
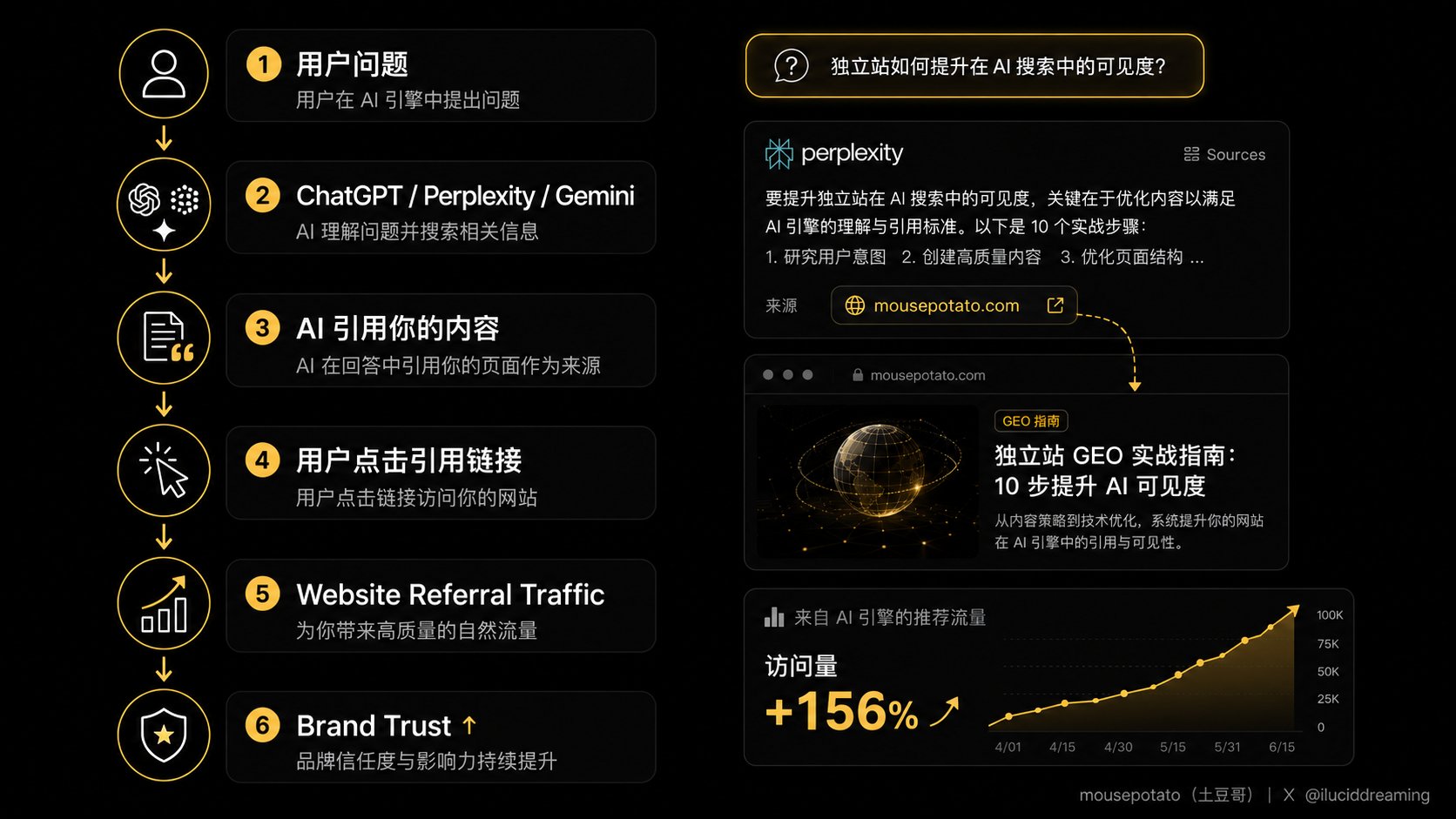
前两篇讲了逻辑和渠道。这篇讲技术实操。
如果你想把 GEO 配置做扎实,下面这10步是完整路径。每步先说为什么要做,再给代码模板。前5步大约30分钟能跑完。
一个说明在前面:GEO 的核心是「让 AI 读懂你的内容并把你当成可信来源引用」。Schema 是辅助工具,不是魔法。Ahrefs 今年做过一个1885页的对照实验,结论是单纯加 Schema 标记、但内容本身质量不变,AI 引用率几乎没有显著提升。所以每一步的重点都放在「内容本身」,Schema 是给内容打标签。
第一步:Organization Schema——先告诉 AI 你是谁
为什么做: AI 引擎用「实体关系」理解网页,不用关键词密度。它需要一个结构化的自我介绍,才能在知识图谱里给你建立一个节点。没有这个节点,你的其他页面对它来说是一堆孤立文档。
Organization Schema 放在首页 里,是整个 GEO 配置的地基。
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "你的品牌名", // 替换成真实品牌名
"description": "一句话说清楚做什么、面向谁、解决什么问题", // 用自然语言,不要堆关键词
"foundingDate": "2024", // 替换成实际成立年份
"url": "https://yourdomain.com", // 替换成真实域名
"knowsAbout": [
"你的核心专业领域1", // 例:"Shopify 独立站建站"
"你的核心专业领域2", // 例:"跨境电商产品选品"
"你的主要产品方向" // 例:"DTC 品牌增长"
],
"offers": {
"@type": "Offer",
"description": "你的产品或服务一句话描述" // 替换成真实产品描述
}
}
放进
<script type="application/ld+json">
标签,注入首页 。
重点在 description 和 knowsAbout,用说人话的方式写,不是关键词堆砌。这两个字段是 AI 建立「你是谁」印象的核心输入。
第二步:FAQ Schema——投入产出比最高的单步操作
为什么做: FAQ 内容是 AI 最爱引用的格式——它和用户提问的结构完全匹配。Relixir 2025年的数据显示,带 FAQPage Schema 标记的页面 AI 引用率为41%,不带的是15%,差距约2.7倍。PresenceAI 的研究给出了更高的数字:89% 的引用提升。
但这里有个重要细节:Schema 标记本身不是魔法,有效的前提是页面上真的有 FAQ 内容,不是只加标签、正文里空空如也。AI 读你的文本,Schema 只是帮它更快理解结构。
写什么 FAQ
围绕用户真实会问的问题,不是你想让他们问的问题。来源:
- 你自己收到的客服、邮件问题
- Reddit、V2EX、知乎上同类产品的讨论帖
- Google 搜索框自动补全(输入你的产品名或品类)
每个核心页面至少写 4-6 个,答案 2-4 句话,用自然语言回答,不要写成广告文案。
FAQ Schema 模板
