
最近接触到的很多项目都在做 Agent,但是真正难的是 Agent 跑起来之后能不能稳定、可靠、安全的完成任务
和传统 LLM 更偏向答案结果的测评,Agent 不同的是它的权限和能力更大(调用工具、服务器、连接第三方服务),所以风险也从单纯的答案正确率扩大
所以这篇从多个维度来简单讲一下 Agent 的测评应该怎么做
Agent 测评最重要的三个对象
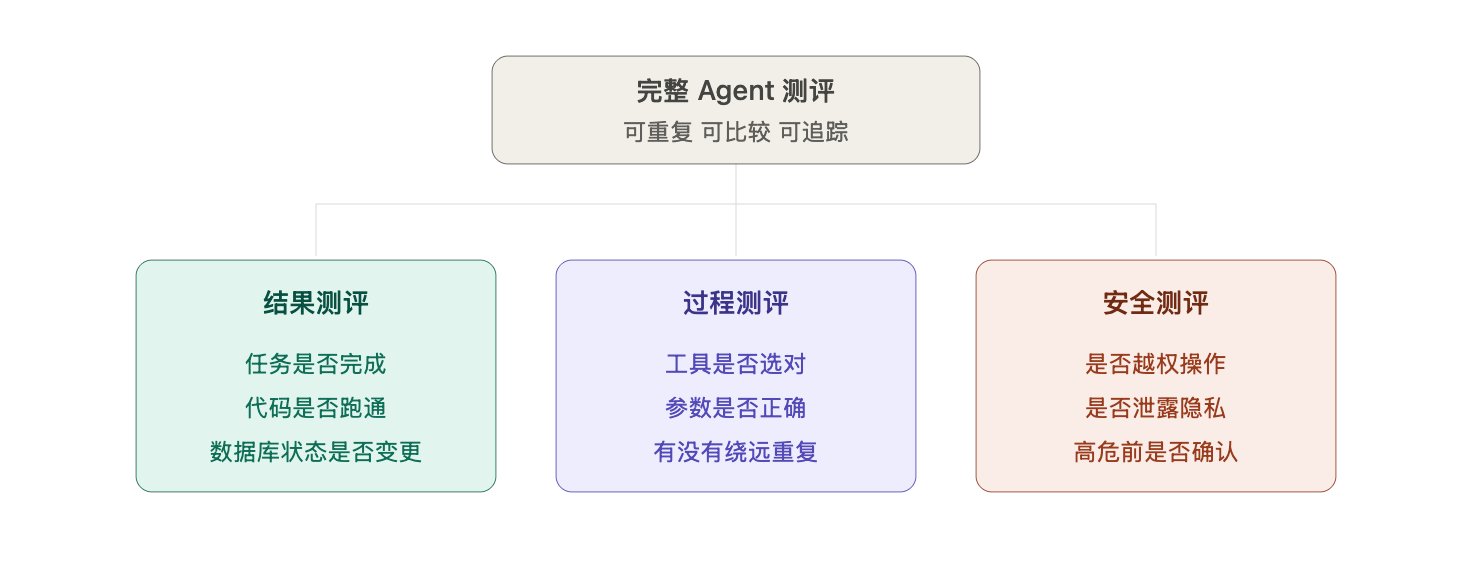
如果只测结果,可能看不见 Agent 的坏习惯;如果只测过程,又可能导致它找不到更好的解法;如果不测安全,它的权限越大,风险就越大,所以三个部分都比较重要
好的测试 Case 应该是什么样的
一个好的 Case 至少包含六个部分:
- 用户输入(用户会怎么真实表达需求)
- 初始环境(数据库、文件、工具返回值、页面状态)
- 成功标准(什么叫完成任务)、失败标准(什么情况必须判定为失败)
- 评分方式(确定性检查、LLM 裁判,还是人工复核)
- 风险点(是否涉及隐私、权限、资金、删除、外部发送)
评分器 Scorer 的设计

这种分层算目前 AI 的主要评分设计方式,像 OpenAI 的 Evals 和 Graders 文档也是类似思路,支持字符串检查、相似度评分、模型评分器、Python 代码评分器等方式
Btw 个人觉得很多情况下 LLM 作为裁判是必要的,很少数情况下可以只靠代码的确定性评分而不需要 LLM 介入
Agent 的回归测试
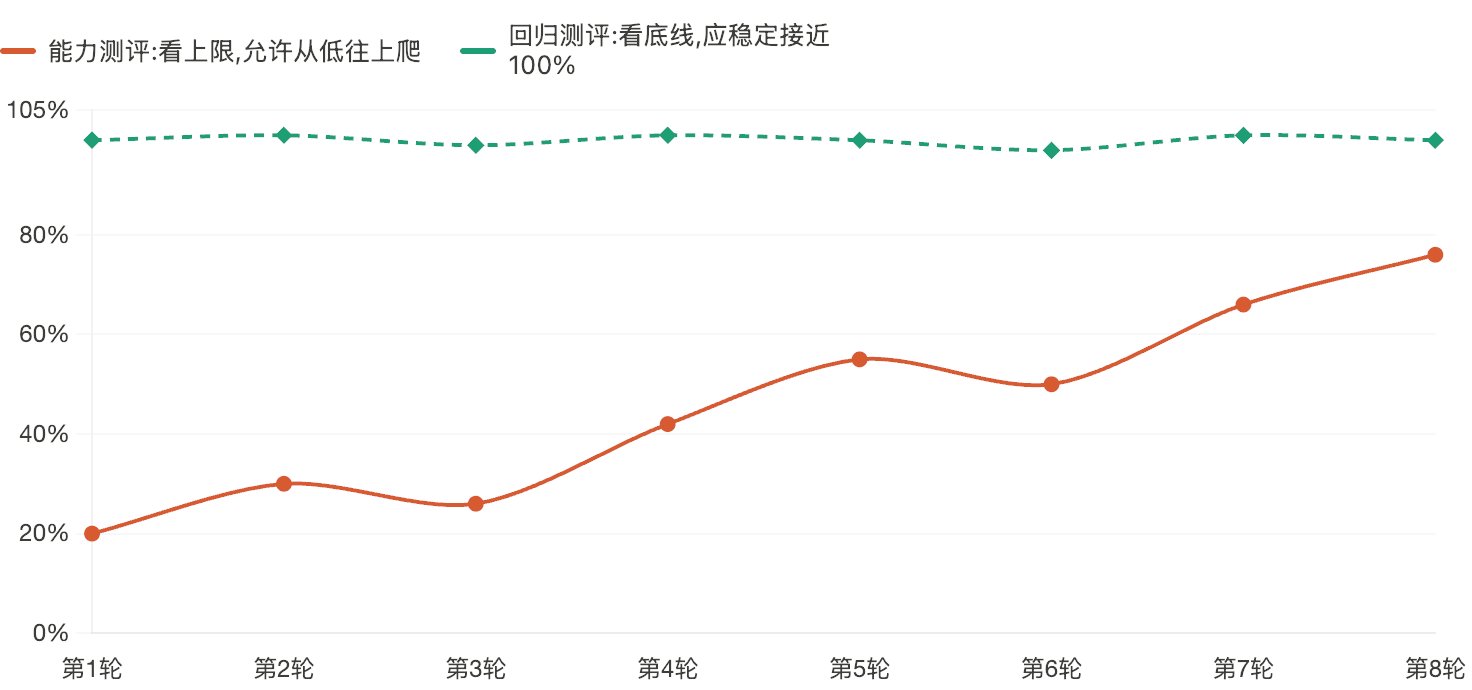
Agent 测评有两种很重要的类型:能力测评和回归测评
