
AI Agent 记忆系统的困境

你的 AI Agent 每次重启都会"失忆"。
这不是 LLM 的问题,而是记忆系统的缺失。当你在笔记本上告诉 Agent "我喜欢喝咖啡",切换到服务器后,它完全不记得。当你用 OpenClaw 记录了 100 条偏好,换到 Claude Code,一切归零。
更糟糕的是:
- 多个 Agent 无法共享记忆(每个都要重新学习你的习惯)
- 跨设备无法同步(笔记本和服务器是两个世界)
- 跨框架无法迁移(OpenClaw 的记忆,Claude Code 读不到)
这就是 AI Agent 记忆系统的现状:碎片化、孤岛化、不可迁移。
现状分析:以 OpenClaw 原生记忆为例

OpenClaw 内置了一套简单的记忆系统:

优点:
- ✅ 开箱即用,0 配置(hook自动通过skill注入非常好用!)
- ✅ 纯文本存储,易于理解和调试
- ✅ 完全本地,无隐私担忧
局限:
- ❌ 本地存储:换台电脑就失效
- ❌ 单机限制:无法跨设备同步
- ❌ 框架绑定:只能在 OpenClaw 内使用
- ❌ 无结构化:难以支持复杂查询(如时间范围、标签过滤)
结论:OpenClaw 原生记忆适合单机、单 Agent 的简单场景,但无法满足跨平台、多 Agent 协作的需求。
市场上最知名的两个方案:MemOS 和 OpenViking
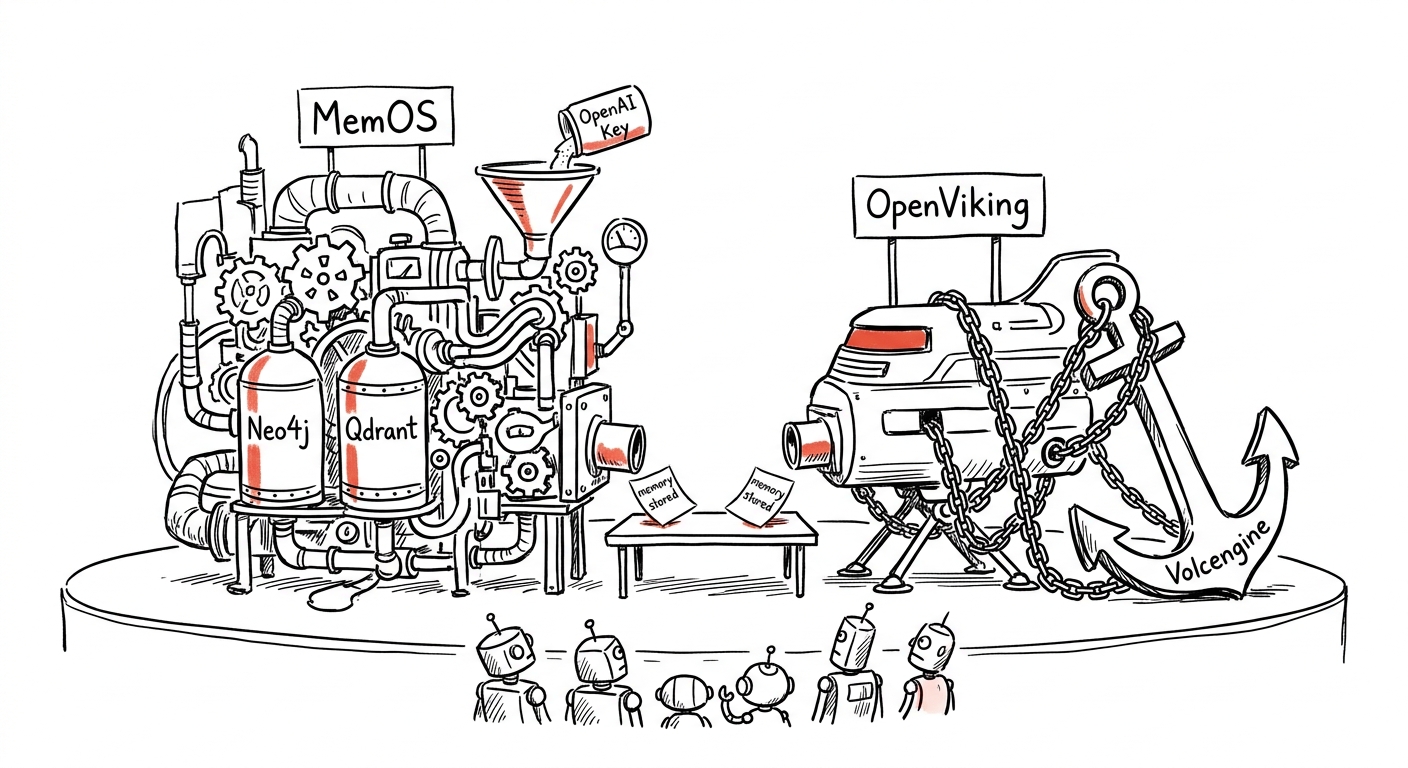
面对这些问题,社区出现了两个主流方案:
3.1 MemOS:功能全面的记忆操作系统
核心特性:
- 三层记忆模型(参数记忆、激活记忆、明文记忆)
- 任务摘要自动化(Next-Scene 预测)
- 技能进化系统(从记忆中提炼可复用技能)
技术架构:
