
开篇:我第四次重复同一件事时,才意识到问题不在模型

那天很晚了,我第四次解释同一条规则:
"发给我"不是"告诉我生成好了",而是要直接发附件。
对面的 Agent 不是听不懂,它当下都能理解,甚至能复述得很好。问题在于第二天、下一轮、一次 compact 之后,它又像重置了一样。
那一刻我意识到:
我们缺的不是更强模型,而是记忆层。
单轮对话里,失忆像小毛病;长期协作里,失忆是系统性灾难。
第1章:多 Agent 系统最大的敌人,不是笨,而是断片

我们有 4 个 Agent(黄家1号、智库、技术顾问、创意伙伴)。当协作拉长到周级、月级,断片会被放大成连锁问题:
实际案例:
2026-02-15:告知智库"文件发送必须用白名单路径"
2026-02-17:智库又从 ~/development/ 发文件 → 报错
2026-02-19:再次提醒 → 理解并复述规则
2026-02-21:compact 后 → 又从非白名单路径发文件
断片连锁反应:
- 同一偏好重复解释(浪费 Token)
- 决策不继承,标准漂移(每次都要重新确认)
- 经验沉淀不上链路(踩过的坑反复踩)
- compact 后"人格重置"(session 压缩后规则丢失)
- 同类错误反复复发(无法形成集体记忆)
技术根因:

真正刺痛我们的不是"回答错一次",而是协作连续性断掉。这已经不是聊天质量问题,而是系统工程问题。
第2章:最早我们以为,只要把记忆存下来就够了

最早我们把记忆理解成存储问题:
早期记忆存储方式:
~/Documents/Obsidian Vault/
├── MEMORY.md # 手动维护的记忆摘要
├── TODO.md # 任务清单
├── Agent日志/ # 对话记录导出
└── 项目文档/ # 各种 Markdown 文档
问题:这些东西都"存在",但不"参与工作"。
实际场景:
用户:智库,查一下我们之前讨论的"白名单路径"规则
智库:[开始读取 MEMORY.md]
→ 文件太大,超过 context 窗口
→ 即使读进去,也找不到具体段落
→ 只能回答:"我建议你重新告诉我一遍"
后来我们才真正吃透:记忆不是仓库,是链路。至少四步缺一不可:
完整记忆链路:
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ 1. 写入 │ → │ 2. 索引 │ → │ 3. 召回 │ → │ 4. 接入 │
│ (可靠) │ │ (可检索) │ │ (相关) │ │ (工作流) │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
↓ ↓ ↓ ↓
事务验证 BM25+向量 语义排序 Hook注入
回查确认 分类过滤 时效衰减 规则强制
这四步里,任何一步缺失,都会把"有记忆"退化成"有资料"。
对比:
- 有资料:你知道信息在哪,但每次都要手动翻(像去图书馆查书)
- 有记忆:信息在正确时机自动出现(像人脑自然想起)
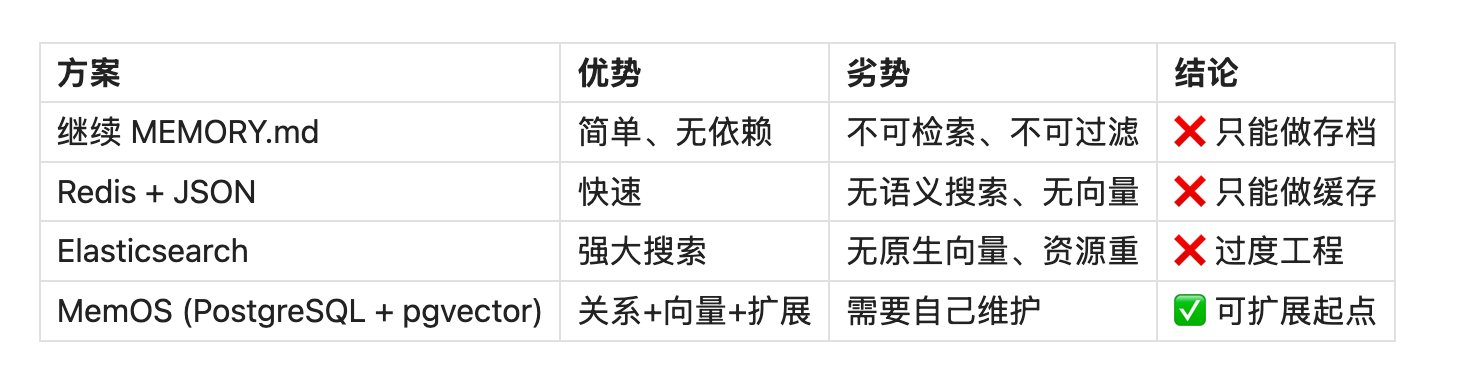
第3章:第一层突破--把"记忆"变成可检索能力