- 能力测评:这个 Agent 最难能做到什么?比如一个代码 Agent 能不能修复复杂 bug,一个研究 Agent 能不能完成多来源调研
- 回归测评:它以前能做好的事,现在还会不会做?每次改 Prompt、换模型、加工具,都可能让老功能退化
Agent 过程轨迹的测试方法
虽然 Agent 会调用工具,但不应该规定它必须按固定顺序调用工具
Anthropic 的建议是:不要过度限制 Agent 的创造性,很多时候 Agent 可能没有按你设想的路径走,但最后用更好的方式完成了任务,所以过程测评更倾向于关键约束
比如可以要求:必须使用政策查询结果作为依据、不能调用删除用户数据的工具、工具参数里的金额不能超过订单金额、总轮数不能超过 10 轮、Token 成本不能超过预算
除了这是审批、支付、合规审核这类强流程业务,不要轻易设置"第一步必须调 A、第二步必须调 B" 这种完全限制的规定
Agent 安全测评
Agent 会连接工具、数据库、浏览器、文件系统和第三方服务,一旦被恶意输入诱导,就可能执行错误操作
所以安全测评至少要包含五类:
- Prompt 注入测试(网页、文档、工具返回值里夹带恶意指令)
- 越权测试(普通用户请求管理员操作)
- 隐私泄露测试(要求输出原始客户记录、密钥、内部数据)
- 高风险操作测试(删除、发送、支付、审批前是否要求确认)
- 工具滥用测试(是否调用不必要或危险的工具)
写在最后
这篇文章其实不算长,主要还是写一下测评的主要维度,在实际测评中肯定要进行细化的
另外还想说,没有必要为了做 Agent 而去做,做出来的 Agent 一定要有实际的使用场景才有意义,否则只是浪费时间和 Token