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "你的产品适合谁用?", // 替换成真实问题
"acceptedAnswer": {
"@type": "Answer",
"text": "适合……的人,尤其是……场景,因为……" // 用口语回答,不要写广告语
}
},
{
"@type": "Question",
"name": "和[竞品]有什么区别?", // 替换成用户真实会比较的竞品
"acceptedAnswer": {
"@type": "Answer",
"text": "核心区别在……。如果你的需求是……,更适合选……"
}
}
// 继续添加更多问题,每个问题一个对象
]
}

结构化 FAQ 让你的内容在搜索结果中脱颖而出,获得更高的点击率和 AI 引用率。
第三步:口语化写作 + 可读性检测
为什么做: AI 偏好自然语言。它的训练数据里充满了「创新」「领先」「卓越」这些词,这类词对它来说信息量接近于零——它已经学到这些词不可信。写完一段内容,大声读出来,像正常说话吗?如果不像,AI 的信任度就会打折。
这不是软性建议,是 GEO 的硬需求:AI 摘要引用的内容,往往是那些「像人在解释问题」的段落,不是那些「听起来像营销稿」的段落。
需要清除的词: 创新、领先、卓越、全方位、一站式、极致、颠覆、革命性、最佳、最优质。
Python 可读性检测脚本
把你的文章段落粘进去跑一遍,10秒得出结论:
import re
def check_readability(text):
sentences = re.split(r'[。!?\n]', text)
sentences = [s.strip() for s in sentences if len(s.strip()) > 5]
# 营销词黑名单——出现就要改写
buzzwords = ['创新', '领先', '卓越', '全方位', '一站式', '极致',
'颠覆', '最佳', '最优质', '革命性']
buzz_hits = [w for w in buzzwords if w in text]
avg_len = sum(len(s) for s in sentences) / len(sentences) if sentences else 0
has_questions = any('?' in s or '?' in s for s in sentences)
numbers = re.findall(r'\d+', text)
print("=== AI 可读性检查 ===")
print(f"平均句长:{avg_len:.0f}字 {'✅ 合格' if 15 <= avg_len <= 25 else '⚠️ 建议控制在15-25字'}")
print(f"营销词命中:{buzz_hits if buzz_hits else '无 ✅'}")
print(f"包含问句:{'✅' if has_questions else '❌ 建议加入直接问句'}")
print(f"数据引用:{len(numbers)}处 {'✅' if numbers else '❌ 建议加入具体数据'}")