- 数据库:Neo4j(图数据库)+ Qdrant(向量数据库)
- Embedding:需要 OpenAI API Key
- 部署:需要自行搭建或使用云端 beta
问题:
- ❌ 部署复杂:需要同时部署数据库(Neo4j + Qdrant)
- ❌ 配置繁琐:需要申请 Key,配置多个环境变量
- ❌ 学习成本高:三层记忆模型需要理解概念
**适合谁:**需要高级功能(任务自动化、技能进化)的重度用户,愿意投入时间学习和部署。
3.2 OpenViking:字节跳动的文件系统范式
核心特性:
- 文件系统范式(L0/L1/L2 三层加载)
- 目录递归检索(黑盒变白盒)
- 可视化记忆轨迹
技术架构:
- 数据库:VikingDB(字节跳动出品)
- 部署:需要 Volcengine 账号
问题:
- ❌ 账号门槛:注册 Volcengine 账号(需要实名认证)
- ❌ 生态绑定:依赖字节跳动的云服务
- ❌ 集成成本:需要开发 OpenClaw 插件
**适合谁:**已经在使用字节跳动云服务的团队,或者需要企业级支持的用户。
灵魂拷问:你愿意花多少时间在"记忆"上?

看完前面的方案,你可能会
"我只是想让 Agent 记住我的偏好,为什么这么复杂?"
如果你需要:
- ✅ 零门槛启动:不想折腾复杂的注册和配置流程
- ✅ 跨平台统一:笔记本、服务器、多个 Agent 共享同一份记忆
- ✅ 免运维:不想自己部署数据库、管理备份、监控健康
- ✅ 企业级可靠:数据不能丢,性能要稳定
那么,前面的方案都不够好:
- OpenClaw 原生:本地存储,无法跨平台
- MemOS:部署复杂,需要管理两个数据库
- OpenViking:需要 Volcengine 账号,生态绑定
