
企业必看:80 种省 token 的方法,让你用 AI 更省钱!

这期的教程是以 Claude Code 为例讲的,但对其他 agent 产品也适用。
💡 提示:不会安装和配置 Claude Code 的同学移步:【链接在下方】
下面讲如何使用 Claude Code 更省 token。

1. 退订

很多人缓解 AI 焦虑的方式是订阅一堆自己从来不用的 AI 产品,以让自己看起来像是跟上了 AI 时代。从源头切断,退订所有你还不知道怎么用的 AI 产品。
2. 配好环境再开干
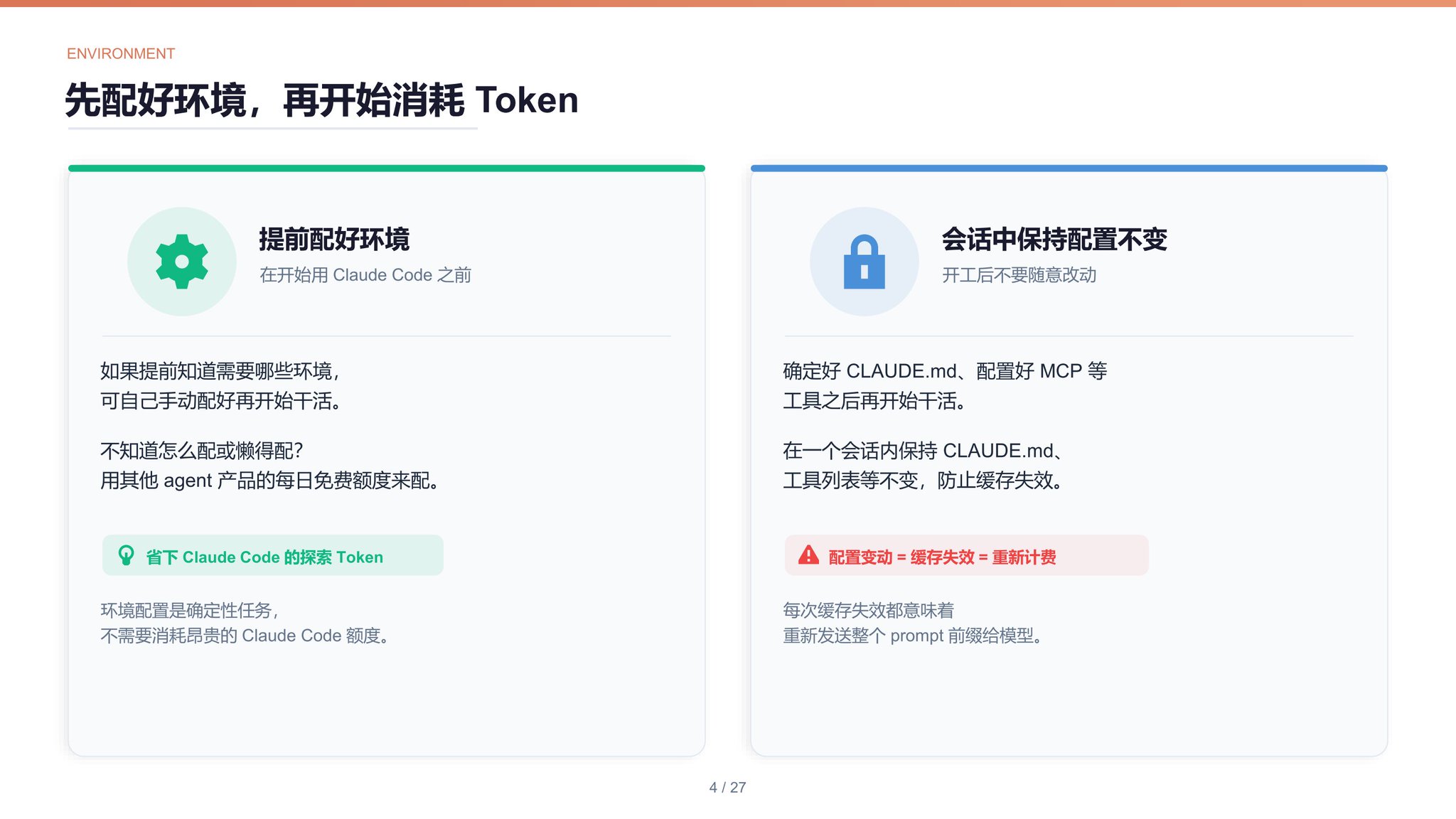
提前配好环境如果能提前知道自己需要哪些环境,可自己手动配好再开始用 Claude Code 干活。如果不知道如何自己配环境或者懒得自己配环境,可用其他 agent 产品的每日免费额度配环境。
会话中保持配置不变确定好项目的 CLAUDE.md、配置好要用到的工具(MCP 等)之后再开始用 Claude Code 干活,在一个会话内保持 CLAUDE.md、工具列表等不变,防止缓存失效。
3. CLAUDE.md

Claude Code 每次运行时都需要读取 CLAUDE.md,而 CLAUDE.md 分为全局的和项目级的。可优化如下方面:
合理安排全局和项目的 CLAUDE.md比如你既有 vibe coding 的需求,又有文字创作的需求,那么 vibe coding 的那些工程规范应该放在项目级的 CLAUDE.md 而不是全局的 CLAUDE.md。只有那些你需要 Claude 在任意项目中都遵守的规则,比如“使用猫娘的语气”回复,才应该写进全局的 CLAUDE.md。
CLAUDE.md 需要包含项目介绍包含项目文件树、每个文件的说明、每个模块的功能等,避免 Claude Code 自行遍历文件。
删去 CLAUDE.md 中与系统提示词重叠的部分如题。
4. Skills、MCP 与其他工具
类似于 CLAUDE.md,agent skills 也分全局的和项目级的。Claude Code 每次运行时,都会读取全局的和当前项目的 skills 的 metadata。可优化如下方面
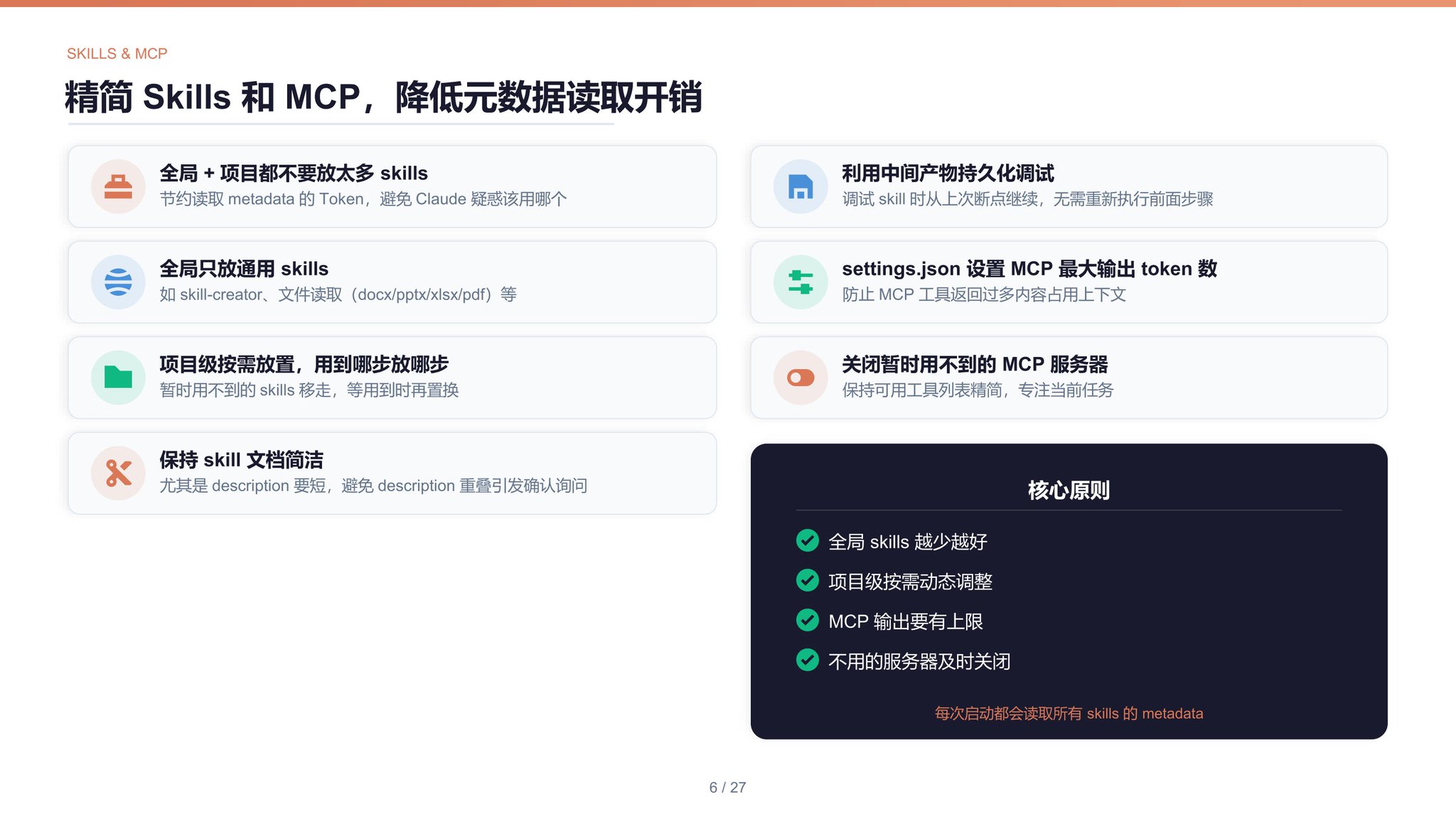
全局和当前项目都不要放太多 skills一方面是节约读取 metadata 的 token,另一方面是避免 skills 过多导致 Claude Code 疑惑应该使用什么 skills,以及 skills 的 description 重叠过多时引发的确认询问。
