
一个会“反省”的 Agent!

前阵子翻 GitHub 的时候,偶然看到一个叫 Memento的项目。
一开始没当回事,以为又是个 Skill 管理框架。但点进去一看,发现它做了一件很有意思的事:Agent 每执行完一个步骤,都会停下来“反省”:刚才做对了什么?做错了什么?下次怎么改?
它的核心机制很简单:
执行步骤 → 检测结果 → 反思分析 → 修复 skill → 重试
每次执行后,Agent 都会调用 LLM 分析刚才的执行结果。如果发现问题,它会尝试修改 skill 的定义文件(SKILL.md),然后重新执行。这个循环可以持续多轮,直到成功或达到重试上限。
关键在于,Memento 把“反思”作为执行流程的一部分。失败不是终点,而是学习的起点。每次失败都会触发一次自我诊断,系统会问自己:
- 是参数传错了吗?
- 是依赖没装吗?
- 是路径变了吗?
- 还是 API 限流了?
然后根据诊断结果,自动修改 skill 配置,再试一次。
看完之后我就在想:我们的 OpenClaw 能不能也这样?
Skill 的尴尬现状
说实话,OpenClaw 的 Skill 系统现在就是个“一次性选手”。
跑一个数据爬取的 Skill,路径找不到:失败。参数传错了:失败。依赖没装:还是失败。然后呢?没有然后了。你得自己去翻 session 日志,一行一行看是哪出了问题,手动改完再跑一遍。
每次失败都是孤立事件。上周踩的坑,这周还会再踩一遍。系统不记得,也学不会。
这就是我们想改的:让 Skill 不再“执行完就忘”,而是能从失败里学到东西。
切入点:Hook
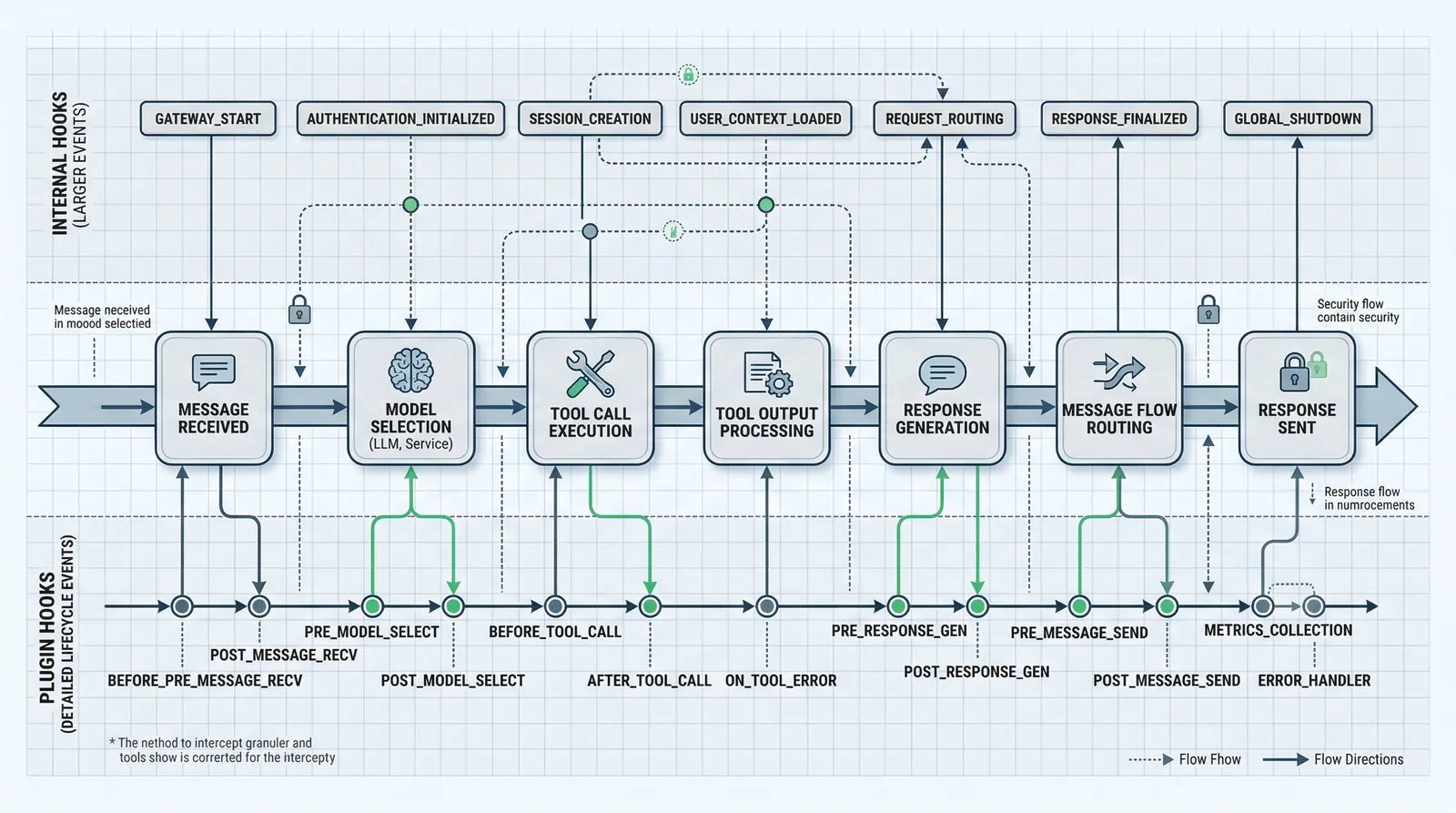
要让 Skill 学会反思,首先得有个“观察点”——在它执行的时候,能看到它做了什么、成功还是失败、花了多长时间。
OpenClaw 正好有这个东西:Hook 系统。而且不止一套,是两套。
第一套:Internal Hooks
这套 Hook 管的是“大事件”。用户敲了 /new、Agent 启动了、Gateway 上线了、消息收发了——这些节点都能挂钩子。