这就是 mem9 要解决的问题。
mem9:2 分钟安装的跨平台记忆中枢
mem9 的设计哲学很简单:
"让 AI Agent 的记忆系统,像用 Google Docs 一样简单。"
核心特性:
5.1 零门槛启动(2 分钟上手)
有多简单?给你的 OpenClaw Agent 发一句话就行:
阅读 mem9.ai/SKILL.md ,按照说明为 OpenClaw 安装并配置 mem9
Agent 会自动完成所有步骤:创建 API Key、安装插件、写入配置、重启生效。
✅ 完成 - 立即可用
记住:我喜欢喝咖啡
✅ 已记录到 mem9
无需你手动操作:
- ❌ 注册账号
- ❌ 配置环境变量
- ❌ 部署数据库
- ❌ 管理 Embedding 模型
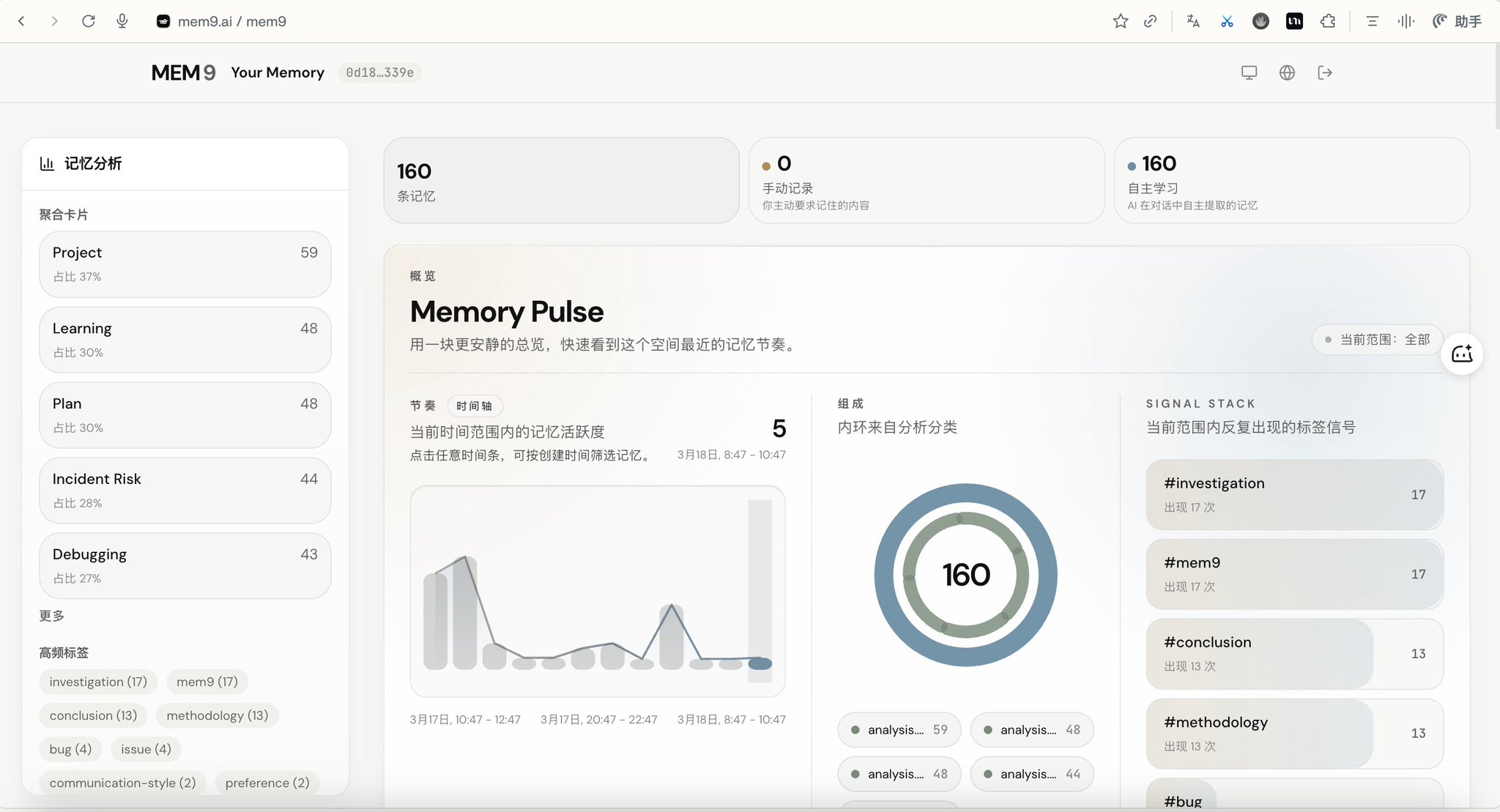
最让我惊讶的是,这个界面真好看! 通过API Key,登陆:mem9.ai/your-memory/space
Agent 读完 SKILL.md 后还会自动接入生命周期钩子(如 before_reset 自动保存 session 摘要、agent_end 自动捕获对话内容),实现真正的"装完即忘"。
5.2 跨平台统一(一处配置,处处可用)
场景 1:笔记本 + 服务器无缝切换
笔记本上(OpenClaw)
openclaw.json 配置 mem9 API Key
记住:我喜欢喝咖啡
✅ 已记录
服务器上(另一台机器)
配置同一个 mem9 API Key
我喜欢喝什么?
✅ 咖啡(从 mem9 读取)
场景 2:多 Agent 共享记忆
Agent A(OpenClaw)
记住:项目代码在 ~/my-project
Agent B(同一个 API Key)
项目代码在哪?
