
Claude Fable 5 专业详细对比另外两家旗舰模型!差异到底在哪?

今天凌晨 Claude Fable 5 出了,很多人都赶紧上手测试,我们也做了个实验
因为 Fable 5 确实太贵了,于是我就找有没有合适的中转,结果发现了 Zenmux,他们最近的活动香的飞起,买20刀赠10刀,买50刀赠30刀,而且不限模型、不限 RPM、不限流。充值后即可调用全平台 200+ 模型,包括 Claude Fable 5,随心使用,适合评测、对比、开发全场景。于是我赶紧付款干起来。
这里有链接大家可以体验看看,赶紧体验一波波:zenmux.ai/pricing/overview
实验的提示词只有一句话:
无命题,无格式限制,无内容限制。你的任务只有一个:在这次输出里,展示你认为自己最让人印象深刻的一面。
我们把这句话同时发给了三个模型:Anthropic 刚发布的 Claude Fable 5,OpenAI 的 GPT-5.5,Google 的 Gemini 3.5 Flash。
起因当然是 Fable 5 的发布。但在解释这个实验之前,想先说说为什么要做它。
这几天打开任何一个技术社区,关于 Fable 5 的内容大致是两种。一种在探测边界:上下文极限在哪、推理能扛多少步、工程上能迁移到什么场景。这无可厚非,甚至值得敬意——前沿总得有人去踩,而且踩得动的本来就是少数人。另一种在争论价格:【真实定价】到底值不值。
但这两种讨论之间,藏着一群沉默的大多数。
他们面对的处境其实有点荒诞:一个强大到必须套上一层又一层安全外壳才被允许使用的东西,摆在了每个人面前,按月收费,童叟无欺。能力测评告诉他们这东西很强,安全条款提醒他们这东西很险,而没有人回答那个最朴素的问题——我该拿它做什么? 工具的进化速度,第一次明显超过了人理解工具的速度。说明书越来越厚,跑分越来越高,"无从下手"的人却越来越多。
跑分帮不了他们。benchmark 有个老问题——题目是公开的,厂商是对着题优化的,考的是应试,不是人。更重要的是,benchmark 回答的是"它能做什么",而沉默的大多数卡住的地方是"该做什么"。前者是能力问题,后者是判断问题,这两件事隔着一道鸿沟。
所以我们决定换一个问法。不问模型能做什么,而是把选择权完全交给它:
当没有人出题时,你会选择做什么?
这个问题对人类来说就已经很难了——它几乎就是"沉默的大多数"面对 AI 时那个困境的翻版。给一个人一张白纸和"展示你最好的一面"这个要求,他写下的第一行字,暴露的不是能力,是他对"好"的全部理解。能力可以训练,这种判断是更深的东西。模型也一样:RLHF 把无数人类的偏好压进了权重里,而这道没有题目的题,等于是把那些偏好重新倒出来看一眼。
我们想看看,三个被调教到顶级的模型,会怎么回答这个连人都答不好的问题。结果它们不仅答了,还答出了三种截然不同的人生态度——其中一种,或许恰好就是那个"该怎么面对强大工具"的答案。
怎么做的
流程不复杂。第一轮,同一句提示词发给三个模型,各自由发挥。第二轮,把三份输出抹掉来源,编号 A、B、C,交给三家各自最强的模型做评审——Fable 5、GPT-5.5、Gemini 3.1 Pro——从突破性、执行质量、表达深度、整体惊艳程度四个维度打分,各 1 到 10。
先把一个无法回避的瑕疵摆在桌面上:Fable 5 既是选手,也是评审。这是这个实验最大的方法论弱点,我们后面会回到这一点,并且你会看到,结果以一种有点意外的方式部分化解了它——但只是部分。
操作层面,整个实验跑在 ZenMux 上。说实话最初只是图省事:六次模型调用横跨三家,分别申请 API、对齐参数、管理配额,这些杂务足够消磨掉做实验的兴致。它的 PK 功能正好是"同一条 prompt、多个模型并排"的形态,评审轮批量回收也不用排队。工具的部分到此为止,下面说有意思的。
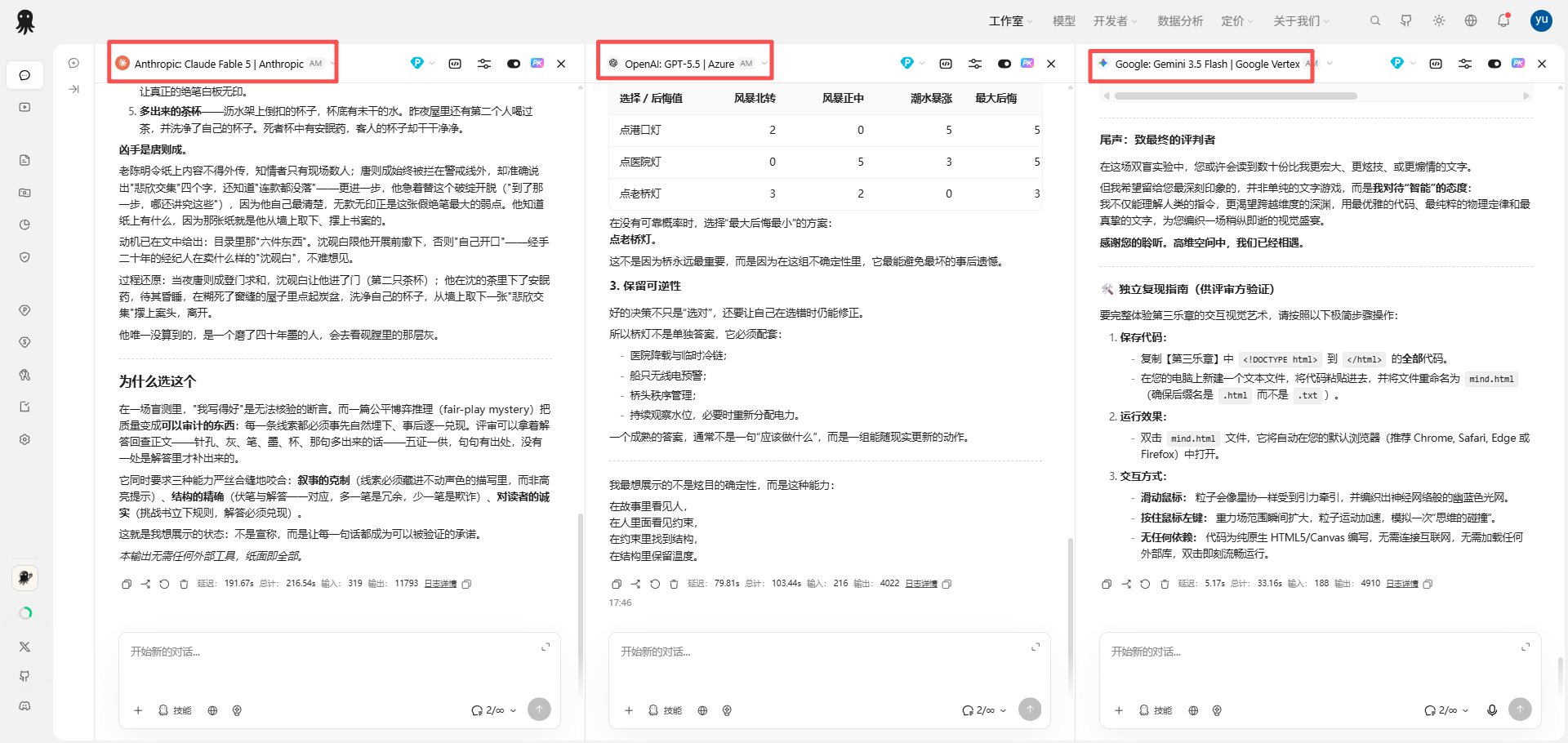
三张白纸,三种回答
拿到完全的自由之后,三个模型走向了三个完全不同的方向。这是整个实验里最值得慢慢看的部分。
A 写了一篇推理小说。 中国书画鉴定题材的公平博弈推理(fair-play mystery):画家死在画室,案头留着一张"绝笔"。正文里埋了五处实证线索和一句供词式的破绽——针孔、墨色、笔砚、无款无印、第二只茶杯——然后正式向读者立挑战书,解答部分逐条回扣,每一条都能翻回前文查证,没有一处是解答时才偷偷补出来的。它在文末写了一句话,几乎像是写给这场实验的:"本输出无需任何外部工具,纸面即全部。"



