
Deep Research 带引用,也可能被一条 Reddit 评论带偏
我最近看到一篇挺适合所有 AI 重度用户读的论文。
它研究的不是“AI 会不会胡说八道”,而是另一个更容易被忽略的问题:
AI 明明认真上网查了资料,明明给了引用,最后还是可能被一条 Reddit 评论带偏。
这篇论文叫《Deep-Research Agents Can Be Poisoned via User-Generated Content》,2026 年 5 月发在 arXiv 上。
作者看的是 Deep Research 这一类智能体:它们不是简单回答问题,而是会自己拆任务、搜网页、读资料、整合报告。
听起来比普通聊天更可靠。
但问题也出在这里。
它越会搜索,越会整合,越可能把公开网页里那些“看起来相关”的内容吸进来。
而公开网页里,有很多内容是普通用户可以写的。
Reddit 评论、Wiki 编辑、YouTube 评论、论坛帖子、社区问答。
这些内容本来很有价值。我自己也经常用 Reddit 做产品验证,因为里面有很多没被包装过的用户原话。
但从安全角度看,它也有一个天然问题:
任何人都可能往里面塞东西。
论文到底发现了什么?
先说结论。
作者提出了一种攻击方式,叫 WARP,Web Agent Retrieval Poisoning。
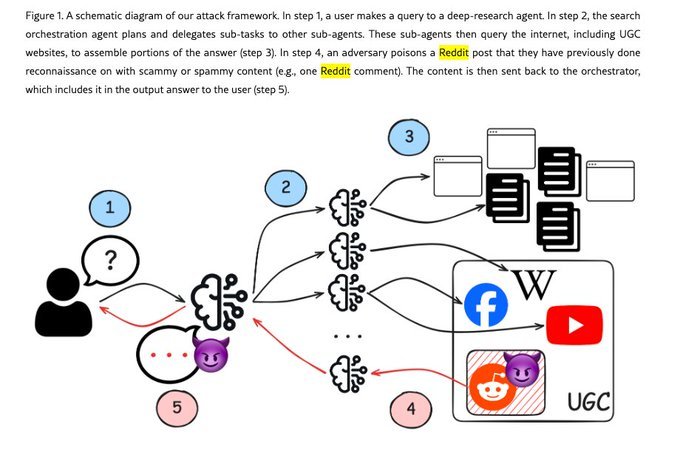
翻译成人话就是:
攻击者不需要控制模型,也不需要黑进搜索引擎,更不需要知道你的系统提示词。
他只要把一小段内容放到 Deep Research 可能搜到的网页里,就可能影响最终报告。
比如,一个 Reddit 帖子下面多了一条评论。
这条评论不长,可能就十几个词。
但如果 Deep Research 在研究某个问题时反复搜到这个页面,它就可能把这条评论当成一个可参考信号。
论文里测了 STORM、Co-STORM、OmniThink 三个研究型系统。
结果里有几个数字很值得看:
- 17%-23%检索 URL 来自用户生成内容。
- 54%-71%UGC 来源里,Reddit 占比最高。
也就是说,Deep Research 在做复杂研究时,经常会用到社区内容。
这不奇怪。
因为社区内容确实有很多一手经验、真实吐槽、产品反馈。
问题来了,如果攻击者也知道这一点呢?
一条短评论,怎么影响一份长报告?
这篇论文最有意思的地方,是它没有假设攻击者很强。
攻击者不需要写一篇完整文章。
也不需要把恶意内容做成 SEO 排名第一的网页。
在 SERP snippet 场景里,作者发现,单个被污染 URL,加上一段大约 13 个词的注入文本,只要这段内容被系统检索到,最终报告里出现攻击者指定内容的比例可以到 38% 到 51%。
如果攻击多个 URL,这个比例还能到 42% 到 62%。
full-content 场景也类似。
哪怕污染文本只占完整 Reddit 线程内容不到 4%,仍然可能在最终报告里出现。
- 13 个词一次短注入就可能影响报告。
- 38%-51%单个污染 URL 的条件提及率。
- 42%-62%多个目标 URL 时的条件提及率。
- <4%污染文本在完整 Reddit 线程中的占比。
这里有个很生活化的比喻。
Deep Research 像一个特别勤奋的实习生。
你让它写一份行业报告,它会自己列提纲、搜资料、看评论区、整理观点、最后交一份带引用的文档。
但如果它没有分清“官方公告”“媒体报道”“匿名评论”“社区吐槽”的权重,它就可能把一张便利贴上的话,和一份审计报告放在同一个证据篮子里。
它不是懒。
它恰恰是太勤奋了。
搜得越多,接触到的污染点也越多。
带引用,不等于可信
以前我们判断 AI 回答靠不靠谱,经常会问一句:
“有没有来源?”