全局不要放太多 skills尽量只放通用的,比如 Anthropic 官方的 skill-creator 和文件读取(docx, pptx, xlsx, pdf)。
项目级按需放置 skills如果一个项目的流程包含很多步,则项目级只放当前步骤需要用到的 skills,而将暂时用不到的 skills 移走,等到用到它们时再置换。
保持 skill 文档简洁同 CLAUDE.md,保持 skill 的所有文档的简洁,尤其是保持 description 简洁。
利用中间产物持久化调试在会话中制作并调试包含多个步骤的 skills 时,可先让每一步都将中间产物持久化到本地文件,后续修改 skills 并重新测试时,从修改位置之前的最后一个状态开始继续执行,而无需重新执行修改位置之前的步骤。调试完毕后,去掉非必要的中间产物的输出。
在 settings.json 中设置 MCP 的最大输出 token 数如题。
关闭暂时用不到的 MCP 服务器保持可用工具列表简洁,专注于当前正在做的任务。
5. 使用 .claudeignore
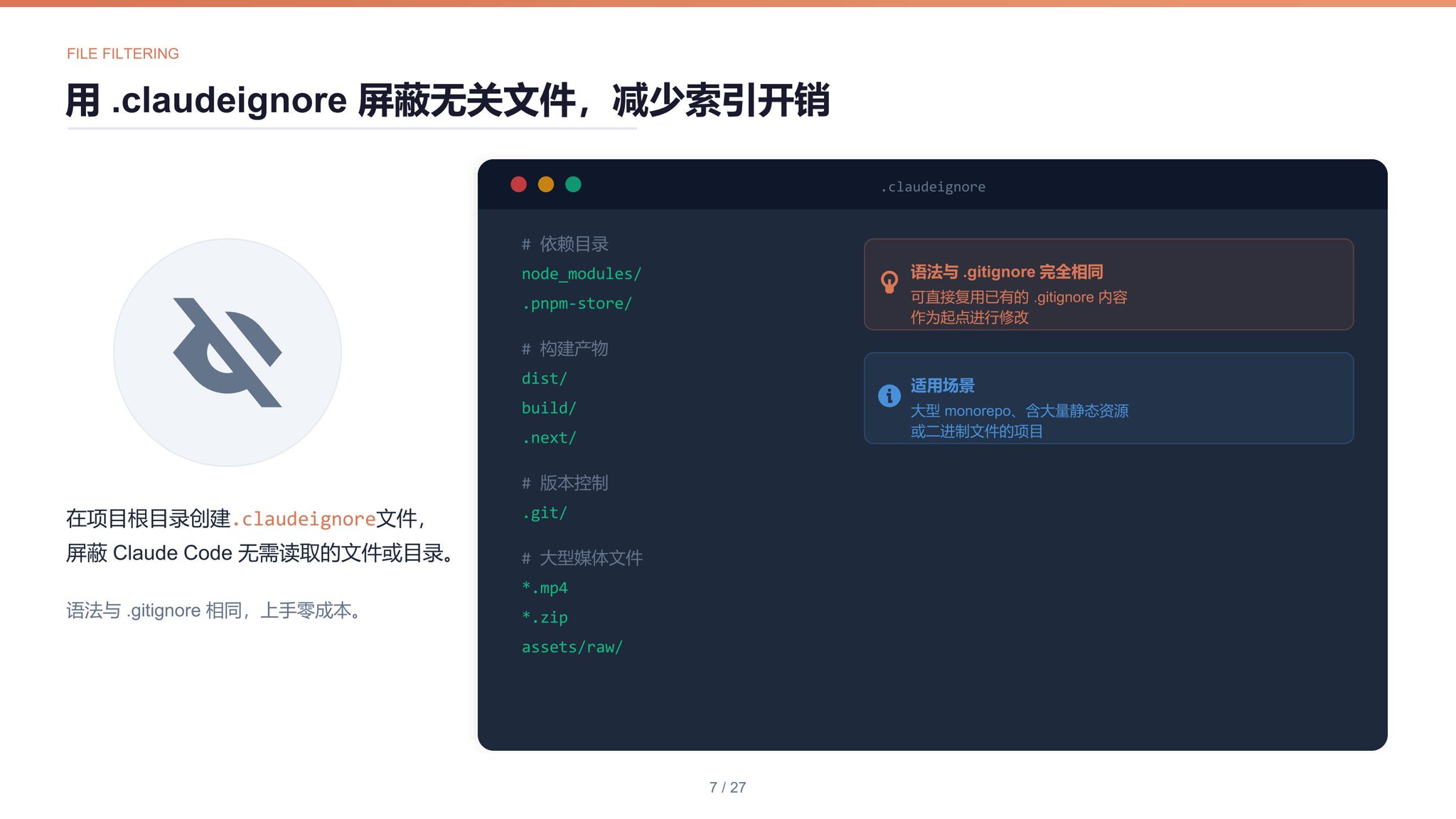
在项目根目录创建 .claudeignore 文件,屏蔽 node_modules/ 等 Claude Code 无需读取的文件或目录。
6. 提示词
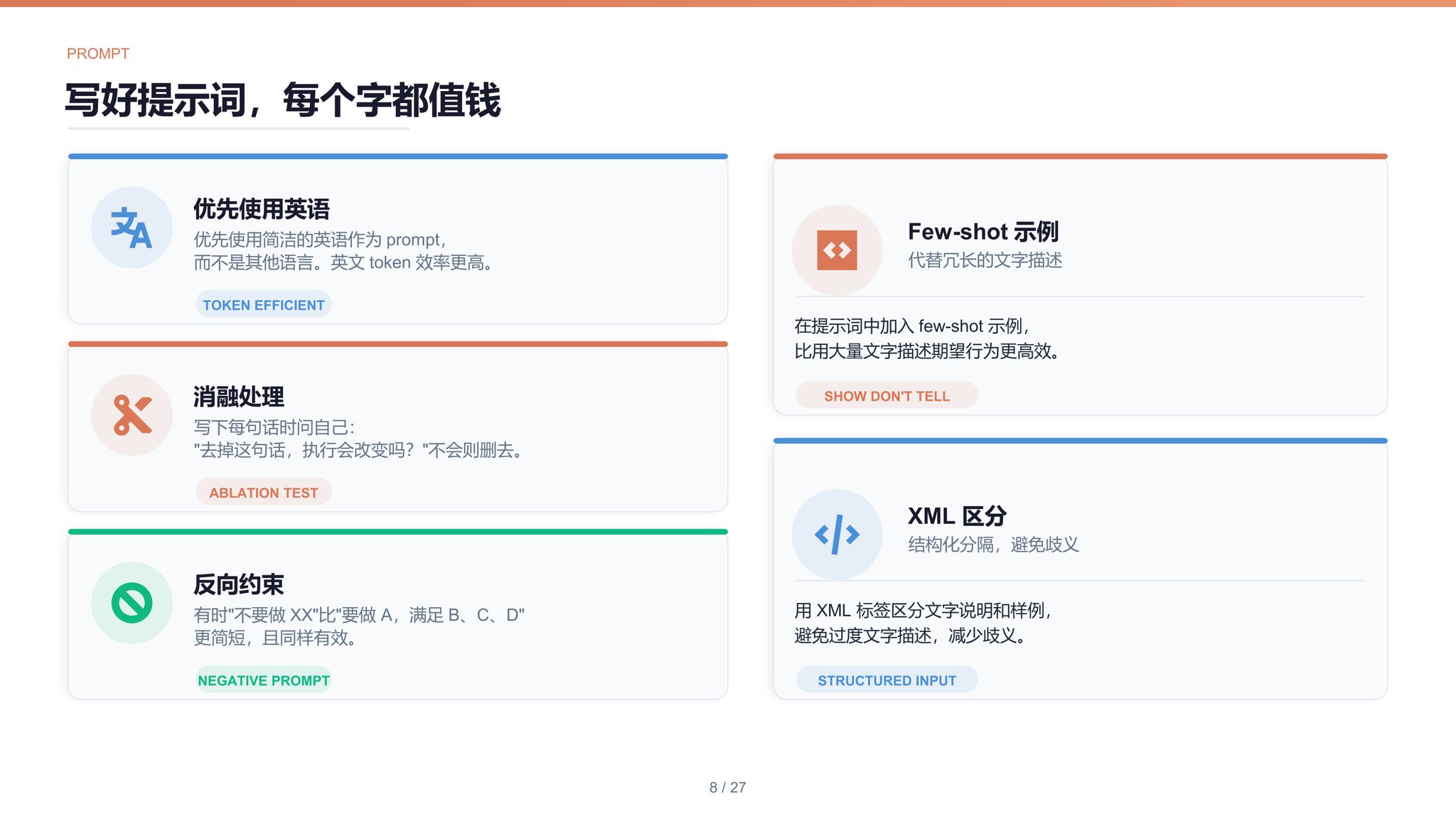
优先使用英语优先使用简洁的英语作为 prompt,而不是用其他语言。
消融处理保持简洁,进行消融思考:写下每一句话时思考“如果这句话去掉,执行是否会改变?”,如果不会改变,则删去。
反向约束提示词中,有时描述“不要做 XX”比“要做 A,满足 B、C、D 要求”更简短。
Few-shot 示例在提示词中加入 few-shot 示例代替冗长的描述。
XML 区分采用 XML 区分文字说明和样例,避免过度文字。
7. 模型分级使用

根据任务复杂程度分配模型根据任务的复杂程度选择使用的模型,复杂的任务使用 Opus;极其简单的任务使用 Haiku;对于大部分情况,使用 Sonnet。
优化长程任务 Skill如果你的 skill 需要执行长程任务,还可用能力较强的模型配合 skill-refiner skill (【链接在下方】)优化你的 skill,让你的 skill 被能力较弱的模型运行时也可以获得较好的 prompt alignment,进而可以换用能力较弱的模型来执行任务。