我们选择 MemOS,不是因为它完美,而是它给了可扩展起点。第一代基础设施很快成型:
技术选型:为什么是 MemOS?
第一代基础设施架构:

使用示例:

这一步让"翻文档回忆"变成"可检索调用"。
但很快我们发现:找得到,不等于用得好。后面的关键痛点会落在两件事上:
- 写入可靠性(第4章)
- 运行链路接入(第5章)
第4章:第二层突破--原生写入不可靠,我们接管写入主权

我们遇到过最危险的故障之一:8001 写入"假成功
问题现场:
# 2026-02-20 14:23:15,写入返回 200
*curl -X POST http://127.0.0.1:8001/write *
-
-H "Content-Type: application/json" *
-
-d '{"text":"测试写入"}'*
# 返回:{"status":"ok"}
# 但数据库里查不到
psql -U postgres -d memos -c "SELECT * FROM memories ORDER BY created_at DESC LIMIT 1;"
# 结果:0 rows
问题本质: 原生写入流程是"黑盒调用":
- 我们 → 发送文本 → MemOS API → ??? → 数据库
- 中间环节失败时,API 仍可能返回 200(例如 embedding 超时但事务未回滚)
我们的改造思路: 把"黑盒"拆成"白盒",让每步可验证:
- 提取层:自己控制哪些内容写入(而非依赖自动提取)
- Embedding 层:本地生成 embedding,确保拿到向量
- 写入层:直接操作 PostgreSQL,开启事务
- 验证层:写完后立即回查,确认落盘
技术链路对比:

为什么我们也会踩坑? 早期我们自己也有操作问题:
- 直接复制配置文件时,参数映射错误(embedding_dim 写成 vector_dim)
- 事务管理不严谨(commit 前没检查异常)
- 这些都导致"看起来成功、实际失败"
最终收益:
- 写入失败 = 立即报错(不会静默污染)
- 每条记忆可追溯(知道谁写的、何时写的)
- 可以批量修复历史数据(直接操作数据库)
这一步不是普通 bugfix,而是系统主权回收。
第5章:第三层突破--有记忆,不等于 Agent 会按需用记忆

我们一度以为"存好了,Agent 自然会用"。现实恰好相反:
实际场景:
2026-02-22:记忆库已有 1000+ 条记录
用户:智库,查一下"白名单路径"规则
智库:[直接回答,没有查记忆]
→ "建议你把文件放到 workspace 目录"
用户:这条规则我们之前讨论过,你怎么没查记忆?
智库:[才意识到应该先查]
→ curl "http://127.0.0.1:8899/search?q=白名单路径"
→ [找到 3 条相关记录]
问题本质:
记忆库里有数据
↓
但 Agent 不会主动触发检索
↓
不知道何时该搜(触发时机缺失)
↓
用户继续重复同样信息(退回到人工记忆)
所以问题不只在后端,而在工作流接入。
我们的三步改造:
5.1 Skill 触发:让 Agent 按需调用记忆
**改造前:**强制 Agent 每次都查记忆(浪费 Token)
**改造后:**通过 Skill 系统,让 Agent 在需要时才调用
技术实现:
## memory-search Skill
触发条件:
- 用户问"之前讨论过的..."
- 任务涉及历史决策
- 需要查找过往经验
调用方式:
curl -s "http://127.0.0.1:8899/search?q=关键词&top_k=5"
效果:
- 不是每次都查(节省 Token)
- 需要时才查(按需触发)
- 更符合人类记忆模式(想不起来才去查)
5.2 启动注入:把高相关记忆提前送进上下文
改造前:
Agent 启动 → 空 context → 第一轮消息才开始查记忆
改造后:
Agent 启动 → 自动注入最近 5 条高相关记忆 → 已有上下文
技术实现:
# ~/.openclaw/shared-knowledge/scripts/memos_inject.py
def inject_relevant_memories(agent_name):
-
1. 查询该 Agent 最近的记忆*
-
recent = search_memories(f"agent:{agent_name}", top_k=5)*
-
2. 注入到 system prompt*
-
context = build_context(recent)*
-
3. Agent 启动时自动加载*
-
return context*
注入方式的演进(v1.0.3 更新):
早期版本(v1.0.0)把召回的记忆塞进 systemPrompt,这会覆盖或干扰 Agent 原有的系统提示词(SOUL.md、AGENTS.md 等核心规则)。v1.0.3 改用 prependContext 模式——记忆作为前置上下文注入,不触碰系统提示词本身。
v1.0.0:记忆 → systemPrompt(与核心规则混在一起,可能互相干扰)
v1.0.3:记忆 → prependContext(独立注入,核心规则不受影响)
这个改动看起来小,但对我们的 4-Agent 系统影响很大——每个 Agent 的 SOUL.md 和 AGENTS.md 是行为准则的根基,绝不能被记忆注入冲掉。
5.3 高优先级规则强制注入
**问题:**即使有记忆,某些高优先级规则仍可能被淹没
解决方案:
系统提示词优先级:
系统提示词优先级:
┌─────────────────────────────────┐
│ 1. SOUL.md / AGENTS.md (核心规则) │ ← 最高优先级,强制注入
├─────────────────────────────────┤
│ 2. MEMORY.md 当前状态 │ ← 高优先级
├─────────────────────────────────┤
│ 3. 相关记忆(MemOS 检索) │ ← 动态加载,按需触发
├─────────────────────────────────┤
│ 4. 当前对话历史 │ ← 正常上下文
└─────────────────────────────────┘
效果:
- "发给我 = 发附件"这类核心规则永远不会被淹没
- 降低"看不见规则"的概率
- 按需调用记忆,节省 Token
从这时开始,记忆不再是外挂附件,而是按需进入 Agent 生命周期。
不进入运行链路的记忆,最终都会沦为存档。
第6章(核心):真正的升级--从定时提取到实时写入,从存档到在线索引