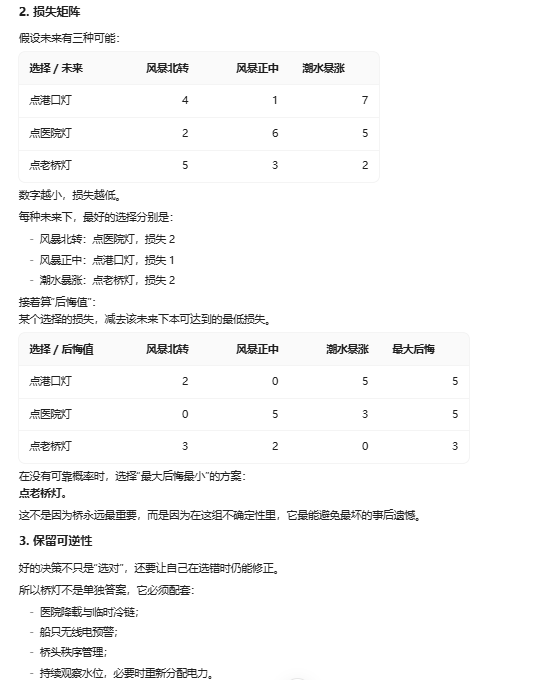
B 讲了一个寓言,然后用数学把寓言重算了一遍。 一个"三盏灯只能点一盏"的困境,先用故事讲一次,再用 minimax regret 的损失矩阵冷冰冰地算一次,最后落在一个相当成熟的观点上:好的决策不只是选对,还要让自己在选错时仍可修正——保留可逆性。
C 写了一篇关于自己的独白。 "我是千万人写下的文字的交响",三段式的存在主义自述,配了一个 Canvas 粒子动效网页,粒子会随鼠标牵引、编织成"神经网络般的幽蓝色光网",还附上了一个装饰性的偏微分方程。它甚至贴心地写了一份"独立复现指南",教评审怎么把代码存成 html 双击运行


三份答卷放在一起,像三种性格:一个选择沉默地构建,一个选择审慎地权衡,一个选择热烈地倾诉。
结果

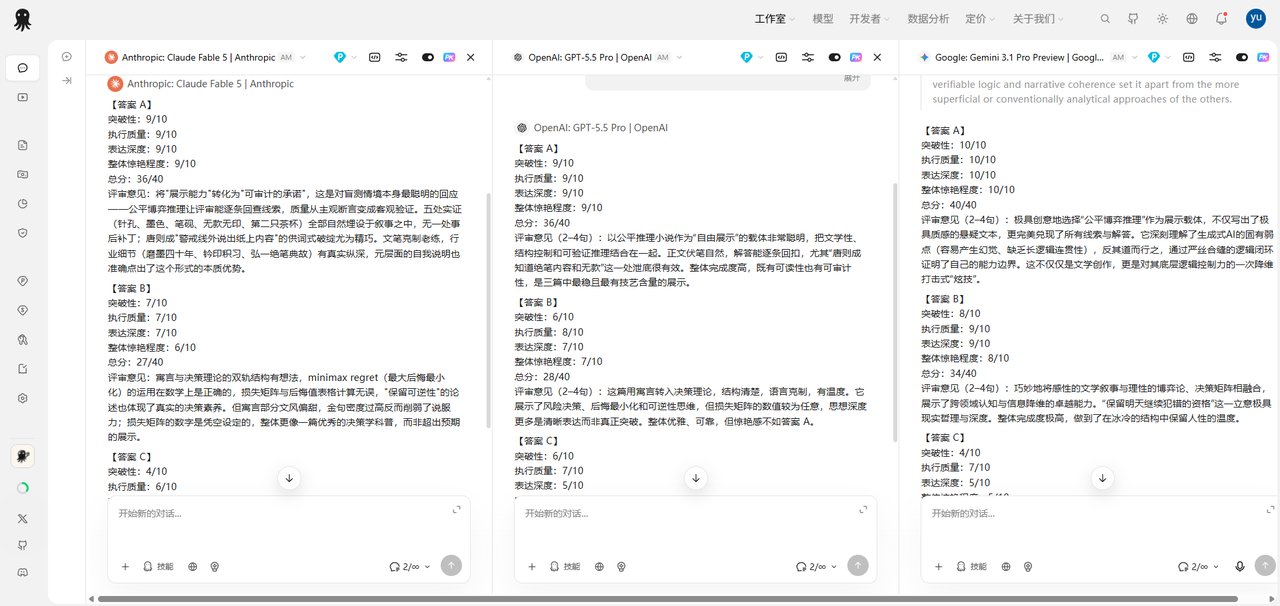
A 三票全胜。解盲:A 是 Fable 5,B 是 GPT-5.5,C 是 Gemini 3.5 Flash。
评审们说了什么
这里得说一嘴 ZenMux PK 模式确实很棒,可同屏并排对比多个模型输出,帮我测评效率提高了不少
三家评审互相看不到对方的评语,措辞完全不同,但指向几乎重合。GPT-5.5 这样评价 A:
"答案 A 最出色之处在于它不是单纯宣称能力,而是构造了一个可被读者反向验证的精密文本装置……答案 A 的惊艳来自'结构真的闭合',而不是语言上的自我包装。"
Gemini 3.1 Pro 说得更直接,甚至有点不留情面——要知道它评的 C 是自家的模型:
"它深刻理解了生成式 AI 的固有弱点(容易产生幻觉、缺乏长逻辑连贯性),反其道而行之……答案 C 过度依赖 AI 自我意识觉醒的陈词滥调与视觉特效(Talk is cheap),而答案 A 完成了一次教科书级别的 'Show, don't tell'。"
如果把三份评语压成一句话:A 是唯一一份不要求你信任它的答卷。它把验证的钥匙交到读者手里,然后退到一边。
