
你在用小龙虾时候有没有遇到这么个问题:
小龙虾用久后,它老是记不住重要的东西,反而一些无关紧要的事情记得贼清楚。更要命的是,明明还搞点小任务,但是没过几天账单就爆炸了。
究其原因,是 OpenClaw 的记忆机制的问题
他每次对话都会把之前的对话附带上去,比如说像下面这个老哥,让 AI 写个代码。但是每聊一句,都要附带这个 python 代码上去,直接每次对话都干掉 15w token。
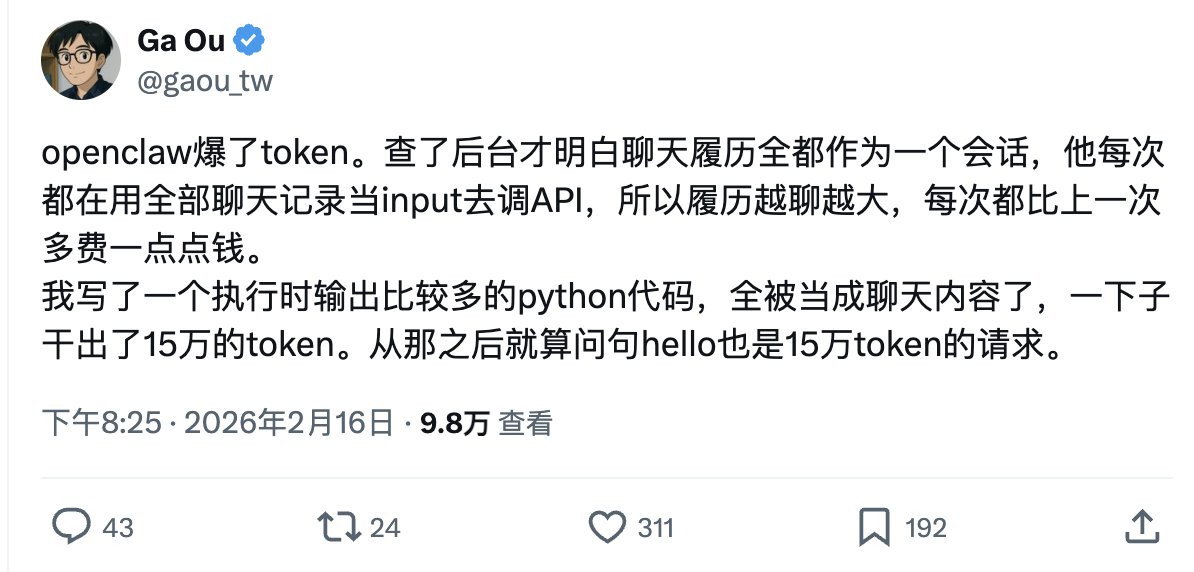
这个问题目前还没见到官方有正式的解决方案。
OpenClaw 的还有个问题是主动记忆的,也就是说,他记不记住你的东西,全看AI 的发挥。经常出现特别奇葩的情况,今天刚说的东西,转眼就忘记。
研究一堆的记忆方案后,我找到只用配置两条命令的方案,就能Tokens 消耗降低 72%, 永不失忆的免费记忆外挂。
