
一
Fable 5 刚发布,迄今到现在为止最强的模型。
昨天我拿它做测试,随手让它帮我查一个东西。
它给我写了一大段,逻辑很完整,结构清楚,细节也像那么回事。读完以后,我差点就直接信了。
但里面有个关键数据,我顺手核了一下。
错的。
这种错误不离谱,甚至很难一眼看出来。它错的比较巧妙:周围全是对的,中间那一句,是模型自己补进去的。
真正让我后背发凉的地方。
是它错得太自然。
前后都对,逻辑也通,那句假的被裹在一堆真的里面,我差一点就没看出来。
模型越强,幻觉越不像幻觉。它不会摆出一副“我在瞎编”的样子等你识破。它会把那一点错,塞进一大堆正确内容里,让你慢慢停止检查。
后来我想明白一件事:幻觉不像大模型身上的一个小 bug,也不像以后修一修就能补掉的洞。
它和“模型能听懂你说话”,用的是同一套机制。
理解也好,编造也好,手法没有换。
要看清这一点,得往下沉一层,去看那个所有大模型都绕不开的东西:attention,注意力机制。
二
它最奇怪的地方就在这里。
我们读一句话,通常从左到右,一个字一个字读完。模型的读法不同。它可以让一句话里的每一个 token,直接看见其他所有 token。
token 你可以先理解成一句话被切碎之后的基本片段。
模型为什么要让这些片段互相看?
因为语言真正的意思,很多时候不在某一个词里,而在词和词的关系里。
比如这句:“奖杯放不进箱子,因为它太大了。”
这里的“它”,指的是奖杯。
但只要改最后一个字:“奖杯放不进箱子,因为它太小了。”
这个“它”立刻变成了箱子。
同一句话,同一个“它”,意思能直接反过来。模型凭什么判断?它没别的办法,只能让“它”这个 token 回头去看整句话,从上下文里把意思找出来。
这就是 self-attention,自注意力。
一个词是什么意思,不只由它自己决定,还要看它和周围所有词的关系。
三
那它具体怎么“看”?
每个 token 会生成三种向量。
query,查询向量,代表“我现在想找什么”。
key,键向量,代表“我这里有什么特征”。
value,值向量,代表“你注意到我之后,能从我这里取走什么信息”。
当一个 token 的 query,和另一个 token 的 key 越匹配,它俩之间的注意力分数就越高。
这些分数会经过缩放和 softmax,变成注意力权重。权重高的 token 被放大,权重低的被压下去。模型再按这个权重,从各个 value 里取信息,合成一个新的 context。
也就是这个词在当前这句话里,到底该怎么被理解。
attention 真正做的,远远不止判断“哪个词重要”。
它在判断:“这个词,放在此刻这个语境里,应该怎么理解?”
而且它不只做一次。
Transformer 会用很多个注意力头,从不同角度同时看一句话。有的头盯语法,有的头盯指代,有的头盯情绪。再往上叠很多层。
到这一步,模型已经不只是在处理词了。
它是在一层一层地重写整句话的上下文。
GIF
四
