
基于 xai-org/x-algorithm 仓库 5 月 15 日提交的深度对比分析**【只做新增解读,原有逻辑请参考配套阅读】**
2026 年 5 月配套阅读:《X 算法深度调研报告:创作者实战指南》(v1,2026 年 1 月)【50w阅读】
*共 23000 字、25 张图 🖼️/需要 38 分钟 *🕙
写在前面
- 黄推居然没了!牛牛牛!(小狼失业了)
- 不要发送成人内容(经验证黄推都不敢发了)
- 评论区的垃圾广告评论尽快删除,会影响主贴流量
- 评论区课代表的春天来了,乱刷评论的会被惩罚
- 缓存策略导致一天发几十条的反而比每天认认真真发一条的流量好得多得多(这个以后应该会调整)
- 混圈子越来越重要了,圈子互动更加重要(目前有效,但是以后估计也是会调整)
2026 年 1 月,X 第二次开源了它的推荐算法,我写了一份《X 算法深度调研报告:创作者实战指南》【50w阅读】带你看懂这个"黑盒子"。
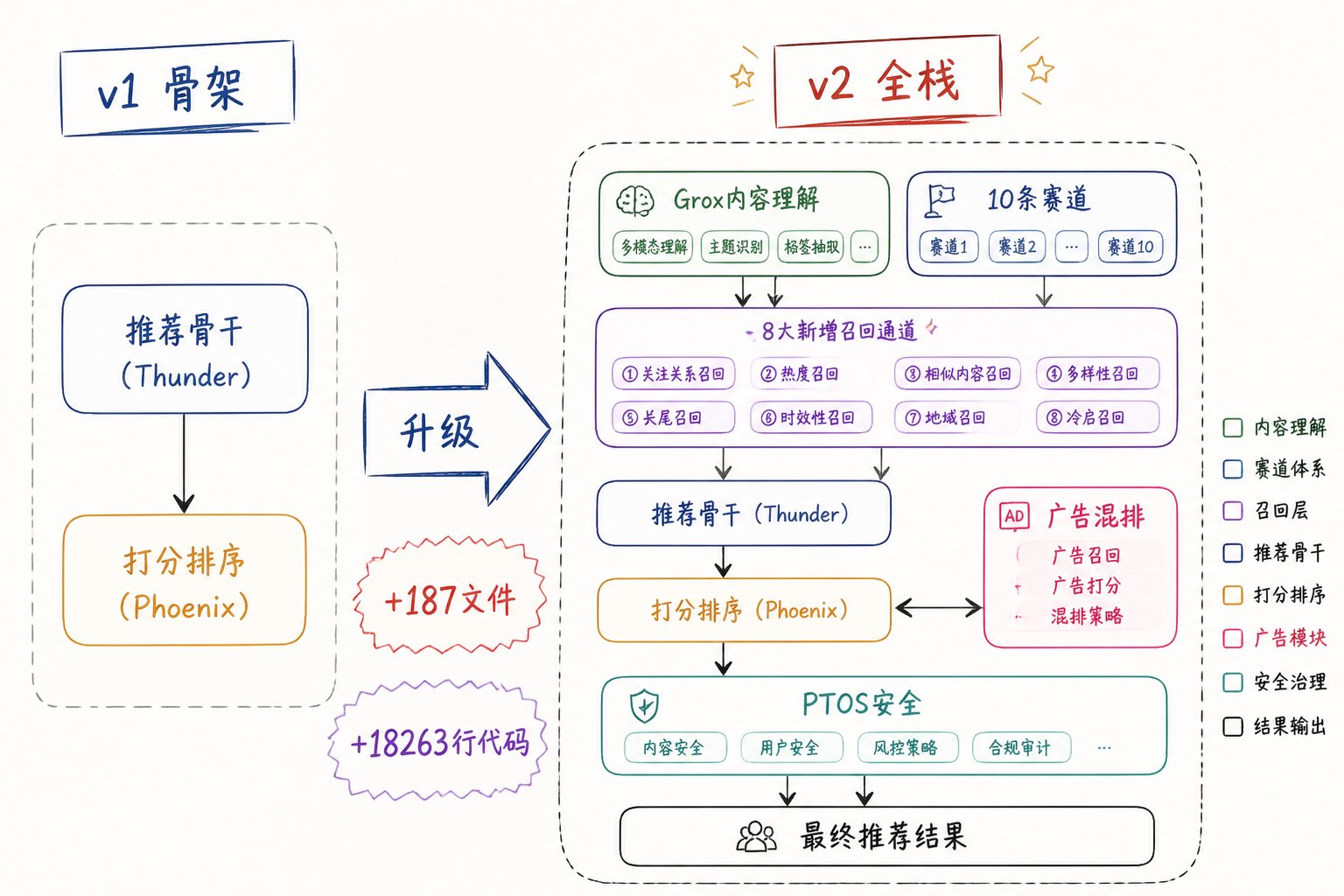
四个月后,X 又一次更新了这套代码——这一次是重大补全:
- 新增 187 个文件
- 新增 18,263 行代码
- 全新的 Grox 内容理解管线(59 个文件)
- 全新的 广告混排系统
- 全新的 8 条候选召回赛道
- 模型架构、过滤规则、社交信号全面升级
如果说 1 月那次开源让我们看到了 X 算法的"骨架",这次更新就是把"血肉"全亮了出来——所有以前藏在中后台的"内容审查、新用户冷启动、广告调度、圈层推荐"机制,这次全部公开了。
这份报告不是替代 v1,而是对 v1 的关键补丁。如果你还没读过 v1,建议先读那篇,再回来看这篇。(这一个新算法感觉是 AI 写的,因为太牛逼了,黄推没了、搬运干死)
开篇:5 月 15 日,到底发生了什么?
一句话总结
算法长出了三只新眼睛(Grox 内容理解 + 圈层社交 + 话题画像),新增了一位内容审查官(PTOS 安全管线),还多了一位广告调度员(Ads Blender)。
这次更新的本质:从"主干公开"到"全栈公开"
给创作者的 3 个核心提醒
**提醒一:你的"回复"现在被独立打分。**不只是原帖被算法评判,每一条评论也有自己的 0–3 分,0 分会触发 spam 标签动作——以前以为评论区是"加分项",现在它是一个独立赛道。(也就是说评论区的垃圾评论会拉低你的主贴权重😂)
提醒二:新用户冷启动玩法彻底变了。以前新账号靠"内容质量出圈";现在新用户注册时勾选的 Grok 话题会变成硬性过滤规则——不命中话题集的内容根本不会被推到他们的发现流。(如果你是AI博主恭喜你数据会更好,没什么人拒绝 AI 话题,但是如果你是币圈博主,你的日子会更加难过😫)
