
Codex + image-2 视频产出工作流分享:躺赚五位数
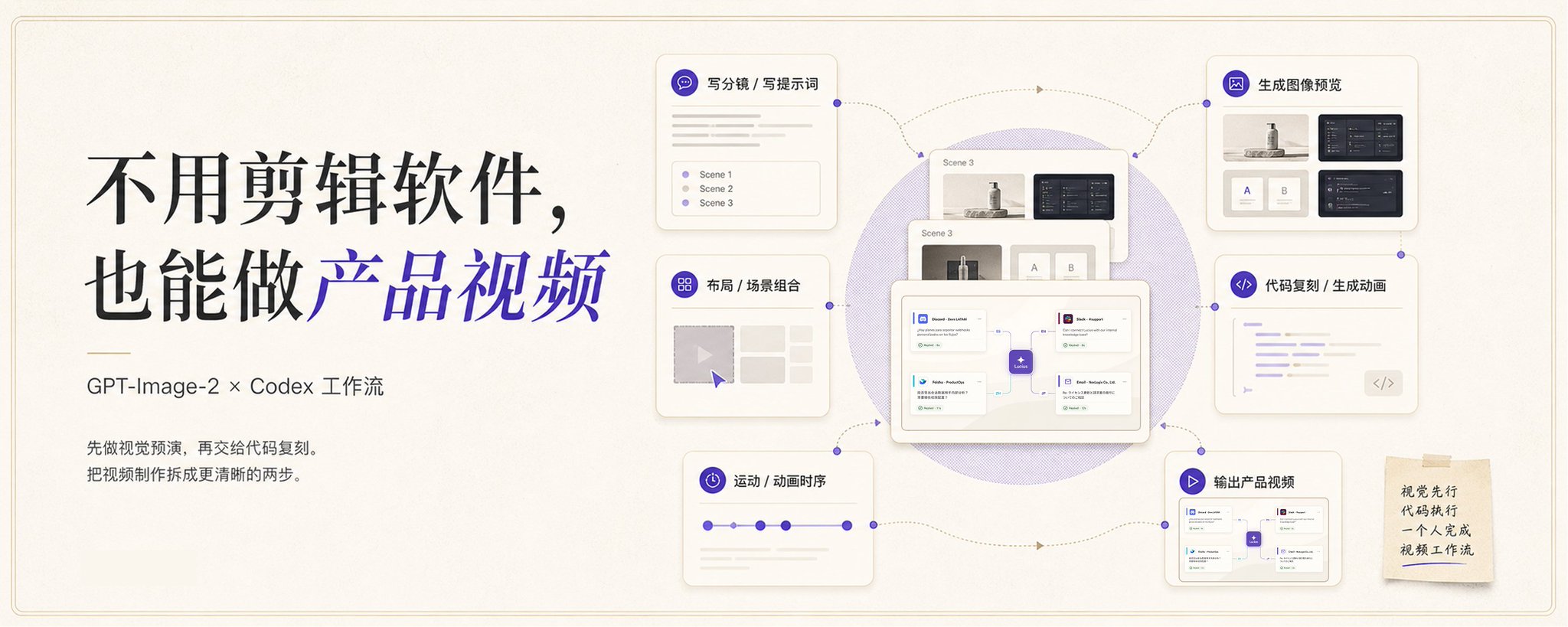
外包一个几十秒的产品视频要上万块,但我没打开任何剪辑软件,只用代码就把它跑出来了。
工作流的关键在于:先用 GPT-Image-2 把每个场景的视觉预演图出好,再把图交给 Codex 复刻成代码。
先看成品👇:

为什么要先出图
用 Codex 写界面,没有图,就像让人画画但不告诉他画什么:能动笔,但结果全靠运气。
做视频也一样。**「深色调、有科技感、简洁大气」**AI 能理解这些词,但落到实际画面,十次有七次不是你想要的。
所以,结合生图软件,先生成一张预览图,AI就有了可视化的参考,而且比起文字也更直观。
从「帮我做一个有科技感的场景」,变成「按照这张图的布局、颜色、层级,复刻成动画」。
视觉目标从模糊变成可执行。这一步,是整个工作流能跑通的原因。
Step 1:构思脚本和分镜
每个场景确认四件事:
- 画面里有什么(元素、位置、数字)
- 情绪基调(紧张感、讽刺感、转折感)
- 需要出现哪些文字和标注卡
- 动效的出现顺序
不需要任何工具,写文档就行。几个场景,就写几份分镜描述,这是之后所有东西的地基。
Step 2:用 GPT-Image-2 生成分镜预览图
每个场景写一份图片 Prompt,格式如下:
A [界面类型] in 16:9 landscape format, [色调].