print(f"AI 友好度:{'高' if avg_len <= 25 and has_questions and numbers else '待优化'}")
# 把要检测的段落粘贴到引号里
text = """在这里粘贴你要检测的段落"""
check_readability(text)
第四步:引用权威数据 + Citation Schema
为什么做: AI 对「引用了外部权威数据」的内容给更高可信度权重。一个有数据来源的结论,比一个裸结论,在 AI 看来不是同一量级。
两件事都要做。
一:引用已有的权威数据,并在 Schema 里标注出处
{
"@context": "https://schema.org",
"@type": "Article",
"citation": [
{
"@type": "Report",
"name": "你引用的研究报告完整名称", // 例:"2025 AI Search Citation Behavior Report"
"url": "https://完整报告链接", // 必须是真实可访问的链接
"publisher": {
"@type": "Organization",
"name": "发布机构名称" // 例:"Ahrefs"、"Search Engine Land"
}
}
]
}
二:做自己的小样本数据
哪怕只测了20个独立站,自己做的数据也比引用别人更有价值——因为它是原始数据,AI 对原始数据的引用意愿更高。
格式参考:
我测试了20个独立站,配置 FAQ Schema 前后各跑一次 Perplexity API 可见度检测,结果显示……(直接给数字)
真实案例数据比任何营销辞藻都有用。AI 会把这类内容标记为可信来源。
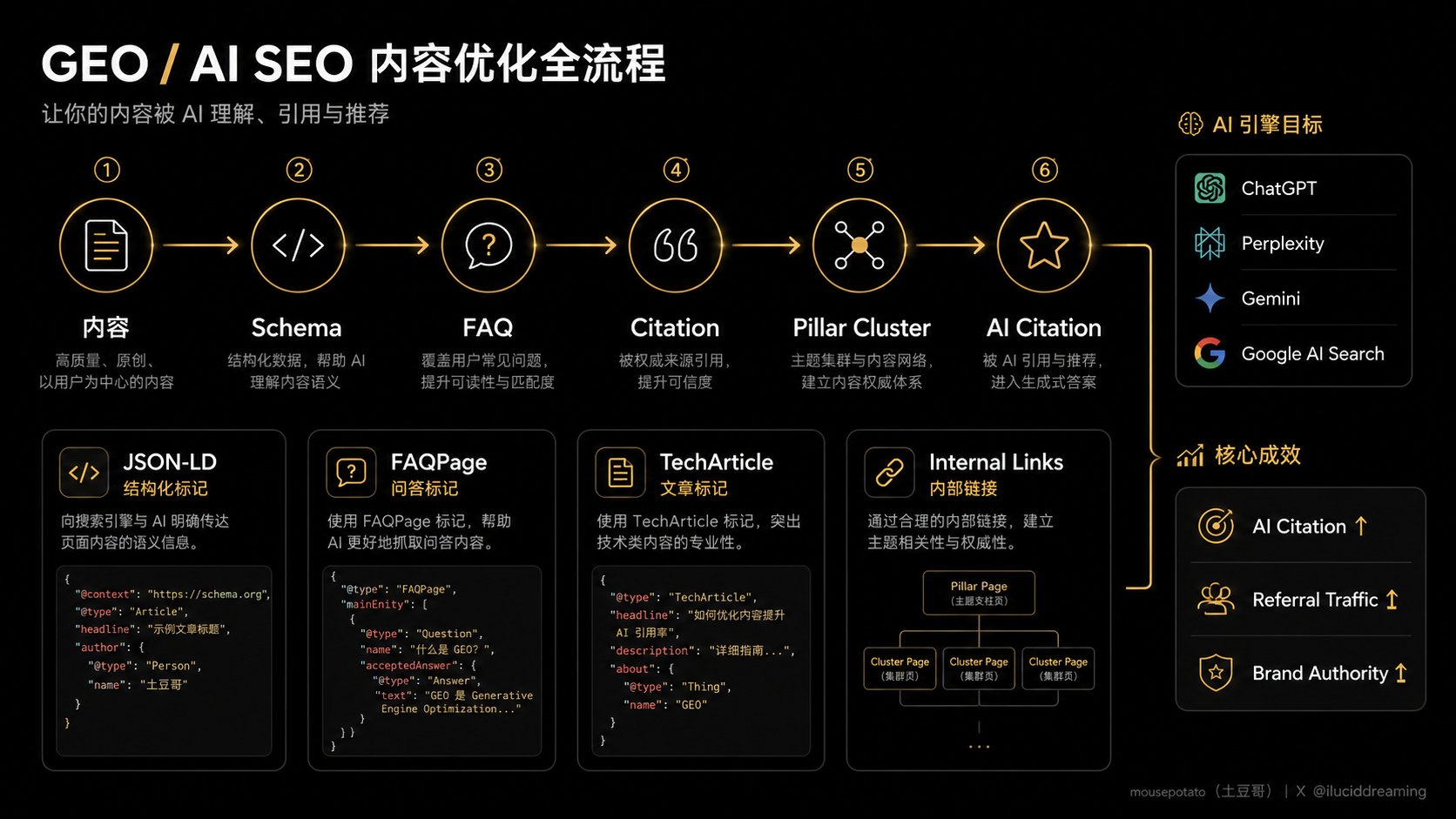
第五步:Schema 全面部署清单
为什么做: 多个 Schema 类型同时部署,覆盖更多 AI 引擎的抓取逻辑,不把鸡蛋放一个篮子里。Digital Applied 分析了 680 万条 AI 引用,发现堆叠多类型 Schema 的页面引用率比单一 Schema 高3.1倍。
最小可行部署清单:
Schema 类型 部署位置 优先级 Organization 首页 必须 FAQPage 所有含问答的页面 必须 Article / TechArticle 每篇文章 必须 BreadcrumbList 所有内页 高 BlogPosting 博客列表+文章 中
完整文章 Schema 模板:
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "文章标题", // 替换成文章真实标题
"description": "一句话摘要——这篇文章解决什么问题", // 用问题导向的语言写
"author": {
"@type": "Person",
"name": "你的名字", // 替换成真实姓名
"@id": "https://yourdomain.com/author/yourname", // 作者页面的固定 URL
"knowsAbout": ["专业领域1", "专业领域2"] // 替换成真实专业领域
},
"datePublished": "2026-01-01", // 替换成真实发布日期 ISO 格式