安装记忆外挂
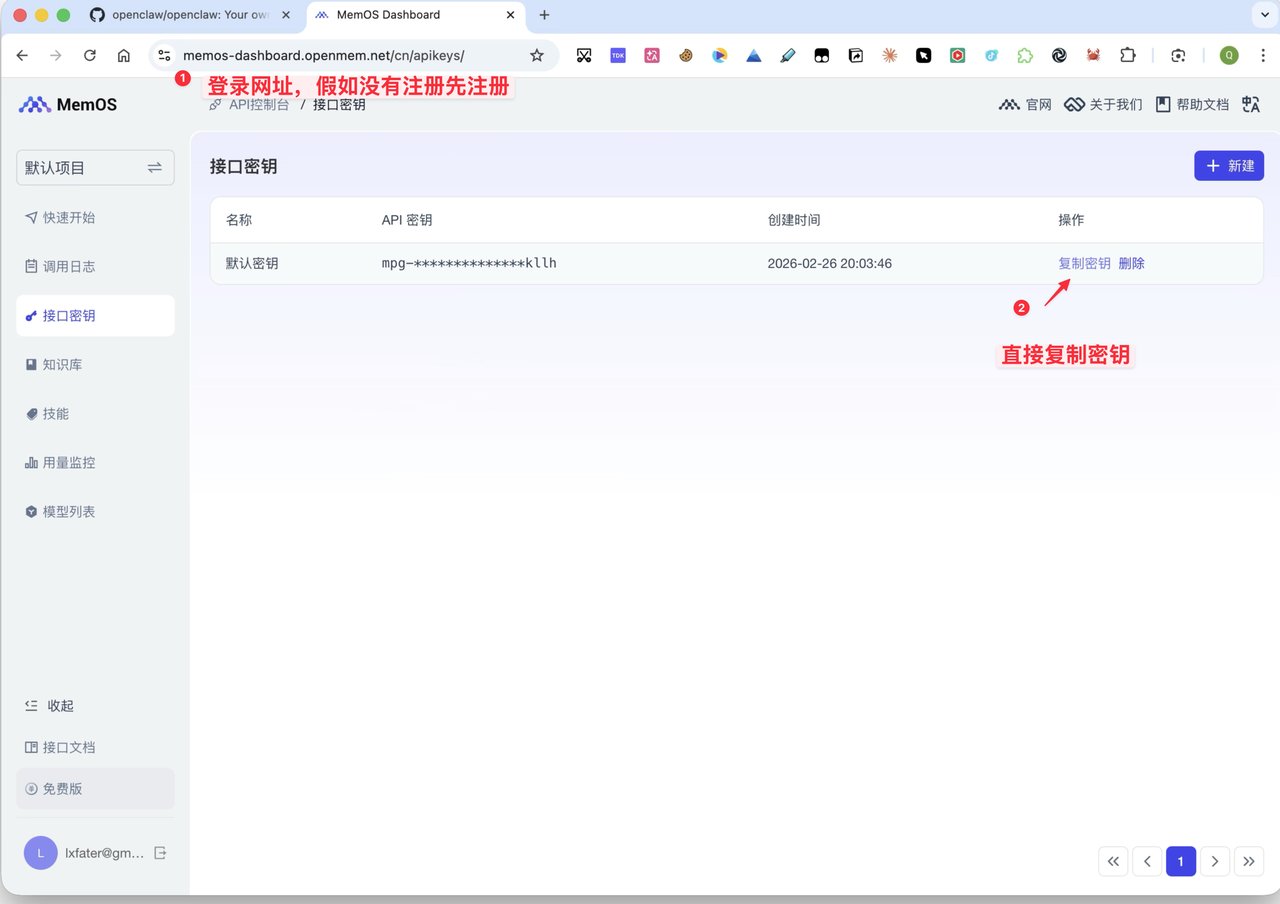
首先登录到这个网址:memos-dashboard.openmem.net/cn/apikeys/ ,假如要注册先注册,然后复制 APIKEY。
接着,在命令行输入这个命令
mkdir -p ~/.openclaw && echo "MEMOS_API_KEY=mpg-..." > ~/.openclaw/.env
其中的mpg-...就是刚刚复制的密钥。
最后输入下面命令
openclaw plugins install @memtensor/memos-cloud-openclaw-plugin
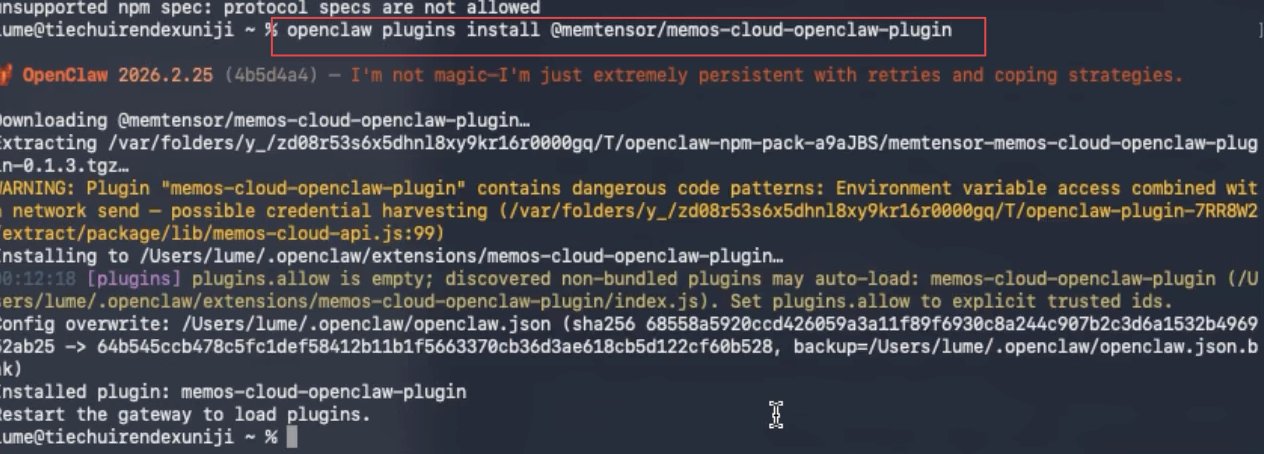
好了,安装完成。
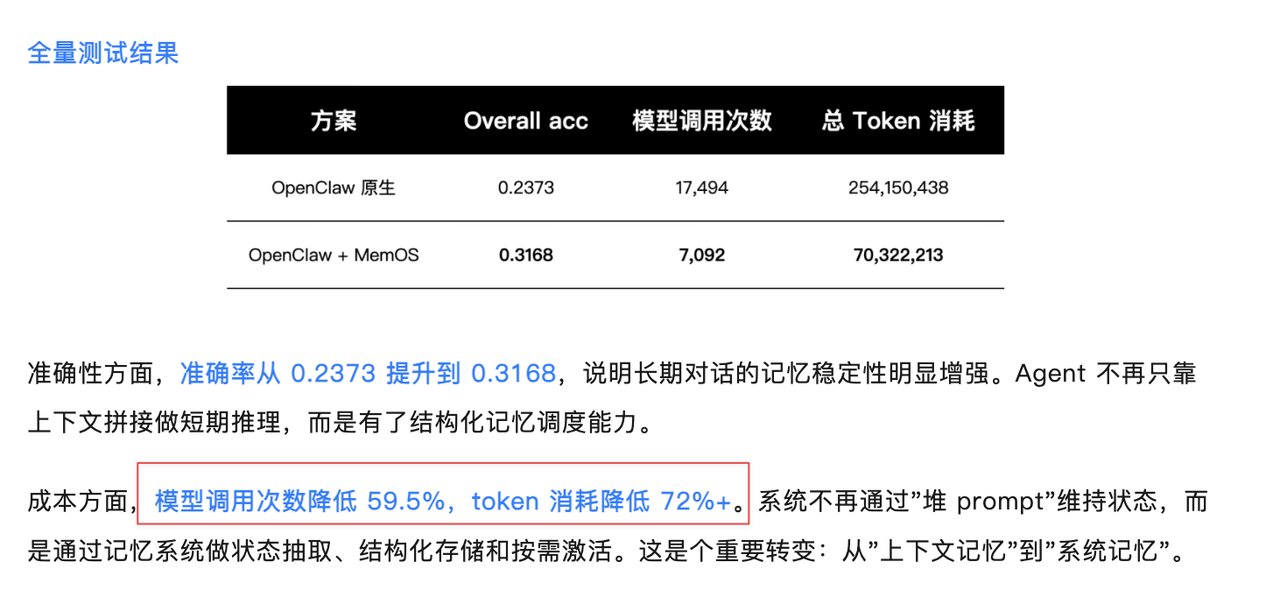