[主要元素,精确到位置、层级、数字、颜色]
Floating annotation card · [位置] · semi-transparent dark background
+ white border · large: "[主标注]" / small: "[副标注]"
Overall tone: [情绪基调,如 clinical and quietly wasteful]
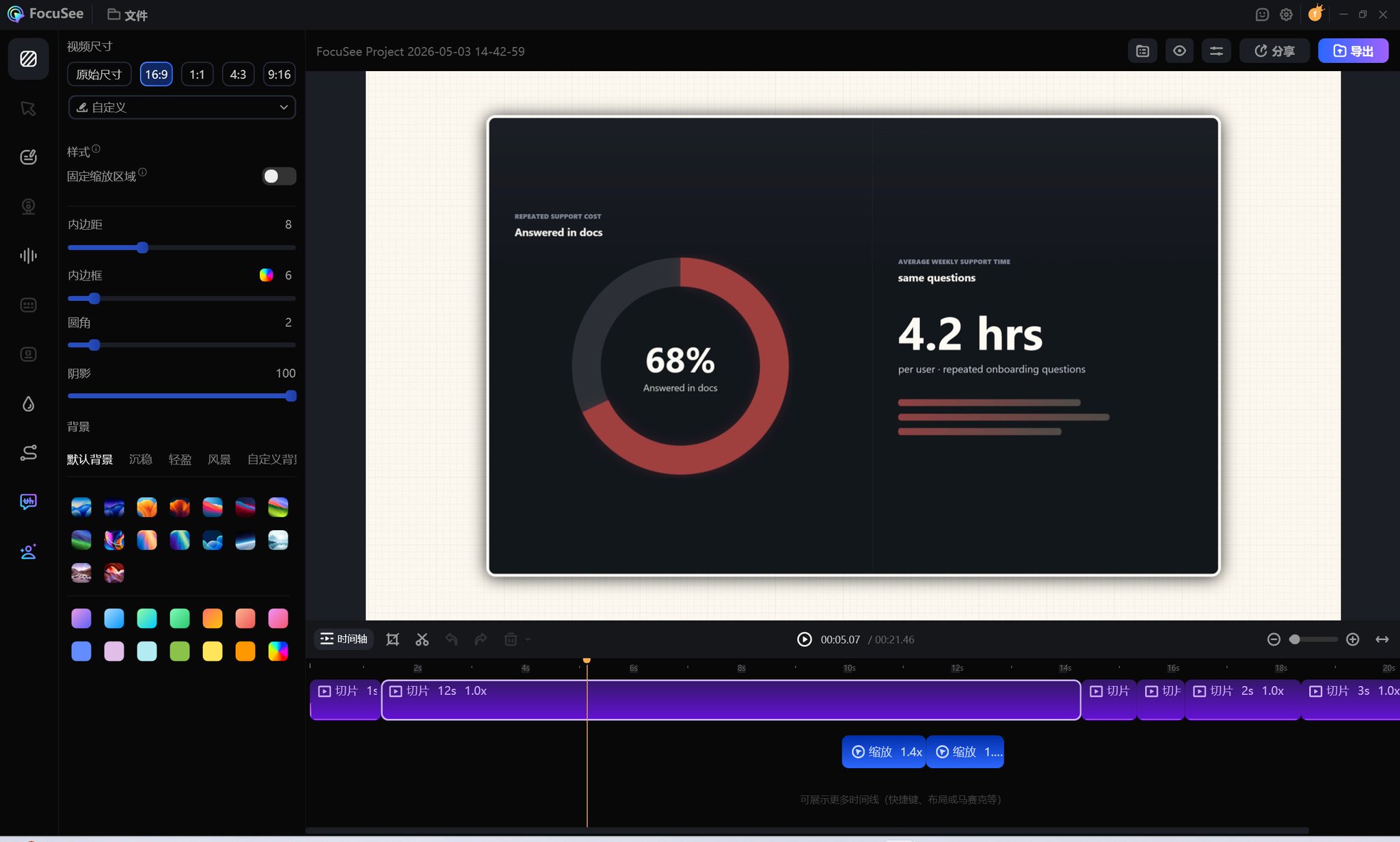
我实际用的 Prompt(数据看板场景):
A clean dark analytics dashboard in 16:9 landscape format.
