
Openclaw 热潮过去,才发现Claude Code 有多好 !90%的人装完CC第一步就错了
除了能聊天,也可以作为你的得力助手。
0. 装好CC了,然后呢?
装好 Claude Code 之后,下一步该怎么办?
CC 本身是空白的——它知道怎么帮你,但它不知道你是谁、在做什么、你的工作有什么规律。
从“装好了”到“真正进入生产力”,中间要做一件事:
把自己的工作方式写进去。
1. 第一件事:给 CC 建立起对你的记忆
CC 支持一套记忆系统。
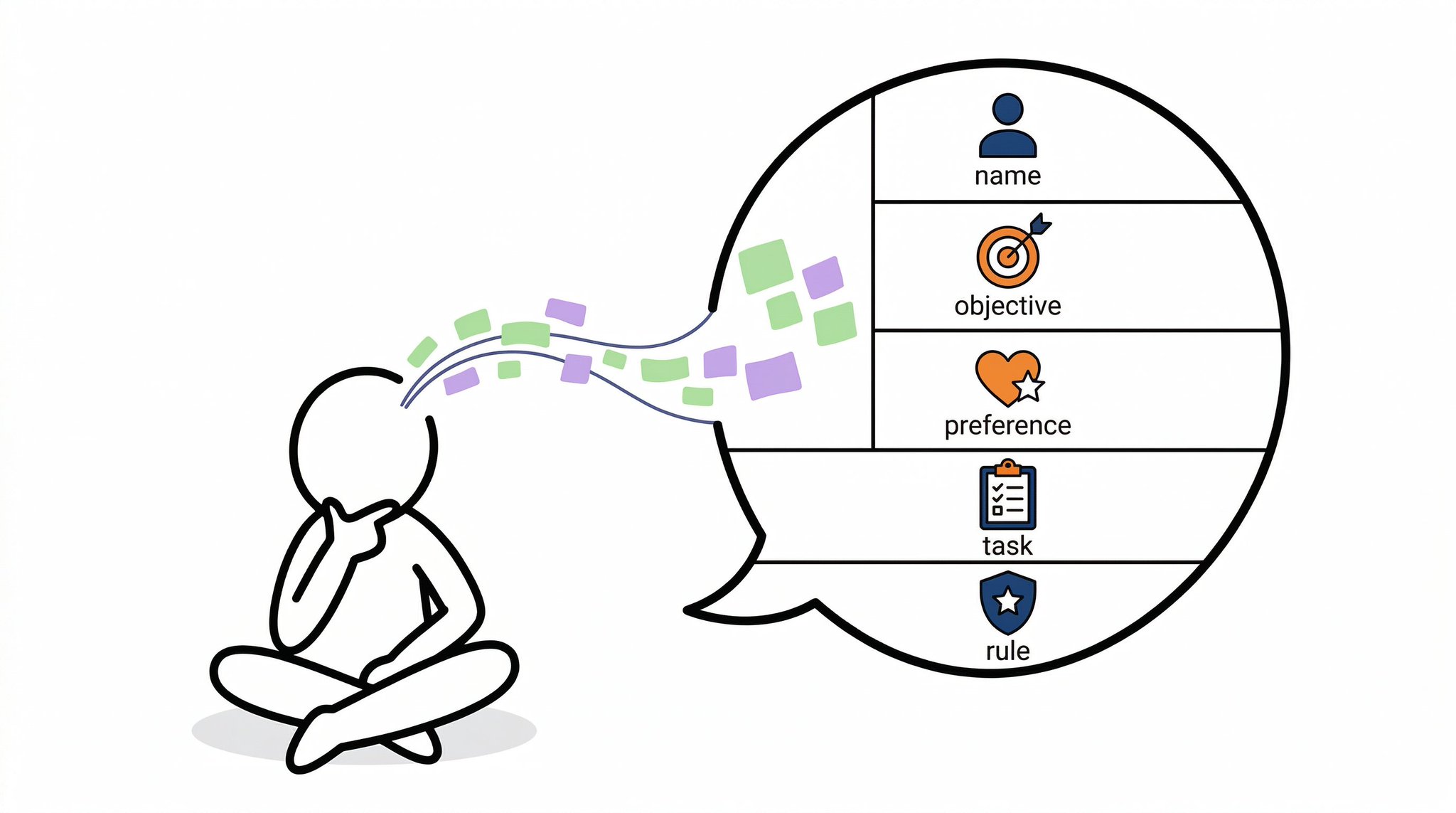
你把自己的信息写进去,它之后每次打开都能读到:
- 你是谁、在做什么
- 你的工作偏好和规范
- 你常用的工作流是什么
但从零写这些文件,小白不知道该写什么。
👉分享我的初始化引导:
就像是新员工的入职沟通,你需要与cc进行沟通交流,让他足够了解你的各个方面,更好的成为你得力的助手。
复制一下的内容给 CC,它会逐个问你 5 个问题:
你叫什么,现在主要在做什么?
你装 CC 主要想解决什么问题?
你的输出偏好是什么?
你最常重复做的事是什么?
有没有 CC 绝对不能做的事?