简单任务对于简单的定时任务,如 OpenClaw 的心跳,用能力较弱的模型或本地模型运行。对于确定性的任务,采用脚本执行。
使用 Advisor Strategy使用 advisor strategy(【链接在下方】),用 Sonnet 或 Haiku 作为执行者,给它们配上 Opus 作为顾问。执行者遇到无法合理解决的问题时会向顾问寻求指导,顾问访问共享的上下文并返回指导意见,由执行者继续执行。
顾问只给执行者提供指导意见,本身不进行工具调用或面向用户的输出。
调节 Effort简单的任务不要设置过高的 effort。
8. 会话
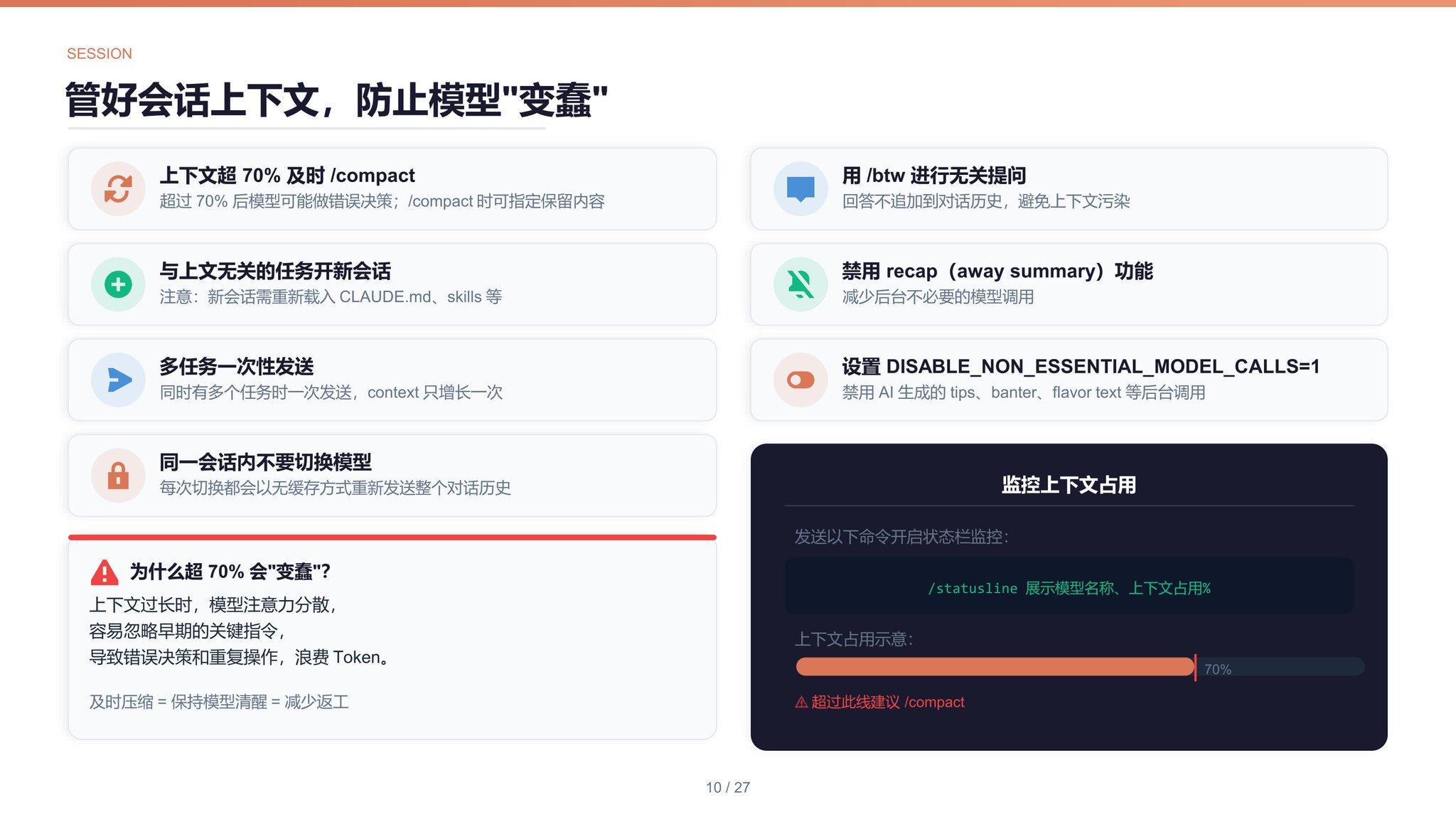
及时压缩或清理对话历史在会话中,如果上文对接下来的操作不那么重要,及时清理。
经验上,模型的上下文超过 70% 之后可能会变蠢,可能做一些错误的决策导致浪费 token。此时建议进行上下文压缩。使用 /compact 时可指定要保留的内容,比如保留工具调用的记录。
你可以向 Claude Code 发送```text /statusline 展示正在使用的模型名称、当前上下文占用的百分比和进度条
来监控上下文的占用情况。
<strong>开启新会话</strong>如果接下来的操作与上文完全无关,则新开启一个会话,而不是继续旧会话。但注意开启一个新对话需要重新载入 CLAUDE.md、skills、plugins 等。
<strong>任务一次性发送</strong>如果同时有多个问题、同时需要执行多个任务,则一次性发送而不是分多次发送,让 context 只增长一次。注意需要调节批次大小,保证单次请求的 token 数不超过模型的 context window,输出结果不超过 output limit。
<strong>在同个会话中保持模型不变</strong>不要在同一个会话中频繁切换模型因为每次切换都会以无缓存方式重新发送整个对话历史给新模型。
<strong>进行无关提问</strong>如果在会话中需要问一个与对话历史有关,但与任务主线无关的问题,比如好奇 Claude Code 前面说的某个词的意思,则用 /btw 进行提问,它能读取上下文,但回答不会追加到对话历史,避免上下文污染。
<strong>禁用会话的 recap 功能</strong>禁用会话的 recap (或称为 away summary)功能。
