch=8、frame=0.5s 的配置下,达到 258.9× real-time。
1 小时的音频,不是处理 1 小时,而是十几秒量级处理完。
同时显存占用只有约 2.8GB。这意味着在一张不算顶级的 L4 上,就可以跑相当高吞吐的转录任务。
daily.co 做了一个开源 语音 agent benchmark,对比了主流 ASR 模型的延迟和准确率:
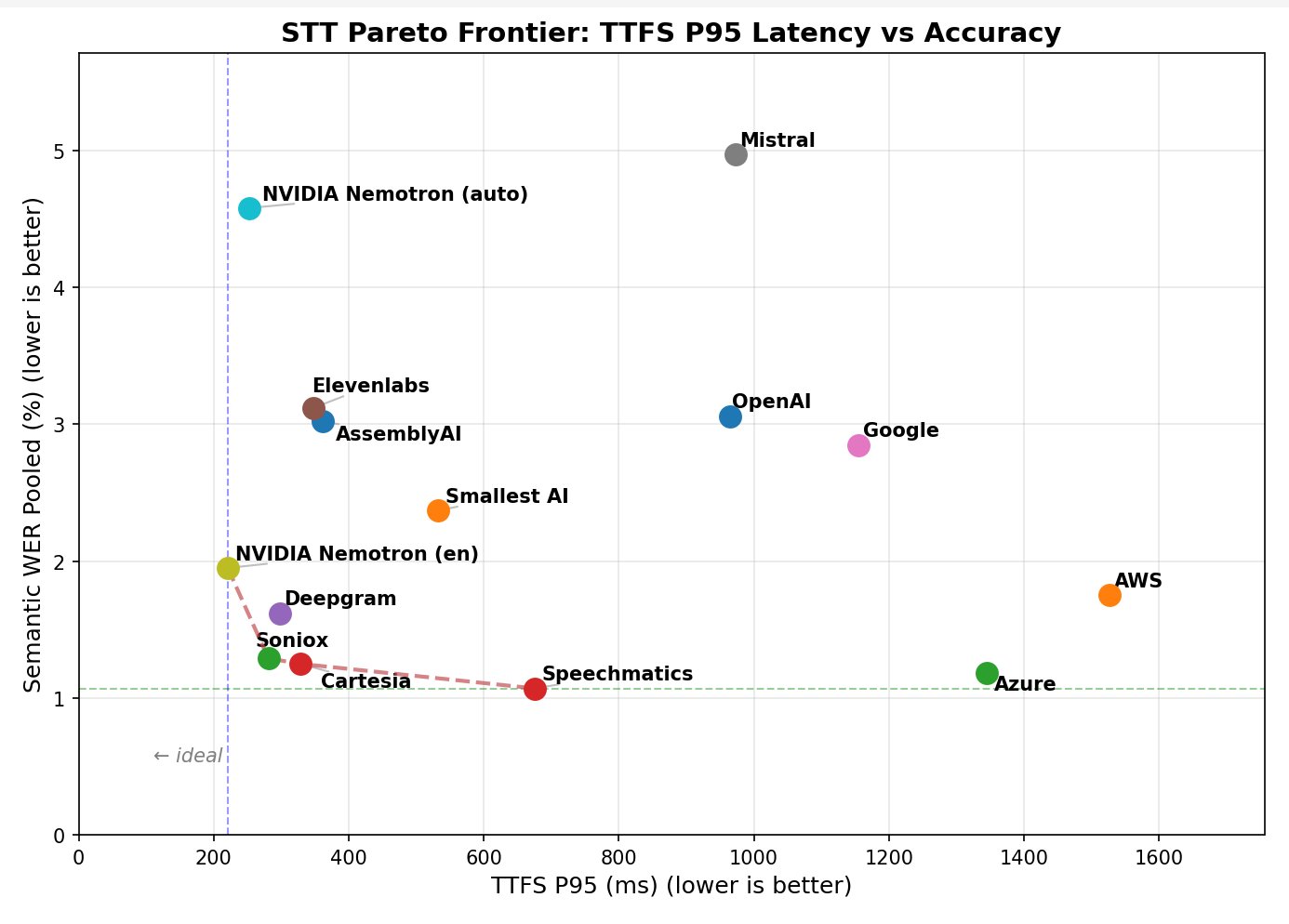
多语言版本是所有测试模型中延迟最低的,英文专用版本在延迟极低的同时准确率接近当前最强模型。
测试二:CPU 量化测试
有研究把 Nemotron Speech Streaming 做成 ONNX Runtime 版本并量化(ONNX 是一种通用模型格式,可以在没有 GPU 的环境里跑):
- int4 量化版本只有 0.67GB
- 平均 streaming 词错率约 8.20%
- CPU 上能超过 6× real-time(即 1 分钟音频不到 10 秒处理完)
- 算法延迟约 0.56s
这说明它有潜力成为真正的 on-device ASR:电脑本地跑、边缘设备跑、企业内网跑、不依赖云 API 跑。
测试三:Apple Silicon 社区测试

社区已有人把 Nemotron-3.5-ASR 移植到 Apple Silicon,使用 FLEURS 多语言样本测试。
结果:
- CoreML INT8 和 MLX bf16 在多个语言上接近 fp32 参考精度
- MLX 4-bit 版本体积更小,但准确率会明显下降
4-bit 不是免费午餐。它适合本地助手、提示型转录、边缘部署。但如果要做生产级会议转录,8-bit 或 bf16 更稳。
几个高频问题,集中说清楚
Q:有没有和 Whisper 的 benchmark 对比?