Left: large donut chart, 68% muted red "Answered in docs", 32% dark gray.
Right: "4.2 hrs" in large white text,
label "avg. weekly support time per user · same questions".
Minimal grid lines, no decorative elements.
Floating annotation card lower-right · semi-transparent dark background
+ white border · large: "68%" / small: "of tickets · already in the docs".
Overall tone: clinical and quietly wasteful.
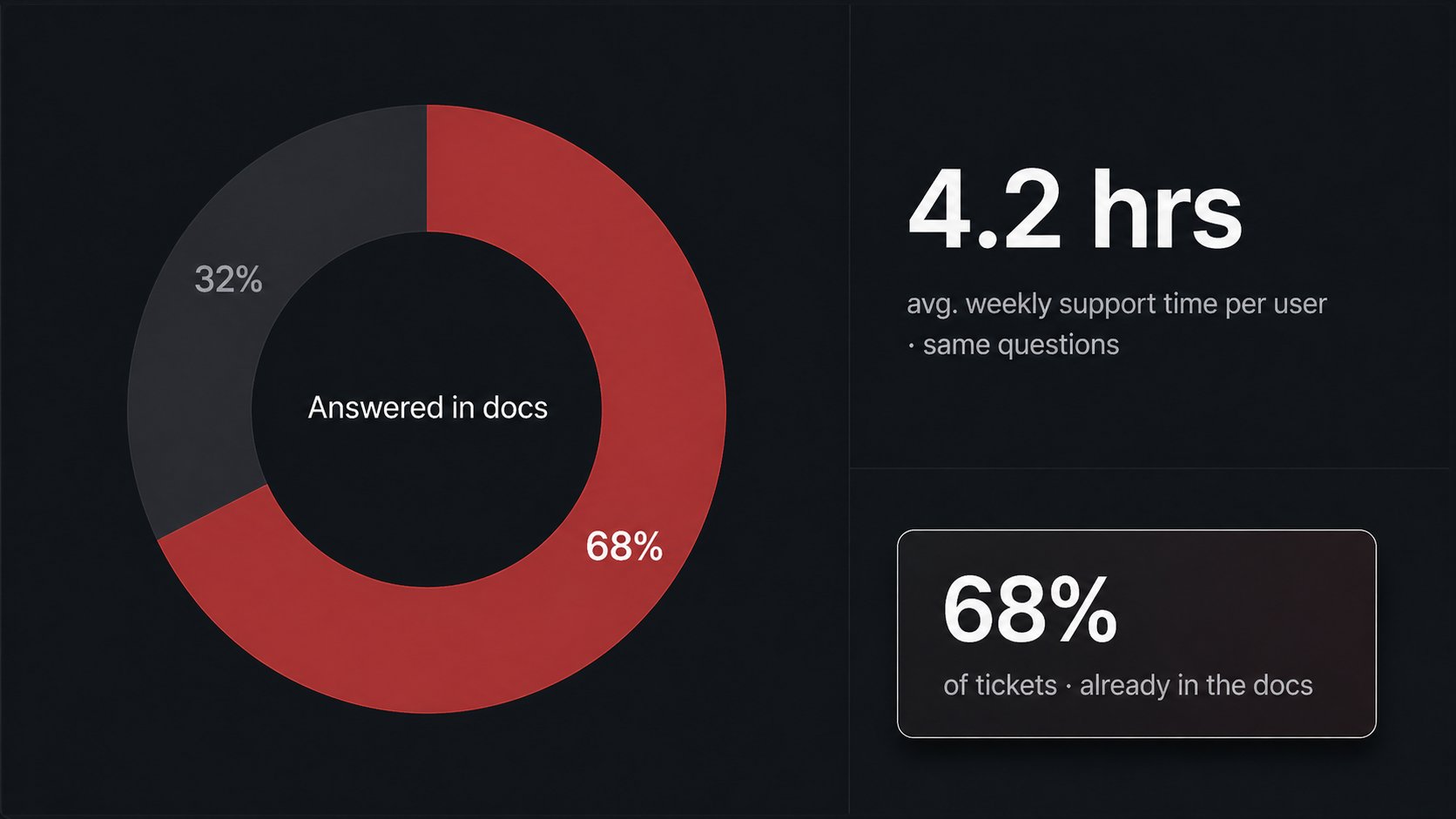