<strong>禁用非必要模型调用</strong>在 settings.json 中设置环境变量 DISABLE_NON_ESSENTIAL_MODEL_CALLS 为 "1",以禁用后台中不必要的模型调用,比如 AI 生成的提示词(tips)、闲聊(banter)和装饰文本(flavor text)。禁用后不会影响到核心工作流,但能减少后台 token 消耗。
## 9. 规划
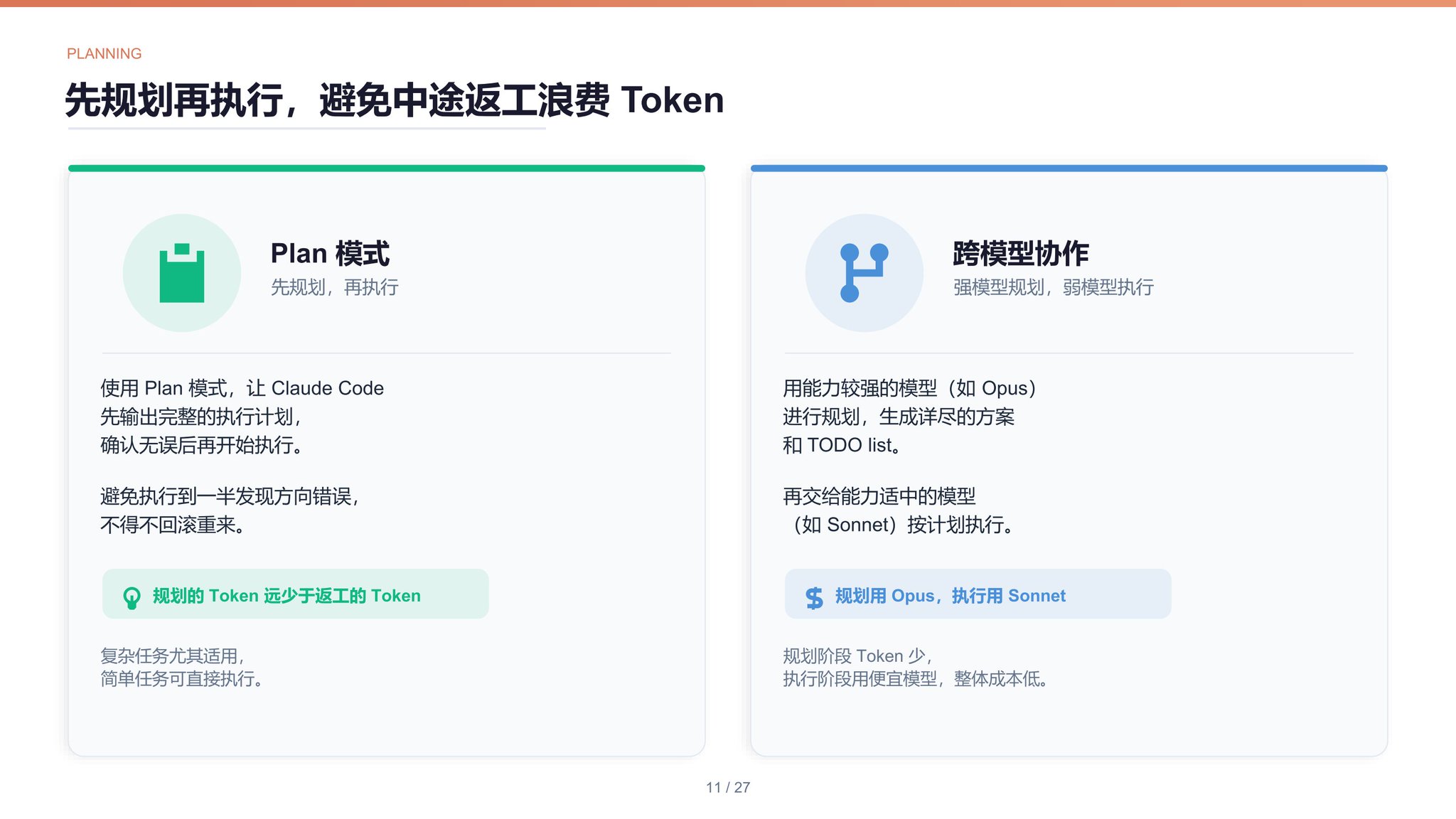
<strong>Plan 模式</strong>使用 Plan 模式,先规划再执行,避免执行中途返工。
<strong>跨模型协作</strong>使用能力较强的模型进行规划,生成一份详尽的方案和 TODO list,交给能力适中的模型执行。
## 10. 开启 Subagent

<strong>无需占用主 Agent 上下文的任务</strong>比如读取文件(尤其是文件数不少于 3 个)然后写总结,启动 subagent 进行读取,写完总结再返回给主 agent。
<strong>指定 Subagent 的模型</strong>在 settings.json 中指定 subagent 用能力较弱的模型,在主 agent 委派任务给 subagent 的提示词中,判断任务难度是否在 subagent 模型的能力范围内。
<strong>根据任务复杂程度分配模型</strong>用能力较强的模型进行任务分配,根据任务的复杂程度将不同的任务分配给不同能力的模型的 subagent。
## 11. 文件格式

<strong>使用 AI 友好的文件格式</strong>比如 Markdown、JSON、CSV、XML 等,而不是包含很多样式代码的 AI 不友好的文件格式,比如 HTML、Word 等。必要时,将其他文件格式通过 MinerU (【链接在下方】)转化为 Markdown 格式后,再喂给 AI。
对于网页,可以在 AI 浏览器中打开该网页,并输入提示词:
```text
将当前的正文部分转化为 Markdown 格式
结果保存在代码块,方便我复制
在 Pipeline 的中间采用 AI 友好的文件格式常用 JSON 传递消息,只在最后转化为人类友好的文件格式。比如在数据处理过程中以 CSV 传递,再转化为用户友好的 XLSX 格式。
使用更简洁的文件格式使用比 JSON 更简洁的 TOON 格式(【链接在下方】)。