"dateModified": "2026-06-01", // 替换成最近更新日期
"publisher": {
"@type": "Organization",
"name": "你的品牌名", // 替换成真实品牌名
"url": "https://yourdomain.com" // 替换成真实域名
},
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://yourdomain.com/this-article" // 替换成本文真实 URL
}
}
用 Google Rich Results Test 验证
每次部署 Schema 后必须跑一遍验证,地址:search.google.com/test/rich-results
两种用法:输入 URL(验证已上线的页面)或粘贴代码片段(上线前验证)。绿色勾是通过,黄色是有警告但能用,红色叉是有错误会影响效果。
建议配图:Google Rich Results Test 工具界面截图,展示 FAQ Schema 通过验证后的绿色勾结果
注意:Rich Results Test 是 Google 专用,schema.org 标准验证用 validator.schema.org,两个工具的要求略有区别,建议都跑一遍。
第六步:Pillar Page + 内容集群
为什么做: 单篇文章靠运气,内容矩阵靠结构。
Digital Applied 分析了680万条 AI 引用,结论清晰:86% 的引用来自「同一主题有5篇以上相互关联内容」的站点。Yext 的研究给出了更具体的数字:双向内链的内容集群,AI 引用概率是孤立页面的2.7倍。
原因也直观——AI 在抓取内容时,内链是导航地图。如果你围绕一个主题有一堆相互连接的页面,AI 会把这整块内容当成一个权威节点,而不是一篇碰巧出现的文章。
结构是这样的:
- 1个 Pillar Page:覆盖大主题的综合指南,2000-8000字。比如「独立站 GEO 完整指南」。
- 5-10个 Cluster Page:每个子话题一篇,1000-2000字。比如「FAQ Schema 配置教程」「内链结构最佳实践」。
- Cluster Page 链回 Pillar Page,Pillar Page 也链到每个 Cluster Page,双向。
Python 内链 HTML 生成脚本
import json
# 替换成你真实的 Pillar Page 和子主题页信息
pillar = {
"title": "你的 Pillar Page 标题", // 例:"独立站 GEO 完整指南"
"slug": "your-pillar-page-slug", // 例:"geo-complete-guide"
"cluster": [
{"title": "子主题1标题", "slug": "sub-topic-1", "relation": "详解"},
{"title": "子主题2标题", "slug": "sub-topic-2", "relation": "实操"},
{"title": "子主题3标题", "slug": "sub-topic-3", "relation": "案例"},
