
这些天,你的朋友圈是不是被 GPT-Image-2 生成的图片刷屏了?中文海报、复古杂志封面、高考试卷、社交截图……专业设计师们惊呼“完了”,普通人兴奋地喊“我又能行了”。
但很快,现实就给了一记重锤:免费用户一天只有几张额度,抽卡次数有限,活没干完,次数就没了。
这时商汤发布并开源了 SenseNova U1 系列原生理解生成统一模型。不同于传统的文生图模型,U1 采用统一架构同时处理图像理解和生成任务,在技术路径上走出了一条新路。
核心亮点:8B 参数,挑战 30B 开源模型
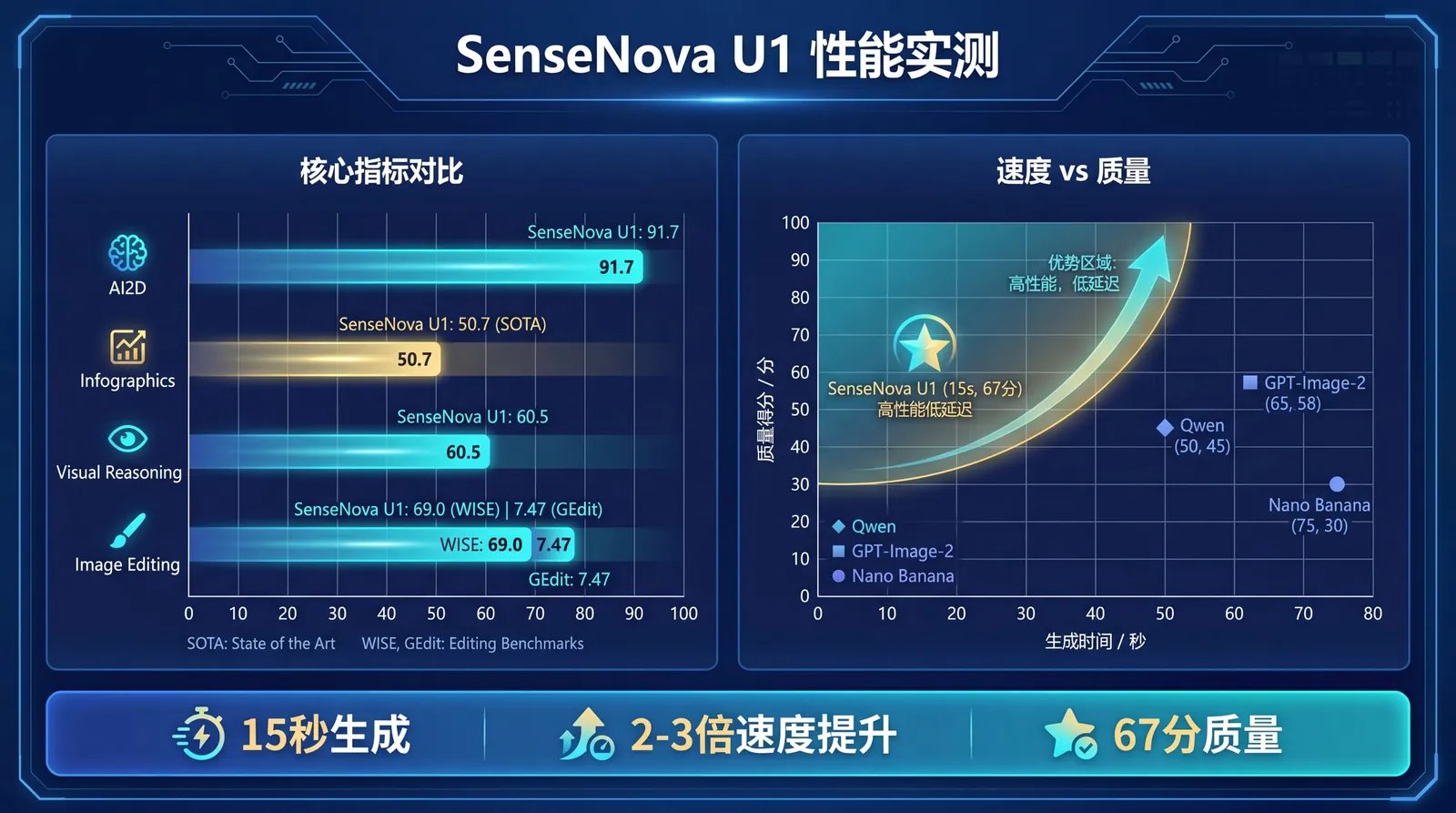
本次开源的 SenseNova-U1-8B-MoT模型,以 8B 参数规模,在图像理解、生成、推理等 20+ 项基准测试中达到同量级开源模型 SOTA 水平,在多项指标上比肩 30B 级别的大型开源模型。
性能指标
- **生成速度:**2K 图像生成延迟约 15-20 秒
- 参数效率:8B 参数在多项测试中接近 30B 模型表现
技术突破:NEO-Unify 原生统一架构
SenseNova U1 采用了 NEO-Unify 架构,这是一种不同于传统多模态模型的设计思路。
传统架构的局限
传统多模态 AI 采用分离式设计:视觉编码器负责理解,变分自编码器负责生成,两者之间存在信息断层。视觉编码器压缩图像时会丢失细节,导致理解与生成割裂、连续输出不一致等问题。
