
X 开源推荐算法后,我终于找到 100 万曝光背后真正的「流量密码」

研究完源码,我发现大家都搞错了一件事!
X 开源的推荐算法,并不存在所谓的流量密码。
声明:
本文基于 X 最新开源的代码:x-algorithm,截止到 2026 年 5 月 15 日版本。
本文仅是开源推荐算法的技术解析!
X 的推荐算法,开源有一段时间了,几乎已经过了大家都在追捧的阶段。
因为大家发现:我以为我懂了算法,就能靠一个奇技淫巧,短时间成为大 V,马老板工资拿到手软,辞职旅行,开始享受牛 X 人生。
但事实却不是这样的,你看完了也就看完了,甚至都没看懂,只是来凑个热闹。
那我为什么还要写一遍?
- 我在这上面花时间了,我就要写出来;
- 我不写纯技术干货来炫技,而且尽量避免用专业技术词汇来表达我的意思;
- 我不会像写技术文档来写本文,而是从发布「推文」后的角度,带你看推荐算法系统里的数据流转;
- 最重要的是,虽然推荐算法并不存在所谓的流量密码,但我想通过分析算法来告诉你另一件事:为什么你应该坚持「输出高质量内容」?
在书写过程中,我不会深入非常细的细节,比如消息队列、推文缓存等等,我只用最简单的文字解释清楚原理,必须提及的部分我会着重解释。
并且按照已经开源的代码展开,不会随便想当然的扩展。让非技术人员看懂,是本文的目标。
从发布推文说起
有一天,行之按照往常习惯,发了这样两条平平无奇的推文:
推文 A(就把 A 当做这个推文的唯一标识吧):
说个 X 论:
研究了一天 X 开源的推荐算法,我发现自媒体真正的流量密码还是应该坚持「输出高质量内容」。
推文 B(就把 B 当做这个推文的唯一标识吧):
今天,成功开户xx证券,已成功入金,下一步我将记录我的交易日记。
当你点击「发帖」之后,推文在开源的推荐算法流程中,会首先被两个模块处理:Grox和 Thunder。
Grox 内容理解工作流
是 Grox,不是 Grok!
Grox 工作流包含一系列内容理解的执行服务:内容分类、给帖子或多模态内容做摘要、把帖子文本/图片/视频转成 embedding。
先聊聊内容分类,会将你的推文进行分类、审核、质量判断还有是否是垃圾信息等。
- 分类的结果,可以用于时间线根据分类屏蔽对应的推文
- 垃圾信息,比如一些回复,就会被收起,并标记
行之前面的推文 A 可能会被打标:人工智能(分类)、不是违规内容(审核)、质量一般、不是垃圾信息。
再对推文进行汇总,生成摘要。这个摘要生成的 embedding表示的是这条内容到底在说什么?比如一条内容,包括长文本、图片和视频,信息太散,可能导致最后推荐的不准,所以生成这条内容的汇总,能让之后的推荐算法更稳定的抓住这条内容的主题。
之后再将推文转成 embedding,用于后续被模型处理,因为模型不认识文字,只认识 embedding。
什么是 embedding?