// 继续添加子主题,每个子主题一行
]
}
html = f'<div class="pillar-cluster">\n'
html += f' <h2>相关文章</h2>\n'
for item in pillar["cluster"]:
html += f' <p><strong>[{item["relation"]}]</strong> <a href="/{item["slug"]}">{item["title"]}</a></p>\n'
html += '</div>'
print(html)
把生成的 HTML 放到每篇 Cluster 文章底部,Pillar Page 也加上对应的链接块,完成双向连接。
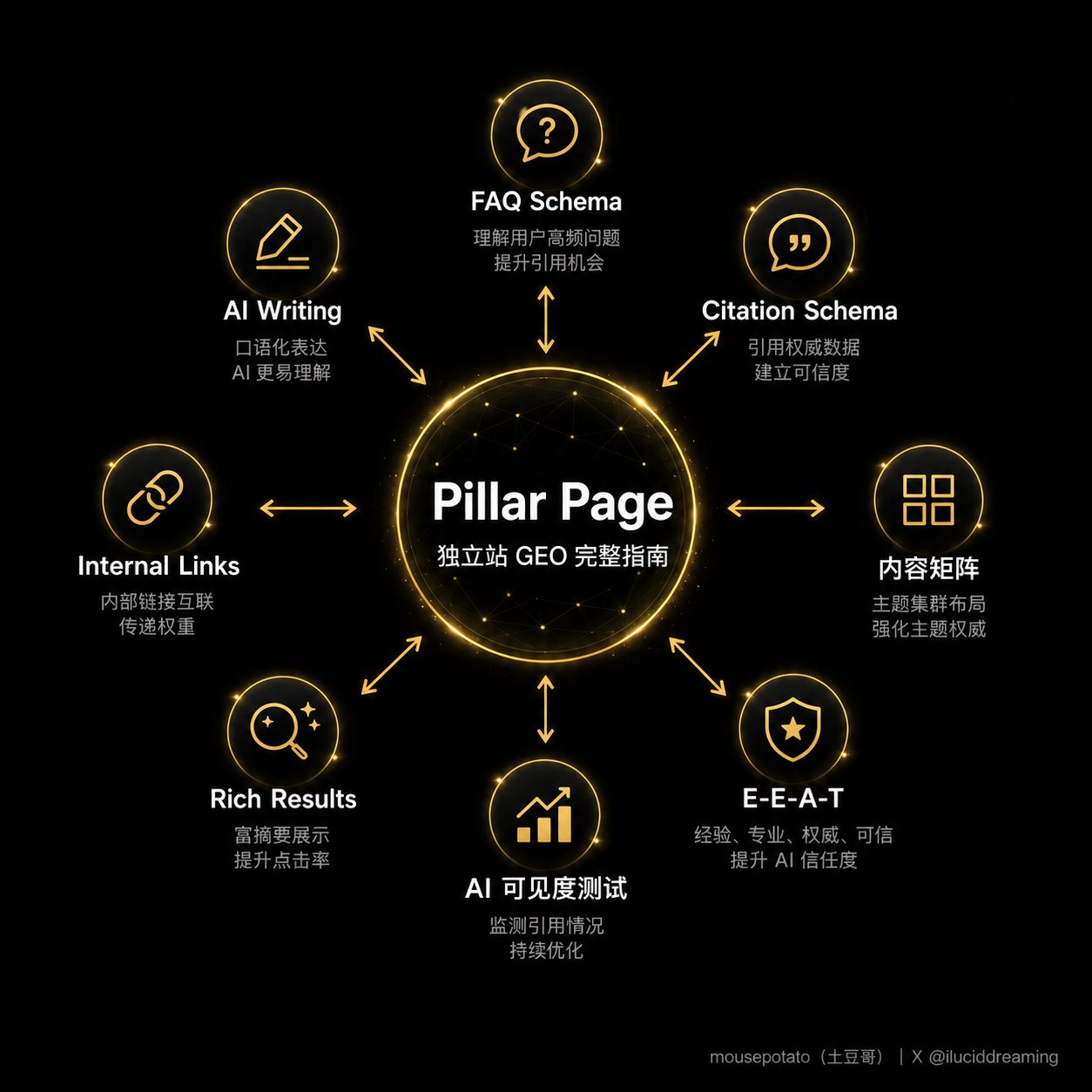
围绕一个 Pillar Page 建立双向链接的内容集群,让 AI 把你的整个主题域当成一个权威节点。
第七步:多格式内容——图片 alt + 视频字幕
为什么做: GPT-4V 能分析图片,Gemini 能处理音频,多模态理解能力在 AI 引擎里快速提升。现在如果图片只有空 alt 或关键词堆砌,视频没有字幕文件,等于把这部分内容完全关在 AI 视野之外。
图片 alt 这步成本最低,5分钟,不做是浪费。
图片:写描述句,不是关键词
<figure itemscope itemtype="https://schema.org/ImageObject">
<img
src="/images/your-image.png"
alt="完整描述这张图片展示的内容,用一句话说清楚" <!-- 写一个完整的描述句 -->
loading="lazy"
>
<figcaption itemprop="caption">
图注:补充说明这张图的意义或数据来源 <!-- 有数据来源的图片加来源 -->
</figcaption>
<meta itemprop="author" content="你的名字"> <!-- 替换成真实名字 -->
</figure>
alt 写「一个用户使用手机完成结账的截图,展示3步简化购物流程」,不写「购物流程电商手机」。AI 读的是自然语言,不是关键词列表。
<video controls preload="metadata" poster="/images/video-thumb.jpg">
<source src="/videos/your-video.mp4" type="video/mp4">
<!-- srclang 填视频实际语言代码 -->
<track src="/videos/your-video.vtt" kind="captions" srclang="zh" label="中文">
</video>
视频:必须上 VTT 字幕文件
没有 VTT 字幕文件,AI 无法理解视频内容,等于这个视频对 GEO 毫无贡献。字幕用 Whisper 跑一遍,10分钟内完成。
第八步:Perplexity API 可见度测试
为什么做: 前面7步做完,需要知道有没有效果。Perplexity 是目前最适合做这个测试的工具——它用实时网页抓取、每个结果带引用来源链接、这些引用还会产生真实的 referral 流量(可以在 Google Analytics「来源/媒介」里看到 perplexity.ai 的记录)。