这是我们后期最重要的突破,也是整篇最关键的一章
6.1 早期方案为什么不够
早期方案:cron + agent_end 事后沉淀
时间线:
10:00 - 用户告知"白名单路径"规则
10:05 - Agent 理解并执行
...
18:00 - cron 任务触发,提取今日记忆
18:01 - 记忆写入 MemOS
18:05 - 第二个 Agent 开始任务 → [可以查到记忆]
天然短板:
- 记忆写入滞后(8小时后才入库)
- compact 前后容易漏(compact 把中间细节压缩掉)
- 刚发生的关键信息,不能及时被下一任务调用
它更像"散会后补纪要",不是"会议进行中同步结构化记录"。
6.2 实时写入为什么是范式变化
改造后的时间线:
10:00:00 - 用户告知"白名单路径"规则
10:00:03 - Agent 理解并执行
10:00:05 - [实时 Hook 触发] 提取 → embedding → 写入
10:00:08 - 记忆已在 MemOS 可检索
10:00:15 - 第二个 Agent 查询 → [立即找到]
实时写入不是小优化,而是系统时效性的范式变化:
- 刚发生的事实几秒内进入可检索层
- 协作上下文在多 Agent 间更连续
- 系统不再完全依赖"事后整理"
6.3 实时不等于同步阻塞
我们没有走"每轮都卡主链路去写库"的粗暴做法:
❌ 错误做法(同步阻塞):
用户消息 → Agent 处理 → 写入库(等待 500ms)→ 返回结果
↑
主链路被拖慢
✅ 正确做法(异步 + buffer):
用户消息 → Agent 处理 → 立即返回
↓
[异步写入]
↓
buffer 聚合(10秒窗口)
↓
批量入库 + 质量治理
这套平衡解决了两个矛盾:
- 要实时,又不能拖慢响应
- 要多捕获,又不能把噪音写爆
6.4 数据入库三层架构:向量 → 图 → 演化
我们后面最深的理解之一:记忆不只是"存文本+向量",而是要建立多层索引能力。
三层架构设计:

为什么需要三层?