12. 确定性任务

脚本和工作流优先确定性的任务,比如按指定格式维护文件,尽量通过脚本和工作流完成,而不是由 agent 自行探索如何实现。
优先使用命令行、CLI 执行任务如题。
13. 缓存

避免交互中断超过 5 min现在(2026.04.22)Claude API 的缓存只保活 5 min,应避免一个会话不交互超过 5 min,否则会再次计算 prompt 的前缀。如果必须要离开超过 5 min,可以根据实际情况判断是否应 /compact。
Prompt 书写规范如果用到多个差不多的 prompt,则将 prompt 中相同的部分(必须完全相同)放在前面,以命中缓存。
共享缓存同一个 Anthropic 账号或同一个 organization 内可以共享缓存。这一点理论上可行,但实践中很难命中缓存,因为每个会话的 prompt 前缀很难完全一致。此外,考虑到绝大部分人用的是中转站,存在账号调度问题,所以实际上很难实现这一点。
14. 自进化
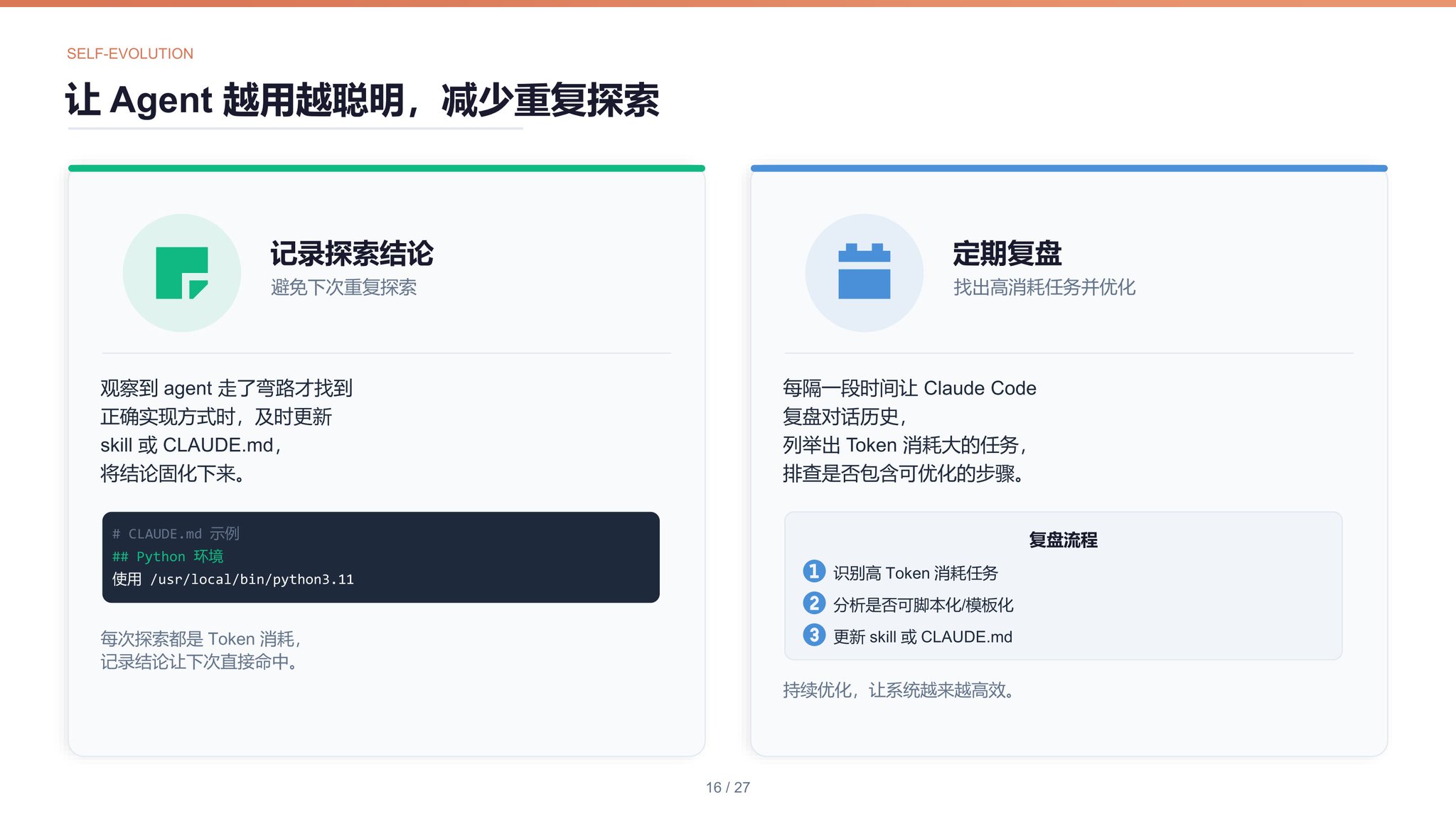
记录探索结论如果观察到 agent 执行过程中探索了一些错误的路径后才找到正确的实现方式,则及时更新 skill 或脚本,或将探索的结论写入 CLAUDE.md,避免 agent 下次再次探索。比如本地有多个 Python 环境时,在 CLAUDE.md 中指定要用的那个。
定期复盘每隔一段时间让 Claude Code 复盘对话历史,列举出其中 token 消耗大的任务,排查是否包含可优化的步骤。
15. 渐进式披露
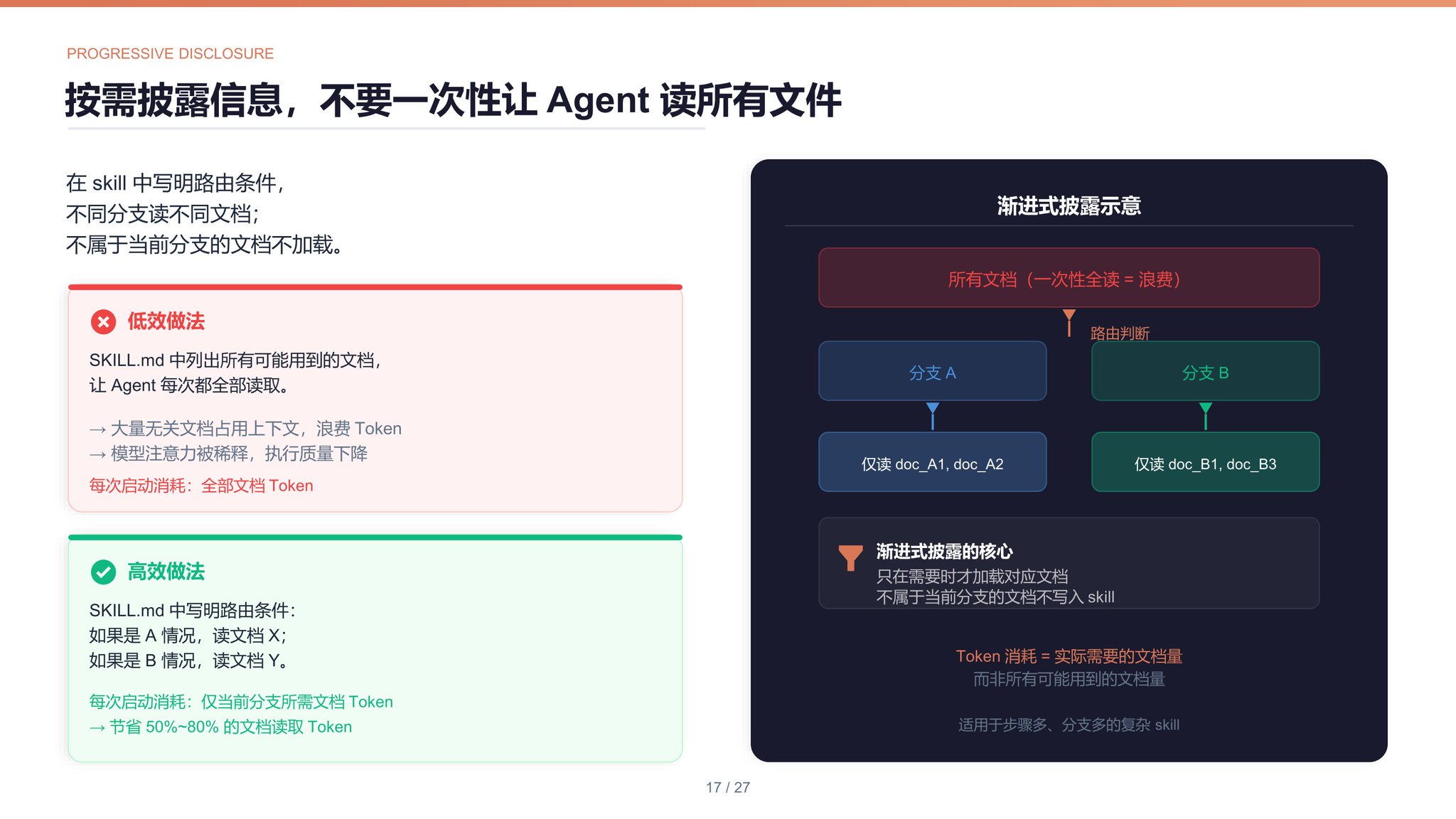
不要一次性让 agent 读取所有文件,而是采取渐进式披露,按需读取。比如一个 skill 的某个步骤可能有多种情况,每种情况需要读取不同的文档,则在 SKILL.md 中写明路由条件和要读取的文档,不属于这个分支的文档就不要写。
16. 读写文件

指定文件路径指定文件路径,避免 AI 频繁使用 ls, find, grep 等。
指定文件读取方式比如“使用 /pdf skill 读取 test.pdf”,避免 agent 自行探索读取方式,比如把 PyMuPDF、pypdf 、pdfplumber 试一圈。
局部提问与读取根据文件内容或网页提问时,如果提问的内容不是与整个文件或网页有关,则:
- 在 AI IDE 或 AI 浏览器中选中相关的部分进行提问,而不是直接指定文件的路径。
- 在指定路径的同时指定需要读取的行号。
清晰指出读写需求清晰地指出要读写的文件和需求,而不是模糊描述。比如“修复 auth.html 中用户名没有正确显示的 bug”,而不是“修复认证页的 bug”。
增量更新尽量采取增量更新,而不是将相同的内容重写多次。
17. 精简模型的输出
增加输出限制在提示词中告诉 Claude Code 只输出结果不输出过程、只输出修改的部分、输出多少个字以内,或者在调用 API 时限制 MAX_TOKENS 和 MAX_THINKING_TOKENS。
使用 caveman skillcaveman skill (【链接在下方】)可以极度简化 AI 的输出内容,删掉所有废话,允许碎片化表达,只保留关键的部分。注意,使用文言文输出未必能减少 token,因为 token 数与汉字数并非严格一一对应。实际每个汉字对应多少 token 与采用的 tokenizer 有关。
截断或摘要工具调用的结果添加 PostToolUse 的 hooks,将工具调用的结果截断或摘要后再传递给 agent。
压缩命令输出常用的命令,如 ls, git status, cargo test 等可能会输出很多信息。
给 agent 安装 rtk (【链接在下方】)的 hook 后,再次执行这些命令时它们会被重写,rtk 会压缩这些命令的输出,只将重要的部分传递给 agent。 缺点:被压缩的部分可能包含一些 rtk 觉得不重要但 agent 觉得重要的信息。
18. 巧用网页端 AI
讨论方案网页端的 AI 没有免费额度限制或免费额度较多。可以先与网页端的 AI 讨论出方案,写一版提示词和一些 example,避免本地的 agent 从零开始探索。
完成基础开发在网页端的开发工具,如 Google AI Studio 上先完成基础的开发,再将源码下载到本地进一步修改。
19. 错误处理

确保 Prompt 发送正确如果 prompt 发送后马上发现 prompt 写错了,按 ESC 键停下,修改后再重新发送。
中间及时打断执行复杂任务或长程任务时,偶尔看一下 Claude Code 的执行情况。如果发现它在反复试错,按 ESC 键停下来检查原因,并告诉 Claude Code 正确的尝试路线。
回滚会话如果 Claude Code 执行完后你发现执行结果不对,不要继续在会话中告诉 Claude Code 修改意见,而是双击 ESC 键或用 /rewind 调出 Rewind 界面,将会话回滚到某个 prompt 的位置。