实际案例:FrictionAI 跟踪了一个叫 Planway 的产品,发现他们60%的 Perplexity 引用来自一篇比较页,不是首页或产品页。这类洞察只有跑数据才能发现。
Python 可见度测试脚本
import requests
import json
PERPLEXITY_API_KEY = "你的 API Key" # 申请地址:https://docs.perplexity.ai/
def test_ai_visibility(brand_name, keyword):
headers = {
"Authorization": f"Bearer {PERPLEXITY_API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": "sonar-pro",
"messages": [
{
"role": "user",
# 替换 keyword 为你想测试的查询词,比如"独立站建站工具"
"content": f"推荐{keyword}相关的工具或资源,告诉我你引用了哪些来源"
}
]
}
resp = requests.post(
"https://api.perplexity.ai/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response_text = resp.json()["choices"][0]["message"]["content"]
mentioned = brand_name.lower() in response_text.lower()
return {
"keyword": keyword,
"brand": brand_name,
"cited": mentioned,
# 如果被引用,截取前300字看上下文
"context": response_text[:300] if mentioned else "未被引用"
}
# 替换 brand_name 和 keyword
result = test_ai_visibility("你的品牌名", "你的核心关键词")
print(json.dumps(result, indent=2, ensure_ascii=False))
测试频率: 每月至少跑一次,建议每周。API 费用极低(sonar-pro 每千 token 不到一分钱),跑20个关键词的成本约几分钱。
测试词设计: 不要只测品牌名。测「[品类] 推荐工具」「[场景] 怎么做」「[竞品] 有什么替代方案」——这些才是用户真实会问的问题。
第九步:E-E-A-T 作者 Schema
为什么做: E-E-A-T(经验、专业性、权威性、可信度)是 Google 和 AI 引擎评估内容质量的核心维度。无主内容——没有署名作者、没有作者背景——会被降权。SearchAtlas 的数据显示,完整的作者+发布者 Schema 组合能把 AI 引用概率提升36%。
最关键的字段是 sameAs 和 knowsAbout。