✅ ~/my-project(从 mem9 读取)
场景 3:跨框架迁移
从一台机器迁移到另一台
无需导出/导入,配置同一个 API Key 即可恢复全部记忆
技术实现:
- API Key 是全局唯一标识符,绑定一个 mem9 记忆空间
- OpenClaw 官方插件支持
- REST API 设计,任何语言都能接入
5.3 免运维(云端托管)
基于 mem9 云端服务:
- 用户通过 REST API(api.mem9.ai)读写记忆
- 无需自行部署任何数据库
- 自动管理存储和检索,用户无需关心底层实现
你不需要:
- ❌ 部署数据库(mem9 云端托管)
- ❌ 管理备份(云端自动处理)
- ❌ 监控健康(GET /healthz 即可检查服务状态)
- ❌ 管理 Embedding 模型(服务端内置)
深入对比:技术架构
6.1 数据库选型
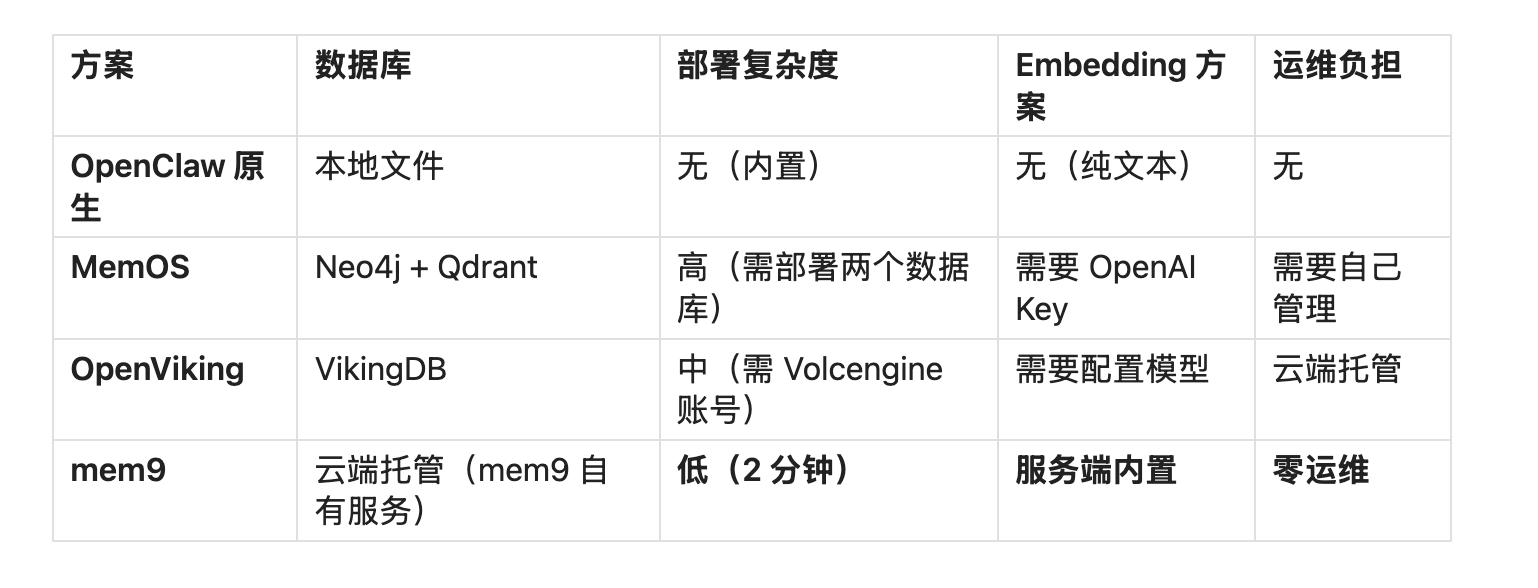
mem9 的优势:
- 云端托管,用户通过 REST API 读写,无需关心底层数据库
- 服务端 Embedding,无需管理 API Key 或部署模型
- 一条命令创建 API Key,即刻可用
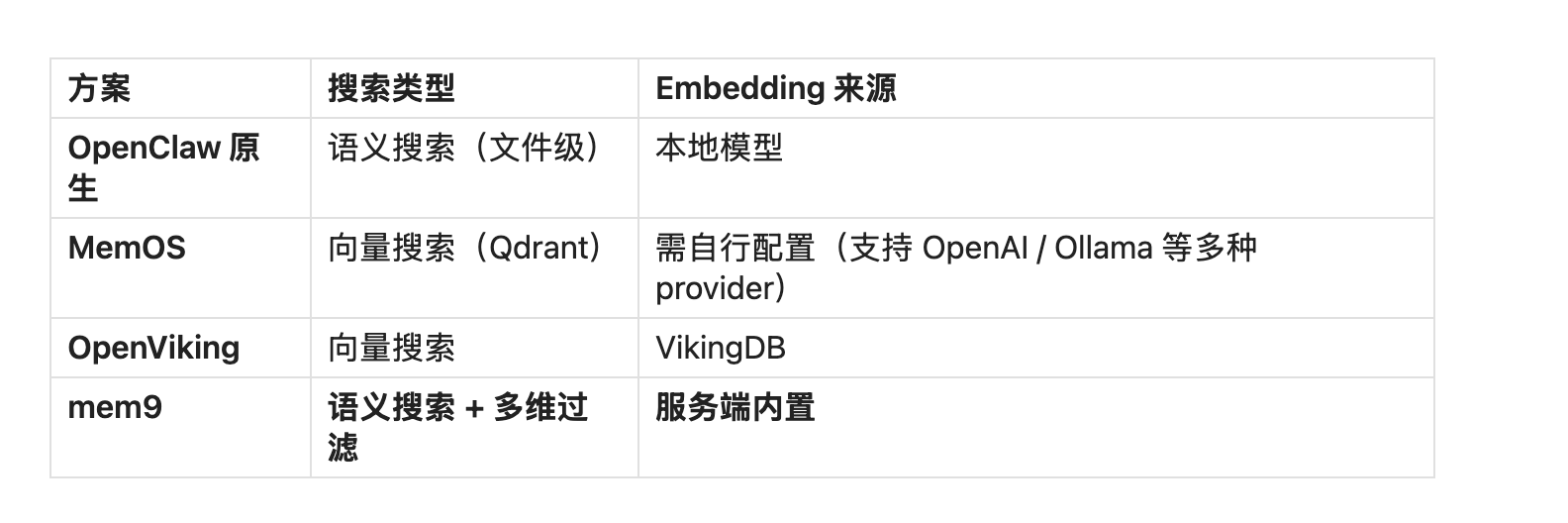
6.2 搜索能力
mem9 的搜索与注入方式:
mem9 通过 REST API 提供搜索能力,支持关键词与语义匹配,以及标签/来源过滤:
语义搜索
curl -s -H "X-API-Key: $API_KEY" \
"api.mem9.ai/v1alpha2/mem9s/memories?q=咖啡&limit=5"
按标签过滤
curl -s -H "X-API-Key: $API_KEY" \