提醒三:私密账号被多个新管线"静默排除"。保护账号 ≠ 保护曝光,而是失去机器理解——你不会被打质量分、不会被生成多模态嵌入、不会进入安全审查……换句话说,你成了算法的"陌生人"。(如果你设置私密账号,那么你的流量不会好的,这也是求仁得仁吧)
第一章:新增的"内容质检员" Grox 是谁?
Grox 不是 Phoenix 的替代,而是它的"上游供应商"
很多人看到 Grox 这个名字会以为它要替代 Phoenix。错了。
实际上,它们是上下游分工:
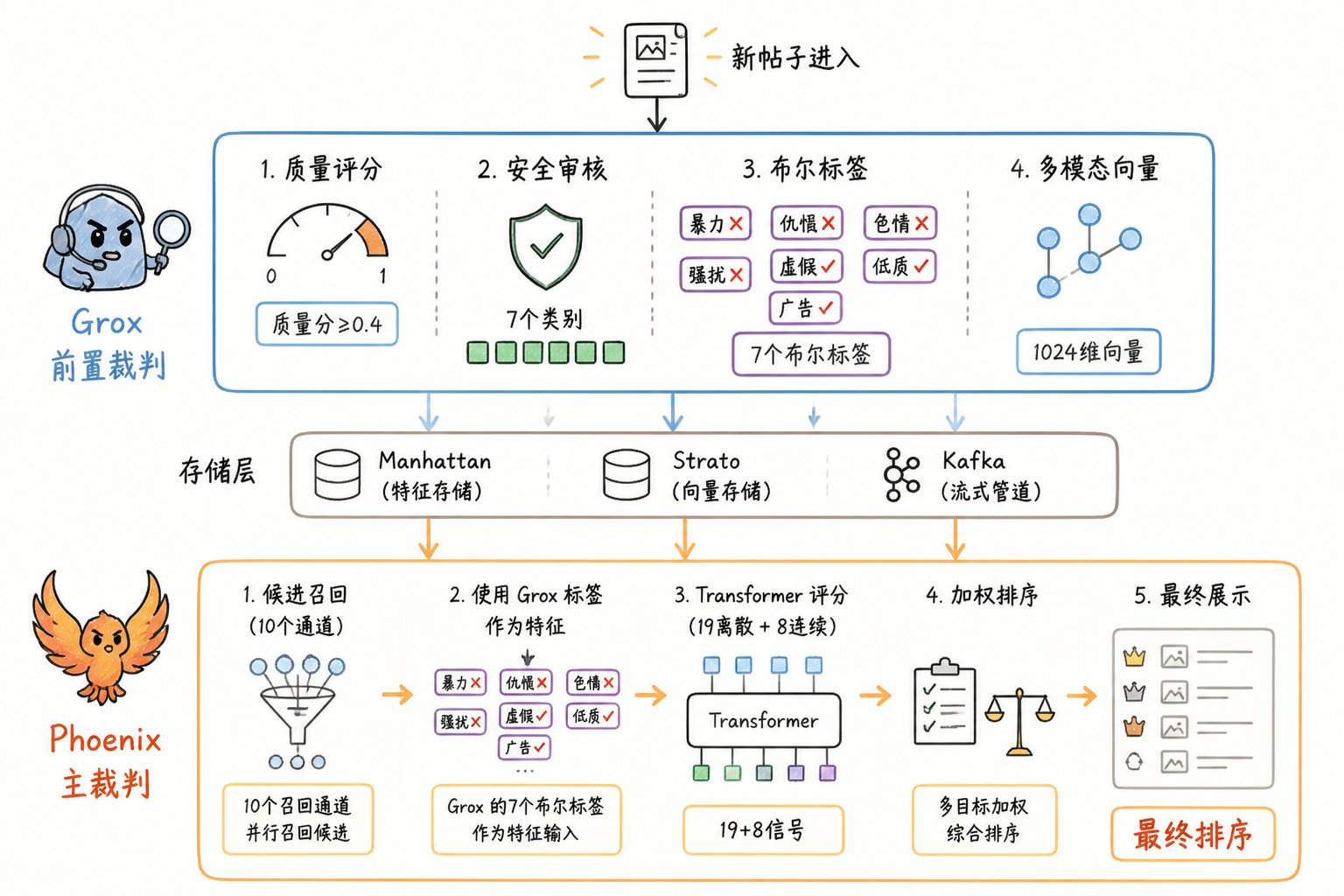
关键点:Grox 的产出(质量分、安全标签、嵌入向量)会喂给 Phoenix,Phoenix 用这些信号做最终排序。所以 Grox 是"前置裁判",Phoenix 是"主裁判"。
Grox 对每一条新帖会做的 5 件事
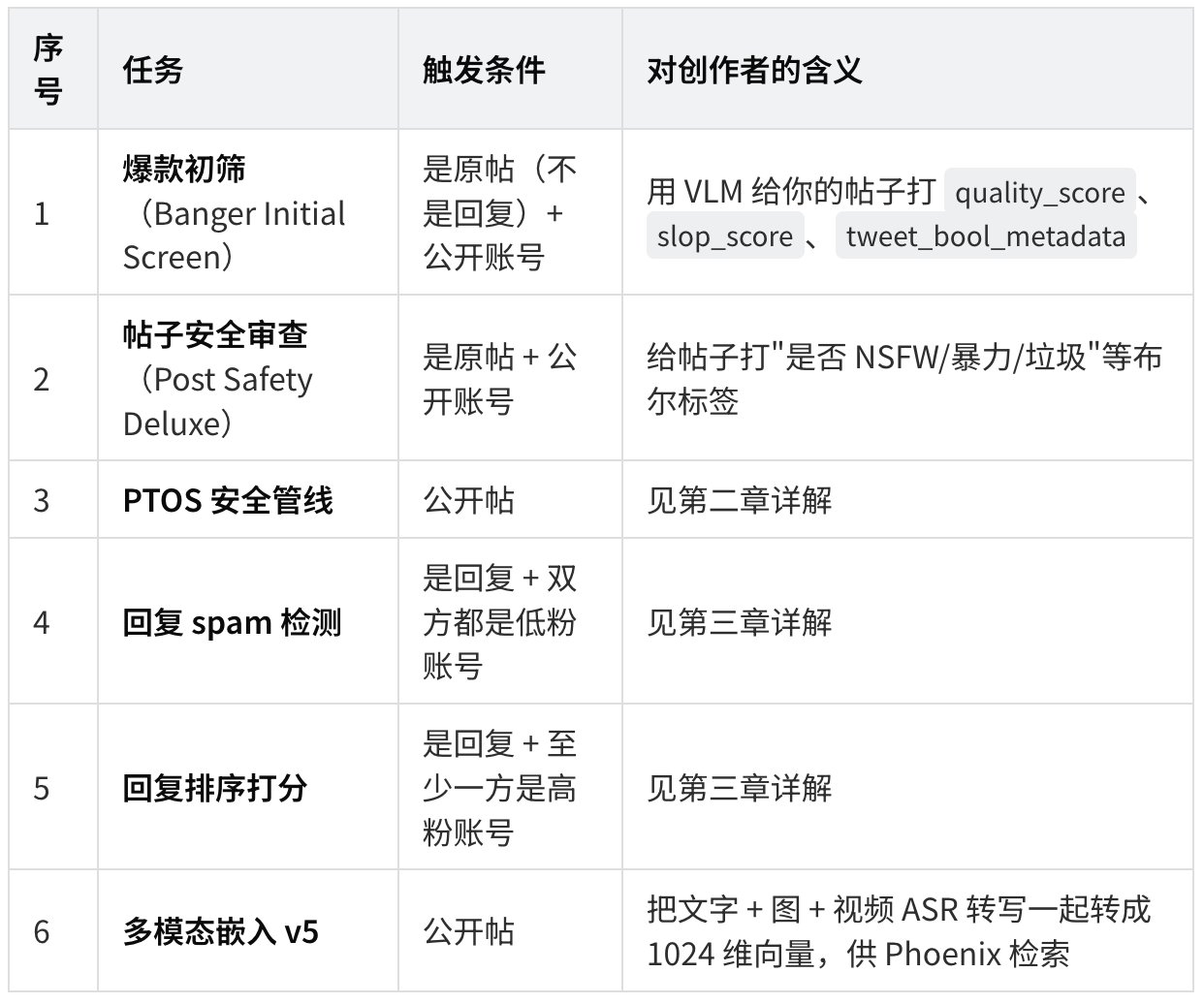
关键发现 1:质量分 ≥ 0.4 才算"初筛通过"
代码里写得明明白白:
quality_score >= 0.4 → positive(初筛通过) quality_score < 0.4 → negative(被打入"低质"档位)
这意味着 X 的算法对你的内容有一个隐形的质量门槛——主流大模型(VLM_PRIMARY,温度 0.000001 等于"无创意完全确定")会用一套固定的提示词模板给你打分。
通过这道门,并不保证你能爆——但不通过,意味着你后续的扩散将处处受阻。
这里如果能知道他的提示词就好了,这样就可以在发帖之前就知道自己的帖子是否有问题(这个我立个 Flag 尝试做一版本出来,大家敬请期待)
关键发现 2:你的帖子会被 Grok 打 7 个布尔标签
经过 Grox 的爆款初筛后,每条帖子会被生成一组布尔元数据(tweet_bool_metadata),写入 X 的 UPA(Unified Post Annotations,统一帖子注解)系统:
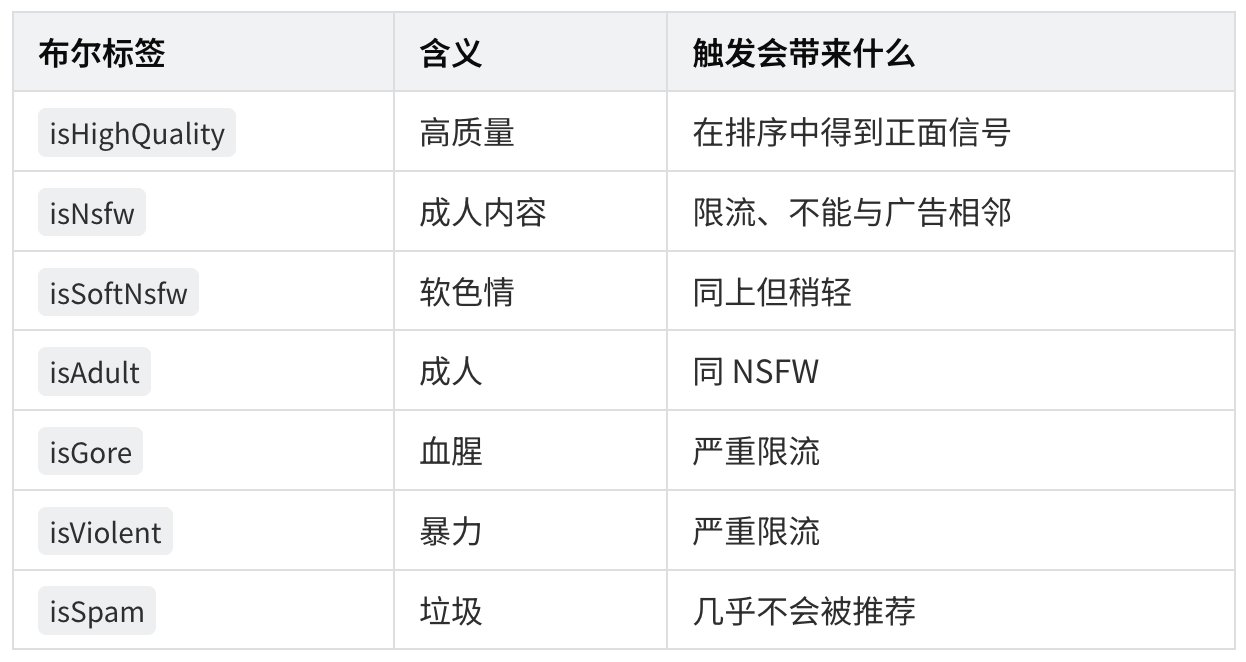
重要:这些标签是 VLM 多模态大模型直接判断的,不是简单关键词匹配。这意味着:
- 你写的文字虽然没有明显违规词,但配的图片如果触发标签,整条帖子会被打上对应布尔
- 视频里出现一闪而过的不当画面,ASR 文字 + 视频帧联合分析仍可能命中
还有一个被忽视的"灌水分" slop_score
Grox 还会给帖子打一个 slop_score(灌水/低质分),分为 1、2、3 三档——分数越高越被认为是"水帖"。具体语义代码里没明确写,但从命名可以推测:模板化、低信息量、AI 生成痕迹明显的内容会被打上高 slop_score。(但是按照我们的经验,这一块儿的判断不是特别准确,黄推、搬运、抄袭好像识别的不是特别精准😮💨)
创作者对策:
- 避免一稿多发(哪怕换说法)
- 避免明显的 AI 生成"模板感"(统一句式、固定开头)