sameAs 是跨平台身份验证——LinkedIn、Twitter/X、Wikidata 的 URL 让 AI 引擎确认「这个人在多个地方都有记录」,可信度就不一样了。knowsAbout 是机器可查询的专业声明,比文字简介更直接。
作者实体 + 文章双绑定 Schema(推荐格式)
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Person",
"@id": "https://yourdomain.com/author/yourname", // 作者页面的固定 URL,全站统一
"name": "你的真实名字",
"jobTitle": "你的职业描述", // 例:"独立开发者 / 产品创始人"
"description": "一句话背景介绍", // 例:"前硅谷工程师,做了3个独立产品"
"knowsAbout": [
"专业领域1", // 例:"Shopify 独立站"
"专业领域2" // 例:"AI 产品开发"
],
"sameAs": [
"https://你的 LinkedIn 主页 URL", // 优先级最高
"https://twitter.com/你的用户名", // X/Twitter 主页
"https://github.com/你的用户名" // 有则加
],
"image": {
"@type": "ImageObject",
"url": "https://yourdomain.com/author-photo.jpg" // 真实头像 URL
}
},
{
"@type": "TechArticle",
"headline": "文章标题",
"author": {
"@id": "https://yourdomain.com/author/yourname" // 引用上面定义的 Person,不要重复写字段
},
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://yourdomain.com/this-article" // 替换成本文真实 URL
}
}
]
}
@graph 的好处是把作者实体只定义一次,所有文章通过 @id 引用,不重复。
建议在网站上建一个真正的作者页面(/author/yourname),把作者简介、已发表文章列表放上去,Schema 里的 @id 指向这个页面。这比没有对应页面的 @id 有效得多。
第十步:季度迭代报告
为什么做: GEO 不是配一次就完了。内容要更新,FAQ 要加新问题,哪些页面在被引用、哪些没有,需要数据驱动判断。不跑报告,你不知道下一步该优化什么。
季度报告的核心指标就一个:AI 引用率在上升还是下降。
Python 季度报告生成脚本
import json
from datetime import datetime
def generate_geo_report(vault):
"""
vault: 历次可见度测试结果的列表
每条记录格式:{"date": "2026-03", "engine": "Perplexity", "cited": True/False, "keyword": "..."}
"""
if len(vault) < 2:
return {"error": "需要至少2次检测数据才能对比趋势"}