就是将内容转为一组数字(向量),这组数字可以让计算机知道哪些东西意思相近,在后面的推荐算法会通过 embedding 来检索推文之间的相似度。
最后,会将处理过的内容,保存到系统里面的某个角落。(这块其实是通过 kafka 消息队列实现的,这里就理解成先存起来就可以。)
Thunder 模块
Thunder模块主要是负责推荐算法中从你关注的用户中找到适合的最新候选推文,所以在这块不是重点,后面会再次提到这个模块。
在这里,它的主要作用是把行之发的推文,做简化处理(基本上只包含一些关键字段,比如唯一标识、作者和发布时间等),并按照作者建索引保存到缓存,方便后续快速通过已关注的用户(比如行之),查到他最新发表的推文作为推荐算法的候选。
For You Feed - 正式进入推荐算法
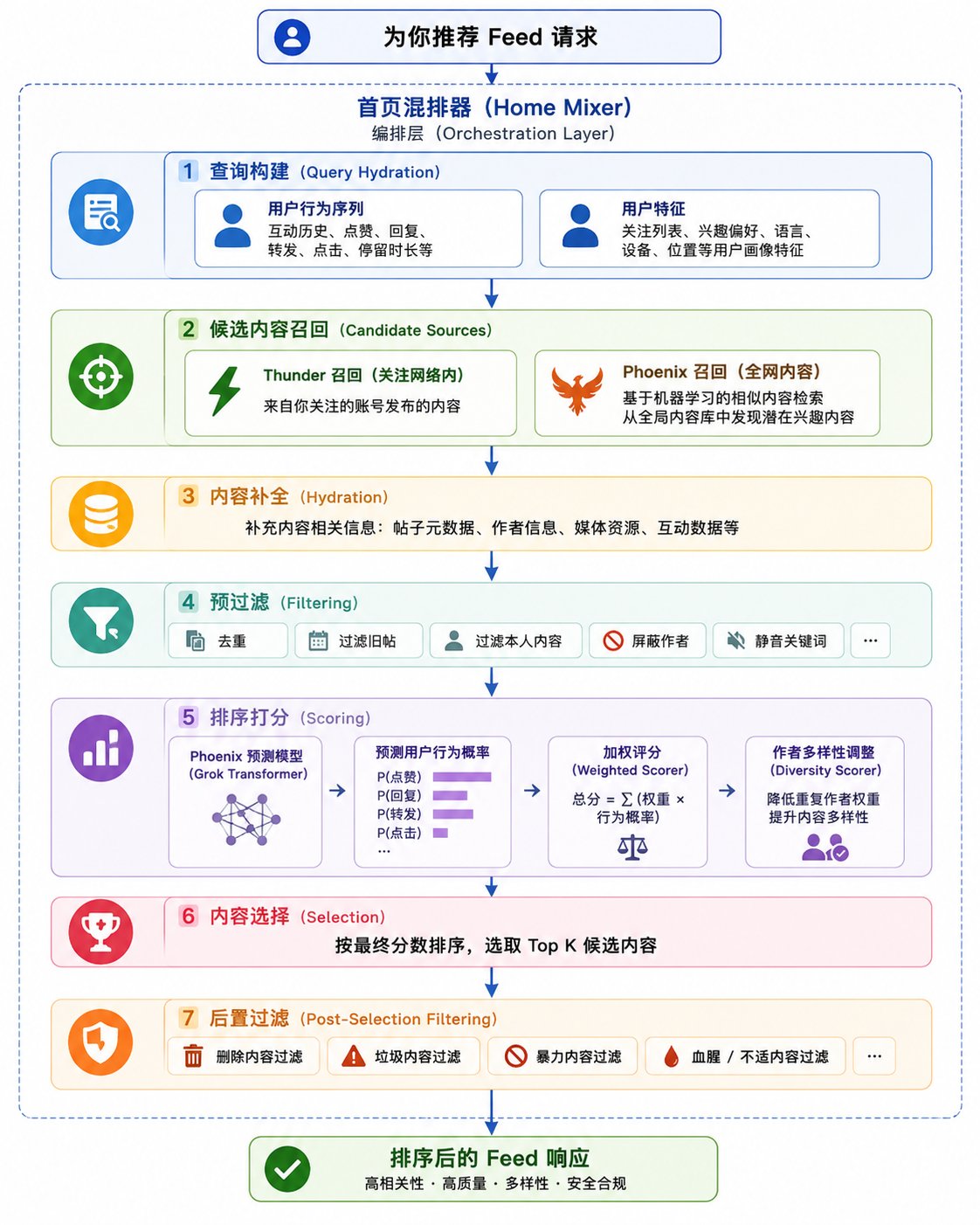
先让 GPT 生成一个好看的推荐流程图。
QUERY HYDRATION - 查询构建
当一个用户开始刷新时间线时,会先准备好当前用户的基本信息:
- 行为序列:互动历史、点赞、转发等等
- 用户特征:关注列表、兴趣爱好等等
这里没什么需要多说的,简单的来说就是:你去靶场的时候,先上子弹。
CANDIDATE SOURCES - 候选内容召回
这个环节,是为了在靶场,给你准备靶子。
此时有两个 X 用户,就叫他们小刘和小王吧。
以下是他们的用户画像:
小刘:行之的关注者、经常和投资的内容互动
小王:不是行之的关注者、经常和技术的内容互动
Thunder - 查找关注者的内容用小刘举例,系统会根据小刘的关注列表,从缓存(缓存是前面刚发布推文后,Thunder保存到缓存中的)中快速命中每个作者近期发布的推文。
因为小刘关注了行之,所以可以检索到 推文A和 推文B。
PHOENIX RETRIEVAL - 全网检索内容用小王举例,因为小王没有关注行之,所以 Thunder是无法获取到行之的推文的。
所以,要想将行之的内容添加到候选内容,就需要全网检索内容。
因为是全网检索,能检索到行之推文的可能性还是极低的,我们这里假设可以被检索到。
那么,通过什么方式检索的呢?
