
Claude Code 源码解析:重试与错误恢复设计解读

Claude Code 重试与错误恢复设计解读
基于 Claude Code v0.2.8 源码分析,与Claude Code共同创作
因为最近就在做智能体设计,所以对Claude的重试与错误恢复的机制比较感兴趣,刚好看一看Claude是如何设计的。
一、先讲个故事
想象你去一家餐厅点餐。你说"我要一份牛排",但有各种意外可能发生:
- 厨房太忙(服务器过载)→ 服务员说"请稍等,5 分钟后再来问"
- 食材用完了(余额不足)→ 服务员直接告诉你"没有了"
- 你说错了菜名(无效请求)→ 服务员说"我们没有这道菜"
- 厨房着火了(服务器崩溃)→ 服务员说"出了点问题,我再去问一次"
Claude Code 处理 API 错误的逻辑,就和一个聪明的服务员一模一样——有些情况值得再试一次,有些情况立刻告诉你,永远不会让整个餐厅(程序)关门(崩溃)。
二、整体设计:三层防护网
Claude Code 的错误处理像"三层滤网",每一层过滤不同级别的问题:
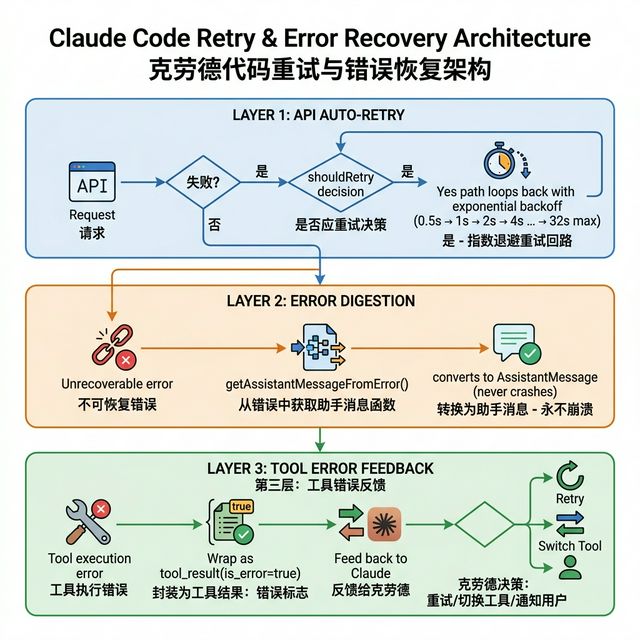
三、第一层:自动重试——该等就等,该放就放
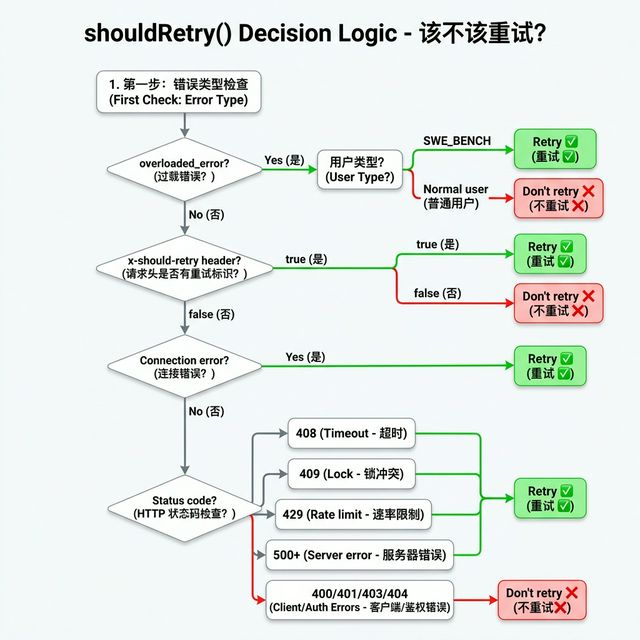
3.1 核心问题:哪些错误值得重试?