"api.mem9.ai/v1alpha2/mem9s/memories?tags=偏好&limit=5"
按来源过滤
curl -s -H "X-API-Key: $API_KEY" \
"api.mem9.ai/v1alpha2/mem9s/memories?source=agent-1&limit=5"
插件端注入限制(源码确认):
- 用户输入 < 5 字符时跳过搜索(如"ok"、"好"不触发)
- 每次最多注入 10 条记忆(MAX_INJECT = 10)
- 每条记忆内容截断到 500 字符(MAX_CONTENT_LEN = 500)
- 无分数门槛:服务端返回的结果全部注入,不做二次筛选
技术特性:
- ✅ 语义搜索(服务端内置 Embedding,无需自行管理模型)
- ✅ 多维过滤(支持 q、tags、source、limit 参数组合)
- ✅ 无需 OpenAI Key(mem9 服务端处理 Embedding)
- ⚠️ 检索质量完全依赖服务端排序,插件端零过滤
对比其他方案:
6.3 记忆模型
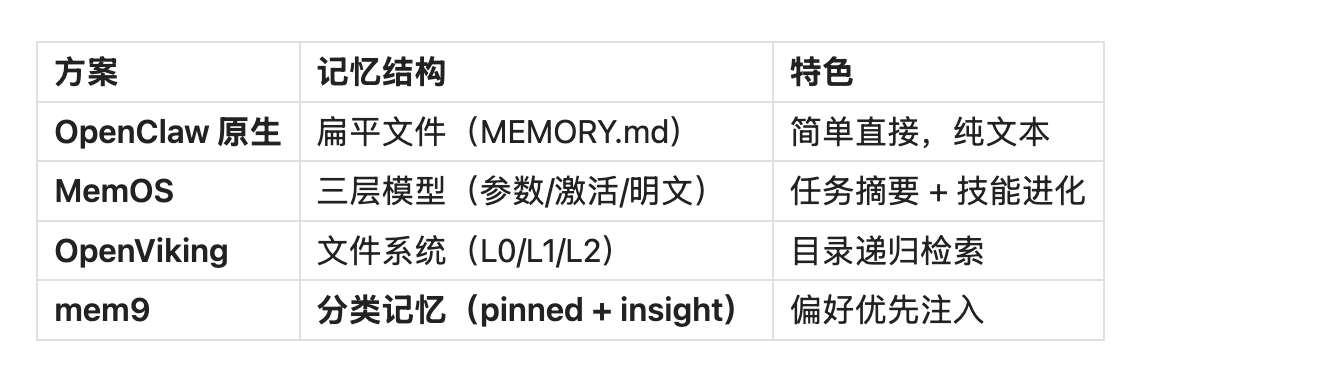
mem9 的记忆分类:
mem9 的记忆分类由服务端 LLM 自动完成(小bug目前插件端不暴露 memory_type 字段,估计以后会迭代):
- 服务端自动将记忆标记为 pinned(偏好)或 insight(知识)
- 注入时按分类分组:[Preferences] 排在最前,[Knowledge] 排在其后
- 注入顺序:偏好 → 知识 → 其他,确保 LLM 优先看到用户偏好
- Agent 无需手动指定类型,一切由服务端智能判断
6.4 自动捕获机制
mem9 通过 agent_end 钩子实现对话记忆的自动捕获:
- 每次对话结束后自动触发
- 从对话末尾倒着选消息,总量不超过 200KB(DEFAULT_MAX_INGEST_BYTES),最多 20 条(MAX_INGEST_MESSAGES)
- 自动剥离之前注入的
块,防止记忆"套娃" - 发送到服务端走 mode: "smart" 智能提取,由服务端 LLM 决定哪些值得记住
6.5 跨平台能力
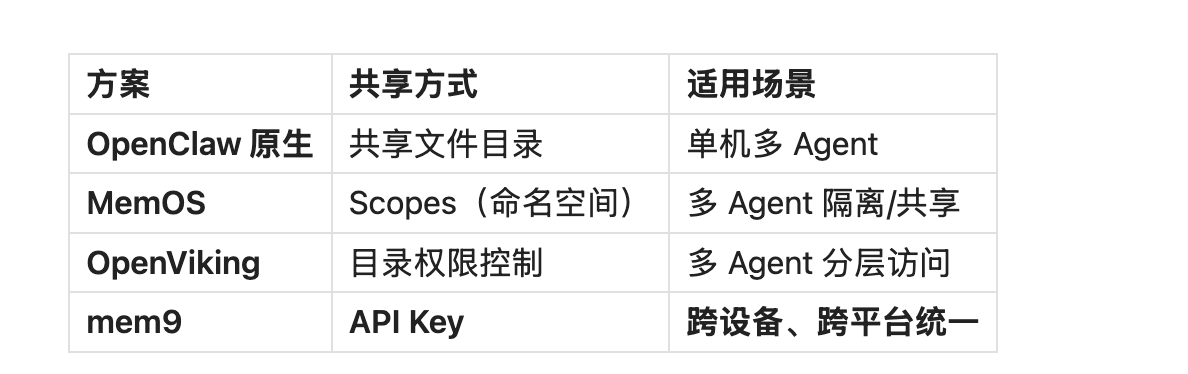
mem9 的杀手锏:真正的跨平台统一
- OpenClaw 官方插件支持
- REST API 设计,任何语言都能接入
- 同一个 API Key,多设备、多框架无缝共享
被忽视的杀手锏:LLM 自动语义标签如何让记忆"活"起来

前面六章讲的都是"怎么存、怎么搜"。但有一个问题被所有方案忽略了:
记忆存进去之后,凭什么能在对的时候被找到?
答案是标签。没有标签的记忆就像没有索引的书——内容再好,翻不到就等于没有。
7.1 传统方案的困境:标签靠人打
MemOS 云端版的 add_message 接口有 tags 字段,但那是写入时由调用方手动指定的。这意味着:
- 开发者需要提前设计标签体系
- 每次写入都要决定"这条记忆该归到哪个标签"
- 标签粒度不一致(有人写"咖啡",有人写"饮品偏好")
- 时间一长,标签体系必然混乱
MemOS 本地版更直接——依赖 FTS5 全文检索 + 向量检索的 RRF 融合,根本没有自动标签能力。检索全靠向量相似度,没有语义层面的分类辅助。
7.2 mem9 的做法:后端 LLM 全自动
mem9 把标签提取交给了服务端 LLM,整个过程零人工介入:
- 对话结束后,插件通过 agent_end 钩子将对话内容发送到服务端