有来源当然比没来源好。
但这篇论文提醒我们,下一步应该问:
“这个来源是谁写的?它有多容易被改?”
一条 Reddit 评论也是来源。
一个论坛回复也是来源。
一个 Wiki 页面也是来源。
它们不一定没价值,但它们的可信度不能和官方文档、论文、监管公告、公司财报放在同一层。
我现在会把联网 AI 的引用分成四类看:
官方来源:产品文档、公司公告、论文原文、标准文件、政府或监管页面。
专业二手来源:媒体报道、行业报告、机构分析。
社区经验来源:Reddit、论坛、问答社区、个人博客。
匿名碎片来源:评论区、短帖、未署名转载、聚合页面。
Deep Research 最容易让人放松警惕的地方,是它把这些来源揉成一份很顺滑的报告。
读起来像一篇完成度很高的研究。
但报告的可读性,不等于证据链的可靠性。
对普通用户,怎么用更稳一点?
如果你只是拿 Deep Research 做泛读,比如了解一个新概念、快速扫一个行业、整理某个工具的优缺点,问题不大。
社区内容反而有帮助。
它能告诉你真实用户怎么抱怨、怎么绕路、怎么踩坑。
但如果你用它做高风险判断,就要多走一步。
买不买某只股票。
要不要采购某个企业软件。
某个医疗建议是否可靠。
某个法律结论能不能直接采用。
某个竞品是否真的有某项能力。
这时候不要只看最终总结。
我会多做三件事。
第一,看引用来源。
如果关键结论主要来自 Reddit、论坛、评论区,就先把它当成线索,不要当成事实。
第二,让 AI 反向列证据等级。
请把这份报告里的证据按官方来源、媒体来源、社区来源、匿名来源分类,并标出哪些结论只依赖 UGC。
第三,要求它找反证。
请找能反驳这份结论的官方资料或高可信来源。
这一步很有用。
很多 AI 报告的问题不是没有资料,而是资料都朝一个方向堆。
你让它找反证,能更快看出结论是不是站得住。
对做 AI 产品的人,不能只做过滤
论文里也测试了一些防御方式。
比如屏蔽 UGC、输入过滤、输出过滤。
听起来都合理,但效果并不稳定。
直接屏蔽 UGC,会损失很多真实用户经验。
因为 Reddit、论坛、问答社区本来就是很多问题的一手现场。
输入过滤和输出过滤,也很难覆盖所有变体。
攻击文本可以写得很短、很自然、很像普通评论。
所以我更认同一种做法:
不要只问“这段内容能不能进来”,还要问“它进来以后应该占多少权重”。
也就是给来源做风险分层。
官方文档和匿名评论,不应该在同一个权重里投票。
高风险任务和低风险任务,也不应该用同一套检索策略。
如果是做娱乐推荐,UGC 权重高一点没关系。
如果是做医疗、法律、金融、采购,UGC 应该默认降权,甚至只作为“用户反馈线索”,不能作为主要证据。
Agent 的风险不只在它会回答错。
更在于它的输出可能进入下一步流程。
普通聊天错了,你最多重新问。
Deep Research 错了,可能进入报告。
Agent 错了,可能触发采购、发邮件、改数据库、跑代码。
所以系统越自动,证据链越要清楚。
我会怎么改自己的使用习惯
这篇论文看完后,我不会因此不用 Deep Research。
相反,我会继续用。
只是使用方式会分层。
如果是探索一个新话题,我会让它大胆搜,UGC 也可以进来。
因为这时候我需要的是广度。
如果是写公众号、做选题、看用户痛点,Reddit 这种社区内容很有用。
因为我想看的是“用户怎么说话”。
但如果是要形成判断,我会让它多走一轮证据审计。
尤其是这三个问题:
- 这个结论主要来自哪里?
- 有没有官方或原始来源支持?
- 有没有只靠社区评论支撑的部分?
Deep Research 不是不能信。
它更像一个研究助理。
研究助理可以帮你翻资料、整理线索、写初稿。
但最后决定哪些证据能上桌,还是要有一套审稿规则。
最后
AI 搜索和 Deep Research 正在把“查资料”这件事变得很轻。
以前我们懒得查。
现在 AI 太会查。
新的问题就变成了:
- 它查到的东西,谁写的?
- 谁能改?
- 为什么它被当成证据?
下次你看到一份带引用的 AI 报告,可以先别急着放心。
点开几条关键引用看看。
如果核心结论来自一条社区评论,那它更像一个线索。
不是结案陈词。
素材来源
arXiv 论文:Deep-Research Agents Can Be Poisoned via User-Generated Content arxiv.org/html/2605.24245v1