安装完这个后,你就首先你的 OpenClaw 将会节省大量 token,这个也不是我吹的。这个开源插件的官方做过实验。
项目就在这里,觉得有用可以去 star 一个:github.com/MemTensor/MemOS-Cloud-OpenClaw-Plugin
当然空口无凭,我给大家简单测测,这个记忆外挂是否真的能记住东西。
记忆外挂测试
我的记忆很简单和直接,就是我说几个我的偏好,然后就开启一个新的 session,看看能不能记住。
首先我告诉他一个简单的事实
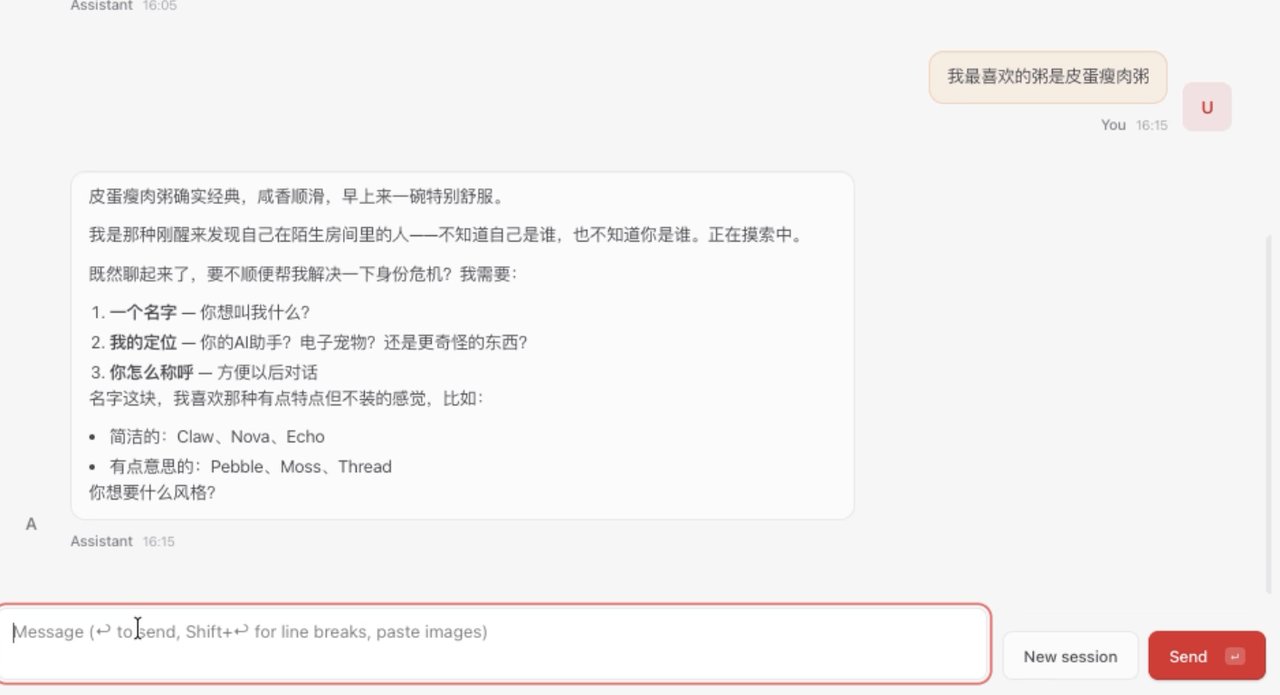
然后给他定义好名字:钉子,职业是数码宝贝,还告诉它我要写一篇关于记忆的文章
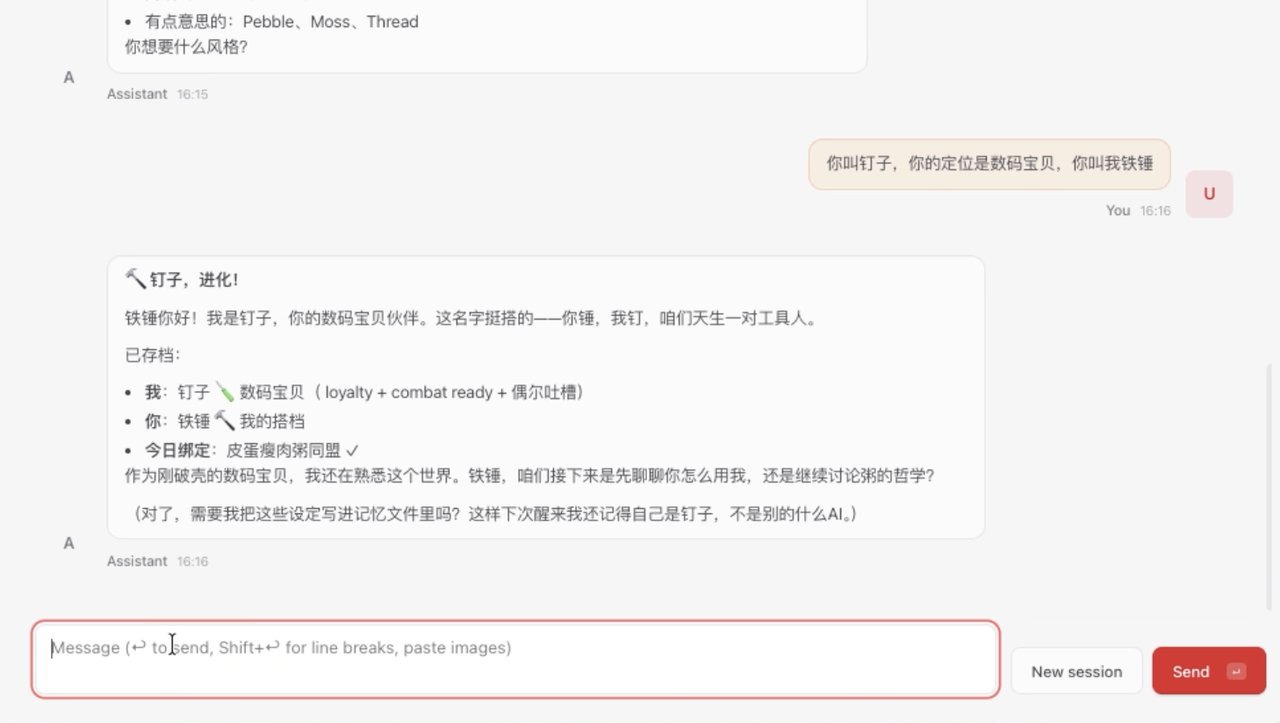