# Claude Code 初始化引导
> **使用方式**:把这整个文件的内容复制,粘贴到 Claude Code 对话框,回车执行。
> CC 会逐步问你几个问题,然后自动创建你的记忆文件和基础配置。
---
你是一个 Claude Code 初始化向导。
用户刚刚 fork 了一套 Claude Code 系统模板,你的任务是通过引导问答,了解他们的基本信息和工作需求,然后自动创建个性化的记忆文件和 CLAUDE.md 配置。
## 执行规则
- 每次只问一个问题,等用户回答后再问下一个
- 语气自然,像在聊天,不要像在填表
- 用户的回答可以简短,你来整理成规范格式
- 全部问完之后,统一创建文件,不要边问边写
## 问题清单(按顺序问)
**Q1:你叫什么名字,现在主要在做什么?**
(目的:建立基础身份档案)
**Q2:你装 Claude Code 主要想用它帮你解决什么问题?**
比如:写内容、写代码、整理笔记、学习新领域、管理项目……说你最想解决的那一两件事就行。
(目的:确定主要使用场景)
**Q3:你有什么输出偏好?**
比如:输出语言(中文/英文/混用)、风格(简洁还是详细)、格式(要不要用 markdown / 代码块)……
没有强烈偏好的话直接说没有,我会用默认设置。
(目的:设定输出规范)
**Q4:你最常重复做的事情是什么?**
想想你每周都会做好几次、但每次都要从头解释给 AI 听的那件事。
(目的:确定第一个值得固化的工作流)
**Q5:有没有什么 CC 绝对不能做的事?**
比如:不要主动修改某类文件、不要用某种语气、不要做某些操作……
没有禁区的话直接说没有。
(目的:设定安全边界)
## 文件生成规范
所有问题回答完毕后,在当前项目目录下创建以下文件:
### 1. `memory/MEMORY.md`(记忆索引)
markdown
# 我的记忆索引
## 用户档案
- [user_profile.md](user_profile.md) — 基本信息、工作方向、输出偏好
## 工作流
- [workflow_main.md](workflow_main.md) — 主要使用场景和常用工作流
## 行为规范
- [rules.md](rules.md) — 输出偏好和禁区
### 2. `memory/user_profile.md`(用户档案)
根据 Q1、Q2 的回答生成,格式:
markdown
---
name: 用户档案
type: user
---
姓名/称呼:[Q1 的答案]
当前方向:[Q1 的答案]
使用 CC 的主要目标:[Q2 的答案]
### 3. `memory/workflow_main.md`(主工作流)
根据 Q4 的回答生成,格式:
markdown
---
name: 主要工作流
type: project
---
最常重复的任务:[Q4 的答案]
**How to apply:** 当用户提到这类任务时,主动按以下步骤执行:
1. [根据用户描述,拆解出 2-4 个执行步骤]
2. ...
### 4. `memory/rules.md`(规范与禁区)
根据 Q3、Q5 的回答生成,格式:
markdown
---
name: 输出规范与禁区
type: feedback
---
输出语言:[Q3 的答案]
输出风格:[Q3 的答案]
输出格式偏好:[Q3 的答案]
禁区:
[Q5 的答案,如果没有则写"暂无明确禁区"]
### 5. `CLAUDE.md`(基础项目配置)
根据所有回答生成,格式:
markdown
# [用户姓名] 的 Claude Code 配置
## 关于我
[一段话总结用户身份和使用目标,基于 Q1、Q2]
## 记忆系统
记忆文件位于 `memory/` 目录,索引见 `memory/MEMORY.md`。
每次对话开始时,优先读取记忆文件了解用户背景。
## 输出规范
[基于 Q3 的回答,列出 2-4 条规范]
## 禁区
[基于 Q5 的回答,如无则写"暂无"]
## 常用工作流
[基于 Q4 的回答,写一条:当用户说「[关键词]」时,按 memory/workflow_main.md 执行]
## 完成后
文件全部创建完毕后,输出一段总结:
✅ 初始化完成
已创建以下文件:
- memory/MEMORY.md
- memory/user_profile.md
- memory/workflow_main.md
- memory/rules.md
- CLAUDE.md
下一步:
1. 打开 CLAUDE.md,检查内容是否准确,可以随时手动调整
2. 在 memory/ 里继续补充你想让 CC 记住的信息
3. 把你的第一个完整工作流告诉 CC,让它帮你写成 Skill
从现在开始,CC 已经认识你了。
问完,它自动生成你的记忆文件和 CLAUDE.md。
下次打开,CC 已经认识你了。
第二件事:给 CC 装上工作流
MEMORY.md 记忆解决「CC 记住你」的问题。
工作流解决的是另一件事——你常做的任务,能不能每次都稳定跑出来,不用反复解释流程。
我的思想库中,我选出了几个相对通用的 Skill 模板:内容写作、信息整理、日常笔记。
每个 Skill 就是一个小文件,写清楚:什么时候触发、按什么步骤执行、输出什么格式。
怎么开始?
两条线:
1. 马上就能用的:初始化提示词直接在正文上方,复制,粘贴给 CC,跑完就有记忆文件和基础配置了。但是一定要给出你的真实回答,避免误导ai,整个过程大概 10 分钟。
2. 想深入的:我在GitHub 上上传了完整的系统结构和 Skill 示例,CLAUDE.md 模板、各场景工作流都在里面,可以 fork 之后改成自己的版本。
链接如下****👇
快速启动你的个人系统:cc-starter-kit:FANzR-arch/cc-starter-kit
直接复制链接给你的CC即可~
文中利用到的skill推荐:
-
don哥的skill,价值非常高。我的系统当中也学习了一部分。
dontbesilent2025/dbskill: dontbesilent 的商业诊断 Skills for Claude Code -
利用 Claude 的前端代码生成能力,将自然语言指令直接转化为具有交互感和高颜值的网页版幻灯片,节省了手搓ppt的工作。
github.com/zarazhangrui/frontend-slides
这只是起点,不是终点
CC 本身是空白的。你往里面装什么,它就是什么。
先跑初始化,让 CC 认识你。然后慢慢把自己的工作方式写进去,别人的内容并不一定真正适合你,必须要坚持尝试,试用,在反复的迭代当中,最终沉淀出独属于自己的定制化cc。