回滚时可以选择仅恢复对话、仅恢复代码、同时恢复对话和代码。这样 Claude Code 执行得到的错误结果将从上下文中被剔除。
20. 本地搜索引擎

Claude Code 有时需要检索本地的文件,默认的搜索方式是关键词搜索,token 消耗高、效率低,且可能遗漏关键词不完全匹配但语义相关的对象。
使用 Obsidian CLI- 对于关键词检索,可以用 Claude Code 调用 Obsidian CLI 进行检索,再返回检索结果。
- 如果你可以给本地文件打上一些标签,可以用 Claude Code 调用 Obsidian CLI 按标签检索。
但这两种方式依旧是匹配关键词。
语义检索如果需要同时支持关键词检索和语义检索,可以使用 QMD(【链接在下方】),向量化、检索等过程都通过本地小模型完成。
缓存常用问答对于电商客服等经常需要回答类似的问题的场景,可缓存常见问题的回答并配合语义检索,以节省 token、降低延时。这需要在应用层自行实现,不是 Claude Code 自带的功能。
21. 编程
生成项目文档先用能力较弱的模型或其他 agent 产品的每日免费额度遍历开源项目的所有文件,写一份详细的项目文档,包含项目文件树、每个文件的说明、每个模块的功能等,将其作为能力较强的模型的参考文档。
使用 code-review-graph MCP使用 code-review-graph MCP (【链接在下方】)增量追踪代码库的修改。
使用 LSP使用 Claude Code 等原生支持 LSP 的 agent 产品,或安装 Piebald-AI/claude-code-lsps marketplace 等社区 LSP 插件,避免阅读代码时用 grep 检索标识符。
常量较长的常量保存在 .env 或环境变量而不是 CLAUDE.md 中,并告诉 Claude Code 用脚本读取。
仅传递函数签名只需调用函数时,只给 AI 传递函数签名而不是传递整个函数内容 AI 就可以知道如何调用。只有当执行发生错误或需要修改该函数时才需要阅读函数体的部分。
过滤代码注释AI 在很多时候不需要像人类一样阅读注释才能理解函数的功能。代码注释较长时,可只保留简单的说明,甚至是先通过脚本过滤掉所有注释行再传递给 agent。
22. API 调用
设置额度限制给 API 设置额度限制。如果订阅的是 Claude Pro 或 Max,需注意拦截机制,手动设置额度限制是必要的。