这个问题问歪了。它们解决的不是同一个问题。
Whisper 是离线转录:给它一段完整音频,它输出高精度文字。Nemotron-3.5-ASR 是原生流式,用于实时交互场景。
在同等延迟约束下比较,Nemotron 更有优势。在"给我最准的离线转录"这个任务上,拿它跟 Whisper large 比不公平。
选哪个,看你的场景:实时交互选 Nemotron,离线精度优先选 Whisper。
Q:和 Parakeet v2 比怎么样?
Parakeet 是 NVIDIA 的英文专用 ASR,单语言精度更高。
NVIDIA 自己也建议:如果只做英文,用 English-only 版本或 Parakeet。
Nemotron-3.5-ASR 的价值是多语言 + 流式,不要为了多语言功能去跟英文专用模型比英文精度。
Q:中文效果怎么样?
坦白说:目前不建议直接用于生产。
官方把普通话 zh-CN 列在"broad-coverage"档,不是最高的"transcription-ready"档,官方 benchmark 里也没有中文这一栏。已有用户实测,中文识别词错率偏高。
如果产品主要面向中文用户,建议先拿 30-100 段真实业务音频测词错率,再决定要不要 fine-tune,或者等后续版本。
Q:支持时间戳吗?
流式输出有 chunk 级别的时间对齐,但高精度 word-level 时间戳不是这个模型的设计重点。
需要精准时间戳(字幕校对、剪辑定位),Whisper 系列更合适。
Q:非英文语言质量有保障吗?
看语言。土耳其语有用户测了,说"以这个 size 来说还可以,但不算 production ready"。日语有用户在播客场景下测试,说效果出乎意料地好。
先测再决定,不要只看"40 种语言"就直接上。
Q:新语言能不能直接加进去?
有开发者发现,有些语言虽然有 prompt slot,但模型底层的字符表(tokenizer)不一定能很好覆盖对应文字。
"支持语言"和"生产可用"是两件事。希腊语和保加利亚语的案例里,fine-tune 后词错率有大幅下降。
这说明 Nemotron-3.5-ASR 真正的价值不只是开箱即用,而是:你可以拿它做自己的语音底座。
接进你的日常工具:飞书、Obsidian、Apple Notes
语音识别不是独立的工具,它最大的价值是接进你每天用的工作流里。
这里有几个真实可用的方案,不是概念,是有人已经跑通的。
场景一:飞书会议 → 自动会议纪要
飞书本身有"妙记"功能,但它是闭源 ASR,语言支持有限,而且音频上传到飞书服务器。
如果你想用 Nemotron-3.5-ASR 替换掉这个环节,思路是:
飞书会议录音 → 本地 Nemotron-3.5-ASR 转录 → LLM 提取决议和待办 → 写回飞书文档或通知
GitHub 上有个项目 feishu-lark-meeting-transcript,实现了:扫描飞书妙记 → 拉 transcript → Claude 整理成 HTML 笔记 → 飞书 IM 推送结果。把里面的 ASR 换成 Nemotron-3.5-ASR,就能实现完全本地化。
场景二:Apple Watch / 手机录音 → Obsidian + Apple Notes
有一个项目叫 watch-transcriber,实现了一条完整的语音笔记流水线:
Apple Watch 录音 → iCloud 同步到 Mac → 自动转录 → 结构化笔记 → 推送到 Obsidian / Apple Notes / 飞书
它的转录层目前用的是 Gemini Flash,但作者专门说明了这一层是可替换的:
"Transcription layer: Whisper, Qwen3-ASR, Nemotron, DouBao, AssemblyAI — just replace transcribe_and_summarize()"
也就是说把转录函数换成 Nemotron-3.5-ASR,剩下的飞书 / Obsidian / Apple Notes 投递层都是现成的。
输出端支持:
目标 说明 Apple Notes AppleScript 写入,免配置 Obsidian 提交到 GitHub 同步 Vault 飞书 通过 lark-cli 创建文档或发 IM 本地文件 Markdown 格式保存
场景三:全局语音输入,打字的地方都能说话
如果你不想搭流水线,只是想"说话代替打字",有个工具叫 Yaps,底层用本地 ASR,支持:
- 按快捷键,说话,文字出现在光标位置
- 支持 Mac 上所有 App,包括 Obsidian、Apple Notes、Notion
- Android 版也有,可以直接在手机 Obsidian 里语音输入
它现在用的是 Parakeet 引擎,但思路和 Nemotron-3.5-ASR 完全一致:本地跑,不联网,低延迟。
一句话总结: 飞书、Obsidian、Apple Notes 都有成熟的接入路径,Nemotron-3.5-ASR 适合放在流水线的转录环节,替换掉需要联网的 ASR API。
手机上能不能跑?