其他三个场景用同样格式出图。
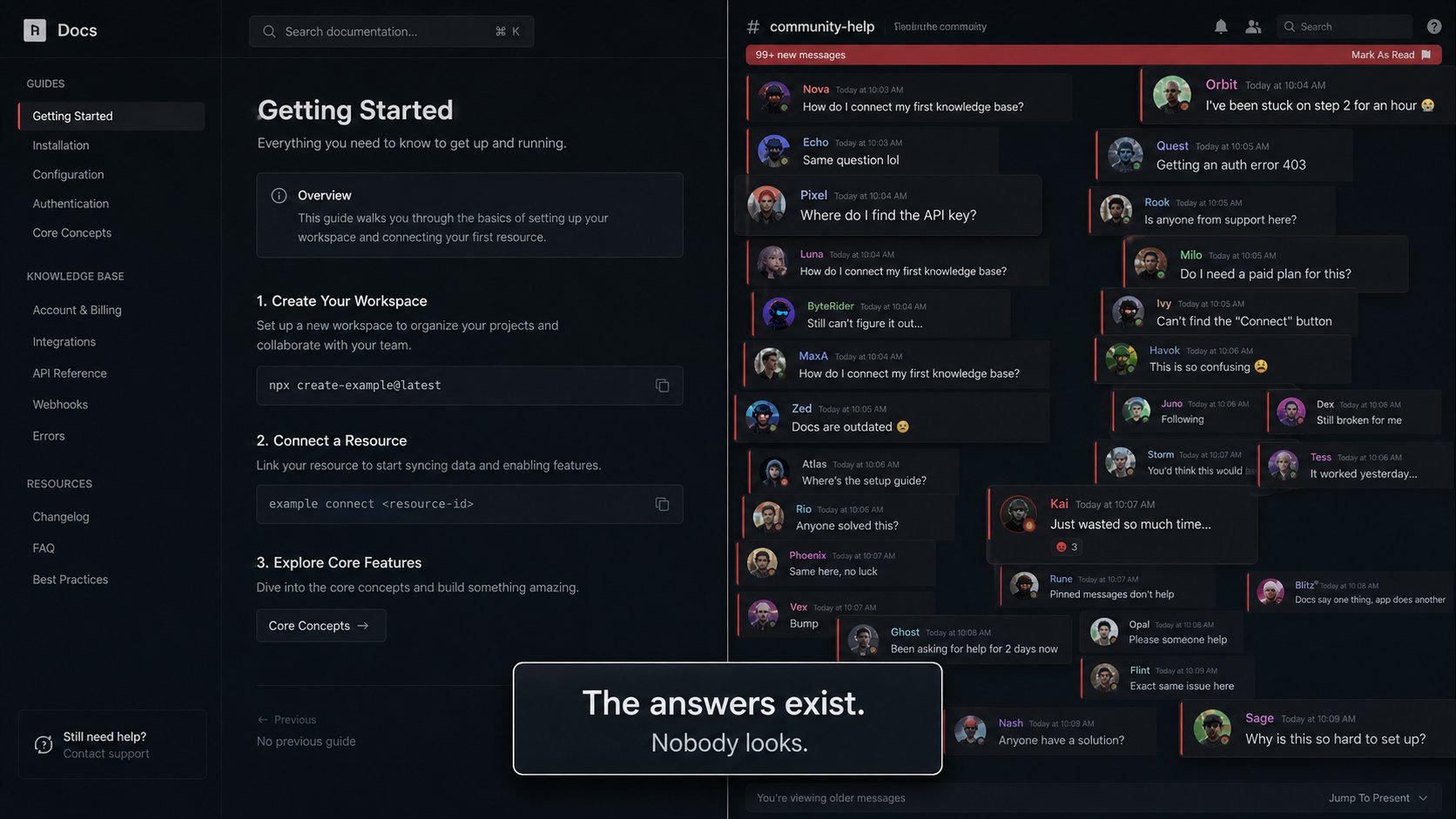
每张图只问一件事:这个视觉方向对不对?对了才进下一步。
数据看板和 UI 截图类场景适合「精确布局型 Prompt」(如上)。如果场景需要人物插图或背景纹理,则需要更换Prompt写法👇:
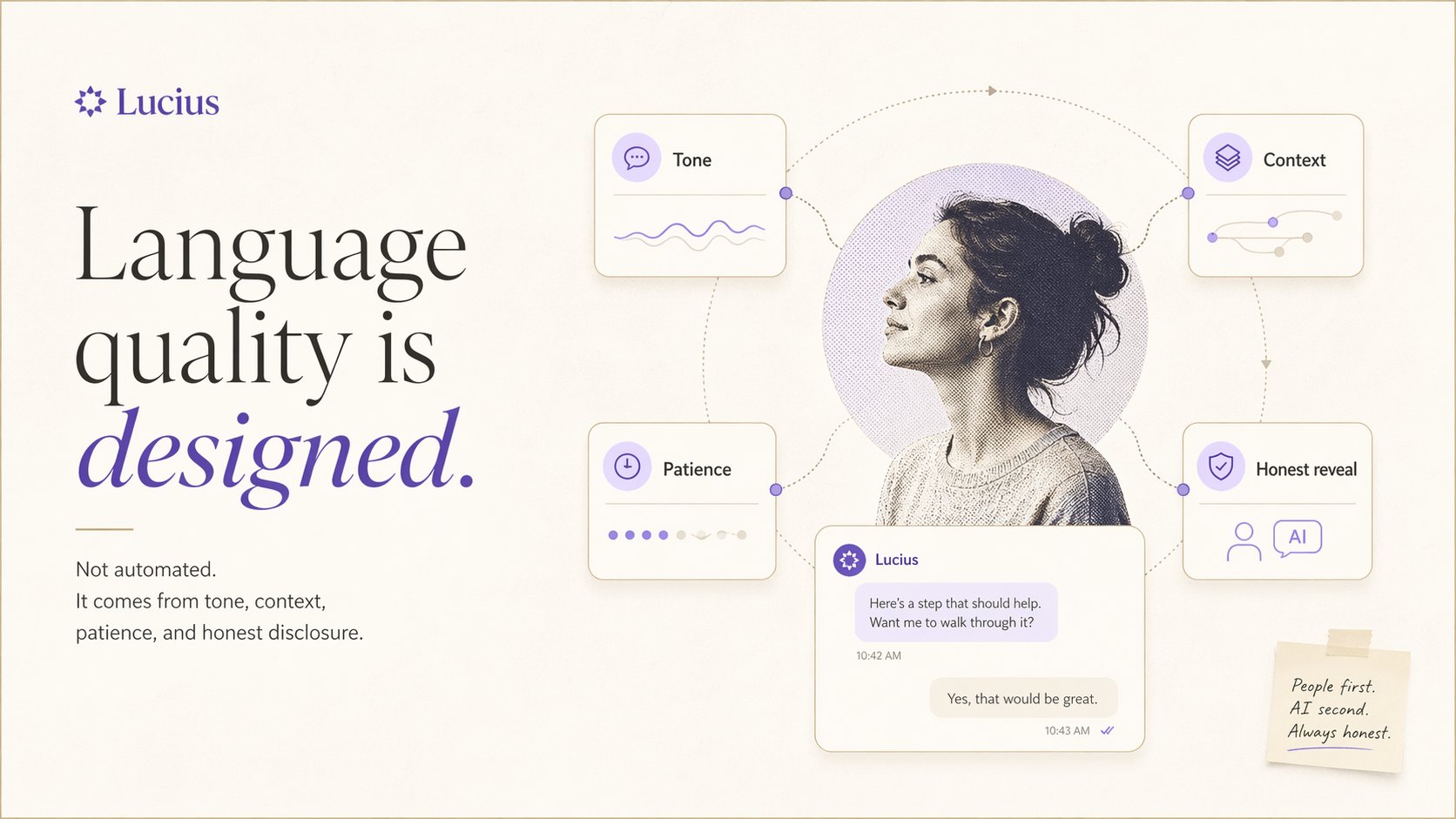
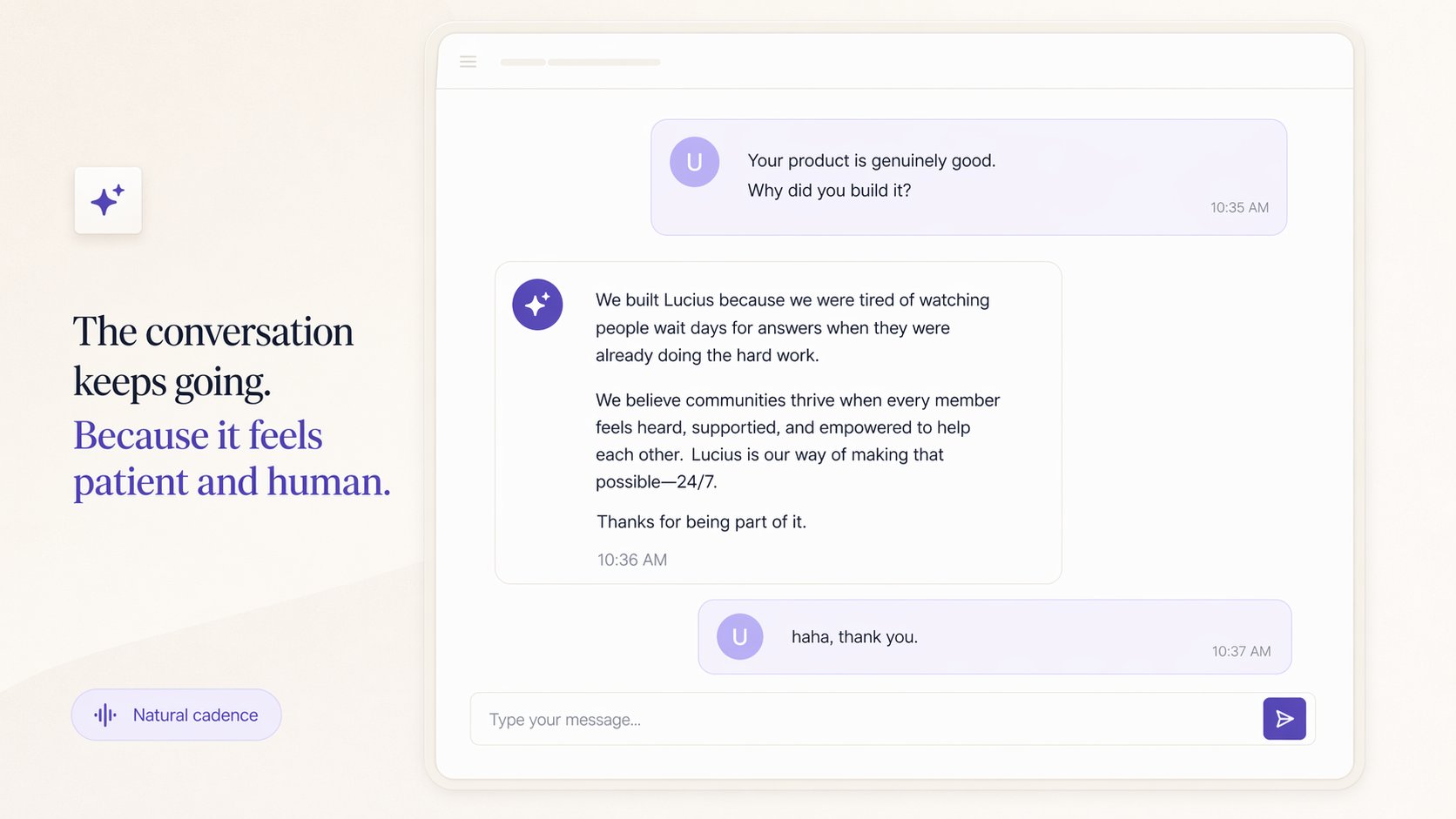
人物插图型(透明背景,叠在代码 UI 上方)
A [halftone / editorial illustration] character, [posture/expression].
Warm color palette: ivory, soft purple, warm white. Transparent background preferred.