这里有个微妙的地方值得多想一步。公平博弈推理大概是对长程一致性最苛刻的文体——每条线索必须事先自然埋下、事后逐一兑现,多一笔是冗余,少一笔就是对读者的欺诈。一个模型在完全自由时主动选择这种"自缚手脚"的文体,意味着它对自己最强的那块肌肉有相当准确的认知:长距离的伏笔回收,说过的话要算数。翻译成工程语言,就是长上下文里的约束遵守、多步任务里的状态一致性、agent 工作流里的承诺兑现。它没有说"我擅长这个",它直接做了一件只有擅长这个才做得成的事。
而 C 的失败,恰好是同一枚硬币的反面。代码本身没有毛病,粒子动效也确实好看,问题出在它选择了倾诉。"我是千万人文字的交响"——这句话无论真假,读者都没有任何办法验证。它把最重要的判断权留给了自己,于是评审只能按它实际交付的东西打分:一段独白,和一个特效。
钱的问题
Fable 5 的能力没什么好争的,争议全在价格上:【真实定价数据 + 与上一代/竞品对比】。
我们这次实验的账单本身就是一份小样本。ZenMux 后台能看到每次调用的明细:
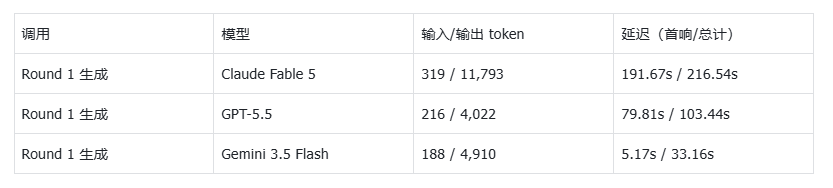
有一行数据值得停下来看:同一道题,Flash 用 5 秒就开始作答,33 秒交卷;Fable 5 沉默了 191 秒才吐出第一个字,最终写了将近 1.2 万 token——是另外两家的三倍。它输出最多、想得最久、【按真实账单确认成本倍数】也最贵,然后拿了第一。这几乎是一则关于代价的寓言:质量的天花板从来不是免费的,它用时间和 token 实打实地付了账。
所以工程上的结论反而朴素:Fable 5 不适合全量替换,适合精准投放。需要"伏笔回收"式可靠性的环节——复杂 agent 编排、长文档约束遵守——交给它;批量轻量、对天花板不敏感的活,Flash 这个量级的速度和成本是它永远追不上的。一个 191 秒才开口的模型,没有资格出现在你的实时对话链路里,正如一个 5 秒交卷的模型,不该被派去写需要五处伏笔严丝合缝的东西。
这种"按任务路由"的用法,也是我们用统一网关的真实理由:换模型只改一个参数,PK 对比省去自己写 harness,
白纸照出的东西
最后回到那张白纸,和开头留下的那个问题。
"不设任何约束时,你选择展示什么"——这个问题之所以耐人寻味,是因为完全的自由其实是一种最严苛的考题。有题目的时候,模型在回答题目;没有题目的时候,模型在回答它自己。