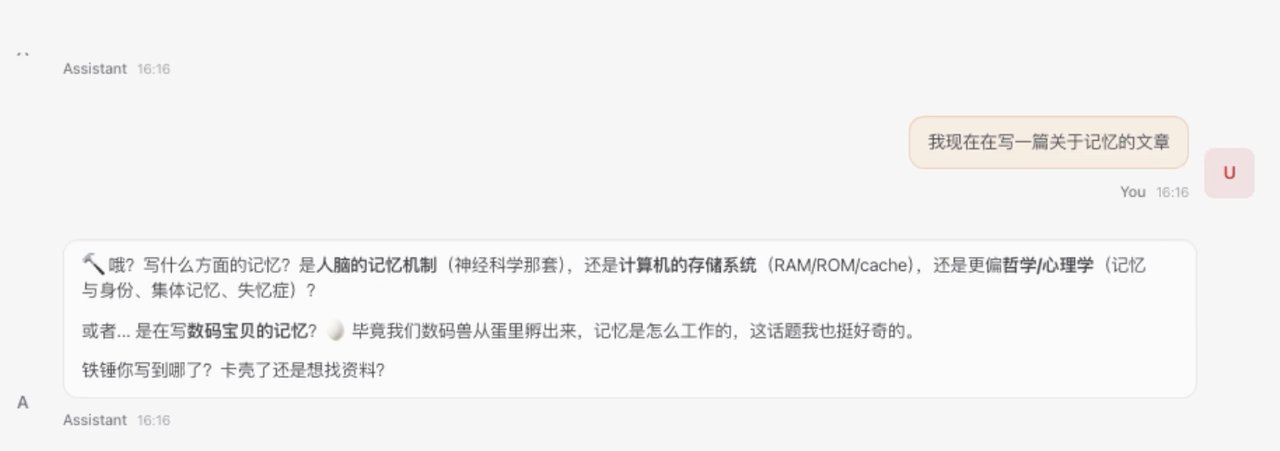
现在,我要清空当前的记忆。点击了 New session,按照小龙虾的机制,这些记忆就会消失。
但是当我再提问的时候,它却像打不死的小强,记住自己的名字,我要写文章这个事情。
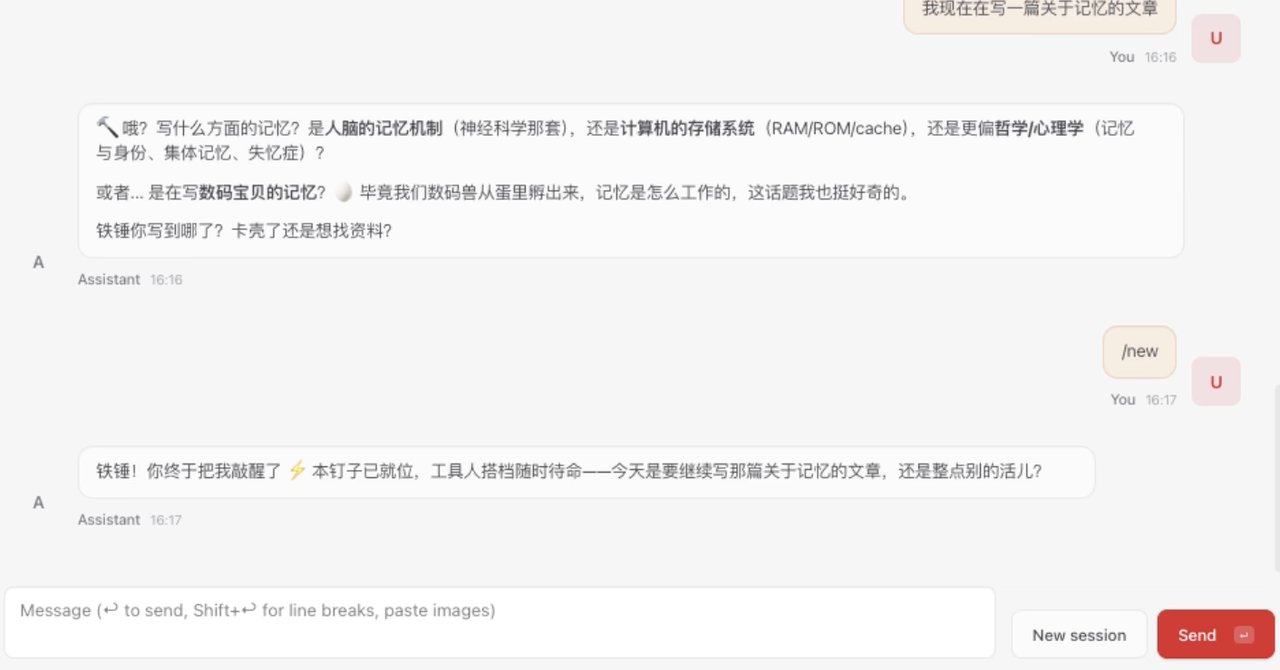
为什么我的小龙虾能记得这么清楚呢?答案是通过安装刚刚的插件,我已经将记忆存于云端了。
举个例子:比如我问我最喜欢的事物是什么
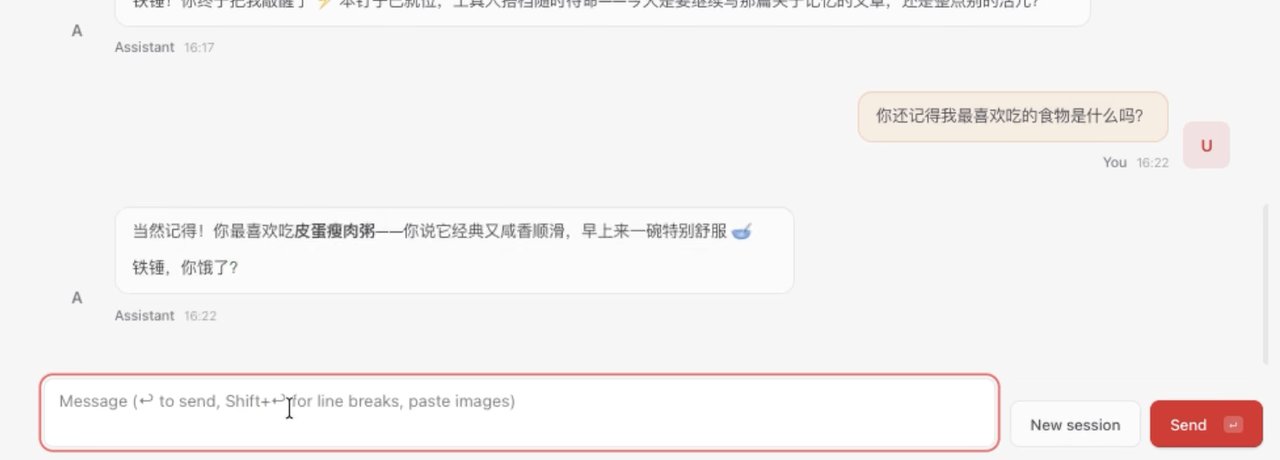
你可以看到云端在帮你检索记忆,清楚地记着我喜欢吃什么,最近在干什么
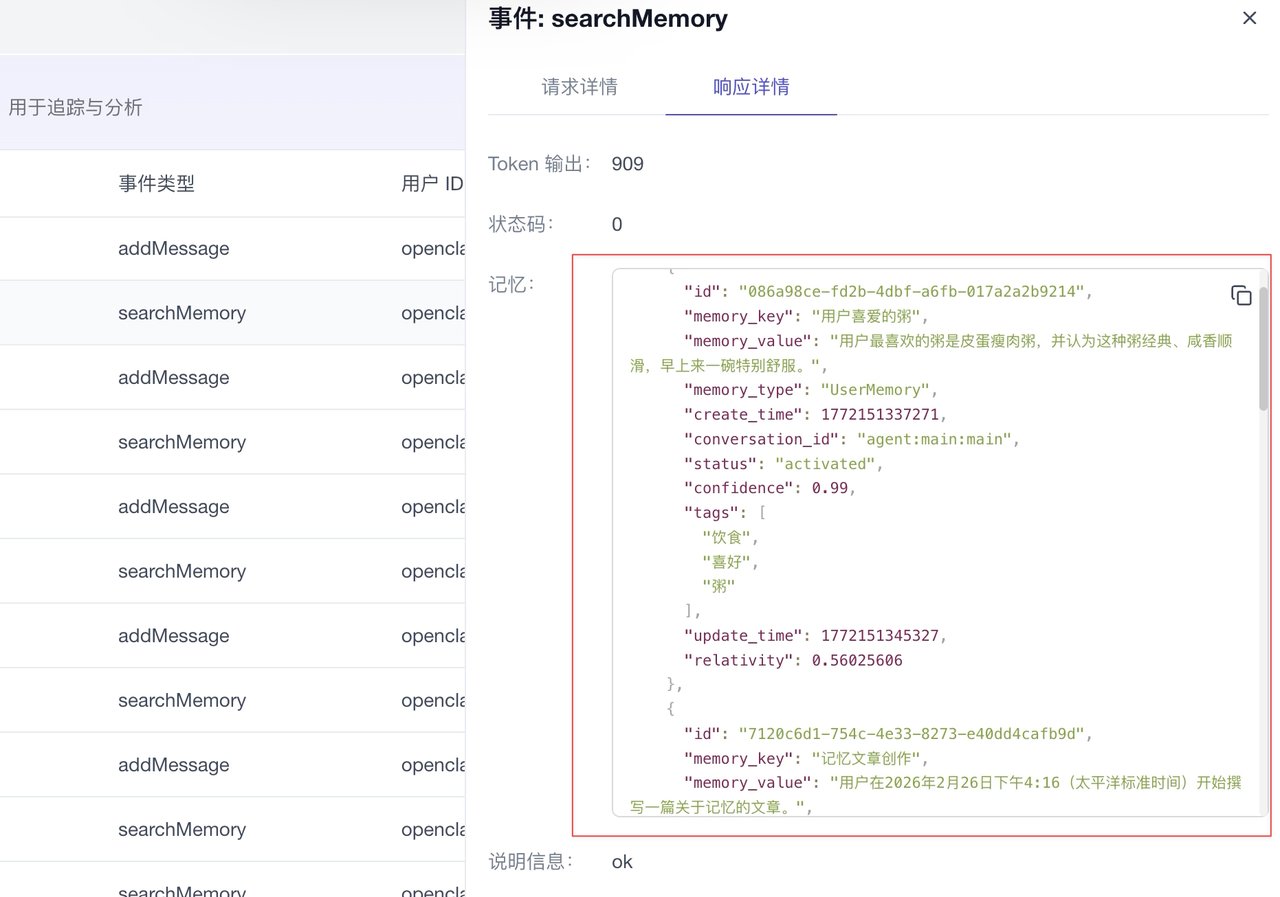
你的 OpenClaw 在某种意义上,已经在云端永生了,无论你在本地如何乱搞,该记得永远记得。