每个 Hook 就是一个目录,里面放一个 HOOK.md 描述它是干嘛的,再放一个 handler.ts 写具体逻辑。系统启动时会自动扫描三个位置:先看 workspace 里有没有,再看全局目录,最后看内置的。
OpenClaw 自带了几个挺实用的:session-memory 在你开新会话时自动保存上一轮的上下文;command-logger 把所有命令记到审计日志;boot-md 在 Gateway 启动时跑一段初始化脚本。
但这套 Hook 的粒度太粗了。它能告诉你“Agent 启动了”,但没法告诉你“某个工具调用失败了”。
第二套:Plugin Hooks
这才是真正深入到执行细节的那套。
Plugin Hooks 运行在 Agent 循环内部,能拦截到几乎所有关键节点。OpenClaw 定义了 20+ 个生命周期钩子,覆盖了从模型选择到工具调用、从会话管理到消息收发的完整流程。
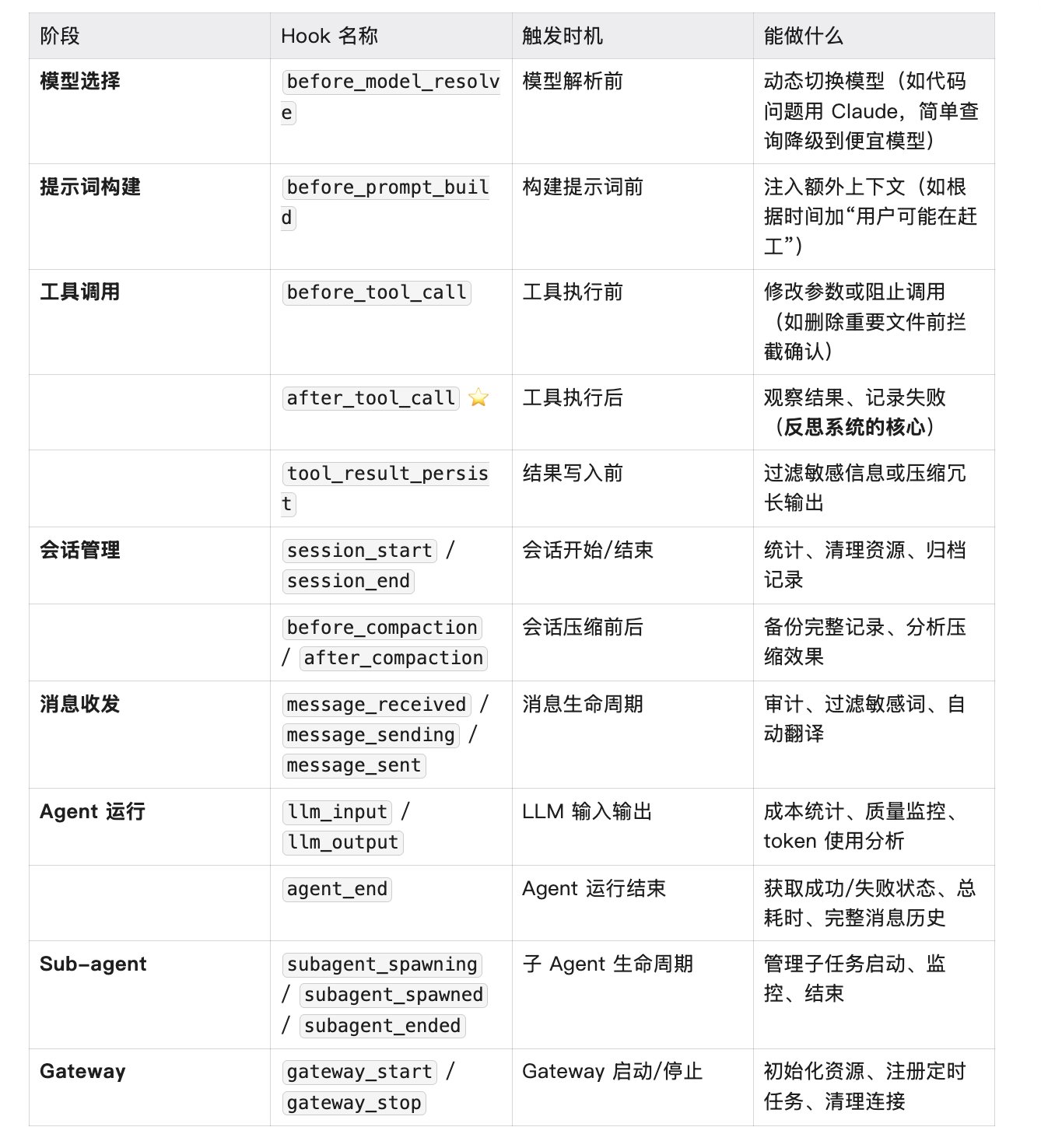
这 20+ 个钩子构成了一个完整的观察网络。每个关键节点都能被拦截、被记录、被修改。
而对于反思系统来说,after_tool_call是最核心的那个。它能拿到这些信息:

工具名、参数、结果、错误信息、耗时——全都有。成功了能看到返回值,失败了能看到错误原因。这就是我们要的“观察点”。
意外发现
本来只是想用 after_tool_call 来监控 Skill 的执行情况。但写着写着发现,这个 Hook 监听的是所有工具调用,不只是 Skill。
这一下子打开了思路。
回头看我们踩过的那些坑:
3 月 22 号,生产脚本改了没做端到端测试,全天输出垃圾数据,当时还以为是 Nitter 限流,折腾了一整天才发现是参数验证的问题。
3 月 21 号更离谱,一个端口配错了,4 个 Agent 全部瘫痪,停了 几个小时。还有 Twitter 爬虫用的 tweety-ns 库,三天两头失效,每次都是出了问题才去救火。
如果当时有 after_tool_call 在默默记录,这些问题本可以更早被发现。
方案:记录→分析→修复→沉淀
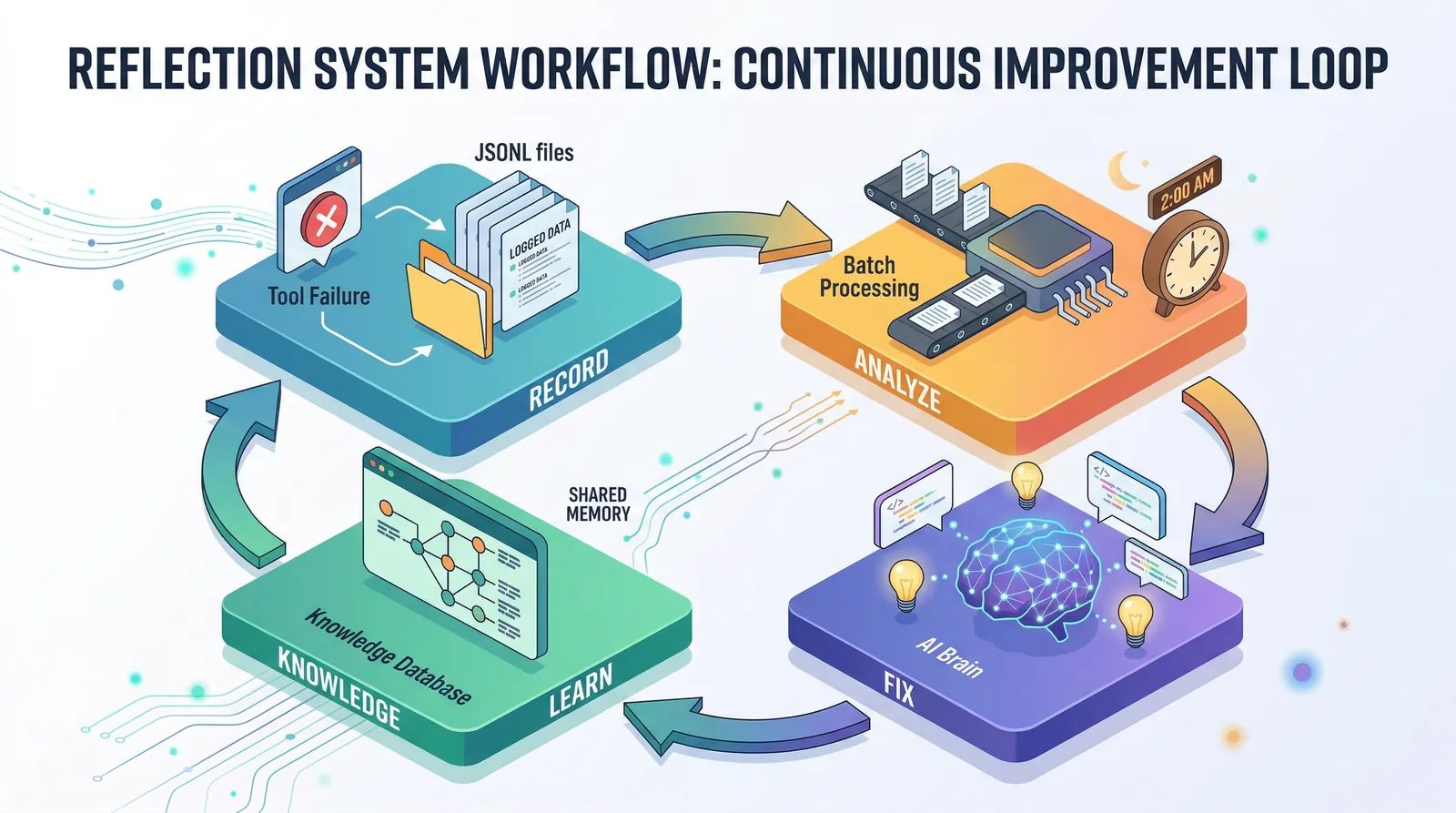
想清楚之后,方案其实很直接。但在动手之前,我们先要回答一个问题:实时反思还是延迟分析?