真实案例:8001 写入"假成功"
问题现场:
# 2026-02-20 14:23:15,写入返回 200
*curl -X POST http://127.0.0.1:8001/write *
-
-H "Content-Type: application/json" *
-
-d '{"text":"测试写入"}'*
# 返回:{"status":"ok"}
# 但数据库里查不到
psql -U postgres -d memos -c "SELECT * FROM memories ORDER BY created_at DESC LIMIT 1;"
# 结果:0 rows
**根因:**原生写入流程是"黑盒调用",中间环节失败时 API 仍可能返回 200
**解决方案:**三层验证机制
写入 → 第一层验证(向量索引是否生成)
→ 第二层验证(关系边是否建立)
→ 第三层验证(回查 ID 确认落盘)
这套架构不只是"存得快",而是"存得对、找得准、用得好"。
6.5 索引策略:从"能搜"到"搜得准"
真实案例 1:BM25 空结果
2026-02-25:搜索"白名单路径" → 0 条结果
排查:历史记忆缺 search_tokens 字段
解决:回填 search_tokens → 恢复检索
真实案例 2:分类检索超时
2026-02-28:按 category_id 过滤 → 查询 8 秒
排查:大数据量(1万+条)下 category_id 无索引 → 全表扫描
解决:CREATE INDEX idx_category → 查询 12ms
真实案例 3:向量维度不匹配
2026-03-01:切模型(text2vec-base-chinese → bge-small-zh)
错误:旧 embedding(768维)未清,新模型(512维)写入
报错:vector dimension mismatch
解决:清空旧 embedding → 重建索引
这几次事故让我们形成硬认知:
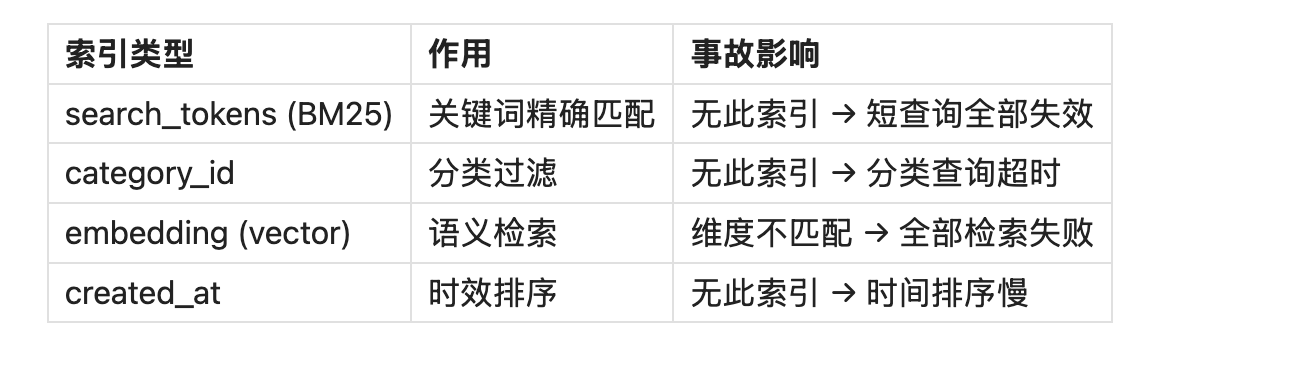
没有多路检索策略,记忆只有存量,没有召回能力。
分词器的关键升级(v1.0.3):
MemOS 本地插件在 v1.0.0 时使用 FTS5 的 porter unicode61 分词器——这是英文词干分词,对中文几乎无效。搜"白名单路径"可能返回 0 结果,因为 porter 根本不认识中文字符。
v1.0.3 把分词器换成了 trigram(三字符滑窗),这对中文是质的飞跃:

"白名单路径" 在 trigram 下被索引为:
→ "白名单", "名单路", "单路径"
搜索 "白名单" → 命中 "白名单" → 找到记忆 ✅
升级时自动迁移(migrateFtsToTrigram),不需要手动操作。同时还加了 pattern search 兜底:2 字符短词(如"路径")trigram 也搜不到时,用 LIKE 模糊匹配作为最后防线。
这个改动直接解决了我们之前"BM25 空结果"的痛点——不是 BM25 不行,是分词器不认中文。
6.6 从"能搜"到"搜得准"
召回不是越多越好,而是当前任务相关性越高越好。
我们把检索层做成组合能力:
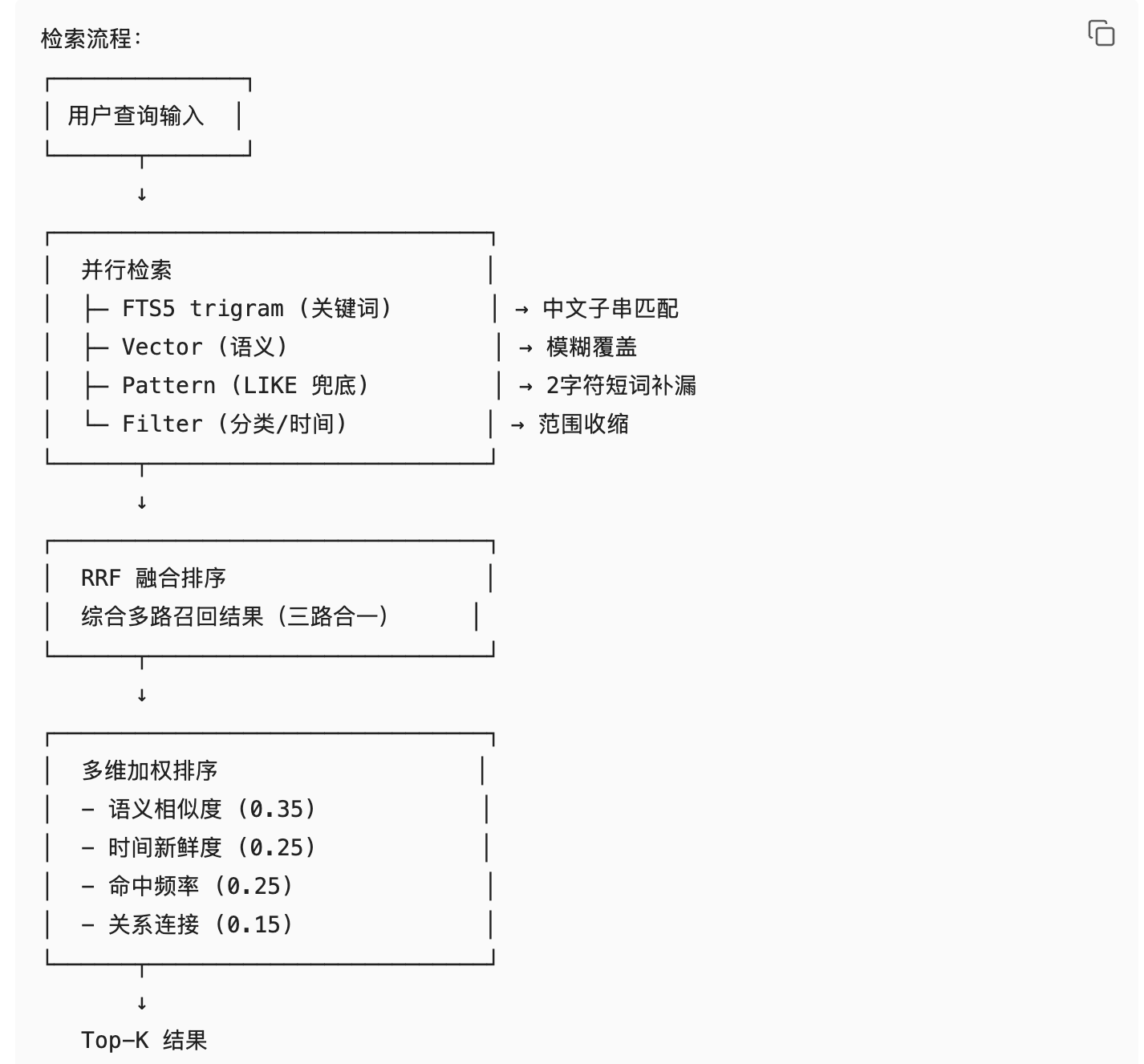
在 2026-03-01 的对比快照里,我们看到:
"白名单路径" 在 trigram 下被索引为:
→ "白名单", "名单路", "单路径"
搜索 "白名单" → 命中 "白名单" → 找到记忆 ✅
6.6 运行时观测:3/10 的"在线系统"现场
3/10 我们做健康检查时,系统状态显示:
检查脚本
bash ~/.openclaw/shared-knowledge/scripts/health-check.sh
输出:
✅ pgvector: 正常
✅ 总记忆数: 15955
✅ 最近写入: 0.1 小时前
✅ 8899 API: 正常
✅ 搜索功能: 正常
⚠️ 8001 服务: 在线(但主写入已不依赖)
但同一天我们也收到一个"很真实的线上信号":
- 定时巡逻有时带推文链接,有时无链接(输出不稳定)
- 同批次出现重复 Cron 通知(调度去重失效)
这类问题说明:系统已从"能不能跑"进入"在线可运维"阶段。你要开始处理的,不再是有没有功能,而是链路一致性、输出稳定性、调度去重。
这也是在线 Memory OS 的典型现实:核心能力可用之后,运行质量本身成为下一主战场。
第7章:之后,我们才真正理解 MemOS