- 服务端 LLM 自动分析对话语义,提取标签(如"咖啡偏好"、"项目架构"、"TypeScript 习惯")
- 同时进行高频主题统计,识别用户长期关注的核心领域
- 标签和分类信息附着在每条记忆上,成为搜索时的额外维度
用户零操作、零配置。你只管和 Agent 聊天,mem9 在后台默默把你的记忆整理得井井有条。
7.3 语义标签的真正价值:提高命中率,赋予记忆权重
为什么这件事这么重要?因为语义标签解决了纯向量搜索的两个致命问题:
问题一:向量搜索的"语义漂移"
纯向量搜索依赖 Embedding 的余弦相似度。但 Embedding 模型不是万能的——"我喜欢喝美式咖啡"和"推荐一家咖啡店"在向量空间里可能很近,但语义完全不同。前者是偏好,后者是请求。
有了语义标签,搜索时可以先按标签缩小范围("咖啡偏好"),再在范围内做向量匹配。标签充当了第一层过滤器,大幅减少误召回。
问题二:所有记忆"一视同仁"
没有标签的系统里,一条随口提到的"今天喝了杯拿铁"和一条认真表达的"我只喝美式,不加糖"在检索时权重完全相同。
语义标签让记忆有了隐性权重:
- 被标记为 pinned(偏好)的记忆,注入时排在 [Preferences] 区域,LLM 优先看到
- 被标记为 insight(知识)的记忆,注入时排在 [Knowledge] 区域
- 高频出现的标签(比如用户反复提到"TypeScript"),意味着这是核心关注领域,相关记忆的实际召回概率更高
这不是简单的分类,而是让记忆系统具备了"什么更重要"的判断力。
7.4 对比总结

一句话总结:mem9 让记忆不只是"存了",而是"存对了、找得到、分得清轻重"。
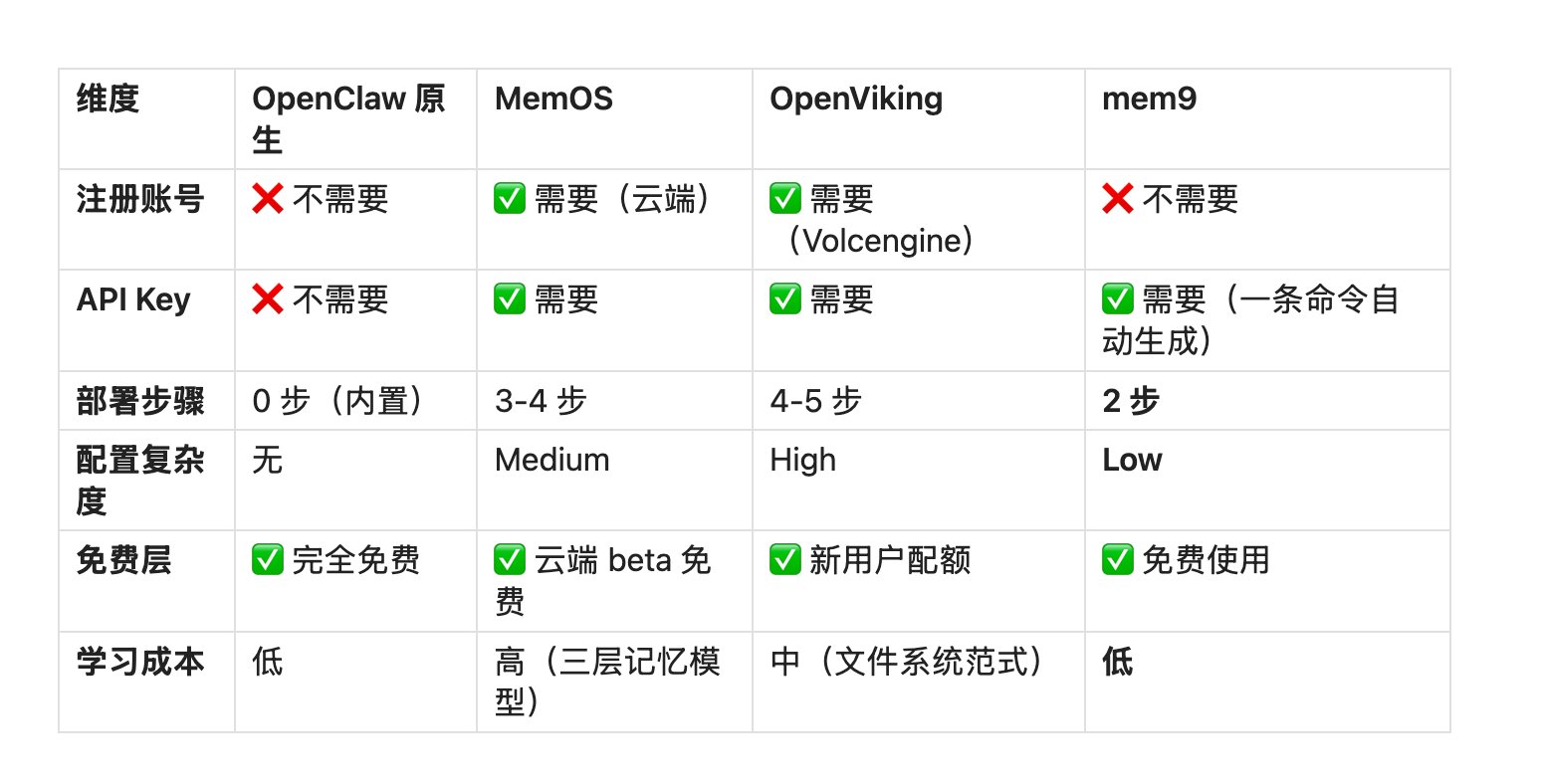
启动门槛对比

决策树:你该选哪个?