Memento 选的是实时反思——每次失败立刻调用 LLM 分析、修复、重试。这在演示场景下很酷,但放到生产环境就有问题了:
- 成本高:每次工具调用失败都要调 LLM,一天下来可能几十次
- 阻塞主流程:分析需要时间,用户得等
- 视角窄:单次失败可能是偶发,看不到跨 session 的模式
我们选了延迟分析:失败时只记录,凌晨批量分析。这样做的好处是:
- 成本低:批量分析比单次便宜 10 倍
- 不阻塞:记录是异步的,不影响响应速度
- 模式发现:能看到“这个 API 今天失败了 10 次”这种系统性问题
架构长这样:

第一步:记录失败
Hook 的实现很简单,核心就是“检测失败 → 写日志”:

关键点:
- 异步写入:不阻塞主流程
- 按日期分片:方便批量分析
- 参数脱敏:移除 token、密码等敏感信息
第二步:批量分析
凌晨 Cron 任务读取昨天的失败记录,先做聚合统计:

然后把这些数据喂给 LLM:
分析这些失败记录,找出:
- 最常见的失败模式
- 可能的根本原因
- 具体的修复建议
失败记录:
[昨天的 JSONL 数据]
LLM 会返回类似这样的分析:

第三步:生成报告
把统计数据和 LLM 分析整合成一份报告:

第四步:沉淀经验
修复后的经验写入 shared-knowledge(我们的工蜂共享知识库):
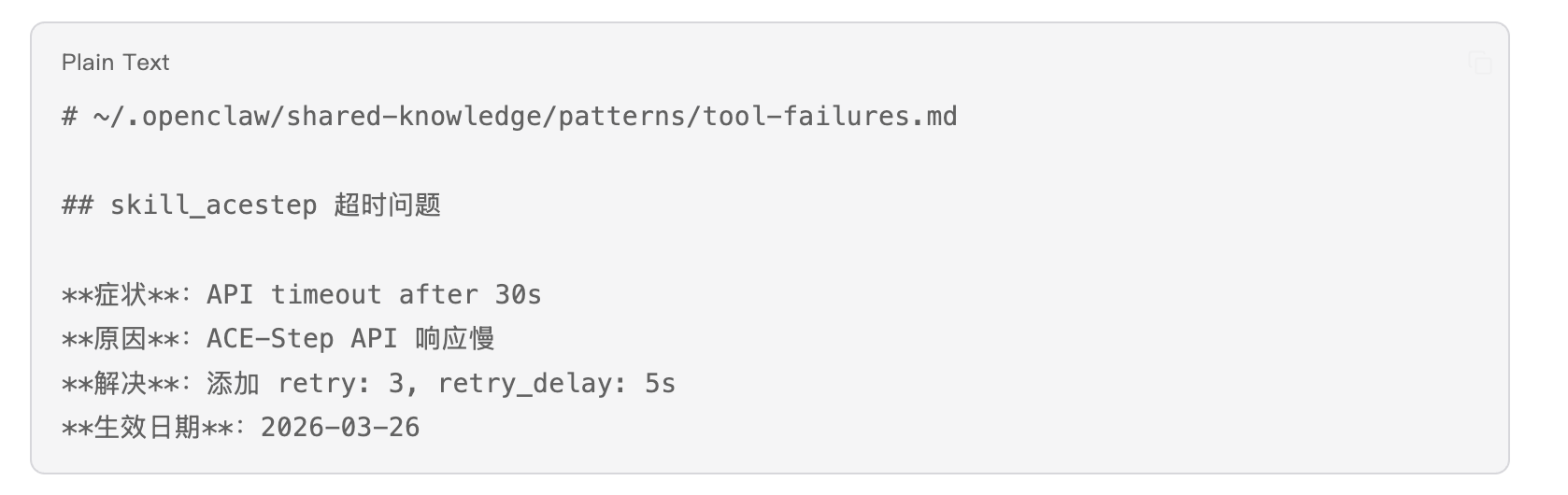
下次遇到类似问题,系统能直接调用这条经验。
这样就形成了一个闭环:失败 → 记录 → 分析 → 修复 → 沉淀 → 下次避免。每次失败都不再是白费的,它会变成系统的一部分智慧。
下一步
从 Memento 的一个简单想法出发,我们找到了 Hook 这个切入点,又意外发现它的能力远超预期。
OpenClaw 正在从一个执行工具,变成一个会从错误中学习的系统。
下一篇,我们会放出反思系统上线后第一周的真实数据。到时候再看,这套东西到底有没有用。