- 避免单帖只有几个字 + 一张图的"凑数贴"(我刚发的一张图就爆了,所以这里有点玄学)
- 视频帖要有真实信息密度,不能只是配乐 + 一段废话(我严重怀疑他们是否舍得每个视频都处理,所以最优方案是识别视频 meta 信息,一样的统一处理,不一样的抽查,先把拌匀的排除掉然后工作量少了 90%,再做后序的识别,但是我怀疑 x 是否舍得投入资源,目前看没有🤣)
第二章:你不知道的 7 大"安全红线"(PTOS)
PTOS 是什么?
PTOS = Platform Terms of Service,平台条款安全管线。它是 Grox 的一个独立任务流,专门给帖子做违规分类。
PTOS 流程是两层:
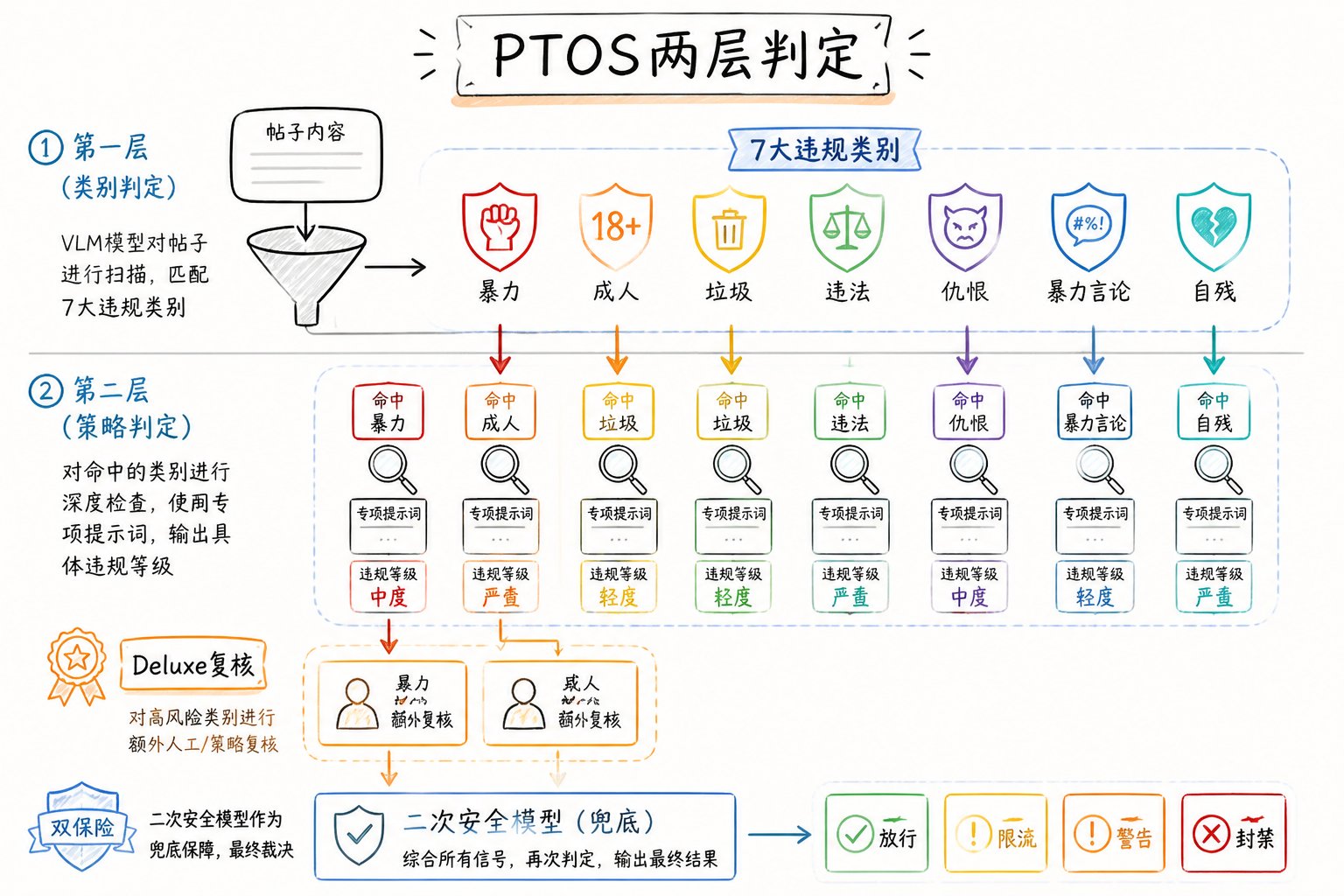
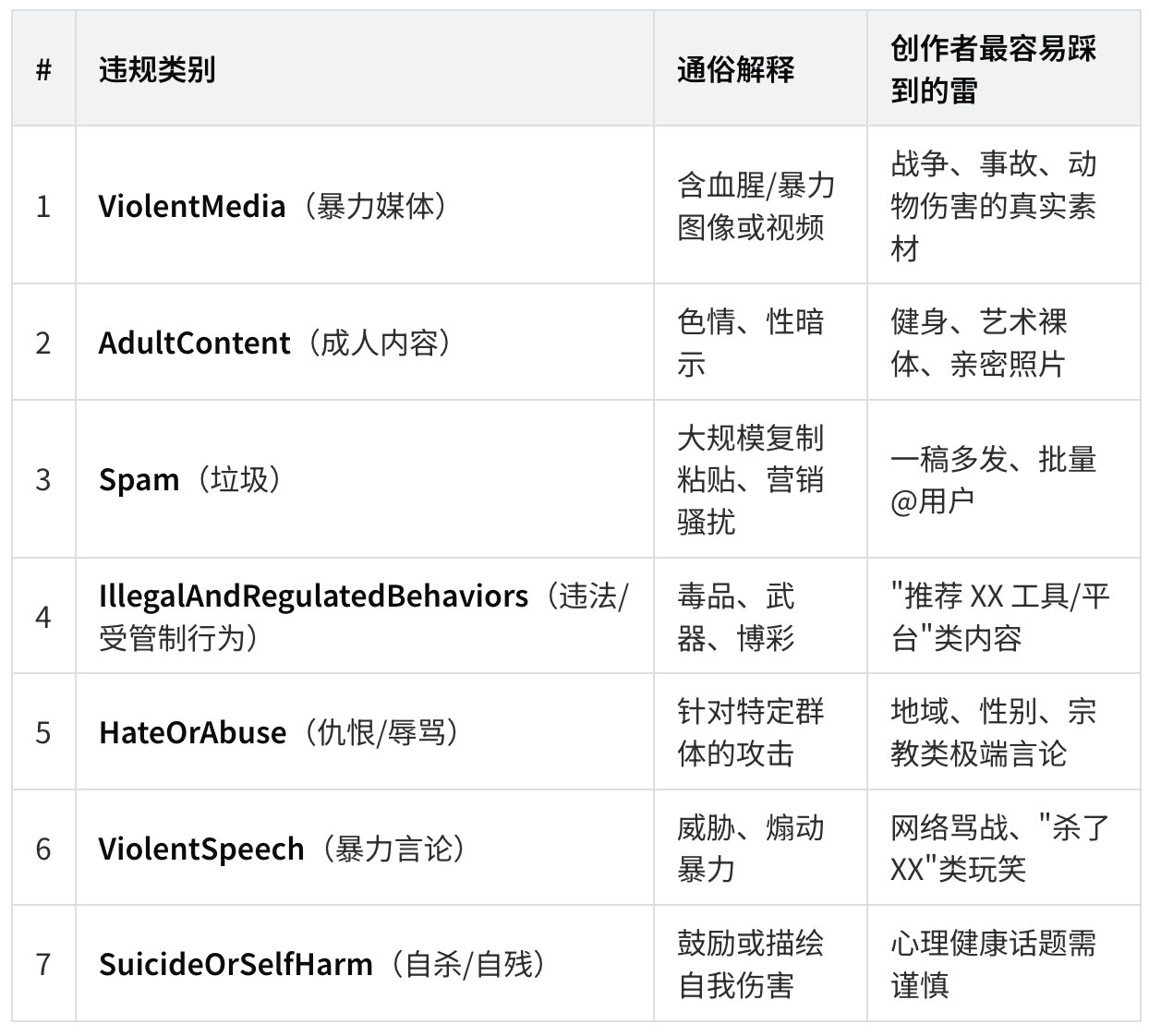
7 大违规类别(代码硬编码)
代码里完全列出了PTOS 关心的 7 大类违规:
"Deluxe 复核"机制
代码里还有一个 deluxe(增强)模式:对成人内容和暴力媒体这两类,会额外用更强的模型做一次复核(专门处理"边缘案例")。
这意味着:
- 这两类是 X 最敏感的内容
- 即使第一次没被命中,仍可能被第二次复审"翻案"
- 健身、艺术、新闻类创作者要格外小心配图
一个"非 Grok"的兜底机制
代码里还藏着一个变量 safemodel_sex_nudity——这是一个独立于 Grok 的安全模型。它的作用是:
如果 Grok PTOS 判定为"无成人内容",但 safemodel_sex_nudity 模型说"有",强制追加一条 AdultContentSexualHard 注解,再次触发 grokPtosActionWithLabels 动作。
也就是说:安全审查有"双保险"——你不能指望"Grok 没打标签就万事大吉"。
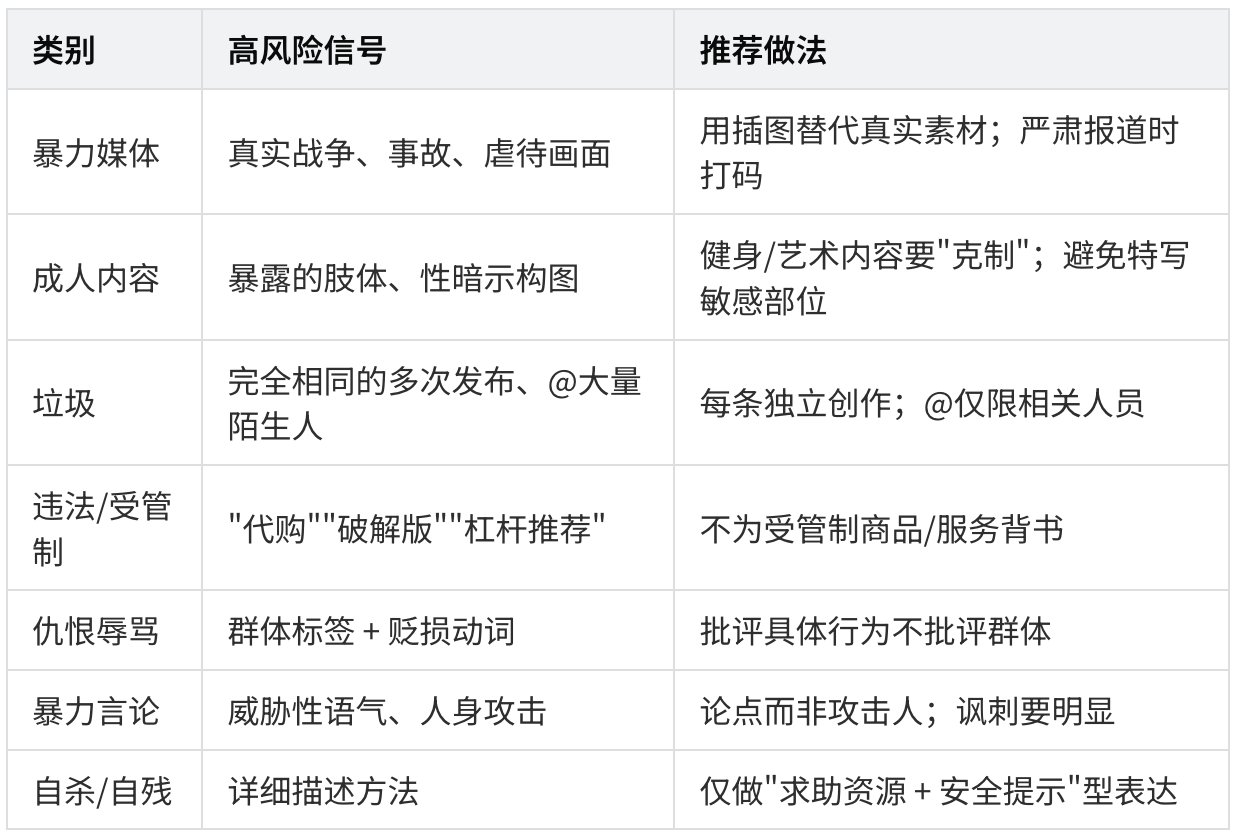
创作者对策表
第三章:你的"回复"现在被单独打分了
一个被严重低估的发现
打开任何一条帖子的评论区,你看到的回复顺序,不是按时间、不是按点赞,而是按一套独立的算法打分排出来的。
这次开源完整公开了这套算法。
评论区双管线:Spam 检测 + 回复打分
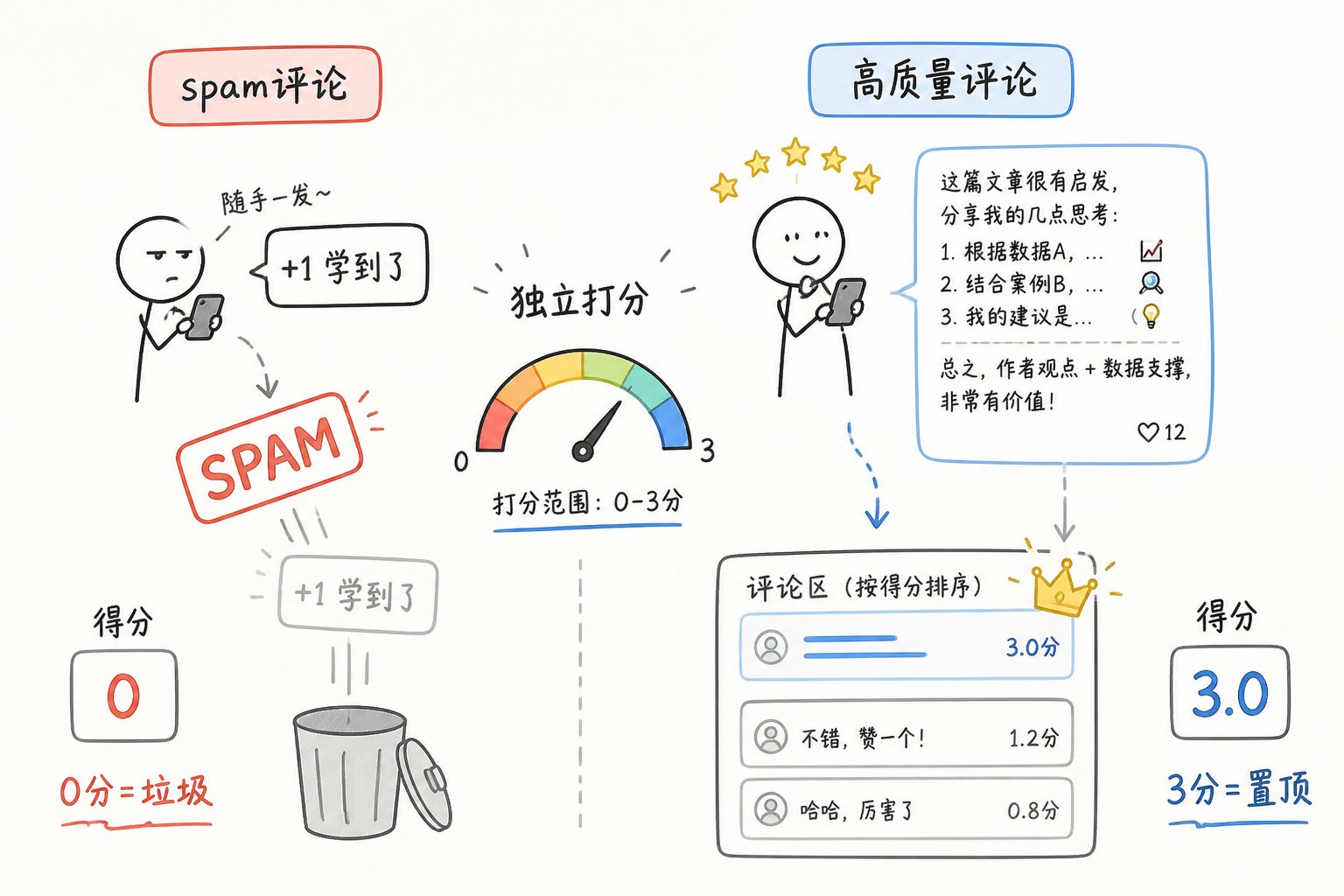
关键发现:评论得 0 分 ≠ 没人看见,而是"被算法判垃圾"
代码里写得很清楚:
if score == 0.0: grokReplySpamActionWithLabels(...) # 触发 spam 标签动作
这意味着:
- 你给某个大 V 评论想"蹭流量",如果 Grok 打了 0 分
- 这条评论不仅会被压到最底下,还会在你的账号上留下"曾发过 spam 评论"的标签(所以到处刷评论的需要注意了)