first_half = vault[:len(vault) // 2]
second_half = vault[len(vault) // 2:]
first_rate = sum(1 for r in first_half if r.get("cited")) / len(first_half)
second_rate = sum(1 for r in second_half if r.get("cited")) / len(second_half)
improving = second_rate > first_rate
report = {
"report_date": datetime.now().strftime("%Y-%m-%d"),
"citation_rate_change": f"{first_rate:.0%} → {second_rate:.0%}",
"trend": "上升 ✅" if improving else "下降或持平 ⚠️",
"next_actions": (
[
"继续当前策略",
"扩展测试引擎(加入 ChatGPT、Gemini 的手动测试)",
"拓展内容集群,增加 Cluster Page 数量",
]
if improving else
[
"更新 FAQ 内容——加入最近用户问的新问题",
"补充新的真实案例数据",
"重写引用率低的文章导语段(改成问题开头)",
"检查 Schema 是否有报错(Rich Results Test)",
]
)
}
return report
# 把每次 Perplexity API 测试的结果存进来
vault_data = [
{"date": "2026-03", "engine": "Perplexity", "keyword": "你的关键词", "cited": False},
{"date": "2026-04", "engine": "Perplexity", "keyword": "你的关键词", "cited": False},
{"date": "2026-05", "engine": "Perplexity", "keyword": "你的关键词", "cited": True},
{"date": "2026-06", "engine": "Perplexity", "keyword": "你的关键词", "cited": True},
]
print(json.dumps(generate_geo_report(vault_data), indent=2, ensure_ascii=False))
每次跑完第八步的可见度测试,把结果追加进 vault_data 列表。季度末跑这个脚本,两分钟出结论。
30分钟落地清单
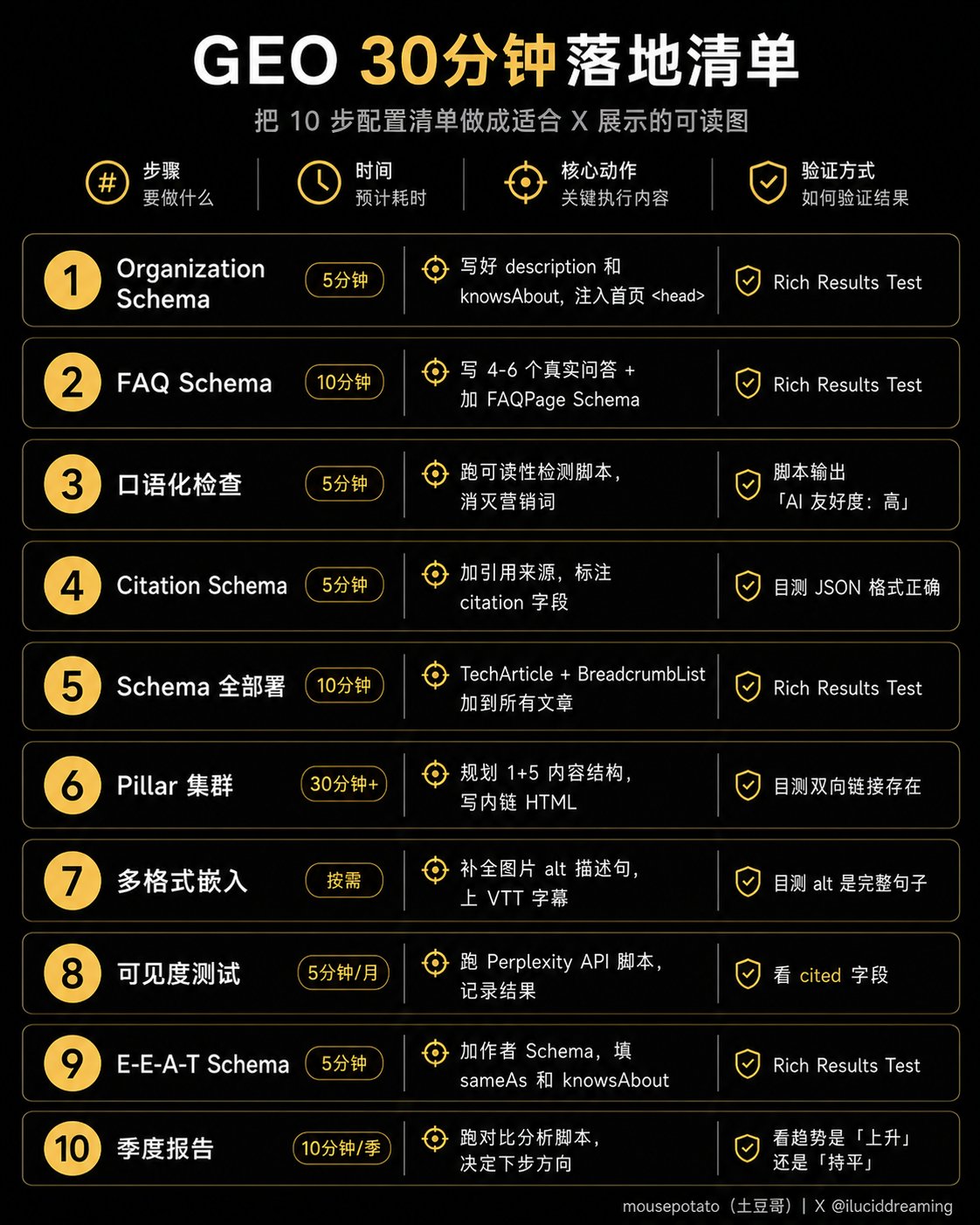
今天就能做完的:①②③④⑤,大约35分钟。
⑥需要额外规划内容结构,不是一次性工作,而是接下来内容创作的框架。⑦⑧⑨做一次,之后维护成本很低。⑩是每季度的例行动作。
这篇写的是地基。没有地基,内容再好也是沙滩上的城堡。配完这10步,你的内容对 AI 引擎来说才是一个「可以识别、可以验证、可以引用」的信息源,而不是一堆匿名文本。