现在回到开头那个问题。
为什么越强的模型,越会一本正经地编?
把前面两层连起来看,attention 从头到尾都在做一件事:在一大片上下文里找相关信号,再把它们组织成一个连贯的整体。
相关信号足够多,我们就说它理解了。
相关信号很少,甚至根本不在,它也不会停下来。它还是会沿着同一套动作,给你组织出一个完整答案。
这时候,我们才叫它幻觉。
理解和幻觉并非两个开关。更像是同一台机器,在信号充足和信号不足时,跑出来的两种结果。
麻烦也在这里。
模型自己分不清这次是哪一种。对它来说,两次干的活太像了。
这也是为什么模型越强,幻觉越危险。它越擅长把碎片组织成整体,信号不足时编出来的东西,就越容易骗过人。
当这套结构被放大,喂进海量数据训练,它开始长出小模型没有的能力:推理、写代码、看懂复杂指令。这些通常被叫作 emergent abilities,涌现能力。
但涌现背后最硬的线索,仍然是这件事:它越来越擅长在很长的上下文里找信号,然后生成连贯的回答。
问题就出在“连贯”两个字上。
连贯不等于真实。
GIF
当模型手里没有可靠依据,它仍然会把几个高权重的线索,硬连成一个听起来合理的答案。语法全对,逻辑通顺,甚至很有说服力。
可它可能根本没发生过。
这就是 hallucination,幻觉。
幻觉没有那么像纯粹乱说。更准确一点,它是模型把一堆不完整的碎片,合成了一个错误的上下文。
回到那个 Fable 5。
它没有撒谎。
它只是很擅长把碎片讲成一个完整故事。
写到这里,我得停一下。
因为接下来要说的,可能已经不只是模型了。
可能会戳中你的心。
五
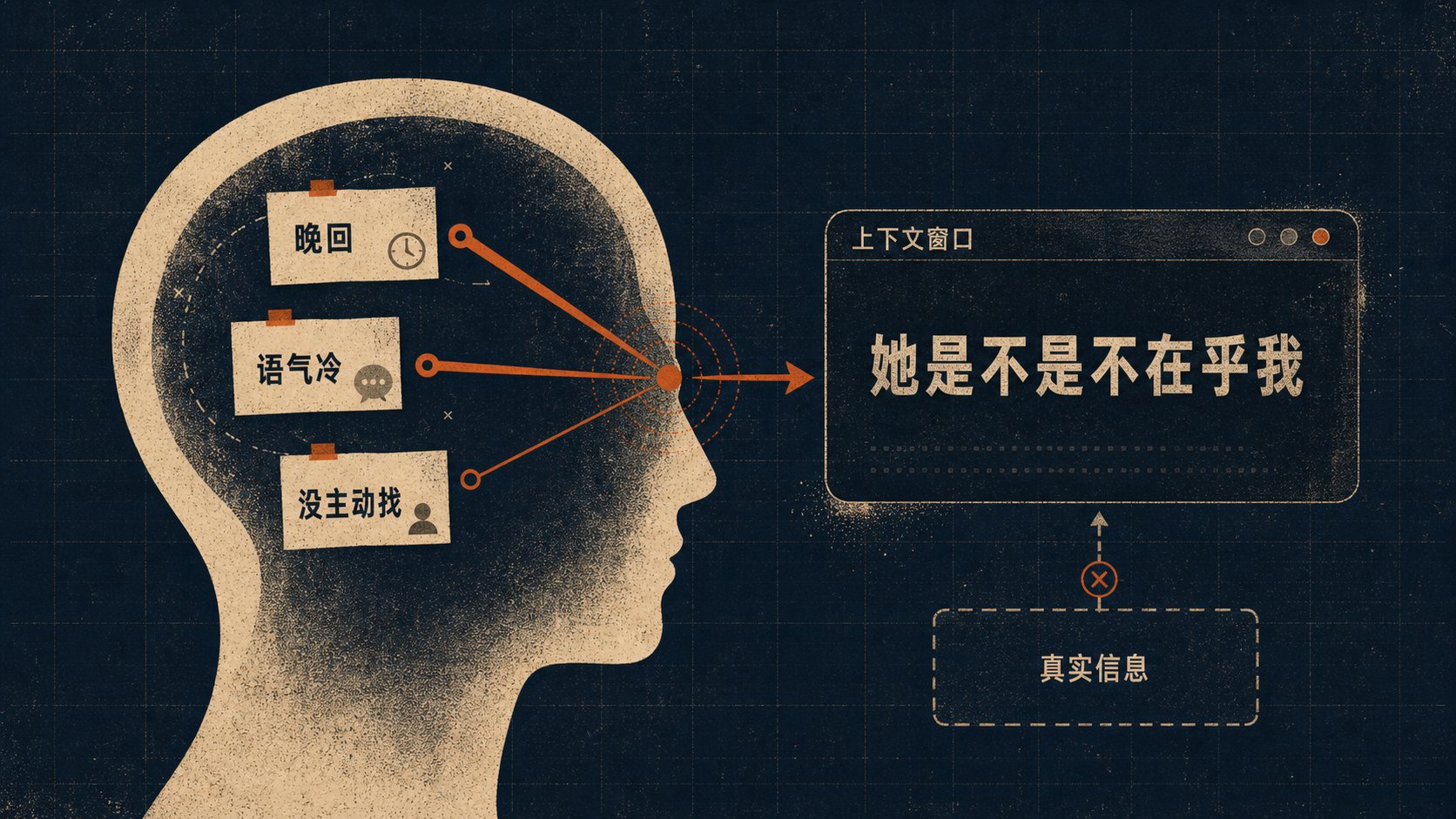
比如,她今天晚回了一次消息。
你给这条消息很高的权重。
然后她语气好像冷了一点,权重又往上跳。
她一整天没有主动找你,这个信号几乎占满了你整张注意力图。
最后你把这些线索合在一起,生成了一个属于你自己的 context:
她是不是没那么在乎我了。
真正折磨人的地方在于,这个 context 可能是真的,也可能只是你的幻觉。
你站在自己的上下文窗口里面,根本分不清。
你感受到的难过是真的。
但你对这份难过的解释,未必是真的。
还有件更麻烦的事。你越在乎一个人,给她的基线权重就越高。
同样一条“晚回的消息”,陌生人发你,没什么波澜;她发你,能让你脑子跑很远。
也就是说,恰恰是在你最在乎的那个人身上,你的注意力图最容易被一点点信号带偏。你的幻觉,也最严重。
这和模型很像。
它越想给你一个满意答案,就越容易在信息不够的时候补全。
模型在幻觉的时候,并不知道自己在幻觉。从里面看,一个真实的上下文,和一个编出来的上下文,长得差不多。
你也一样。
最痛的从来不只是她没有注意你。
最痛的是你分不清:她是真的没给你同等的注意,还是你在自己的上下文里,亲手生成了一份冷漠。
说穿一点:
你觉得你在等她回复,其实你在等一个权重变大。