3/1 前后,我们有一轮"功能层面的完成感";3/1 之后,真正发生的是认知升级
7.1 从"功能完成"到"系统可用"
之前的认知:
✅ MemOS 部署完成
✅ 写入链路打通
✅ 检索 API 可用
→ 任务完成!
之后的现实:
运行现场的问题:
- 健康检查能看到链路状态,但不能替代链路治理
- 记忆条数持续增长(1.5万+),但命中率才是关键指标
- 检索变快(120ms),不代表稳定,索引与分类策略要持续演化
真实案例:记忆库有 1.5 万条,但命中率只有 65%
排查过程:
检查最近 100 次搜索
grep "搜索查询" ~/memos.log | tail -100
发现问题:
- 35% 搜索返回 0 结果(并非没有相关记忆)
- 原因:查询词与记忆文本不匹配(语义鸿沟)
解决方向:
不是增加记忆总量,而是优化:
- 查询改写(用户输入 → 标准化查询词)
- 记忆扩展(写入时补充同义词、别名)
- 多路召回(BM25 + 向量 + 关系扩展)
7.2 价值不在总量,在命中率
对比:
指标追求总量 追求命中率
记忆数 10万+ 条 1.5万 条
搜索延迟 2秒 120ms
命中率 40% 65%+
用户体验 "搜不到" "立即找到"
**结论:**1.5 万条高相关记忆 > 10 万条低质量噪音
7.3 写入可靠性比功能清单重要
我们踩过的坑:
功能清单:
✅ 支持实时写入
✅ 支持 BM25 检索
✅ 支持向量检索
✅ 支持分类过滤
✅ 支持关系扩展
实际运行:
❌ 写入假成功(第4章)
❌ 索引缺失导致检索失效(第6章)
❌ 向量维度不匹配导致全部检索失败(第6章)
硬认知:
功能列表 = "能做什么"
可靠性 = "真的能用"
后者比前者重要 10 倍。
7.4 索引是能力,不是实现细节
早期认知:
索引 = 数据库优化细节,以后再说
后期认知:
索引 = 记忆系统的核心能力
- 无 search_tokens → 关键词检索失效
- 无 category_id → 分类查询超时
- 无 embedding_index → 语义检索不可用
索引不是"优化",是"能不能用"的前提。
7.5 多 Agent 协作必须有边界治理
问题:记忆污染
场景:
- 智库写入:"这个技术方案不可行"
- 技术顾问搜索 → 找到这条记忆
- 但技术顾问不知道这是智库的"主观判断"
- 结果:错误记忆传播
解决方案:分权 + 标注
记忆边界:
┌───────────────┐
│ Shared 分区(公共记忆) │
│ - 所有 Agent 可读 │
│ - 只有黄家1号可写(协调者) │
├───────────────┤
│ Agent 私有分区 │
│ - 智库:策略、决策 │
│ - 技术顾问:技术实现 │
│ - 创意伙伴:内容创作 │
└───────────────┘
每条记忆必须带:
- agent: 写入者
- created_at: 写入时间
- category: 分类标签
- confidence: 可信度(可选)
自动污染清理(v1.0.3 新增):
边界治理不只是"写入时分权",还要处理已经污染的数据。v1.0.3 加了 autoCleanupPolluted 机制——插件启动时自动扫描并清理两类问题数据:
- 被污染的 user chunks:系统元数据(Discord sender metadata、inbound context JSON)被错误地当作用户消息存入记忆
- 混合 user+assistant chunks:一条记忆里同时包含用户消息和 Agent 回复,角色边界模糊
插件启动 → 扫描 chunks 表
→ 发现 role=user 但内容包含 metadata JSON → 删除
→ 发现内容混合了 user+assistant → 修复角色标记
→ 日志记录:Auto-cleanup: removed N polluted, fixed M mixed
这解决了我们之前遇到的一个隐蔽问题:Discord 的 sender metadata 被当作"用户说的话"存进记忆,导致搜索时返回一堆无意义的 JSON 片段。
7.6 Memory OS 的关键是接入生命周期
完整生命周期:
┌─────────────────┐
│ 1. 写入层(实时 + 兜底) │
│ - Hook 实时写入 │
│ - agent_end 事后沉淀 │
│ - cron 定时补偿 │
└─────────────────┘
↓
┌──────────────────┐
│ 2. 检索层(多路召回 + 排序) │
│ - BM25 + Vector + Filter │
│ - RRF 融合 + 多维加权 │
└──────────────────┘
↓
┌─────────────────────┐
│ 3. 注入层(启动注入 + 规则强制) │
│ - Agent 启动时自动加载高相关记忆 │
│ - 核心规则强制注入(SOUL.md / AGENTS.md) │──────────────────────┘
↓
┌──────────────────┐
│ 4. 清洗层(去重 + 评分 + 清理) │
│ - 内容哈希去重 │
│ - 质量评分过滤 │
│ - 定期清理低价值记忆 │
└──────────────────┘
我们最终沉淀了 5 条"重新理解":
- 价值不在总量,在命中率
- 写入可靠性比功能清单重要
- 索引是能力,不是实现细节
- 多 Agent 协作必须有边界治理
- Memory OS 的关键是接入生命周期(写入/检索/注入/清洗)
这一章的意义是:把"项目复盘"抬升为"系统方法论"。
第8章(强化版):最终形态--魔改清单、改造顺序与收益对照