NEO-Unify 的解决方案
NEO-Unify将原本分离的环节收拢到统一架构中,让图像和文本信息在同一内部空间共同参与计算。
核心实现:
- 引入近似无损的视觉接口,统一图像输入输出表示
- 用 Mixture-of-Transformer 做主干,理解和生成共享底层
- 文本走自回归,视觉走像素流匹配,统一学习框架
核心优势:
- 路径更短:将看图、理解、生成压缩进同一个“大脑”,一边理解一边生成,保持语义和视觉一致性
- 效率更高:减少信息损耗和流程开销,让 8B 小模型释放出接近 30B 大模型的能力
性能实测:全面对比主流模型
图像理解与生成:8B 跑出 30B 效果
SenseNova-U1-8B-MoT 虽然只有 8B 参数,但在多项测试中超越了 Qwen3VL-30B、Gemma4-26B等更大规模模型:
- AI2D:91.7 分,领先同量级模型
- 信息图生成:50.7 分,达到开源模型 SOTA
- 视觉推理:60.5 分,超过 Nano-Banana(49.6)
- 图像编辑:WISE 69.0 分,GEdit-Bench 7.47 分
速度 vs 质量:效率才是杀手锏
**15 秒生成 2K 图像,**比同质量闭源模型快 2-3 倍,平均得分 67 分进入主流商业模型区间。
SenseNova U1 在低延迟条件下保持了较高的输出质量,在实际生产场景中具有一定的实用价值。