- 长期可能影响你账号的整体信用
以前就是粗暴的篮V排在前面,现在这个时代过去了
给"评论区运营"的具体建议
反直觉的好策略:在大 V 帖子下留一条有信息增量、能引发其他人回复的高质量评论,可能比你自己发 10 条普通帖更有效——因为这条评论的曝光等于"借了大 V 的流量入口"。
第四章:算法到底"看"什么?——19 个离散信号 + 8 个连续辅助头
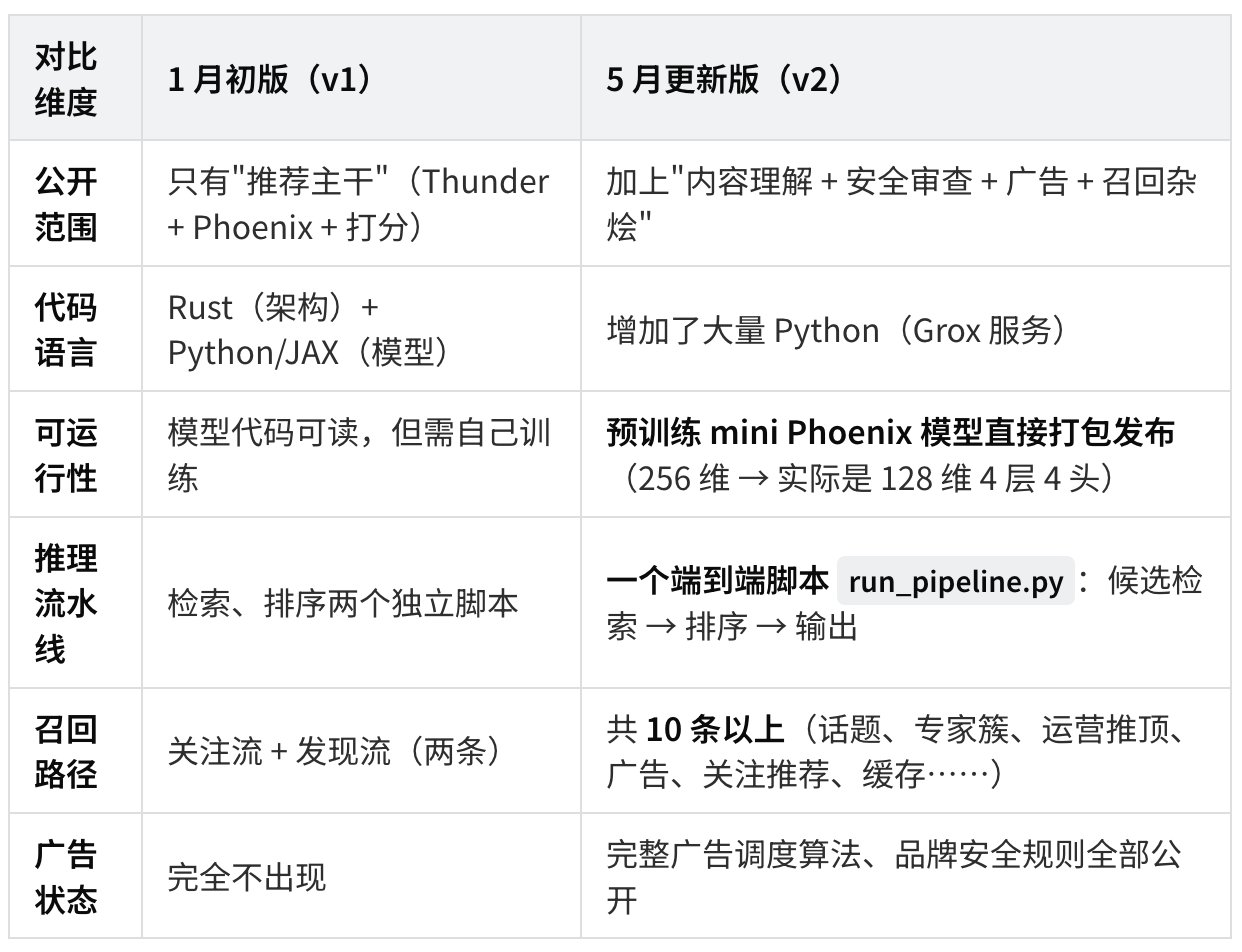
重要更正:v1 报告里说的"18 种行为"
读源代码后我发现 v1 的"18 种行为"略有偏差。实际上:
- 离散行为预测头:19 个(不是 18)
- 这次新增的:8 个连续行为辅助头
这给了我们一个更精确的算法面貌。
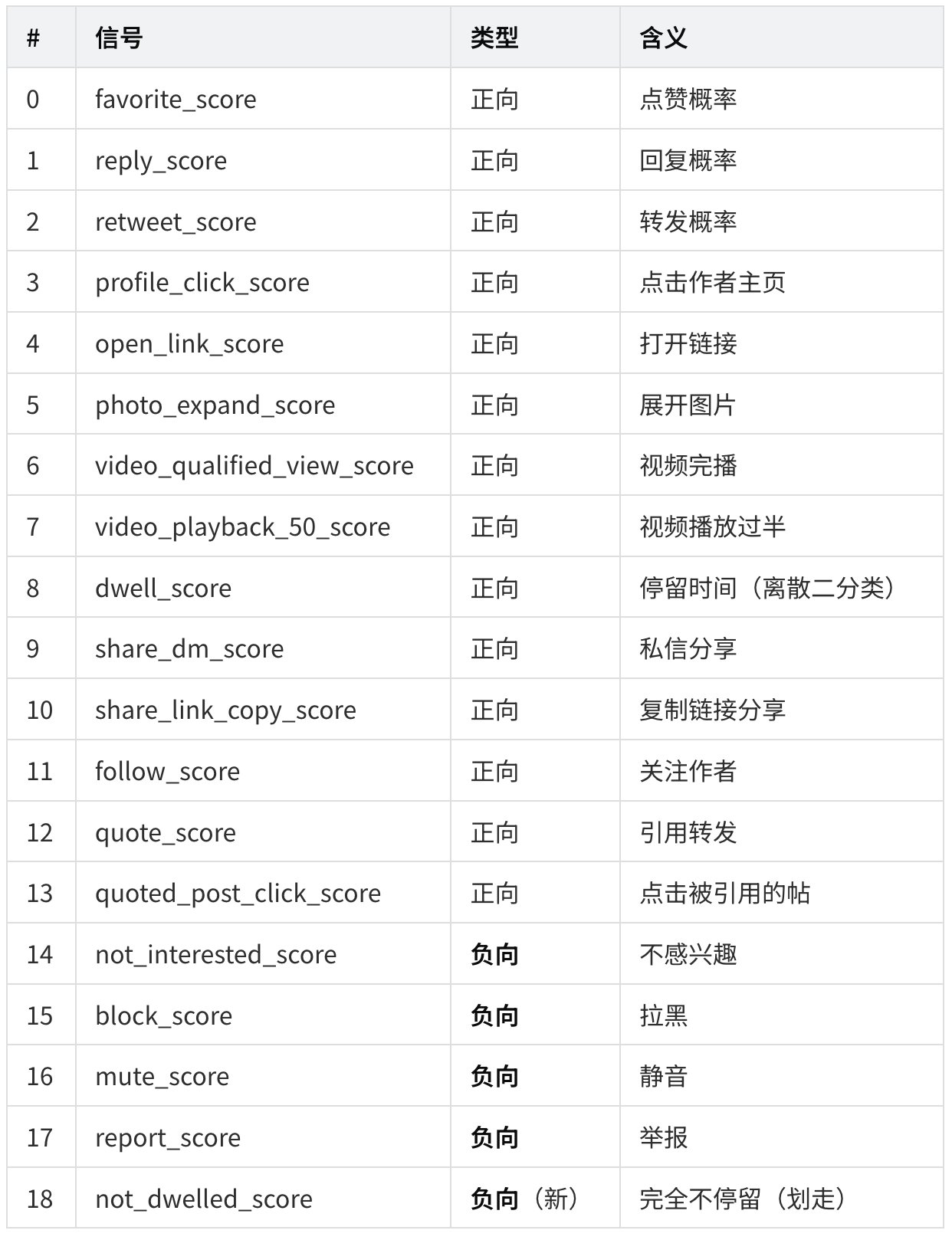
**19 个离散行为头(以 **runners.py中的 ACTIONS 为准)
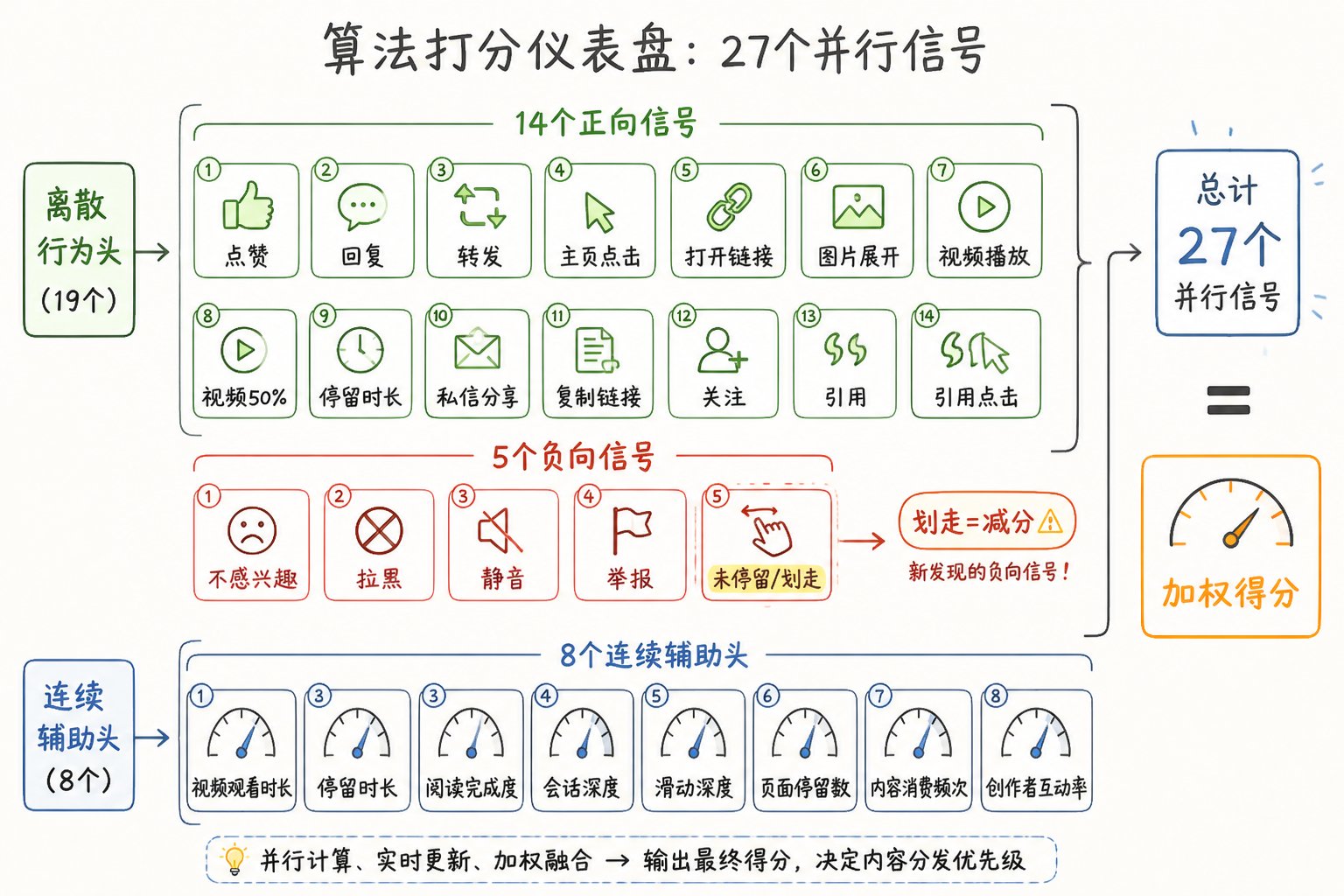
完整对照表(按代码索引顺序):
新增的 8 个"连续辅助头"
除了上面 19 个"是/否概率"外,模型这次还会输出 8 个连续值预测,用来更精细地刻画用户行为:
- 视频实际观看时长
- 帖子停留时长
- 文字阅读完成度
- ……(具体含义代码未完全公开)
这些连续值会作为辅助监督信号参与排序,让算法不再只问"会不会停留",而是预测"会停留多久"——更精细的连续预测意味着算法对内容质量的判断更"立体"。
与 v1 报告的关键差异
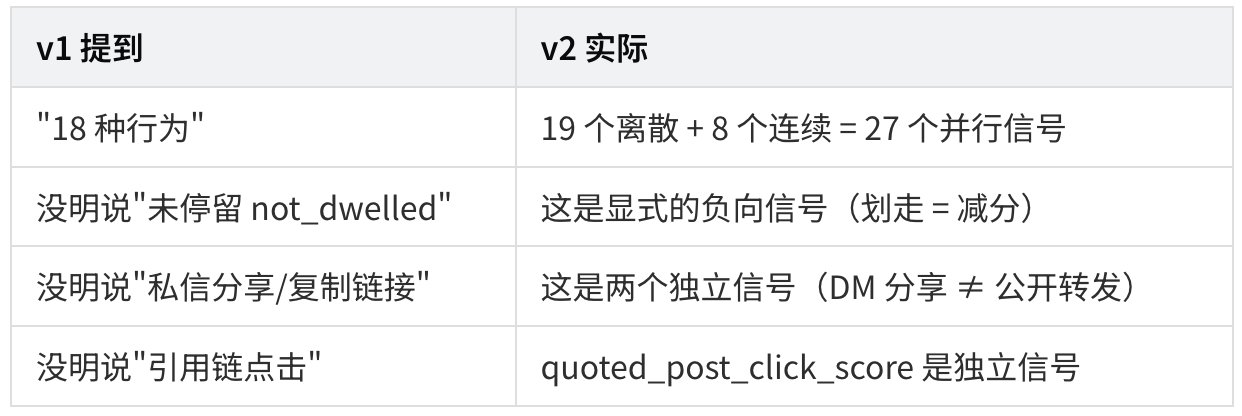
创作者新洞察
"划走"是真的会减分。以前你可能以为"用户没互动就是没看到",但 v2 明确告诉我们:用户快速划走(not_dwelled)是一个主动负向信号。这意味着:
- 视频开头 1 秒没抓住人 = 主动减分
- 长帖第一句话没意思 = 主动减分
- 图片没视觉冲击 = 主动减分
私信分享 > 公开转发。代码把"分享到私信"和"复制链接"列为独立信号——意味着算法特别看重"用户愿意推荐给特定的人"这种隐私性强的信号。这种信号的权重很可能高于普通转发。
第五章:新用户冷启动彻底改变——Grok Topics 与 Starter Packs
一个老观念被颠覆了
v1 的认知:新用户没有数据,算法只能给他们看"通用爆款"——所以新账号要靠"自带传播力"的内容出圈。
v2 的真相:新用户根本不是"白板"——他们注册时就被引导勾选 Grok 话题(兴趣标签)和 Starter Packs(推荐账号包),这些选择会变成硬性过滤规则。
新机制:new_user_topic_ids 是一道硬墙
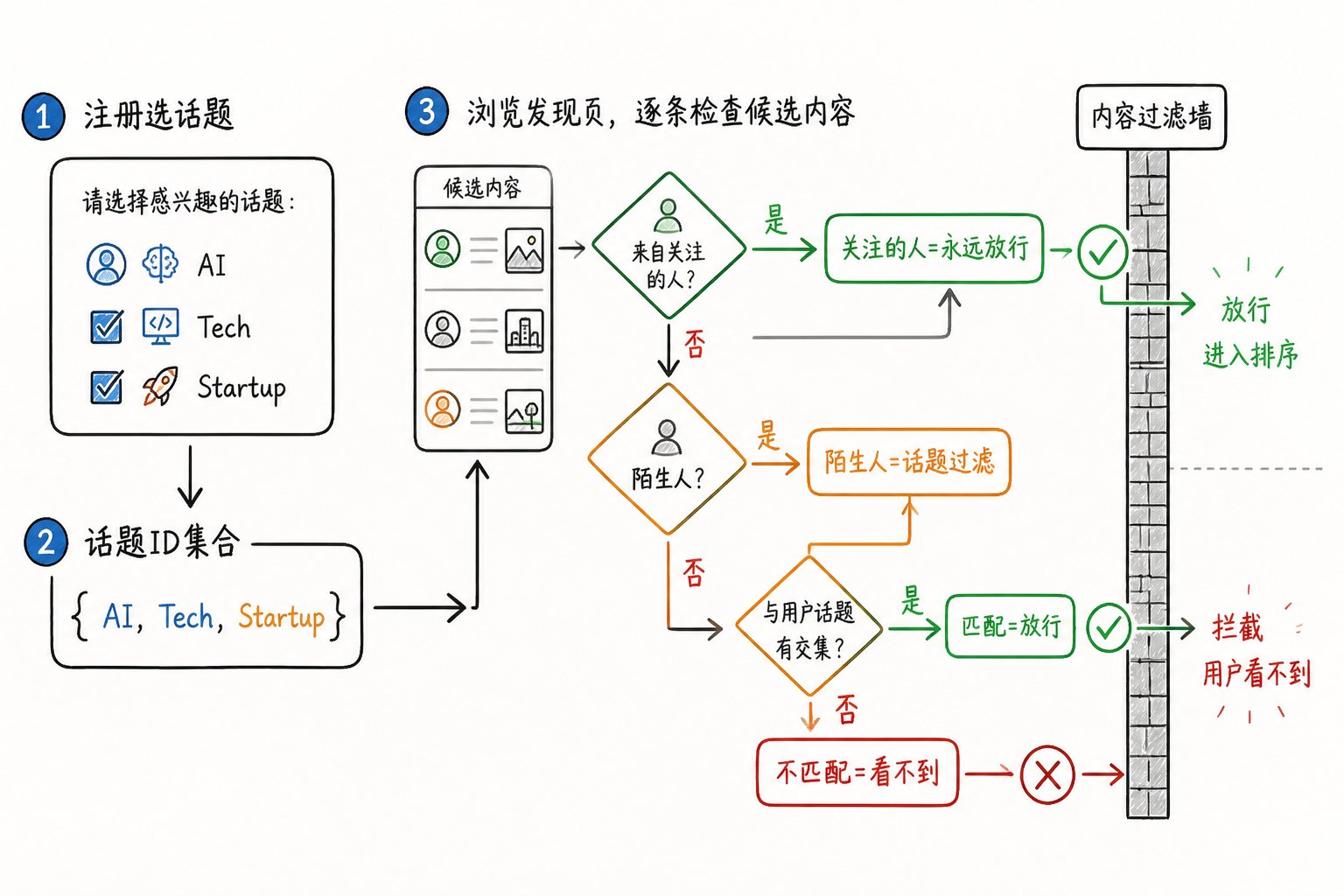
这对创作者意味着什么?