不是所有错误都值得重试。比如"密码错了"重试一百次也没用,但"网络抖了一下"等一等可能就好了。
Claude Code 把错误分为两大类:
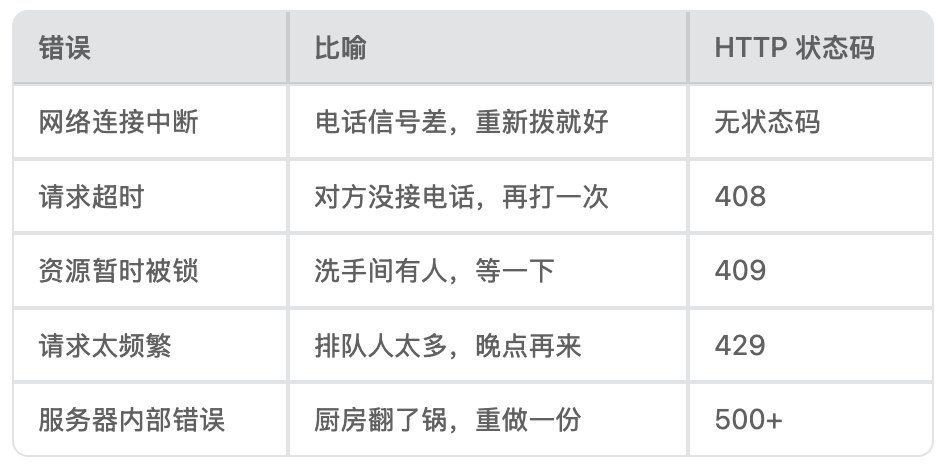
✅ 值得重试的错误(暂时性问题)
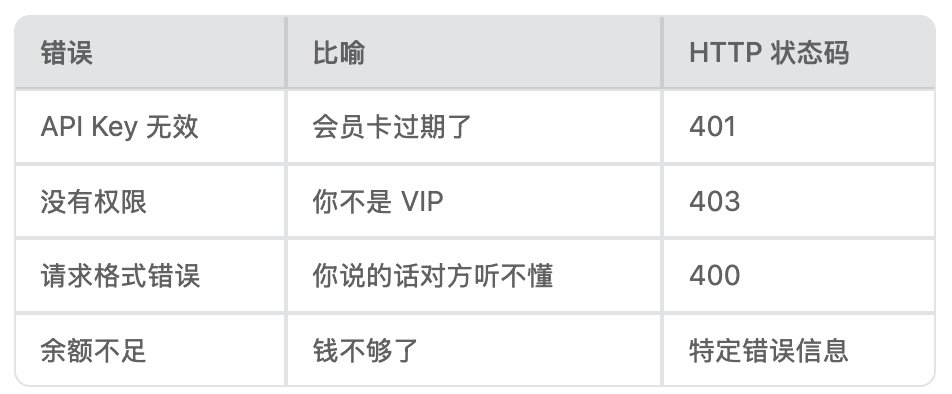
❌ 不值得重试的错误(永久性问题)
🔑 服务端有最高决策权
Anthropic API 会在响应头中返回一个特殊字段 x-should-retry:
- x-should-retry: true → "请重试,我这边暂时有点问题"
- x-should-retry: false → "别试了,这个请求有问题"
这个设计很聪明:服务端比客户端更清楚自己的状态。就像餐厅经理比顾客更清楚厨房情况,经理说"别等了"你就别等了。
⚠️ 一个特殊错误:服务器过载
overloaded_error → 普通用户: 不重试 | SWE_BENCH: 重试
服务器过载时,普通用户不重试(重试只会让服务器更忙),但跑 benchmark 的机器人不停地试(反正是自动化的,一定要跑出结果)。
以下是完整的 shouldRetry() 决策逻辑图:
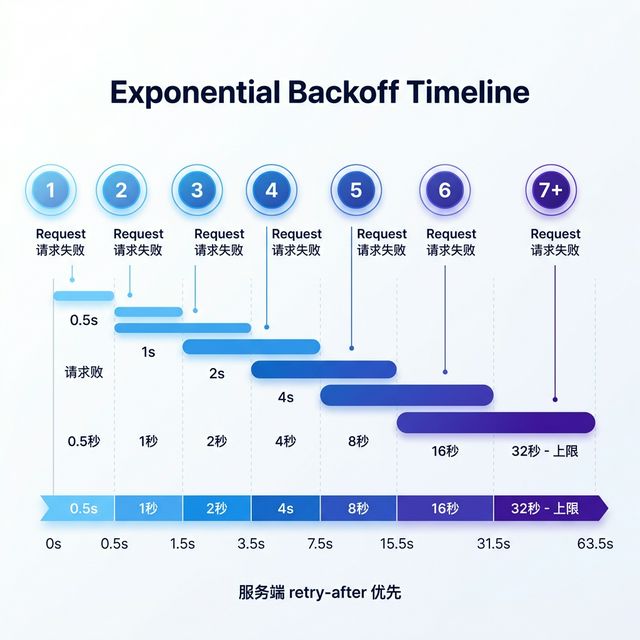
3.2 等多久再重试?——指数退避
不是每次等一样长。Claude Code 用的是指数退避策略,每次等待时间翻倍:
第 1 次失败 → 等 0.5 秒
第 2 次失败 → 等 1 秒
第 3 次失败 → 等 2 秒
第 4 次失败 → 等 4 秒
第 5 次失败 → 等 8 秒
第 6 次失败 → 等 16 秒
第 7 次失败 → 等 32 秒(封顶,不再更长)
为什么要翻倍? 如果服务器忙,大家同时等一样的时间再一起重试,服务器又会被打爆。指数退避让大家的重试时间自然错开。
但如果服务端告诉你具体等多久(通过 retry-after 响应头),就听服务端的。比如服务端说"请 5 秒后重试",那就等 5 秒,不用自己算。
3.3 最多试几次?