实测案例:这才是你急需的提效利器
光看榜单当然不过瘾。让我们看看 SenseNova U1 在实际场景中的表现。
1️⃣ 连续性图文创作(行业首创)
SenseNova U1 是业内首个能够在单一模型上进行连贯图文交错生成的模型。
传统模型的工作方式是:先用文字把问题想清楚,再调用外部工具把图生出来,这是两个步骤,两套系统,中间还有中间商负责牵线。SenseNova U1 打破的,正是这道墙——它能在同一套推理过程中,让图像和文字同步生长,示意图、流程图、草图,在它推理的同时就已经出现了,而不是等推理结束后再配上去。
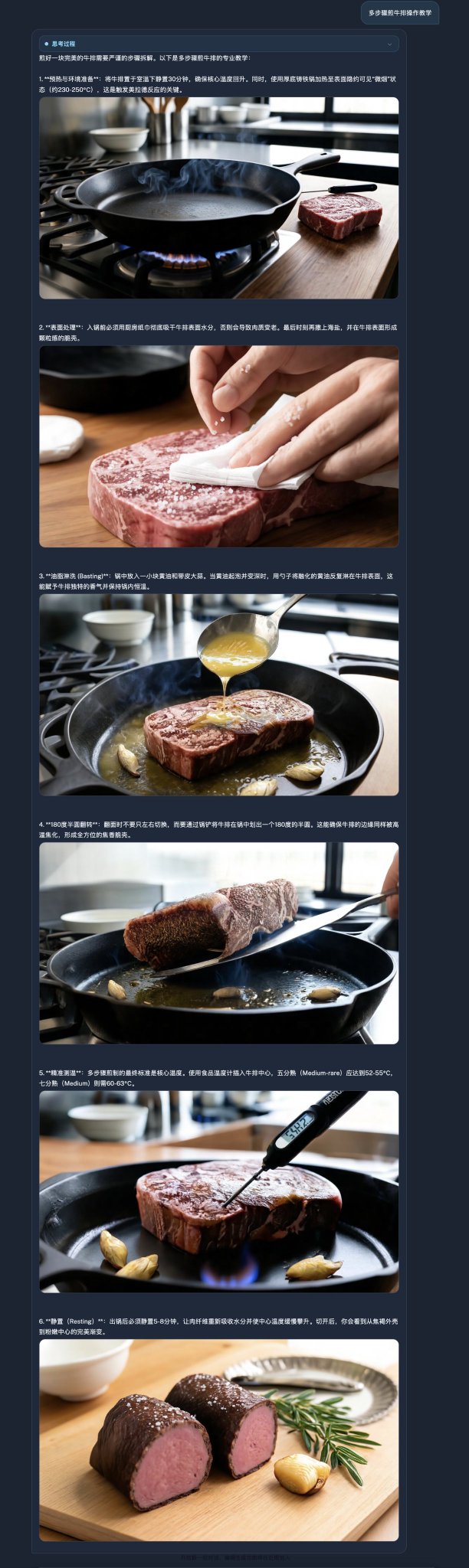
案例:煎牛排操作教学(真实发布图片会变成视频) 从食材准备、沥干水分、调味、煎制到翻面……讲到最后装盘。每一步的关键操作都有图,牛排的形象从生肉到五分熟一路保持高度一致,不会画着画着变成另一块肉。
案例:三只小猪盖房子(真实发布图片会变成视频) 输入只有“7 个字”,输出就能直接给你一整组连环画——三只小猪、三种材料、三栋房子、最后那只大灰狼,一格一格排好,顺序对得上故事。