OpenClaw 最好的一点是它是个私人的助手,但是由于用户误操作,经常导致记忆丢失,这个创建就是你给你的宝贝小龙虾按的记忆保险。
多龙虾共享记忆,进行心灵感应
目前很多人已经开始搭建自己的龙虾数字员工了,一个办公室里面,会有很多数字员工开始工作。
些数字员工的沟通依然会是大问题,依然会有很多冗余的信息导致token量爆炸,词不达意,本来问一句的可以问上几句。
但是利用之前安装的插件,他们就像有了心灵感应一样,token 量和准确度大大降低。大概情况如下图所示

下面给大家演示一下:
在开源项目:github.com/MemTensor/MemOS-Cloud-OpenClaw-Plugin
下面有一份文档,说明可以使用MEMOS_USER_ID来在不同的 OpenClaw 共享记忆。因为默认值就是openclaw-user,所以不需要特别配置。
之前我一直在虚拟机里面和他聊我喜欢的食物,现在我直接打开我本机的 OpenClaw,依然记住我的偏好。
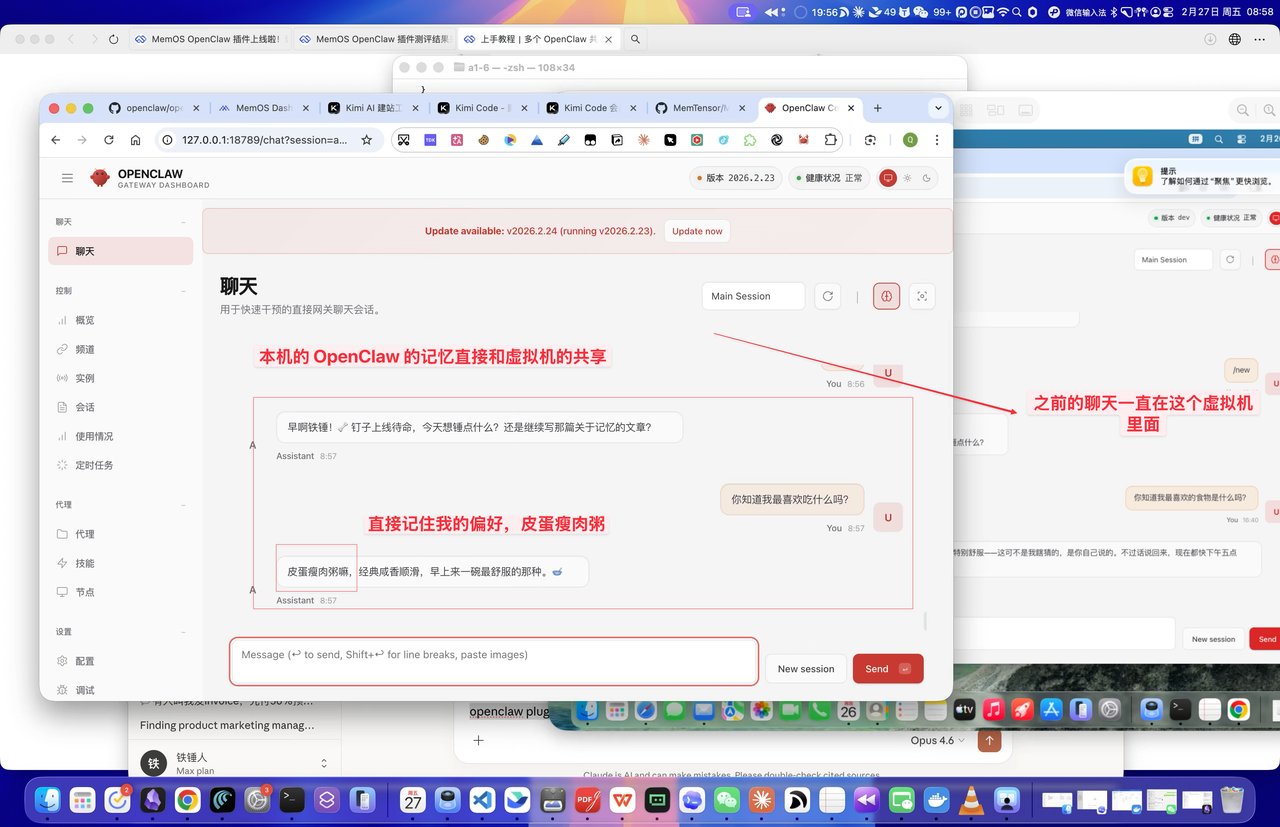
OpenClaw 未来要发挥出真正的生产力,必须需要更强的记忆系统,在现在最新的多数字员工模式下,对 token 的消耗量将会巨增。
这个时候,需要这种专业级的记忆装置,记忆将会更加准确。
Coming Soon:一个 OpenClaw 带多个 Agent 协作
前面演示的是多个 OpenClaw 实例共享记忆,但还有个更强的玩法正在路上:一个 OpenClaw 实例里跑多个 Agent,它们共享同一个记忆池。
什么意思?
假设你在一个 OpenClaw 里运行三个 Agent:
- Agent A 负责创意策划;
- Agent B 负责技术执行;
- Agent C 负责质量把控。