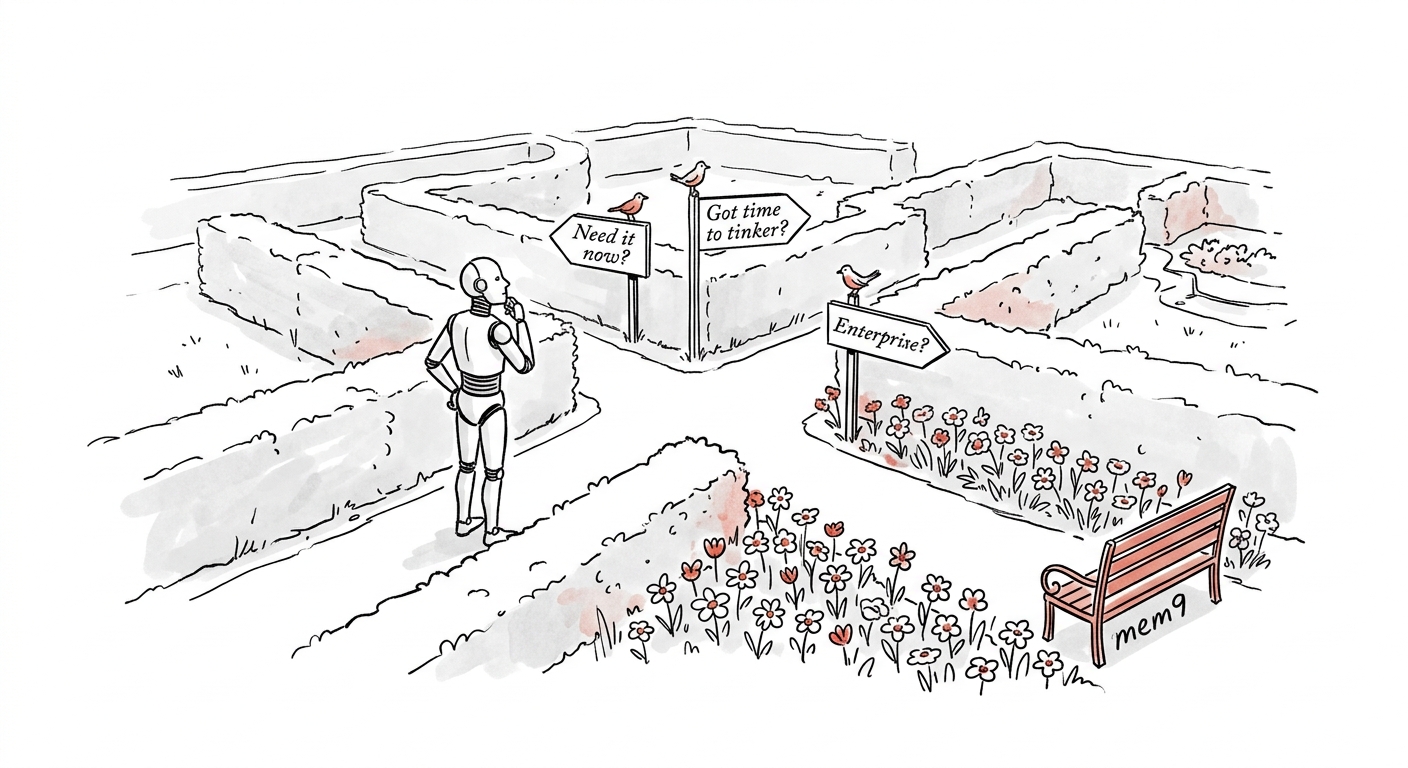
你需要 AI Agent 记忆系统吗?
│
├─ 只需要单机、单 Agent
│ └─ 选择:OpenClaw 原生记忆(开箱即用)
│
├─ 需要高级功能(任务自动化、技能进化)
│ └─ 选择:MemOS(功能全面,但部署复杂)
│
├─ 已经在使用字节跳动云服务
│ └─ 选择:OpenViking(生态集成)
│
└─ 需要零门槛 + 跨平台 + 免运维
└─ 选择:mem9(2 分钟上手,企业级可靠)
总结:mem9 的三大核心优势

启动最简单:
- 2 分钟完成部署(创建 API Key → 安装插件 → 配置 openclaw.json)
- 无需注册账号,一条 curl 命令即可生成 API Key
- 免费使用,个人开发者长期零成本
跨平台最完整:
- OpenClaw 官方插件支持
- REST API 设计,任何语言都能接入
- 同一个 API Key,多设备、多框架无缝共享
技术最省心:
- 云端托管(api.mem9.ai),无需部署任何数据库
- 服务端 Embedding(无需 OpenAI Key)
- 语义搜索 + 多维过滤(tags、source)
mem9 的设计哲学:
"让 AI Agent 的记忆系统,像用 Google Docs 一样简单。"
参考资源
OpenClaw 原生记忆:
MemOS:
- GitHub:github.com/MemTensor/MemOS
- 论文:arXiv:2507.03724
OpenViking:
mem9:
- GitHub:github.com/mem9-ai/mem9