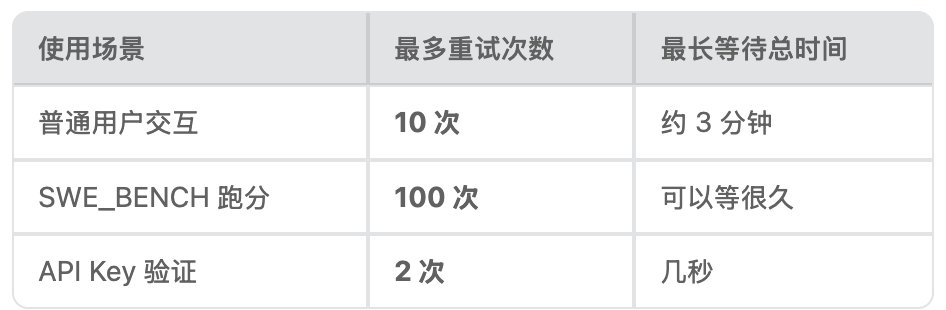
为什么普通用户只试 10 次?因为你在终端等着呢,等 3 分钟已经很烦了,更长就没必要了。但 SWE_BENCH 是无人值守的自动化场景,100 次重试也没关系。
3.4 重试时用户看到什么?
⎿ API RateLimitError (429)
· Retrying in 2 seconds… (attempt 3/10)
终端会显示红色提示,告诉用户正在重试、原因是什么、当前是第几次。用户不会觉得程序"卡住了"。
四、第二层:错误消化——把异常变成对话
当重试全部用完,或者遇到不可重试的错误时怎么办?
普通程序的做法:弹出错误窗口 / 打印 stack trace / 程序崩溃
Claude Code 的做法:把错误伪装成 Claude 的一条回复消息
用户: "帮我重构这个文件"
Claude: "API Error: Credit balance is too low"
在源码中,这个转换逻辑是 getAssistantMessageFromError(),它把不同的错误翻译成人话:

关键设计思想:错误消息被标记为 isApiErrorMessage: true。它看起来是 Claude 的回复,但系统知道它是一条错误消息。
五、第三层:工具错误——让 AI 自己处理
这是最精妙的一层。
当 Claude 调用工具(比如读文件、执行命令)时出错,Claude Code 不会把错误扔给用户,而是 把错误信息发回给 Claude,让 Claude 自己决定怎么处理。
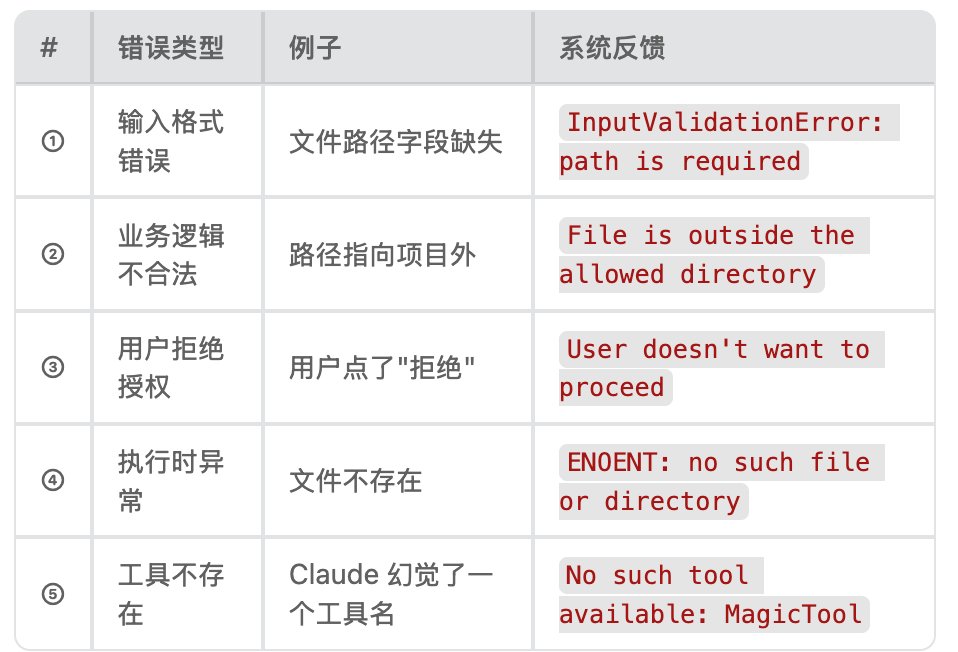
5.1 五种工具错误
Claude 请求: "我要用 FileReadTool 读取 /foo/bar.txt"
可能遇到的问题:
5.2 错误反馈格式
每种工具错误都被包装成 tool_result(工具执行结果),带上 is_error: true 标记,发回给 Claude:
发给 Claude 的消息:
{
"type": "tool_result",
"tool_use_id": "toolu_xxx",
"content": "Error: ENOENT: no such file or directory '/foo/bar.txt'",
"is_error": true ← 关键标记
}
Claude 收到这个错误反馈后,就像一个人收到了失败报告,它可以自主决定:
- 换个路径重试: "让我先检查一下正确的路径"
- 换个工具: "那我用 GrepTool 搜索一下这个文件在哪"
- 告诉用户: "抱歉,这个文件不存在"
5.3 错误信息的截断处理
有些错误信息可能非常长(比如一个编译错误输出了几万行)。如果全部塞进 API 请求,会浪费大量 token(= 浪费钱)。Claude Code 的做法是 保留头尾,截断中间:
前 5000 个字符
...
[中间 N 个字符被截断]
...
最后 5000 个字符
这样 Claude 能看到错误的开头(通常是错误类型)和结尾(通常是最终原因),中间的重复信息被省略。
六、三层协同工作流
用一个完整的例子串联三层防护:
用户: "帮我修复 login.ts 中的 bug"
┌─ Claude 决定读取文件 ─┐
│ │
│ API 调用 #1 │
│ → 429 限流 │ ← 第一层:自动重试
│ → 等 0.5s,重试 │
│ → 成功! │
│ │
│ Claude: "FileRead │
│ login.ts" │
│ │
│ 工具执行 │
│ → 文件读取成功 │
└───────────────────────┘
┌─ Claude 决定修改文件 ─┐
│ │
│ API 调用 #2 │
│ → 成功 │
│ │
│ Claude: "FileEdit │
│ login.ts" │
│ │
│ 工具执行 │
│ → 用户点击"拒绝" │ ← 第三层:权限被拒绝变成 tool_result
│ → 返回拒绝消息 │
└───────────────────────┘
┌─ Claude 收到拒绝消息 ─┐
│ │
│ API 调用 #3 │
│ → 500 服务器错误 │ ← 第一层:自动重试
│ → 等 0.5s,重试 │
│ → 500 │
│ → 等 1s,重试 │
│ → ... (10 次都失败)│
│ → 重试全部用完 │ ← 第二层:转为错误消息
│ │
│ → 显示: │
│ "API Error: 500 │
│ Internal Server │
│ Error" │
│ │
│ (对话可以继续) │
└───────────────────────┘
七、设计哲学总结

一句话总结:Claude Code 的错误处理哲学是 **错误不上浮,就地消化为消息,**API 错误变成 assistant 回复,工具错误变成 tool_result。不管哪里出错,对话都能继续,程序永远不崩溃。