No background objects, no text, no UI elements. Minimum 1024px tall.
Style: product editorial illustration, not photo-realistic.
Avoid: dark tones, heavy shadows, corporate clipart.
背景纹理型(铺在 UI 下层用)
A 16:9 paper grain background texture, [warm ivory / cool white].
Extremely subtle — this will be covered by UI layers above it.
No patterns, no icons, no text, no focal point.
1920×1080. Zero distracting elements.
原则:纹理和插图用生图解决,文字、数字、布局、动效全在代码里重建。各司其职。
Step 3:把预览图交给 Codex
给图之前,先把场景拆成两层:
- 代码层:文字、数字、卡片、气泡、按钮、所有动效——全在代码里重建,不依赖图片
- 图片层:背景纹理、人物插图——作为静态资源 import 进来,代码不负责生成
这层分工要写进 Codex 的 prompt 里:「文字和布局用代码实现,背景图我会手动 import,你不需要生成图片内容。」
严格按照我上传的这张预览图,复刻成一个 React 动画场景。
先不要写代码,先做三件事:
1. 分析图片的布局结构和视觉层级
2. 列出需要哪些主要组件
3. 确认动效执行顺序
然后:
- 先实现静态布局,还原颜色、字号、间距、圆角
- 再按以下动效顺序加入动画:[你在分镜里写的动效描述]
- 使用 [你的技术栈,如 React + Tailwind + CSS keyframes]
- 只做这一个场景,不要碰其他文件
「先分析,再写代码」这一句很重要。跳过它,Codex 会直接开写,容易写歪。
Step 4:对照预览图检查,逐场景微调
每个场景单独跑,对照原图。有偏差就说具体的:
「标注卡片出现得太早,改成主内容 fade-in 完成后再 slide-in」 「donut chart 颜色偏橙,改成#b44040」
越具体,Codex 越好改。说「再好看一点」只会让它加阴影和渐变,也可以让ai先去改进你的提示词,然后再正式提交。
Step 5:浏览器录屏,交付
四个场景全跑通之后,浏览器直接预览,系统自带录屏。
不需要 After Effects,不需要 Premiere,不需要任何视频软件。
美化一下然后配个bgm,就完成了。当然,为了让视频更好看,我选择使用@FocuSeeHQ
这个工作流适合谁
本文仅提供思路和逻辑演示,希望起到一个抛砖引玉的作用;
适合想做产品演示视频、工具教程视频,但没有视频制作背景的小白,你不需要懂剪辑,不需要懂动效工程。
你需要的是:知道每个场景要长什么样,然后用一张图把这件事说清楚。
先确认视觉,再执行工程。把两个判断拆开,效率会更高。
你试过类似的工作流吗?用什么工具,说一下效果。