能。而且比你想的简单。
Android:下载 APK 就能用
sherpa-onnx 项目已经打包好了现成的 Android APK,直接装就能跑实时语音识别。
去这里下载:k2-fsa.github.io/sherpa/onnx/android/apk.html
搜索 nemotron-speech-streaming,选对应 ABI 版本(绝大部分 Android 手机选 arm64-v8a)。
比如:sherpa-onnx-1.12.40-arm64-v8a-asr-en-nemotron-speech-streaming-en-0.6b-560ms-int8-2026-04-25.apk
装上之后,直接对着麦克风说话,实时转录,离线运行,不联网。
如果你要把它集成进自己的 Android App,soniqo 已经做了专门的 Android SDK(speech-android),基于 ONNX Runtime,支持 INT8 量化版本,约 720MB。
iOS:社区已经跑通,但需要自己编译
社区有开发者做了一个 iOS PoC 项目,把 Nemotron-3.5-ASR 通过 CoreML 跑在真机上。
地址:github.com/lbj96347/nemotron-3.5-asr-ios
要求:
- iOS 17+
- iPhone 15 Pro 或更新(有 ANE 神经网络引擎,速度更快)
- Xcode 16+,需要自己 build
CoreML 模型文件用的是社区移植版本(FluidInference),支持 latin 和 multilingual 两套,iOS 17 目标已验证。
目前没有上架 App Store 的现成应用,还是开发者自测阶段。
一句话总结: Android 现在就能玩,装 APK 即可。iOS 需要自己跑代码,普通用户暂时还没有 App 可用。
什么人适合现在开始试
适合用:
- 在做实时语音 Agent 或语音助手
- 需要多语言支持,不想为每种语言维护一套 ASR
- 想把 ASR 放到本地或私有环境,不依赖闭源 API
- 预算有限,不想每个月付云 API 费
- 在做 edge device 或离线应用
不适合用:
- 只做英文,优先用 English-only Nemotron ASR 或 Parakeet
- 需要精准 word-level 时间戳,用 Whisper
- 中文为主,先等等或先 fine-tune
- 不想自己部署,直接用 OpenAI Whisper API 更省事
最小上手路径
别一上来就做复杂语音 Agent。
- 第一步:先用少量音频跑 streaming 模式,验证基本效果
- 第二步:试 att_context_size="[56,3]",这是最均衡的起点
- 第三步:比较 target_lang=auto 和指定语言的差异
- 第四步:拿真实业务音频测错误类型
- 第五步:如果错误集中在术语、口音、场景噪音,再考虑 fine-tune
环境:
git clone https://github.com/NVIDIA-NeMo/NeMo.git
manifest 是标准 NeMo JSONL 格式(每行一条音频):
{"audio_filepath": "/path/to/audio.wav", "duration": 4.27, "text": ""}
已知语言:
python ${NEMO_ROOT}/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=${MODEL_PATH} \
dataset_manifest=${MANIFEST_PATH} \
output_path=${OUTPUT_FOLDER} \
target_lang=zh-CN \
att_context_size="[56,3]" \
strip_lang_tags=true
不知道语言(自动检测):
python ${NEMO_ROOT}/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=${MODEL_PATH} \
dataset_manifest=${MANIFEST_PATH} \
output_path=${OUTPUT_FOLDER} \
target_lang=auto \
att_context_size="[56,3]" \
strip_lang_tags=false
判断值不值得用,看三个指标:转录准确率、用户感知延迟、单卡并发成本。
我的判断
语音 AI 接下来有一段时间,最值得押注的不是 LLM 变强,而是 ASR 变便宜、变快、变可控。
Nemotron-3.5-ASR 让我觉得这个时间点到了:600M、本地跑、80ms 延迟、40 语言,参数一调场景全换。两年前这个组合要么买不到,要么付不起。
我打算把它接进会议转录流水线,替换掉现在用的云端 API。中文先跑个 benchmark,效果差再 fine-tune。
你现在的 ASR 方案,最让你头疼的是哪一点?延迟、准确率、价格、语言支持、还是隐私?
模型地址:nvidia/nemotron-3.5-asr-streaming-0.6b · Hugging Face
Fine-tuning 指南:Fine-tuning Nemotron-3.5-ASR · NVIDIA Blog