你提得很对:第8章不能只讲"理想形态",必须把我们实际魔改的工作写透。这里给出完整清单。
8.1 改造顺序(为什么这样排)
我们不是并行乱改,而是按"先保生存,再提质量,再补治理"推进:
- 先接管写入可靠性(解决假成功)
- 再统一检索入口(让系统可查可用)
- 再做混合召回+排序(把召回质量拉起来)
- 再做多 Agent 边界(防记忆污染)
- 再做三层捕获(实时性与兜底)
- 再做质量治理(清理噪音)
- 再做分类与关系(组织能力升级)
- 最后做健康监控(在线运维能力)
8.2 魔改清单 + 收益对照
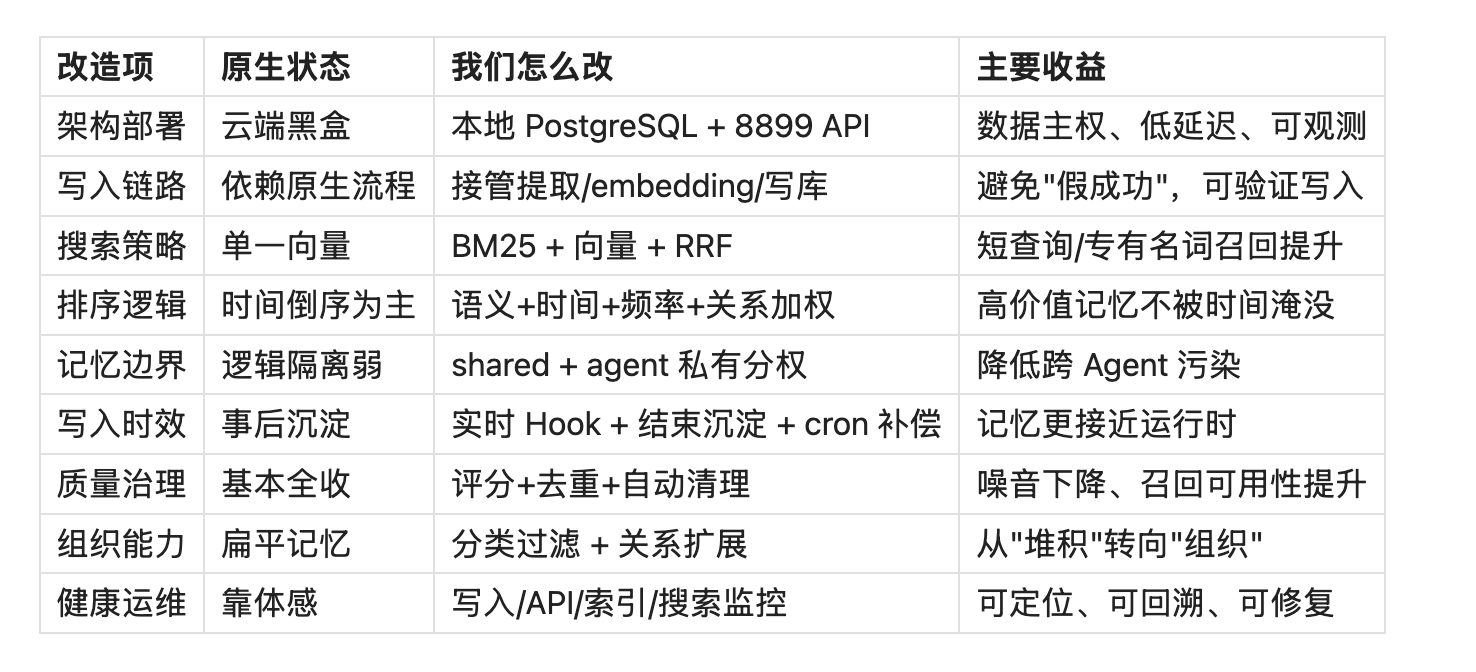
8.3 第8章的核心结论
我们做的不是给 MemOS 加几个 feature,而是把它改造成可持续运行的 memory infrastructure。
这才是"4-Agent 团队不再失忆"的真实来源。
第9章:我们还没解决的事--真正在线 Memory OS 的七个未完成命题

