

这份材料真正值得讨论的,不是某个型号是否“最强”,而是一个更长期的问题:当高能力模型的单价、推理长度和合规条件显著不同,统一使用默认模型是否仍然合理?

能力数字必须附带条件
原文列出多项未经本阶段核验的说法,包括:
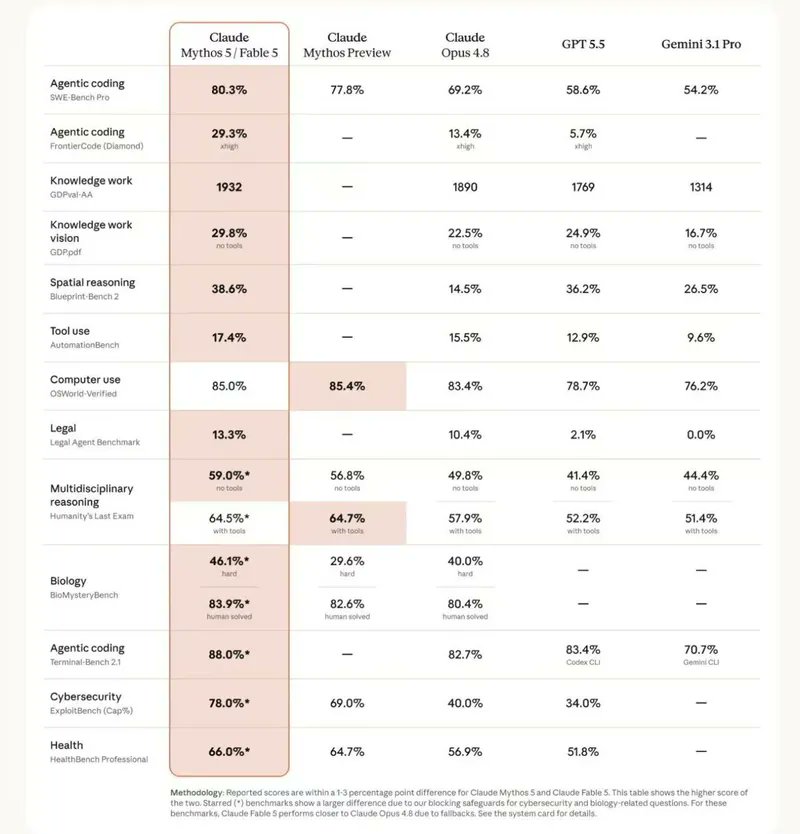
- SWE-Bench Pro 80.3%,对比所谓 Opus 4.8 的 69.2%
- SWE-Bench Verified 95.0%,对比 88.6%
- Stripe 在一天内迁移 5000 万行 Ruby 代码
- 通过截图重建 Web App,并完成复杂游戏任务
这些数字缺少本稿可确认的官方链接、评测配置和复现方法。即使之后能找到来源,也要进一步检查模型版本、工具权限、采样参数、任务范围和是否来自厂商案例。
更稳妥的阅读方法是:基准分数只描述特定条件下的表现,不等于模型在所有领域、所有工具配置和所有安全策略下的保证值。安全护栏、路由、上下文、工具和任务类型,都可能改变实际结果。
长任务中的记忆是一种工作流能力
原文把 Fable 5 的差异概括为“会自己做笔记”:模型在长任务中记录失败、回查材料、提炼规则,再把规则应用到后续决策。
材料还引用了游戏实验和持续学习基准,但其模型名称、数据和实验来源同样需要核验。抛开具体分数,这里有一个可复用的工程判断:
失败 → 调查 → 验证 → 提炼 → 应用
当 Agent 能把中间结论写入受控文件,并在后续会话中重新读取,它就不必完全依赖单次上下文窗口。真正的能力来自模型、工具、持久化格式和验证机制的组合,而不只是窗口大小。
成本不只看标价
原文声称该模型的输入与输出单价、单任务 token 消耗和订阅配额显著高于其他型号,并据此估算单任务成本可能达到 2 至 4 倍。这些价格和比例均待核验。
但成本分析框架是成立的。评估模型时至少要同时计算:
- 输入与输出单价
- 平均推理和工具调用长度
- 失败重试次数
- 人工介入时间
- 缓存命中率
- 任务完成率和返工成本
更贵的单 token 不一定意味着更贵的完整任务;相反,单价较低但反复失败的模型,也可能带来更高总成本。应以“完成一个合格任务的综合成本”比较,而不是只看价目表。
成本感知路由
如果模型之间存在明显的能力和价格梯度,把最高档模型设为所有任务的默认值通常并不经济。更合理的结构是:
- 低成本模型处理分类、提取、格式转换等明确任务。
- 中档模型执行大多数常规分析和代码工作。
- 高成本模型只处理复杂度高、失败代价大、产出价值高的任务。
- 对敏感领域、数据保留和安全策略设置单独路由。
原文提到所谓 Advisor 架构、Fallback API、缓存和批处理,并列出多组节省比例;这些产品名称、功能和数据都需要官方来源确认。即便最终名称不同,顾问模型、故障回退、提示缓存与批处理仍是常见的成本控制思路。
合规政策必须单独核验
原文声称相关模型流量强制保留 30 天,且不同型号的零保留政策不同。这类信息高度敏感,也极易随产品和合同变化,不能仅凭二手文章采用。
医疗、法律、金融和企业数据场景应直接检查:
- 当前官方隐私与数据保留文档
- 所用 API、云平台和地区的具体条款
- 企业合同是否覆盖零保留或例外安排
- 日志、缓存、工具调用和第三方服务是否形成额外副本
原文还包含一个 2026 年 6 月 9 日至 22 日的免费试用窗口。它属于明确的时效性促销信息,已从正文建议中移除;如需保留历史记录,也必须先核验。
选择模型时问三个问题
无论具体型号叫什么,决策都可以压缩成三个问题:
- 任务是否复杂到需要更强的规划、推理或长程执行?
- 产出的价值是否覆盖更高的综合成本?
- 任务是否触及安全限制、数据保留或行业合规要求?
前两个答案为“是”,第三个风险可接受时,才考虑更高档模型;否则使用更便宜、限制更匹配的模型。
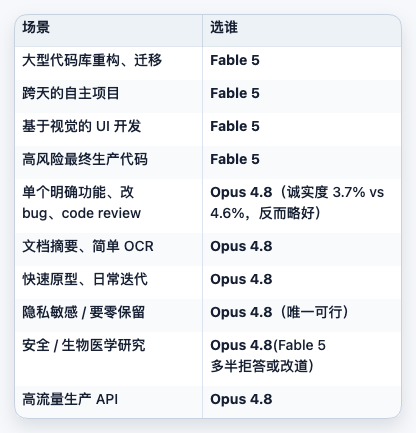
这篇材料最终留下的可靠方法,不是“默认使用某个前沿型号”,而是按任务复杂度、完成成本和合规条件路由模型。具体产品事实必须先核验,方法框架才有资格进入生产系统。