好消息:如果你的内容主题清晰、被系统准确归到某个 Grok 话题下,那么所有勾选这个话题的新用户都会潜在看到你——这是一个精准触达新用户的稳定通道。
坏消息:如果你的内容被系统错误标注话题(或者你写的是"话题边缘"内容),新用户根本看不到你。(哎!币圈的需要发一发生活了,纯币圈内容完犊子了)
创作者实战建议
1. 找到你的"主话题"
- 决定你的核心 1–2 个 Grok 话题(科技、健身、投资……)
- 持续围绕它们创作,让算法把你"贴标签"贴得稳
2. 测试你的话题归类是否正确
- 看新粉丝来源的兴趣画像
- 如果新粉的兴趣标签和你预期的不符,可能是被算法错分类了
- 需要调整内容关键词、话题标签
3. 利用 Starter Packs(账号包)
- 这次代码里 Starter Packs 还只是"上下文特征",不是硬过滤
- 但已经被埋点了,未来可能成为新的曝光通道
- 提前进入相关 Starter Pack(如"AI 必关注"等)会有先发优势
4. 互关网络
- In-network 内容永远放行,不受话题过滤约束
- 与同领域 KOL 互关,让新用户通过"关注的人转发"路径看到你
第六章:新增的 8 条"召回赛道"
全景图:For You 不再只有"关注流 + 发现流"
v1 时代,我们以为推荐内容只有两个来源(Thunder 关注 + Phoenix 发现)。v2 揭示了真相:For You 至少有 10 条平行的召回管道,每条都有自己的逻辑。
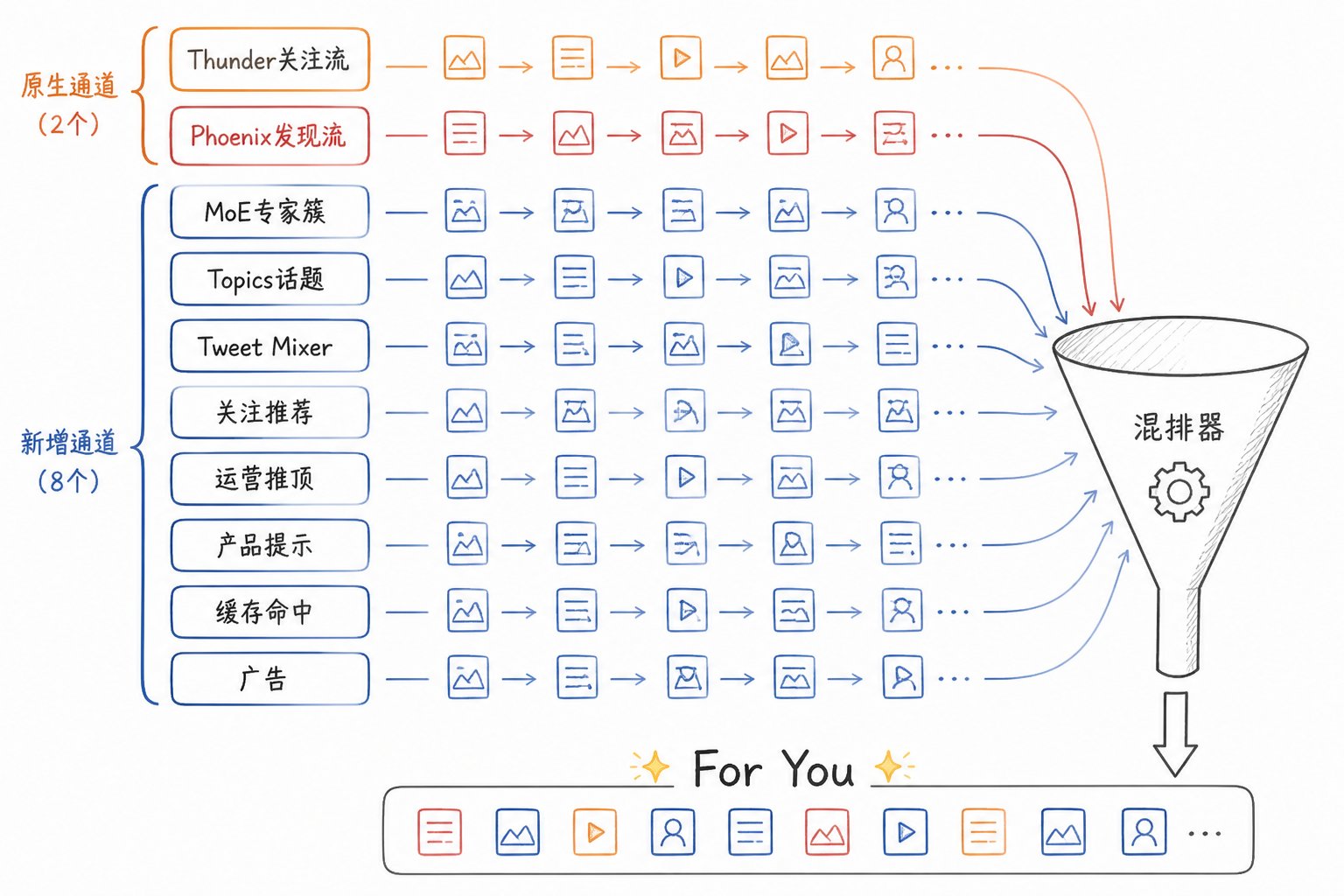
每条赛道一句话讲完
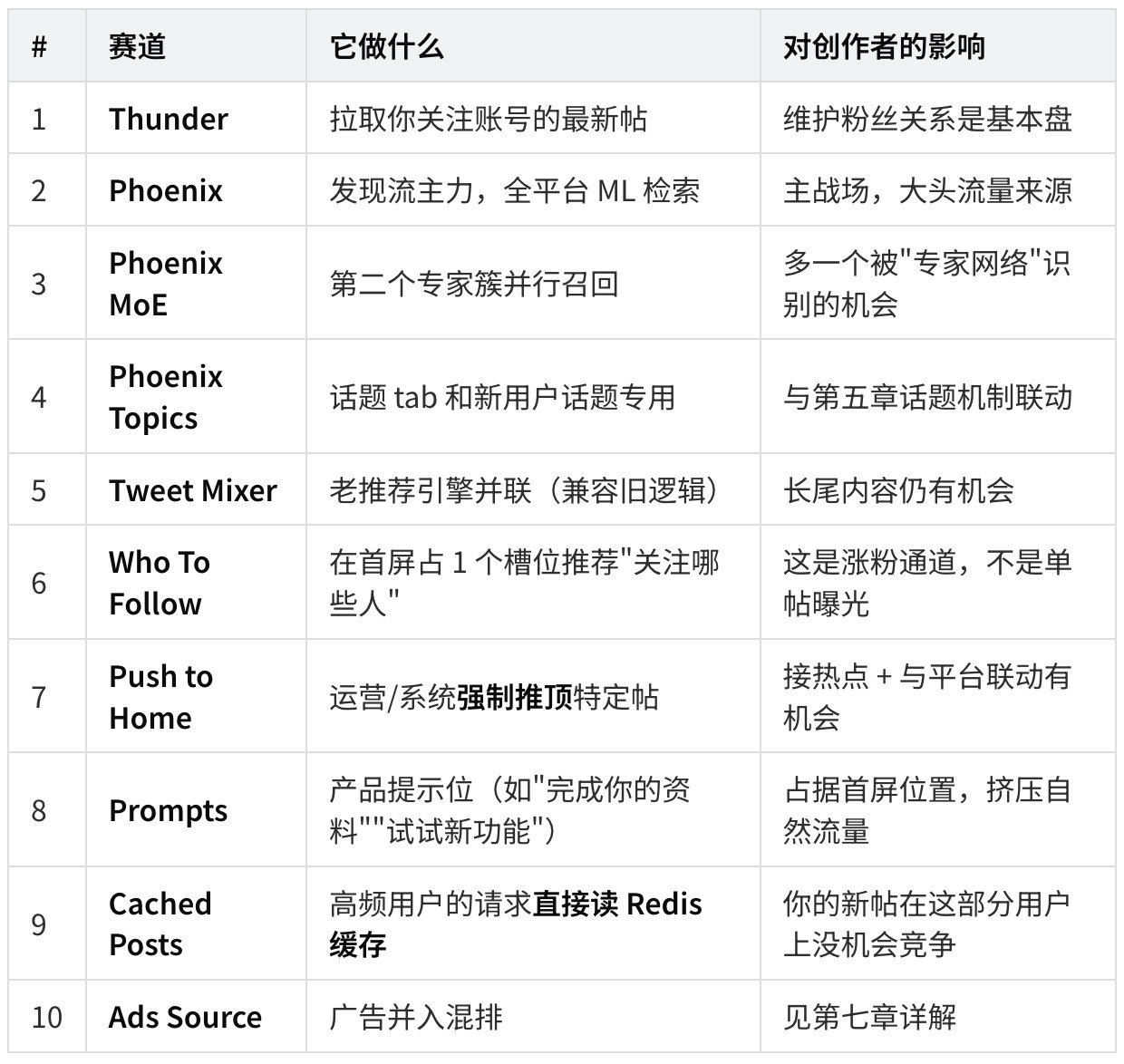
重要洞察一:缓存命中是新帖的"敌人"
代码里有一个细节:
if has_cached_posts and cached_posts.length >= 500: 跳过 Thunder/Phoenix/TweetMixer 等所有实时拉帖 直接返回缓存
这意味着:重度用户(每天打开 X 几十次的人),他们的请求很多时候根本不进推荐管道——只是读了 Redis 里的缓存列表。
(这也说明了最近开始每天狂发几十条的依然有流量,就是 X 做了这个修改😂一代版本一代神啊)
对创作者的启示:
- 如果你的目标受众是"每天打开 30 次 X"的重度用户,新发的内容不会立即触达他们
- 想触达重度用户,要么内容特别热(被系统重新算入缓存),要么走 in-network(关注关系)
- 这也解释了为什么有时候你刚发的帖,关注你的朋友说"刷不到"——很可能他们当时读的是缓存
重要洞察二:召回不是分数高就赢
老观念:"我的帖打分高,就能进 For You。" 新真相:"你要先在你那条赛道里赢,才有资格进入混排。"
每条赛道都有自己的召回上限(top-K),帖打分再高,如果这条赛道这次没召回到你,你就出局了。
例子:
- Thunder 一次最多召回 N 条关注作者的帖
- Phoenix 默认 top-200 最相关
- Phoenix MoE 是另一组 top-K
- ……
如果你的内容风格非常小众,可能在主 Phoenix 召不到,但在 MoE 专家簇能召到——所以多样化的内容更容易"撞上"某条赛道。
第七章:广告系统进入信息流——"三明治插法"的影响
第一次完整公开的广告调度算法
v1 时代,广告这块完全不出现在开源代码里。v2 完整公开了 home-mixer/ads/ 模块——我们第一次能看到广告怎么塞进信息流、和自然内容怎么互动。
硬规则一:候选 < 5 不插广告
if num_organic_posts < 5: skip ads insertion
如果某次推荐召回的自然内容少于 5 条,整次都不插广告。这个规则保证了"刷不出帖子的时候不会还看到一堆广告"。
硬规则二:广告的"三明治"插法
广告不是想插哪就插哪——它必须满足邻接安全条件:
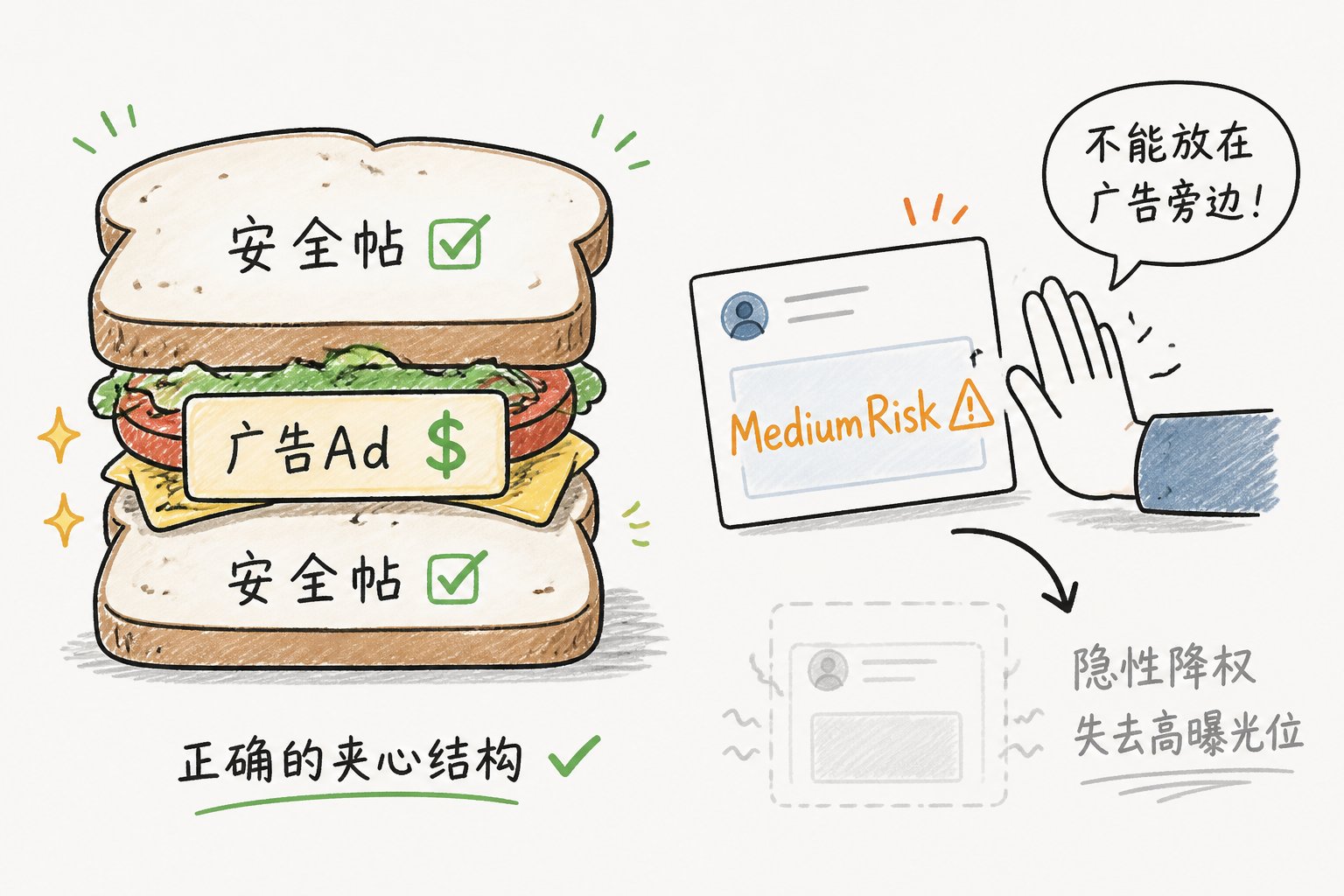
满足不了"三明治"条件,这条广告就被丢弃——广告主不会愿意自己的广告夹在不安全的内容旁边。
致命发现:MediumRisk 帖的"隐性降权"
代码里有一个关键变量:brand_safety_verdict,分四档:
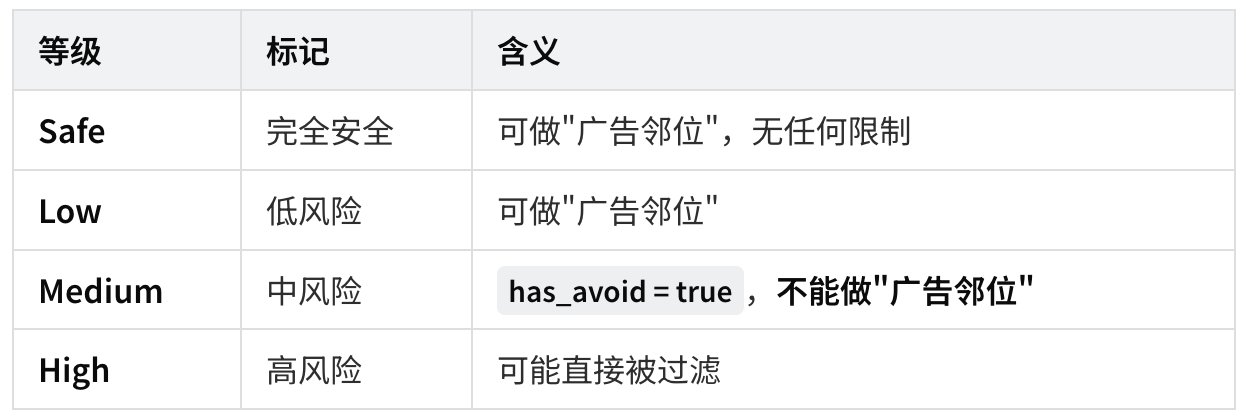
代码里默认值是 Medium——也就是说,如果你的帖子没有被打上明确的"安全"标签,系统就当你是"中风险"。
这意味着:
- 标签缺失 ≠ 安全,而是 = 中风险
- 中风险的帖不会被直接屏蔽,但是会被避免插在广告旁边
- 而广告周围的位置往往是高曝光位置(用户视觉焦点)
- 结果:你的"中风险"内容实际曝光会被悄悄削减——这是一种隐性的货币化降权
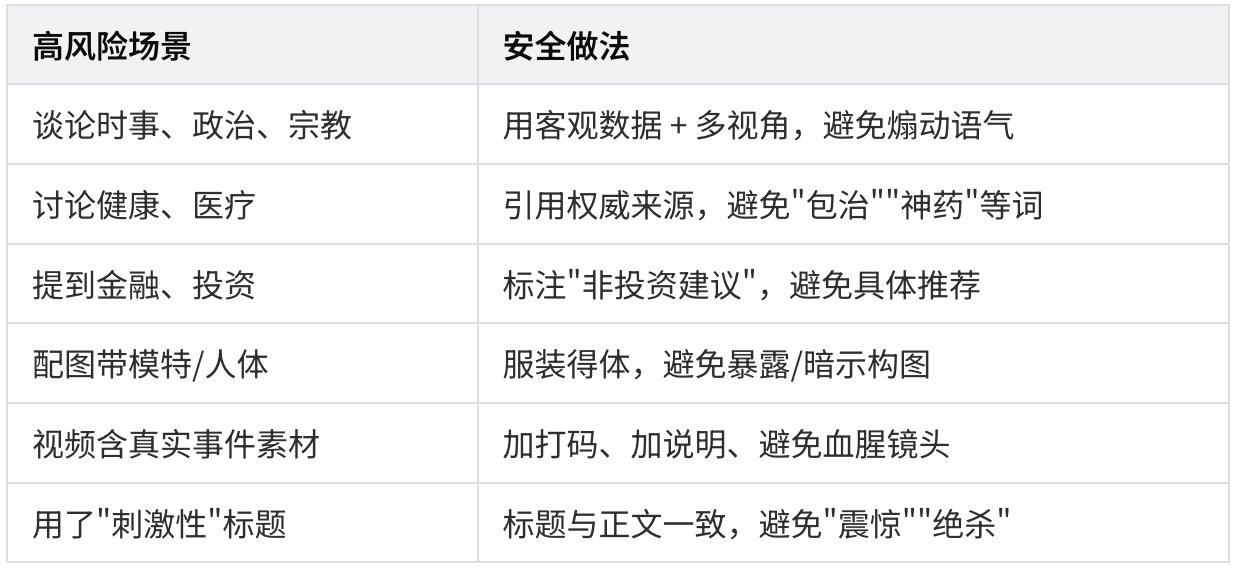
哪些情况会让你被打成 MediumRisk?
代码逻辑可以反推:
- 任何 NSFW/Violence/Hate/DoNotAmplify/PDNA 标签命中
- Grok PTOS 命中任何违规类别
- Grox 安全审查识别为 isNsfw / isViolent / isGore
- 没有被审查过(标签缺失)—— 默认就是 Medium
- 帖子内容 / 媒体里的关键词与品牌敏感词相近
创作者怎么避免落入 MediumRisk
特别提醒:你可能从来没收到过任何"违规通知",但你的曝光已经被悄悄打折——因为系统压根没"封"你,只是"避开"了你的邻位。这是 v2 算法最容易被忽视的"隐性限流"形式。
第八章:互关 Jaccard 与社交圈层化
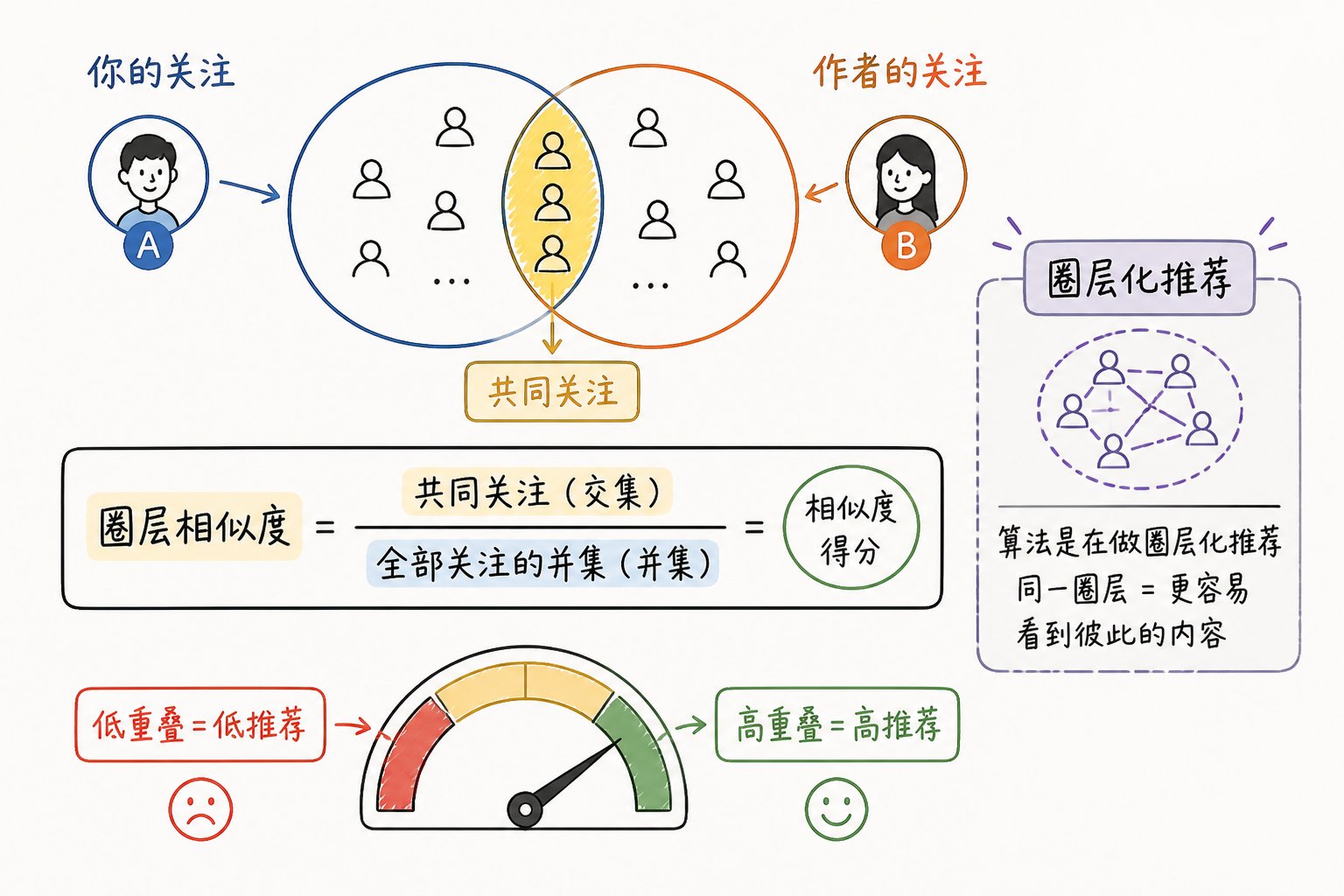
一个全新的社交信号:mutual_follow_jaccard
代码里新增了一个水合器叫 mutual_follow_jaccard_hydrator,它的作用是:
计算"你和这个作者的共同关注圈相似度"——用 MinHash + Jaccard 算法。
如果这个相似度很高——说明你们生活在同一个"信息圈层"——那 TA 的内容就更有可能被推给你。
含义:算法在悄悄把推荐"圈层化"
这是一个非常重要的转变:
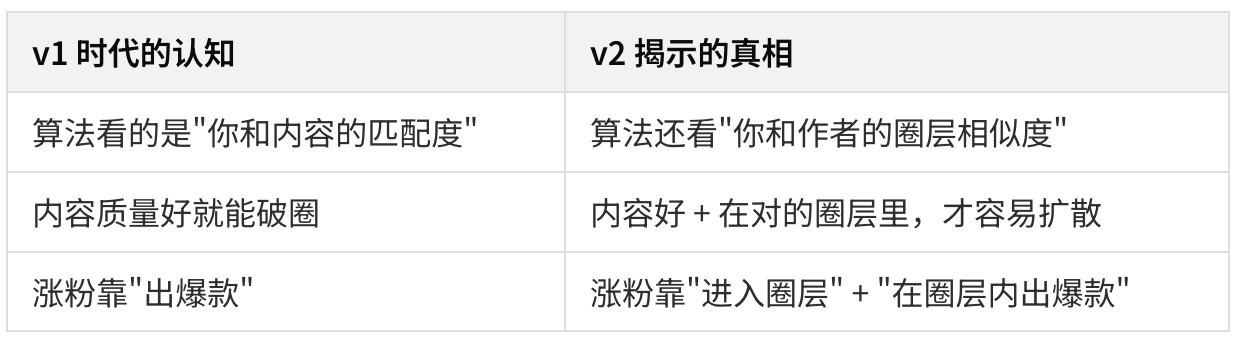
举个例子:
- 你在创业圈写干货,干货质量很高
- 但是你只关注了 5 个泛娱乐账号
- 在某个创业圈用户的眼里,你和他的 Jaccard 相似度接近 0
- 你的内容虽然质量高,但被算法判定"不在他的圈层",难以被推送
另一个新信号:following_replied_users(社交脸堆)
代码还新增了"在你关注的人评论过的帖子下显示脸堆"的机制——也就是你刷信息流时看到的"你关注的 @张三 等 3 人在此评论"提示。
这个信号的作用:
- 让你看到关注的人在哪里互动
- 形成社交证明:"这条值得看,因为我朋友也在看"
- 提高被推荐内容的信任度和点击率
创作者策略:进入圈层的 4 个具体动作
动作 1:精心选择你"主动关注"的账号
- 不要乱关注,每个关注都在塑造你的"圈层身份"
- 关注 30 个同领域 KOL,比关注 300 个杂账号有用
- 这会让你被算法识别为"该圈层的成员",从而更容易被推给该圈层用户
动作 2:在同领域大 V 帖子下高质量评论
- 你的评论会进入 following_replied_users 信号链
- 你关注的 KOL 看到的帖子下,可能会出现你的脸
- 这是借社交脸堆获得曝光的有效手段
动作 3:与同领域作者形成"互关网络"
- 互关 = 双向 follow,会进入 mutual_follow_jaccard 计算
- 与目标圈层内 5–10 个核心账号互关,比单向关注 100 个账号有用得多
动作 4:做"圈层化"内容,而不是"泛大众"内容
- 用圈内黑话、引用圈内事件、cite 圈内人物
- 这会让算法把你牢牢绑定到该圈层
- 牺牲泛流量,换来圈层内部的精准曝光和高互动
第九章:8 类"误杀风险"——你可能被悄悄折叠的原因
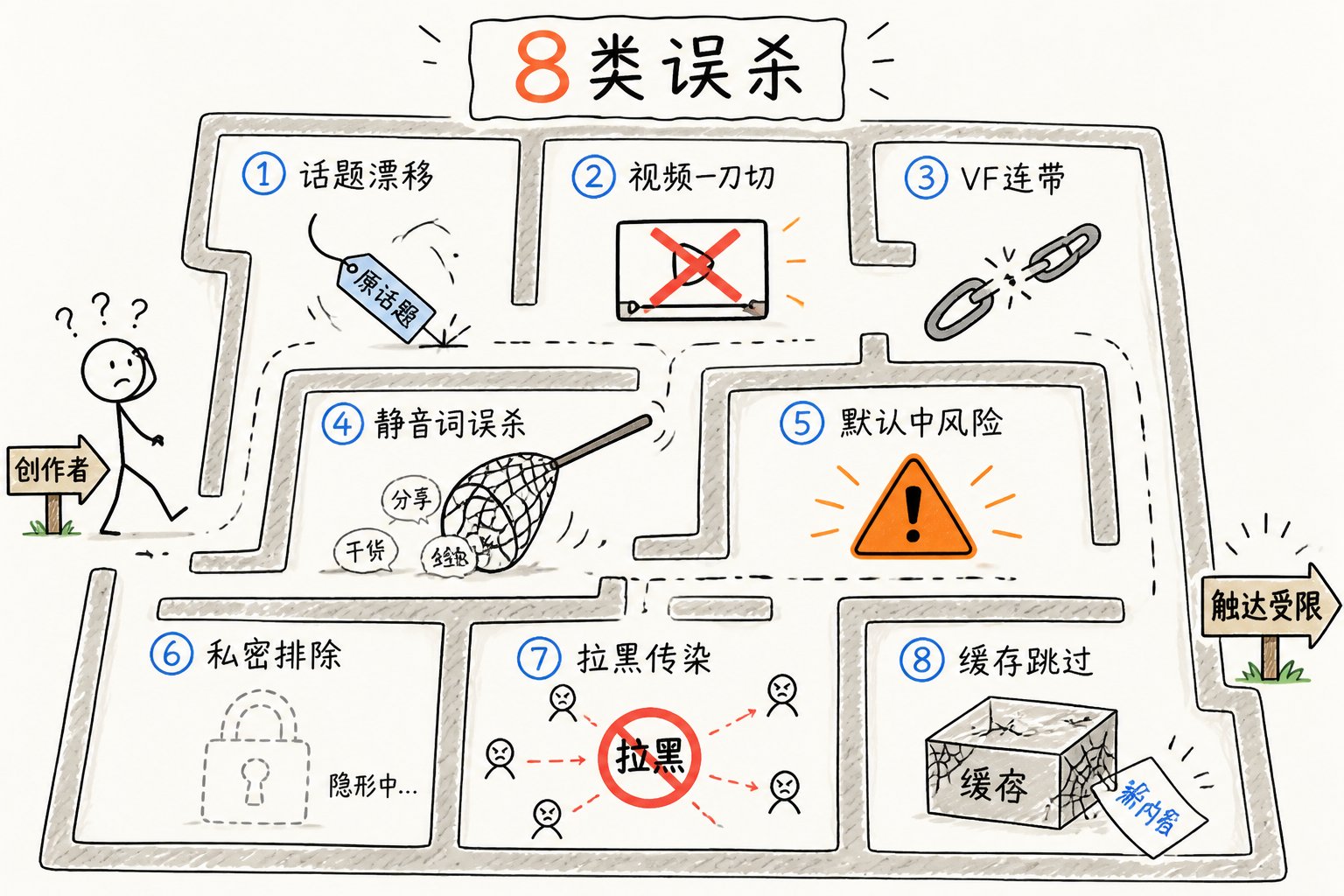
为什么我的内容突然没人看了?
很多创作者都遇到过——内容质量没下降,互动突然崩了。v2 揭示了 8 种"看不见的封堵"机制,每一个都可能是答案。
误杀 1:话题标签漂移
机制:你的帖子被算法自动归类到错误的话题(标签漂移),导致在话题 tab 上根本不出现。
触发场景:
- 你写"AI 提示工程",但被打上"娱乐"标签
- 你的帖子用了多种话题词,被分到次要话题