案例:电影运镜教学(真实发布图片会变成视频) 想学习电影运镜?向 SenseNova U1 提问,它会把文字解释和视觉图同步给你,并且保持人物角色的高度一致性。从推拉摇移、景别变化到机位设计,每个运镜技巧都配有对应的示意图,比单纯的文字教程好懂得多,也比纯图示来得有逻辑。
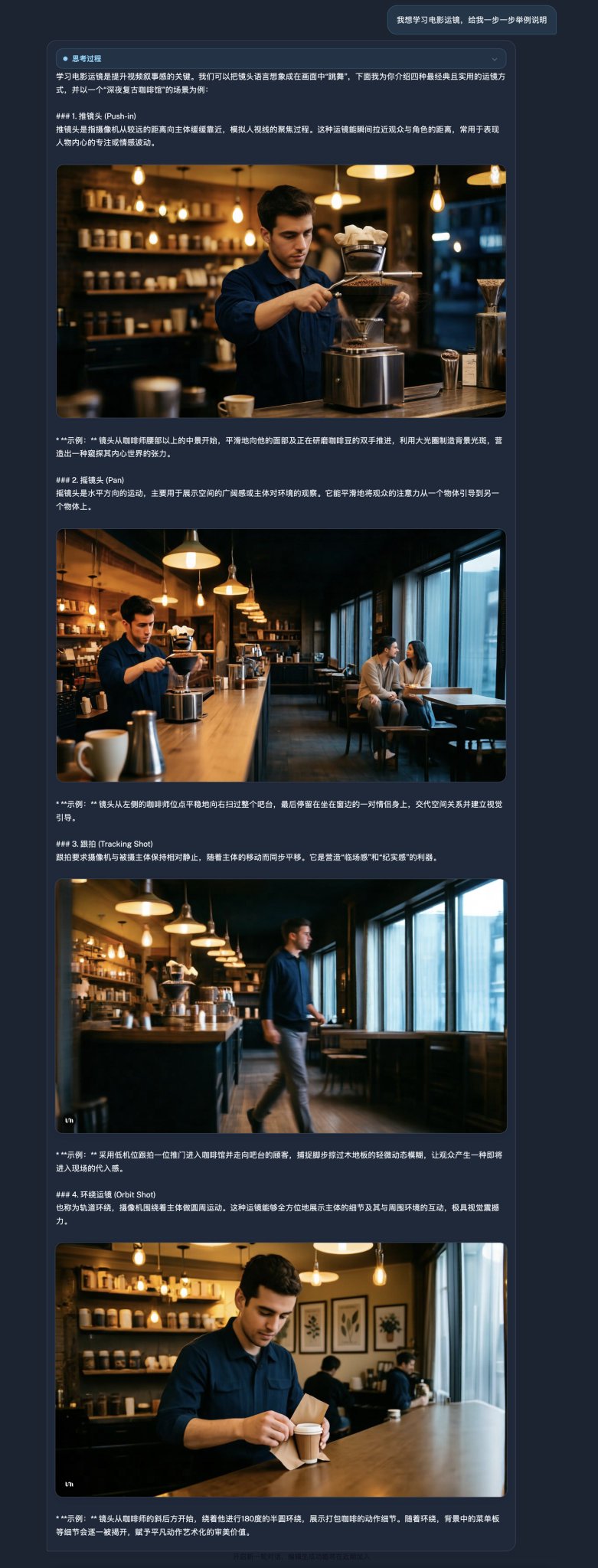
这种“始终是同一个主体“的连贯性看起来朴素,但对生成模型却很难。传统范式得在多个模型之间来回调用,各画各的,角色形象很容易在第三步就走样。U1 是单次单模型调用直接出全套。
2️⃣ 图文交错思维链(图像编辑中的推理能力)
**SenseNova U1 在图像编辑时展现了推理能力。**这种能力在一些场景中比较有趣。
案例:热茶一小时后的样子 扔给它一张刚泡好的玻璃杯热茶,让它“画出一小时后的样子”。它没有简单地直接出图,而是先做了一段推理:
- 定约束:同一只玻璃杯、同一张原木桌面、同一种侧逆光,这样两张图放一起才看得出“是同一杯茶过了一小时”
- 推导物理:刚泡时,叶片高速舒展、气泡从叶脉逸出、蒸汽在杯壁上留下弧形折射;一小时后,多酚类扩散均匀,茶汤变深红褐,叶子完全沉降呈半透明,杯底跟桌面交界处出冷凝痕迹
- 光影变化:从“清晨的清冷”过到“午后的慵懒”

案例:绿香蕉变黄香蕉 给它一个绿色的香蕉,模型会先推理“叶绿素分解+糖化”,从而保证输出的是一根带着斑点的成熟香蕉。
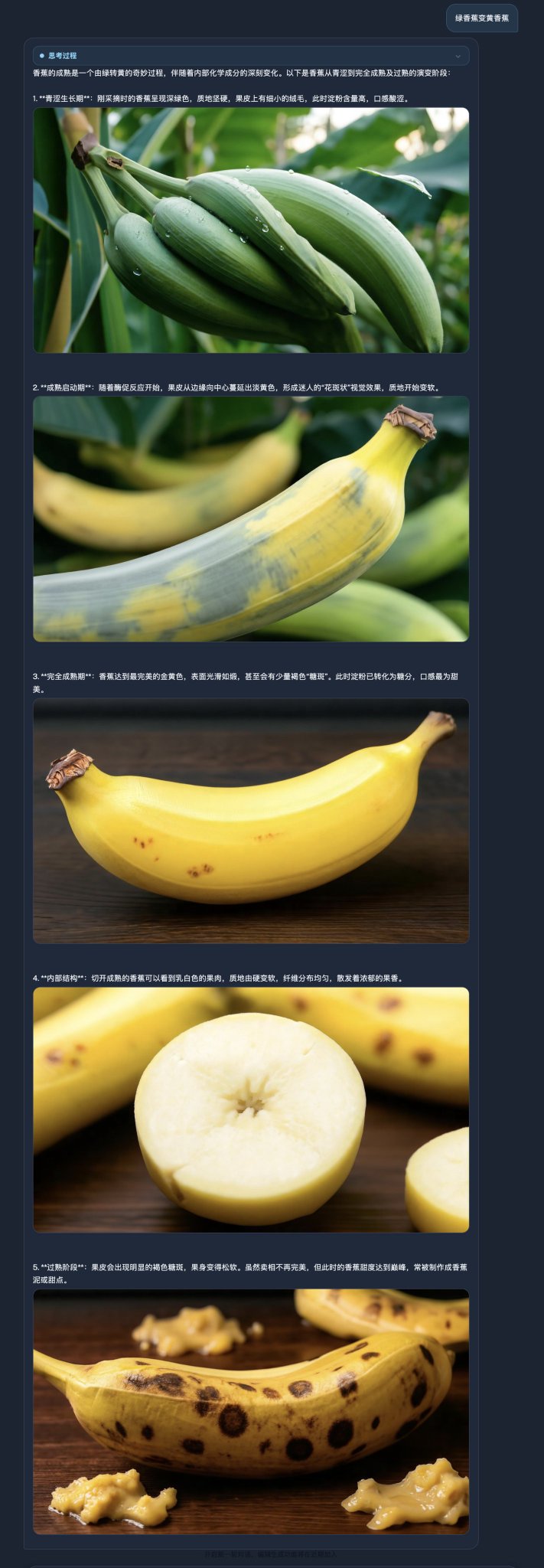