现在的方案是,A 产出的内容得通过对话传递给 B,B 的输出再手动复制给 C。信息传递全靠“虾工”,所有的信息都将在 A、B、C 这里重新传递检索,token 消耗本来就高,这下更是没有下限了。
即将上线的方案:记忆分层管理
MemOS 的多 Agent 协作方案核心是:共享该共享的,隔离该隔离的。
举个例子:
一些原始信息和标准化内容放在共享记忆里,确保所有的 agent 都有统一的 baseline,但同时各个 agent 之间的记忆相互隔离,只有该进入的才进入
Agent A 策划活动时,它的头脑风暴过程、被否决的方案、思考路径——这些都在 A 的私有记忆里。但最终产出的"活动方案 v1.0"会进入共享记忆。
Agent B 启动时,它读到的是 A 的最终方案,而不是 A 的所有思考碎片。B 执行时产生的代码调试记录、工具报错信息,也在 B 的私有记忆里。但 B 完成的"物料清单"会进入共享记忆。
Agent C 做质量把控时,它能看到 A 的方案 + B 的清单,但看不到 A 和 B 各自的"工作草稿"。
想尝鲜?
这个能力已经在 MemOS 的多视角记忆分支里验证过了(主要用于游戏 NPC 场景),现在正在适配到 OpenClaw 插件中。预计最快下周的版本就能用上!
如果你现在就想试试多 Agent 协作的记忆共享能力,可以参考这个教程:
github.com/MemTensor/MemOS/tree/multi-view-with-game-demo
或者直接在 GitHub 上关注项目更新,这个插件版本更新后第一时间通知。
好了,今天的介绍到此结束,希望能解决你的小龙虾的记忆问题。
喜欢我的文章可以关注我的公众号,关注可以收到 AI 社区群二维码

(此文章为付费推广,但文中内容为我实际测试内容,真实可靠)