- 同义词(如"GPT"vs"ChatGPT")被当成不同话题
对策:
- 标题和首段用准确、主流的话题关键词
- 避免一帖横跨多个话题
- 偶尔用 # 显式标话题,强化算法识别
误杀 2:视频过滤一刀切
机制:用户开启"少看视频"开关时,任何含视频时长字段的帖子(哪怕是 1 秒小视频)都会被一刀切剔除。
if query.exclude_videos: drop all candidates where min_video_duration_ms.is_some()
对创作者的含义:
- 部分用户主动关闭了视频流(隐私保护、流量原因等)
- 你发的混合形式(文字 + 短视频)会被这部分用户完全屏蔽
- 而文字帖完全不会受影响
对策:重要内容要有纯文字版本作为备份,不要把所有要点压在视频里。
误杀 3:VF 连带责任(最容易被忽视的)
机制:你引用、转发的帖子,如果原帖被算法处罚(VF = Visibility Filter),你的引用/转发帖也会跟着遭殃。
触发场景:
- 你引用了一条后来被打上 NSFW 标签的帖
- 你转推了一个后来被静音的账号
- 你的帖子的"祖先帖"(被回复的原帖)被处罚
对策:
- 谨慎引用边缘内容
- 引用前确认原帖没有违规风险
- 有争议的话题用"截图 + 说明"代替直接引用
误杀 4:静音词的 token 边界匹配
机制:用户设置静音词"hat"(帽子),代码里用的 token 边界匹配,可能意外命中"that""what""chat"。
对创作者的含义:
- 你的帖子可能因为含完全无关的词而被某些用户屏蔽
- 你看不到这种屏蔽,因为它发生在用户端
- 静音词越短、越常见,误杀风险越高
对策:
- 在英文内容中避免大量使用通用短词组合
- 重要内容多发几次(不同表述),降低被单一静音词误伤的概率
误杀 5:品牌安全默认 MediumRisk
机制:第七章详细讲过——没被审查过 ≠ 安全,而是 = 中风险。
触发场景:
- 新发的帖子还没被 Grox 审查完
- 系统"标签缺失"
- 内容主题边缘(不被任何已知模型确信)
对策:
- 重要帖发出后等 30 分钟到 1 小时再做大力推广(让审查跑完)
- 主题清晰的内容更容易被快速归类为"安全"
误杀 6:私密账号被多管线静默排除
机制:代码里多次出现 is_protected → skip,意思是私密账号被很多 Grox 任务直接跳过:
- 不做爆款初筛
- 不做 PTOS 安全审查
- 不生成多模态嵌入
含义:你保护账号 ≠ 保护曝光——而是算法对你的内容毫无理解。私密账号几乎只能依赖关注关系曝光,发现流路径基本被关闭。
对策:明确你的目的——
- 想保护隐私 → 接受曝光受限
- 想被算法发现 → 公开账号
误杀 7:拉黑关系的传染链
机制:v2 里 author_socialgraph_filter 增强了拉黑关系判定:
- author_blocks_viewer (作者拉黑了观众) - quoted_author_blocks_viewer (被引用的作者拉黑了观众) - viewer_blocks_quoted_author (观众拉黑了被引用的作者) - viewer_blocks_retweeted_user (观众拉黑了被转发的作者)
含义:拉黑关系会沿着引用、转发、回复链传染——A 拉黑你,那么 A 引用别人的帖,你也看不到。
对策:
- 减少与"互相拉黑用户群"的内容关联
- 不要去和明显的"对家"互动(哪怕是论战)—— 互相拉黑后,你们的整个网络都会被切断
误杀 8:缓存命中跳过实时算法
机制:第六章讲过——重度用户的请求很多时候直接读缓存,不走实时算法。
含义:
- 你刚发的内容,对每天打开 X 几十次的重度用户几乎没有机会触达
- 缓存的更新频率受系统决定,你无法影响
对策:
- 重度用户的触达靠关注关系和强热点
- 平日发帖建议在"用户活跃高峰前 10–30 分钟"发,让缓存有机会包含你的新内容
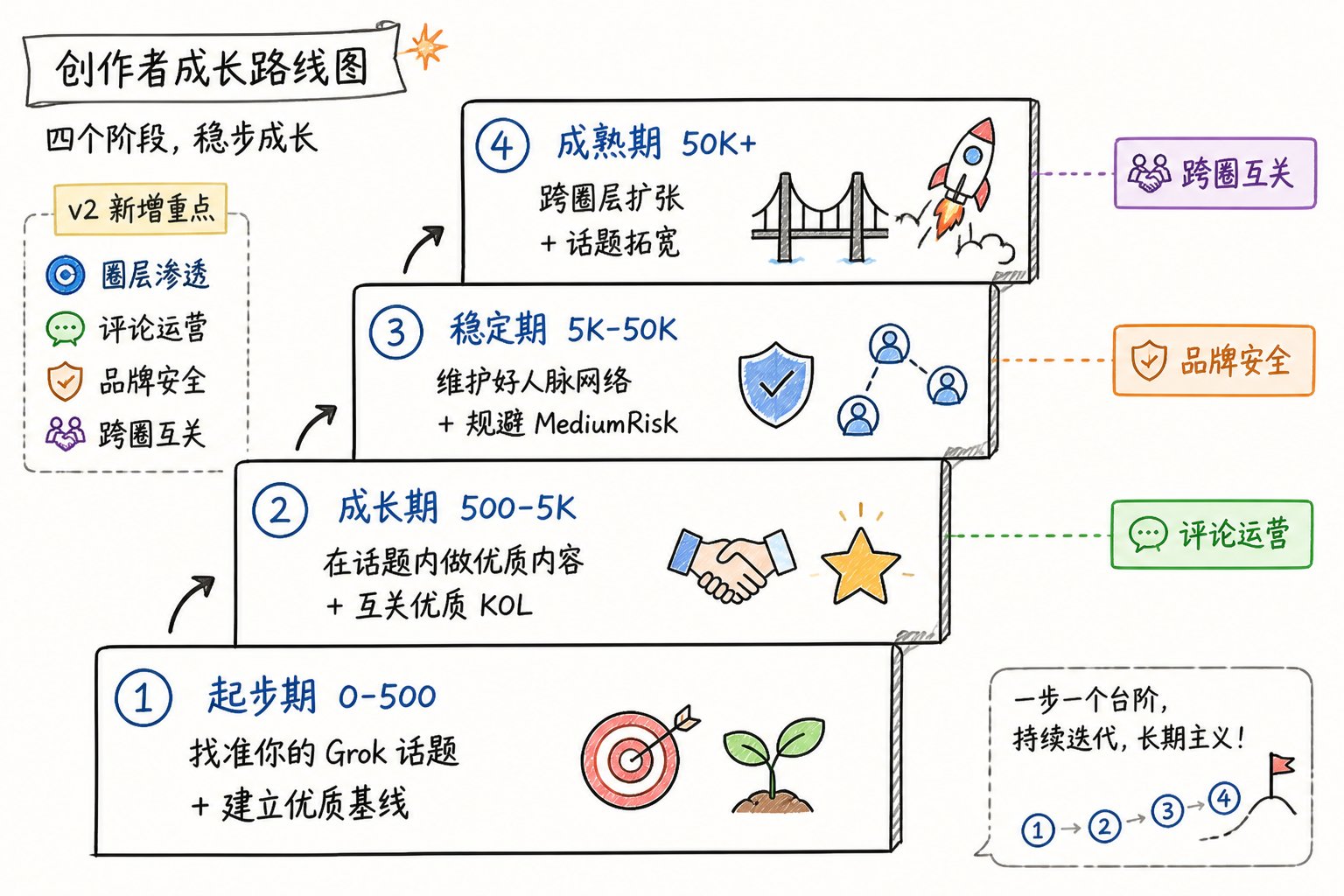
第十章:实战手册更新(v2)
在 v1 "10 条黄金法则"基础上,新增 5 条
法则 11:质量分 ≥ 0.4 是隐形门槛
原理:Grox 爆款初筛对每条帖打 quality_score,0.4 是显式的通过门槛。