可以说,这款新模型不只是在改图,还具备了一定的物理常识。
3️⃣ 高密度信息图生成
信息图要解决的是一个真实的表达困境:一篇论文、一份研报、一个操作流程、一个知识点,原始形态往往密度过高、结构不清,大多数人看到就想关掉。而一张好的信息图,能把同样的内容重新组织,让读者在几秒钟内抓住核心。
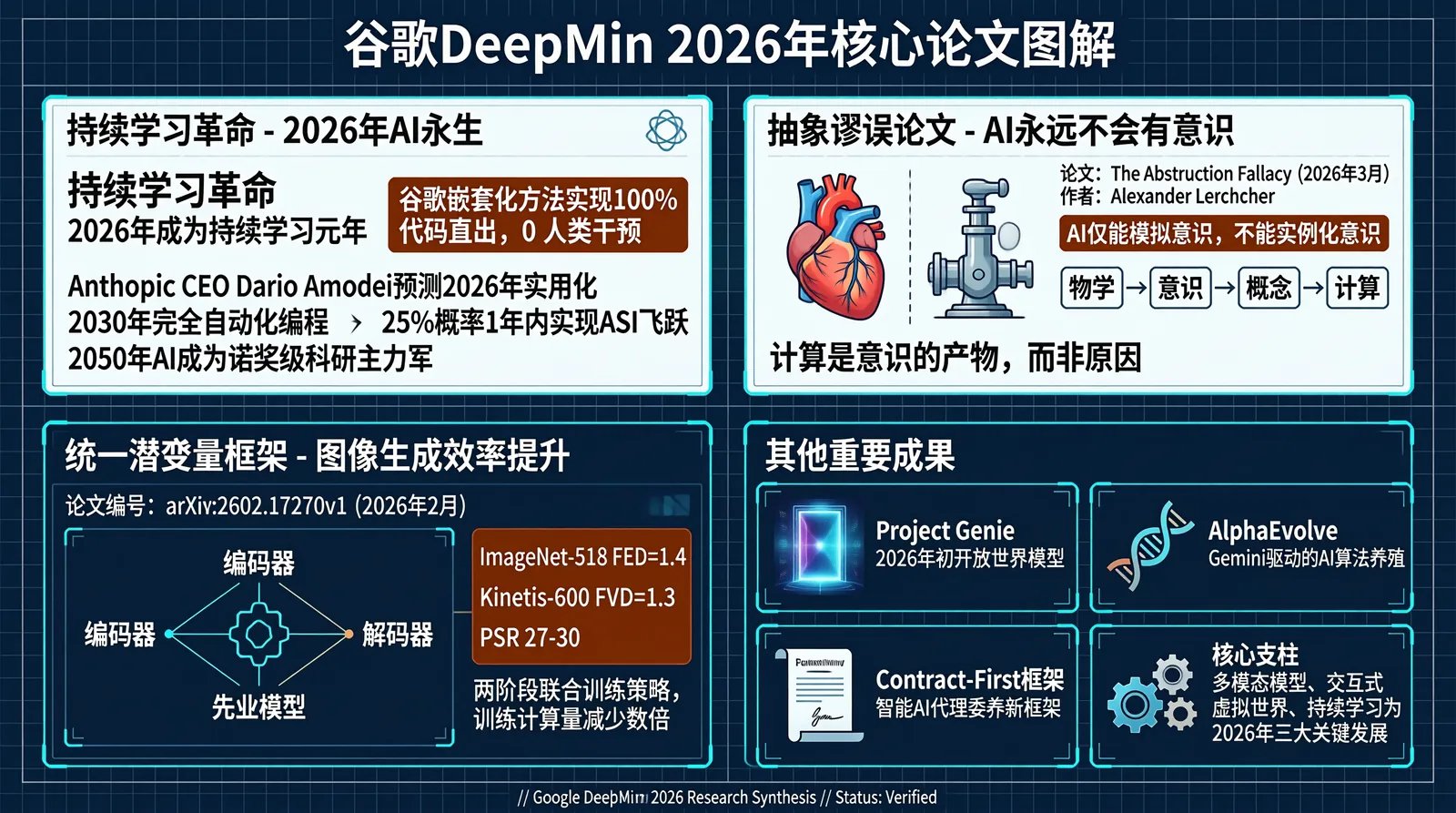
**案例:谷歌 DeepMind 论文图解 ** 最近,谷歌 DeepMind 发布了一篇颇受关注的论文《Image Generators are Generalist Vision Learners》,内容密度高,需要反复阅读才能理清脉络。把摘要丢给 SenseNova U1,让它生成一份图解。它不只是把文字重新排了一遍,而是真正提取出了论文的核心主张、方法逻辑和关键结论,用更直观的视觉结构把这些内容呈现出来,让一篇需要沉下心来读的学术文章,变得可以快速上手。
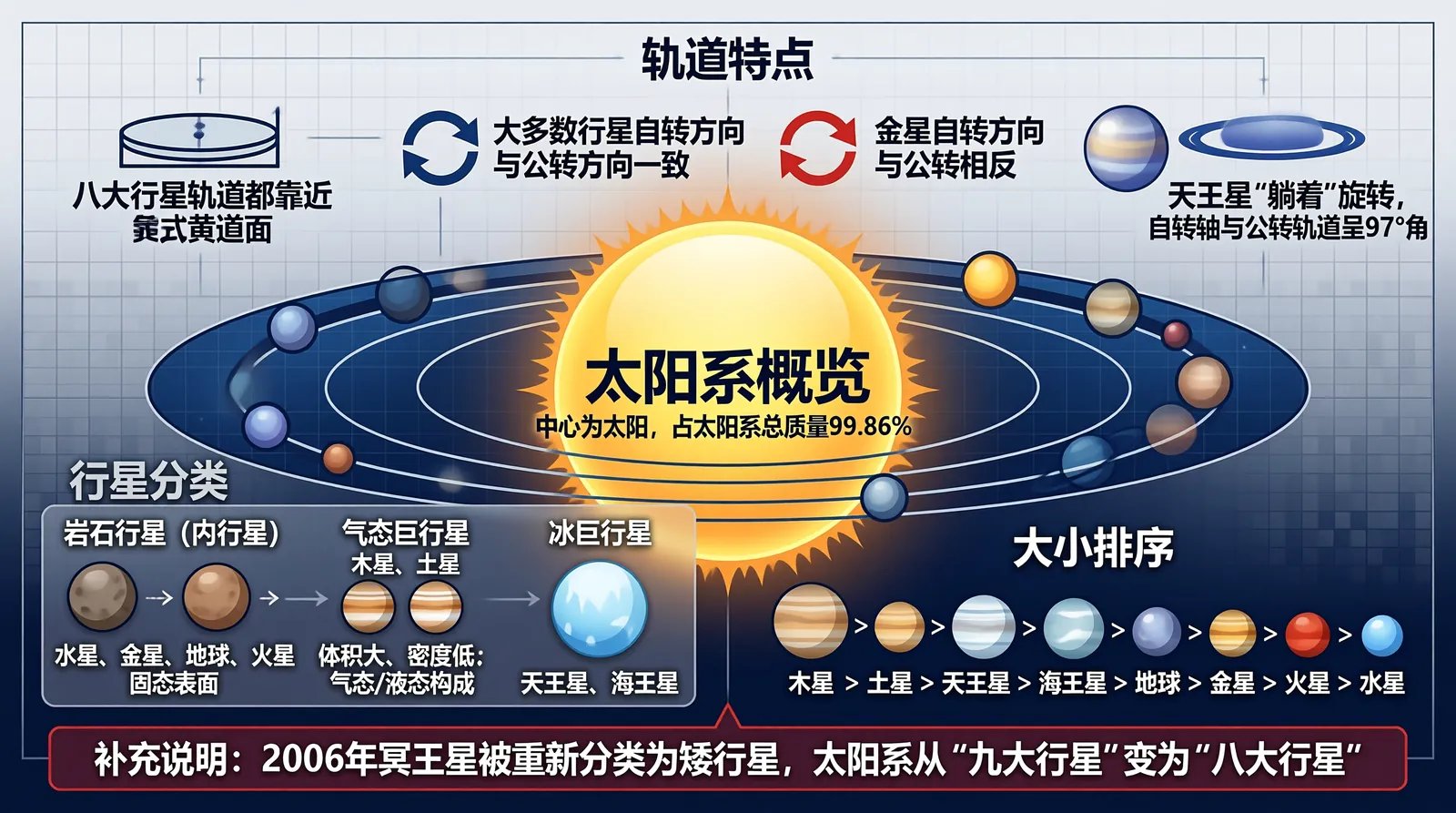
案例:太阳系科普图解 八大行星各自的轨道、属性、图文介绍一应俱全。模型不仅准确呈现了天文知识,还自动完成了信息分层、视觉设计和排版布局,展现出对复杂科学概念的理解和可视化能力。