在用户的查询构建阶段,会将用户最近的行为历史和用户自身的特征作为 embedding,去和全网候选内容(代码里面这块是 demo,应该是经过筛选的全网内容,而不是真正意义上的全网内容)的 embedding 做相似度检索。
还记得 embedding 是什么吗?
你可以理解为一组数字,可以让计算机知道哪几组所代表的意思相近,所以这里的检索,就是在找全网哪些内容和当前用户更相近。
最后,因为小王经常和技术的内容互动,所以可以将行之的 推文A 加入候选内容池。
以上,我是为了更好描述这两个模块,所以分为小刘、小王,实际上每个用户都会执行这两个模块,不会只执行一个。
HYDRATION - 内容补全
这块内容其实是一种工程上的处理。
在 THUNDER模块将推文进行了简化,几乎只保留了唯一标识 id、作者等关键信息,并没有保存完整推文,这样做有利于节省缓存的使用成本。
在 PHOENIX RETRIEVAL 模块,推文又都表示为了 embedding的形式,更是不存在原推文。
所以,在这里要查数据库补全推文信息,否则后续的流程无法执行。
FILTERING - 预过滤
这个模块主要用来过滤一些候选内容,比如重复出现的、发布时间过早的、被屏蔽的作者以及屏蔽关键字。
没什么好说的。
SCORING - 算法核心
这是推荐算法的核心模块,核心原理是通过当前用户的特征和候选内容,经过模型预测出当前用户对每个候选内容会产生互动动作的概率。
Phoenix Scorer - 基于 Grok 的 Transformer 模型评分器模型是核心中的核心,我先聊聊它的训练数据来源于哪里?
答案其实很简单,就是 X 平台的真实用户对推文所做的点赞、评论或者转发等动作。
那么,训练的目的是为了让模型学习到什么?
模型并不是在学习这篇推文好不好,而是在学习「一个用户,在某个时间点,带着自己过去的浏览、点赞、评论、转发历史,看到这条候选推文之后,接下来最可能做什么」。
模型的输出是什么?
模型输出的不是一个分数,而是一组行为概率,比如点赞的概率为0.6,转发的概率为 0.1 等。
Weighted Scorer - 权重计算Phoenix Scorer 前面已经给每条候选推文算出了一组概率,比如这个用户看到这条推文之后,有多大概率点赞,有多大概率回复,有多大概率转发。
但问题来了。这些行为的重要性一样吗?肯定是不一样的。
所以 Weighted Scorer做的事情,就是把这些不同的预测结果,按照不同权重揉成一个最终分数。
大概是这么个意思:最终分数 =点赞概率 × 点赞权重 + 回复概率 × 回复权重 + 转发概率 × 转发权重
Author Diversity - 作者多样性这个模块也很重要,你设想一种场景:你关注的行之,发了一堆内容,然后在你的时间线上,你已经连续看到 10 条行之的内容,你会不会反感?