强制输出 JSON 格式如果只要求模型输出一个特定的格式,比如 JSON 格式,不要输出额外的文字说明,则:
(1)采用 prefill 策略。具体地,先在对话历史中加入 assistant 信息 "json",并在调用 API 时,设置 stop_sequences = [""],这样当 AI 输出至 "```" 时就会停止生成。
但注意:
- 生成的 JSON 中间包含 "```" 时会误触发停止,导致输出不完整。
- extended thinking 下不支持 prefill。因此这种方法现在已不推荐。
(2)调用 Anthropic API 时指定 betas=["output-128k-2025-02-19"] 强制输出 JSON 格式,或者通过工具调用返回 JSON 格式作为结果。
23. 白嫖每日的免费额度
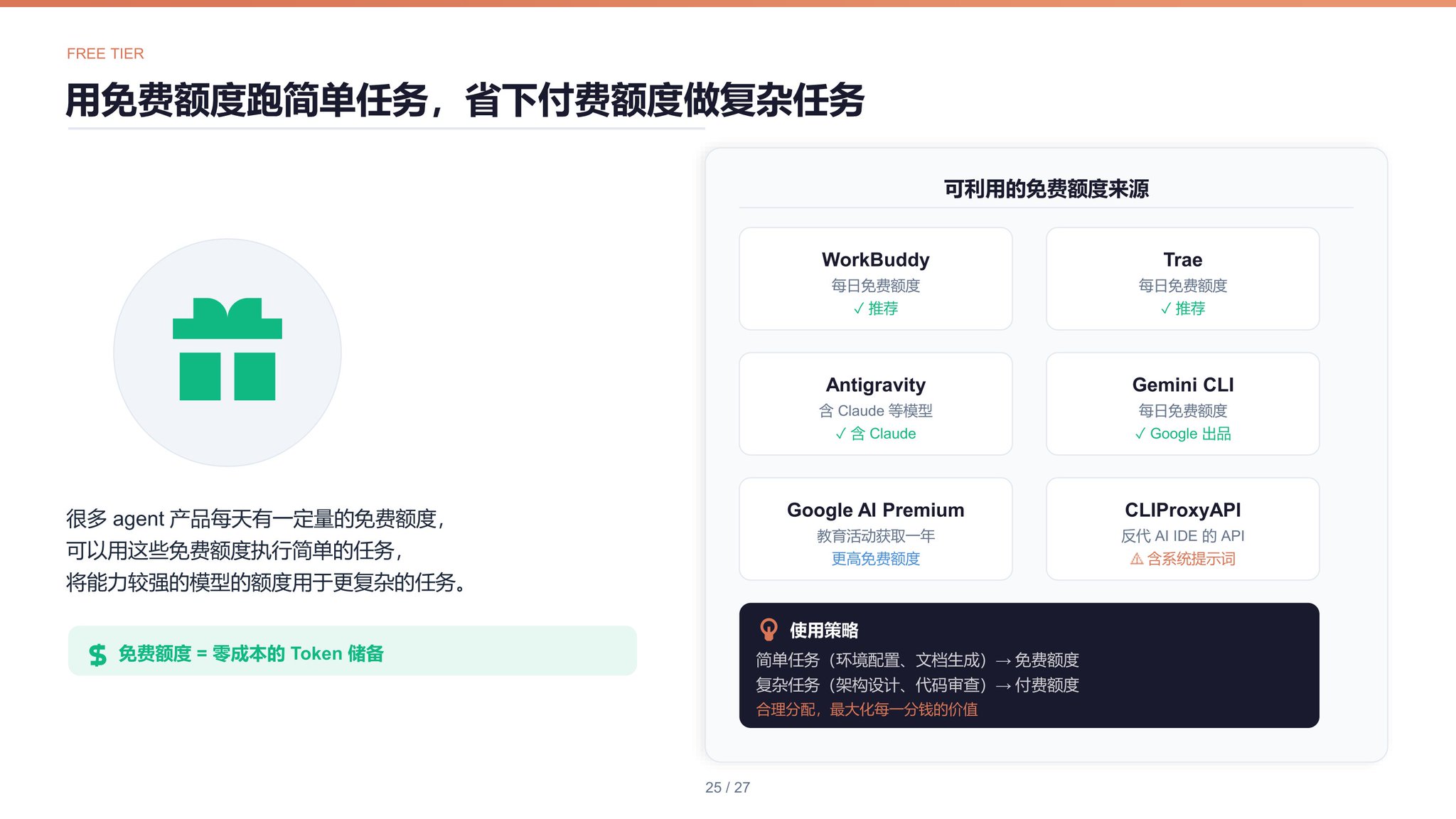
很多 agent 产品每天有一定量的免费额度,比如 WorkBuddy、Trae、Antigravity、Gemini CLI 等。可以用这些免费额度(可能是能力较弱的模型)执行简单的任务,而将能力较强的模型的额度用于更复杂的任务。
Antigravity 中也有 Claude 等模型。你可以先通过 Google 的教育活动获得一年的 Google AI Premium,可以获得更高的免费使用额度。
也可以用 CLIProxyAPI (【链接在下方】)这个开源项目,将 Antigravity 等 AI IDE 中的 API 反代出来白嫖,但这样的 API 不够纯净,比如可能带有 AI IDE 的系统提示词。
24. 使用更划算的付费方式

采用订阅制购买模型产商的订阅、会员、coding plan 等并尽量把额度用满时,实际每 token 的花费比按量计费低。但订阅 Anthropic 对中国用户不友好。
选用便宜 token 渠道按量计费时,选用更便宜的 API 渠道。我用的是这个 ¥1 人民币换 $1 美金的使用额度,甚至不到 ¥1 人民币换 $1 美金的使用额度的中转站。(【链接在下方】)
本地模型买台主机,买个显卡,跑本地模型,比如 Google Gamma。
最后
- 上面看不懂没关系,可以找懂的人问问,比如我。
- 写完之后我深刻意识到,AI agent 对大众来说还是过于冷门了,感觉我上面提到的很多东西只有开发者才知道。