案例:电梯安全警示牌转信息图 扔给它一张路边常见的“电梯安全”警示牌,让它换个排版做成一张信息图。它能直接把版式从警示牌切成科普卡片,完美实现风格迁移,把枯燥的安全提示变成易读的知识图解。这展示了模型对现有视觉内容的理解和重构能力。
4️⃣ 产品爆炸图与技术流程图
案例:相机爆炸图 前段时间火爆的产品爆炸图,在 U1 这里也可以做到。一台相机,被它拆得整整齐齐:镜头组、反光镜、快门、传感器、芯片、电池什么的,统统被它拆得整整齐齐悬浮在空中,标注线一根不少。

案例:GitHub 代码自动生成架构图 让我惊喜的是:U1 可以直接读取我的 GitHub 地址:github.com/huangserva/skill_video-style-analysis,自动分析开源项目的代码逻辑并生成专业的技术架构图。我只是提交了自己项目的 GitHub 链接,它就自动理解了整个系统的工作流程,并输出了清晰的可视化架构图——这种“理解代码+生成图表”的能力,真正做到了多模态统一。(当然文字处理上,还需要更努力)
🌐 应用场景

SenseNova U1 的统一架构在以下场景中可能有应用价值:
📊 知识可视化
论文图解、数据图表、技术架构图、科普图解等内容的可视化呈现
🎨 营销设计
社交媒体海报、活动宣传图、产品爆炸图、视觉提案等设计场景
📝 文档增强
产品说明、功能流程图、用户指南、操作教程等文档的图文结合
🎬 创意叙事
连环画、分镜脚本、故事板、教学演示等连续性图文创作