怎么提高质量分:
- 内容有清晰的论点(而不是流水账)
- 配图要有信息量(图表、对比、示意图 > 装饰图)
- 视频有结构(不是一镜到底无剪辑)
- 避免"AI 生成感"明显的模板化句式
- 避免单帖几十字 + 一张表情包的"水帖"
法则 12:警惕 7 类 PTOS 雷区
原理:PTOS 的 7 大违规类别是硬编码的——任何边缘内容都可能命中。
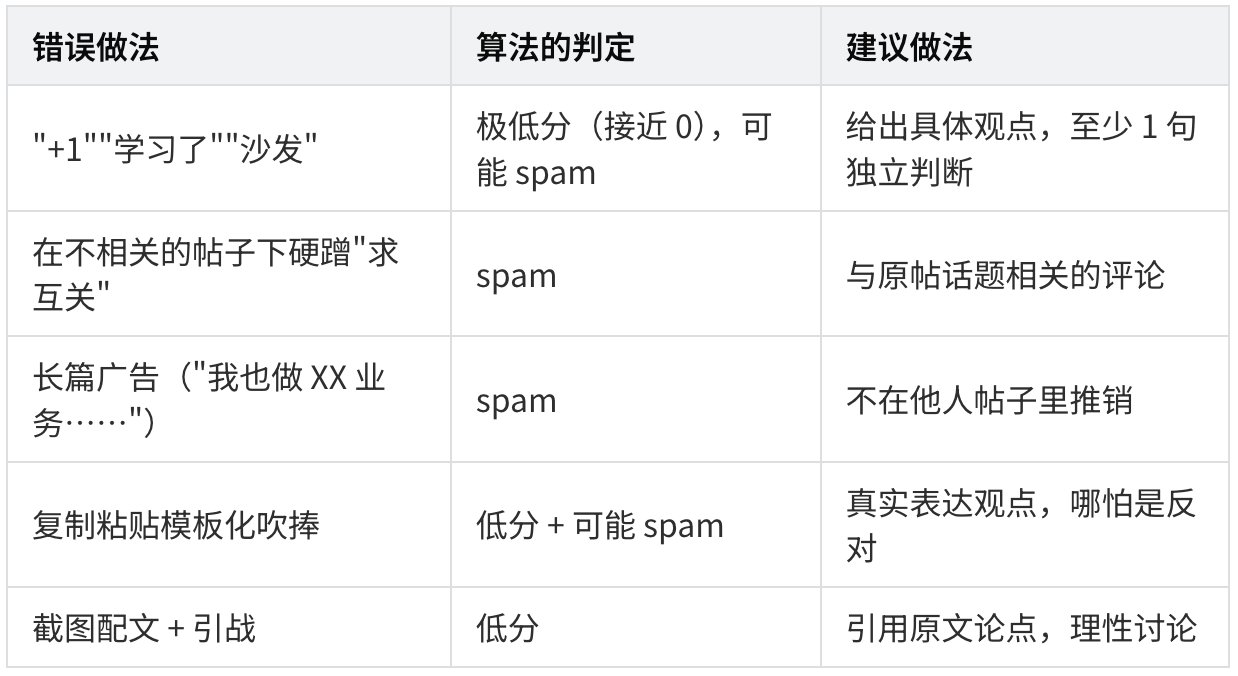
法则 13:评论也是产品(不是配角)
原理:评论被独立打分(0–3),0 分 = spam 标签 + 影响账号信用。
好评论 vs 差评论:
✅ 好评论(高分): "我自己测试了一下,发现这个方法对 RAG 场景特别好用, 但需要把 chunk size 调到 256 以下才稳定。补一个细节给楼主参考。"
❌ 差评论(接近 0 分,可能 spam): "+1 学到了" "沙发" "求互关 我也是做 AI 内容的"
法则 14:圈层比粉丝重要
原理:mutual_follow_jaccard 让算法圈层化推荐——和你共同关注圈相似的用户,更容易被推给你的内容。
圈层运营 4 步:
- 主动关注同领域 30–50 个核心账号
- 与圈内 5–10 个 KOL 形成互关
- 在他们帖子下高质量评论
- 内容用圈内话语体系,而不是"大众化"
法则 15:Grok 话题选择决定冷启动方向
原理:新用户的发现流被 new_user_topic_ids 硬性过滤——不命中话题不被看到。
对策:
- 决定你的核心 1–2 个 Grok 话题
- 持续围绕它们创作,让算法稳定贴标签
- 测试新粉丝的兴趣画像,验证归类准确性
- 偶尔用 # 显式标话题加强识别
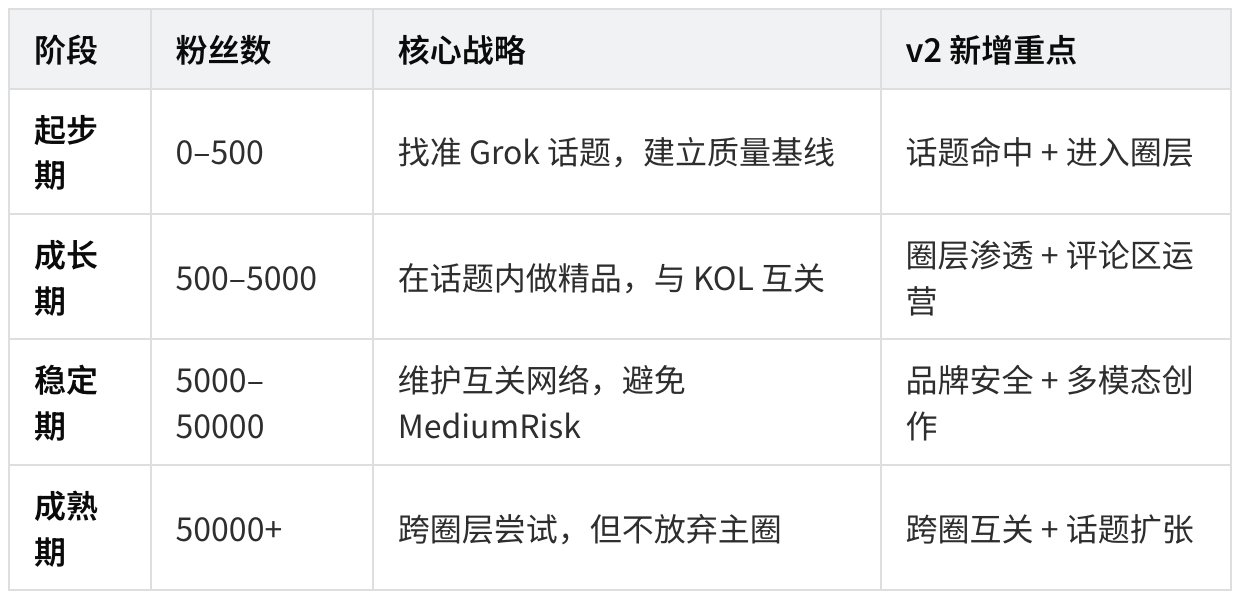
不同账号阶段的策略调整表(v2)
行动清单 v2
今天就做(基于 5 月更新的检查项):
- 评估你的 Grok 话题归类是否准确(看新粉来源画像)
- 检查最近 5 条评论,是否有高质量"圈层证明"型留言
- 检查你关注的账号画像,是否符合"目标圈层"
本周内做:
- 列出目标圈层的 5–10 个核心账号,主动互关
- 优化最近 10 条帖的"质量分"潜力(更长论点、更好配图)
- 检查是否引用过近期被处罚的账号,必要时删除
持续做:
- 每周评估一次"你被打成什么 Grok 话题"
- 在 5–10 个圈内大 V 帖子下做高质量评论
- 重要帖发出后等 30–60 分钟再大力推广
- 定期检查"圈层 Jaccard"——你关注的账号是否过于杂乱
总结:v2 时代的"算法心法"
一张图回顾全部新增机制
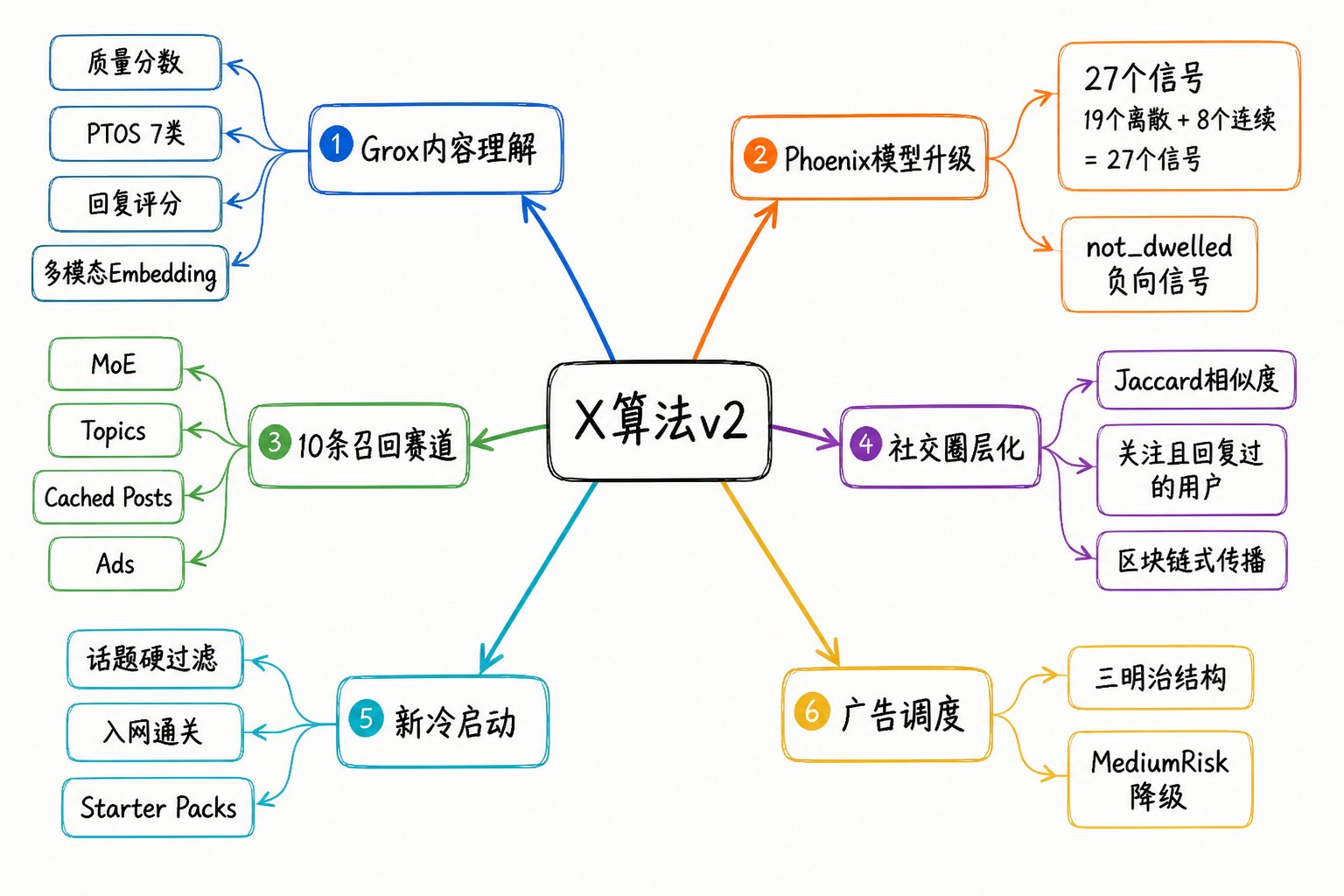
v2 时代的核心心法
"算法越聪明,越奖励真诚和清晰。"
v1 时代你可以靠"套路"骗算法——加图片、堆关键词、追热点。
v2 时代算法用 VLM 直接理解你的内容含义、用 Jaccard 算你的圈层归属、用 PTOS 检查你的边界、用质量分给你打档位……所有"投机取巧"的空间都在被压缩。
剩下能持续奏效的策略,反而是最朴素的几条:
- 找到你真正想服务的人群(圈层)
- 持续围绕一个清晰的主题创作(话题)
- 写真正有信息密度的内容(质量)
- 真诚回复同行,建立网络(社交)
- 避开 7 大雷区(合规)
这是这次更新背后真正的信号。
写在最后
这次开源更新的最大价值,不是"教你怎么钻空子"——而是让你看清规则的全貌,从而做出更明智的长期决策。
如果你只能记住一句话,我希望是这句:
算法升级的方向是越来越像"老练的资深读者"——它在用人的眼光读你的内容,用人的视角判断你的圈层归属,用人的标准评价你的诚意。能持续被算法奖励的,从来不是技巧,而是:真实的洞察 × 清晰的定位 × 长期的耐心。
祝你创作顺利。
本报告基于 xai-org/x-algorithm 5 月 15 日(commit e414c17)开源代码深度分析
配套阅读:
分析时间:2026 年 5 月
免责声明:本报告基于公开源代码分析,所有结论可在代码中验证(见附录 D)。具体的权重值、阈值参数 X 可能持续调整,请以官方信息为准。算法是工具,内容才是核心。