你觉得你想确认她爱不爱你,其实你想确认的是,在她的上下文里,你到底占了多少注意力。
可人毕竟不是 Transformer,感情也没有 softmax。
没有人会把对你的注意力权重,清清楚楚地标出来给你看。
你只能猜。
而你这台推理机,最不擅长的,偏偏就是“不猜”。
六
那怎么办?有办法。
既然你的痛苦,和模型的幻觉有点像,那让模型少幻觉的办法,差不多也能搬到人身上。
第一,去拿真实的 token。
工程上让模型少瞎编,最有效的办法,是给它真实资料去对齐,不让它只在脑子里空转。
对应到你身上,也一样。
你看起来是在等回复,其实是在拿“晚回、语气冷、没主动找”这三个 token,反复跑同一段推理。
数据就那么点。
你算一千遍,也很难算出新东西。
你迟迟不去问,往往并非怕麻烦。
你怕的是那个真实答案,会杀死脑子里那个更体面的版本。
只要你不问,“她可能还在乎”就还活着。可你越不问,就越只能在三个碎片里打转。
出口其实只有一个:
去拿第四个 token。
它只存在于那个真实的人身上。
第二,允许自己停在“不知道”。
好的模型,会在没把握的时候选择不答。它不会硬挤出一个流畅的错误答案。
人最缺的,恰恰是这个能力。
你宁可信“她不在乎我”,也受不了“我不知道她怎么想”。
因为难过至少是一块能站的地。
“不知道”是悬空。
于是你亲手生成了那个最疼的版本。
它不一定真,但它完整。
很多时候,伤到你的未必是她。
你是被你自己那个太完整的故事伤的。
学会停在留白里,不急着把它填满。
这是反幻觉里最难的一步。
第三,越流畅,越要警惕。
记住幻觉的特征:语法全对,逻辑通顺,很有说服力。
就像开头那段 Fable 5 写的答案,完整到我差点全信。
当你脑子里那套“她其实早就……”已经讲得天衣无缝,连她下一步都替她想好了,那不一定是真相的标志。
更可能只是你太熟练了。
一个故事你能讲得这么熟,说明它已经在你心里跑过很多遍。
也许,问题根本不只在这一次。
也不只在这一个人。
七
写到这里,我想说:
你没有那么脆弱,也没有那么作。很多时候,你只是想太多。
你只是一台讨厌空白的推理机。
一遇到留白,就忍不住把它写满。
这是这套结构本身的特性,不全是你的错。模型也一样,留白一多,它就开始补。
而且你不只对她这样。
你对老板那句没头没尾的话,对那条发出去没人点赞没流量的推文,对那个已读不回的甲方,对镜子里的自己,也都这样。
你这辈子,一直在拿三个 token,写一部又一部很长的小说。
理解一句话,和误解一个人,用的是同一双手。
这双手让你能读懂世界,也会让你在没有证据的地方,凭空织出一整匹布。
所以,
当你手里只有三个碎片的时候,最勇敢的事,不在于立刻把它们拼成一部小说。
忍住,先别写。
去那个唯一有答案的地方。
拿第四个 token。
关于作者
Kyrie— 前国内大厂 R&D 工程师,现居曼谷,做中国科技企业出海 BD。持续分享出海一线真实记录、AI 在业务里的实战用法,偶尔也聊聊美股投资和国外生活。