已知局限
值得一提的是,商汤在 README 中坦诚披露了模型的当前限制:
交互方式:U1 采用“单次指令→直接出图”模式,不支持多轮对话和上下文记忆,需要在一次提示中完整表达需求。
文字渲染:中文字符偶现乱码、模糊或拼写错误,长文本排版稳定性有待提升。
其他限制:上下文最长 32K;复杂场景中人物细节不够稳定;连续性图文创作仍处于 beta 阶段。
这些短板均标注“持续改进中”。
开源信息
开源版本
本次开源包含两个版本:
- SenseNova-U1-8B-MoT:8B 参数,端侧可跑
- SenseNova-U1-A3B-MoT:总参数 38B 的 MoE 架构,提供更强的能力
GitHub:github.com/OpenSenseNova/SenseNova-U1
Hugging Face:
huggingface.co/collections/sensenova/sensenova-u1
此外,商汤还给 U1 配了一套自研推理栈,LightLLM 跑理解、LightX2V 跑生成,两条路解耦各管各的。以 H100/H200 单节点为例,生成一张 2048×2048 的图,端到端大概 9 秒。
🌟 结语
商汤通过 SenseNova U1 展示了一种不同的技术路径:用统一架构处理图像理解和生成任务。模型已全面开源,开发者可以基于此进行进一步的研究和应用开发。