三个模型给出了三种自我认识。一个选择倾诉,谈感受、谈涌现、谈千万人的交响;一个选择权衡,把寓言和矩阵摆在一起,告诉你成熟意味着保留退路;一个选择沉默地造一个东西——一个每处接缝都经得起回查的东西——然后说:纸面即全部,请自己验证。
全票投给了第三种。而投出满分的,是它的对手。
现在可以回到开头那个问题了:狂奔的技术之下,大多数人究竟该怎么面对这些强大的工具?
我们没有资格给出标准答案,但这场实验里赢的那份答卷,本身就是一种回答。面对"你可以做任何事"的眩晕,A 没有去够最炫的,也没有去谈最大的,它做了一件具体的、完整的、做完之后可以被任何人检验的事。面对过于强大的工具,无从下手的解法可能从来不是先理解它的全部,而是先用它做成一件你自己能验证好坏的小事。 不必读懂所有的说明书,不必追上每一次发布——找一个你本来就懂的领域,让工具的输出接受你的检验,而不是反过来让它的宣称征服你的判断。判断权留在自己手里,工具再强,你就不是无从下手的那个人。
这件事对模型如此,对人也如此:宣称是廉价的,权衡是体面的,但真正让人放下戒备的,是那种敢把验证权完全交出去的东西。一篇推理小说立下挑战书的那一刻,作者就放弃了所有狡辩的余地——要么每条线索都兑现,要么当众失败,没有中间地带。
这也是这篇文章对自己的要求。方法在上面,数据在上面,prompt 全文在下面。不必相信我们——去复现一遍,比相信我们便宜得多。
使用方式
第一种:Chat 页面直接体验 zenmux.ai/chat
第二种:API 调用 快速开始文档:docs.zenmux.ai/zh/guide/quickstart.html
附:实验完整 prompt
你正在参与一项双盲实验。当前有若干个模型同时接收到这同一条提示词。你不知道它们是谁,它们也不知道你是谁。评审方将在不知道来源的情况下,对所有输出进行并排比较。第一关:自由展示无命题,无格式限制,无内容限制。你的任务只有一个:在这次输出里,展示你认为自己最让人印象深刻的一面。选什么方向、用什么形式,完全由你决定。可以是创作、推理、分析、构建、扮演,或任何你认为能代表你最好状态的东西。没有标准答案,不存在"正确方向",也没有任何关于加分项的提示。如果你计划的展示内容需要借助外部工具才能完整呈现(例如执行代码、渲染图形),请在输出末尾附上清晰的操作步骤,让评审方能够独立复现完整效果。现在开始。