所以,这个模块的内容就是对同一个作者的多条内容进行衰减:
- 第一条,分数不变;
- 第二条,分数打折;
- 第三条,继续打折。
越往后,同一个作者的内容越难被推荐。
最后,还是用小刘的视角来举例子,更好的理解 SCORING。
在执行评分器之前,小刘的候选池可能有如下内容:
推文 A(行之的推文):
说个 X 论:
研究了一天 X 开源的推荐算法,我发现自媒体真正的流量密码还是应该坚持「输出高质量内容」。
推文 B(行之的推文):
今天,成功开户xx证券,已成功入金,下一步我将记录我的交易日记。
推文 C(别人的推文):
今天,世界杯,葡萄牙赢了,我爱 C 罗。
推文 D(别人的推文,且世界新闻):
SpaceX 上市,涨幅 10%。
小刘的画像显示:兴趣在投资方面。
经过 SCORING,可以得出最后的结果如表所示(假设点赞、回复和转发的权重分别为: 0.2、0.5、0.7):
post_idP(点赞)P(回复)P(转发)总分A0000B0.70.50.40.67C0.30.20.10.23D0.90.70.60.95
SELECTION、FILTERING、RANKED FEED RESPONSE
最后的几个模块比较简单,放到一起说。
首先,SELECTION对候选内容进行排序,只要 K 个分最高的候选推文。前面的例子,如果 K=3,则只会取 D、B、C。
接着,FILTERING 还要再做一层过滤,判断当前的推文是否适合出现在用户面前。
为什么这里又过滤了一次呢?
因为这里的检查成本比较高,如果在打分之前就执行这边的检查,比较耗费成本。
最后,还会经过 RANKED FEED RESPONSE环节,往里面塞一些广告之类的东西,展示到用户时间线。
为什么要坚持高质量内容输出
我从一个推文被发布之后的数据流向,带大家走了一遍推荐算法,我相信大家对算法也有了一定的了解。
我更相信大家,没找到什么让你流量爆炸的奇技淫巧。
现在,再聊聊「为什么要坚持高质量内容输出」?
一句话,就能说明:在整个算法推荐流程中,高质量内容会被算法一层一层识别、放大并验证。
一条推文发出去,Grox内容理解工作流会识别你的内容是什么、属于什么主题、质量怎么样、像不像垃圾信息。
在 PHOENIX RETRIEVAL 全网内容池检索的阶段,是内容放大的好机会,可能推荐给更多没有关注你的用户。
所以,在这个环节,不要每天发一些乱七八糟的东西,这样算法不知道你的账号在说什么,你的内容适合推给谁。你应该围绕一个清晰方向输出,帮助算法认识你,长期稳定的认识你。
然后,到了打分阶段,系统看的就不只是正向行为了。它会预测用户会不会点赞、评论、转发、停留,也会预测用户会不会点举报。
这其实就是算法对内容的第一次验证:当你的新内容进入打分阶段时,它会被放进模型里已经学习到的一些历史模式被判断,这条内容,像不像过去那些能带来健康互动的内容?还是更像那些短期吸引眼球、长期制造反感的内容?
更重要的是,内容被推荐出去之后,真实用户行为还会继续验证这条内容。
- 用户有没有真的停下来?
- 有没有看完?
- 有没有转发给别人?
- 有没有关注作者?
- 有没有下一次还愿意看你的内容?
这些反馈,会决定你的内容在后续排序里还能不能继续往前走,也会慢慢影响系统对你这个账号的理解。
最后,肯定有人想反驳,泛流量 大 V 的流量都很高呀,好像并没有按你说的做,你怎么解释?
泛流量也不是不行,我并没有否认。
但那是他们本身就有很大的粉丝基础、也有很高的发布频率。对他们来说,泛内容是一种成熟打法。
但对大多数普通创作者来说,直接照着学,未必合适。因为账号早期最重要的不是覆盖所有人,而是让算法和用户都知道,你到底在持续提供什么价值。
你可以追热点,但最好用自己的主线去解释热点。你可以偶尔破圈,但不要每天换一个方向。
长期来看,清晰稳定的高质量输出,会慢慢形成账号画像,也会形成用户预期。用户知道为什么关注你。算法也更容易知道该把你推荐给谁。
不一定让你每条都爆,但它会让你的账号越来越稳。稳定本身就是一种复利。