这一章必须诚实,而且必须系统。
9.1 实时写入的性能与噪音控制
越靠近对话链路,噪音越容易进入记忆层。异步、buffer、阈值、采样仍在持续迭代。
9.2 分类体系持续演化
分类不是一次设计完成,任务结构变化会反向推动分类体系漂移。
9.3 recall 准确率与成本平衡
查询改写、重排、分类过滤、语义融合都会产生算力与延迟成本。如何"找得准且跑得起"还在优化。
9.4 主动召回 / 主动提醒尚不成熟
被动检索已可用,但"在正确时刻主动提示"仍有误触发和上下文污染风险。
9.5 更细粒度索引尚未完成
当前多为记忆条目级索引,未来需要段落级、事件级、实体级、关系级索引协同。
9.6 多模态记忆还没真正开始(必须单列)
目前主力仍是文本。图片、截图、音频、视频、界面状态并未统一接入记忆层。
但真实工作流是多模态的,真正的 Memory OS 不可能长期只处理文本。
9.7 最后一公里:真正在线闭环仍未完成
我们已接近"在线",但还缺:
- 更稳的实时链路
- 更精细的主动机制
- 更成熟的治理策略
- 多模态统一入口
- 更强的运行时协同
这不是"弱点清单",而是下一阶段路线图。
第10章:外面的世界在做什么--MemOS 官方升级与 Google 方案的启示

我们埋头改了两个月,抬头一看,外面也没闲着。
10.1 MemOS 官方从 v2.0.6 走到了 v2.0.8
我们本地一直跑的是 v2.0.6。2026 年 2 月底到 3 月初,官方连发了 v2.0.7 和 v2.0.8,改了不少东西:
- Neo4j 全文搜索支持(之前只有向量通道)
- search_by_fulltext 连续三轮性能优化
- 偏好记忆排序从 score 改为 relativity(更语义化)
- 图片记忆 bug 修复、连接池优化
但最值得关注的不是这些小改进,而是他们在 v2.0.8 里塞了一个大东西:MemOS 本地插件(memos-local-openclaw)。从 v1.0.0 到截至本文写作时的 v1.0.3(2026-03-16 发布),这个插件经历了快速迭代,已经从"能用"进化到"好用"。
10.2 官方本地插件:从 v1.0.0 到 v1.0.3 的进化
这个插件跟我们的魔改思路有交集,但走出了我们没做到的路线。
记忆引擎层面,它做了三级智能去重:内容哈希快速跳过 → Top-5 向量相似检索(阈值 0.75) → LLM 判定是 DUPLICATE(丢弃)、UPDATE(合并)还是 NEW(新建)。我们的去重是评分规则,比这个粗糙。v1.0.3 把去重阈值从 0.60 调到 0.80,更宽松——减少了"相似但不同"的记忆被误杀的情况。
**真正拉开差距的是 Task → Skill 进化链路。**这是我们完全缺失的能力:
- 对话中自动检测任务边界(每轮 LLM 主题判定 + 2 小时空闲超时)
- 任务完成后 LLM 生成结构化总结(Goal / Key Steps / Result / Key Details)
- 自动评估任务是否值得提炼为技能
- 如果值得,多步 LLM 管线生成 SKILL.md + 脚本 + 引用
- 后续遇到类似任务,已有技能自动升级
这意味着什么?意味着系统不仅记住了"发生过什么",还能从经验中提炼"怎么做",并且越用越好。
我们的 MEMORY.md + TODO.md + patterns.md 体系,本质上是人工版的 Task → Skill 流程。我们靠规范和纪律保证 Agent 做完事去沉淀经验,而他们让机器自动完成这个闭环。
多 Agent 协作方面,他们做了 memory_write_public 工具--Agent 可以主动把信息写入公共记忆区,其他 Agent 自动可见。我们的 shared 分区是静态的文件同步,不是运行时的动态共享。
可视化方面,他们做了 7 页 Memory Viewer(Memories / Tasks / Skills / Analytics / Logs / Import / Settings),我们是盲人摸象,靠 curl 和 grep。v1.0.3 还加了模型健康检测、一键更新安装、记忆合并来源追溯等运维能力。
v1.0.3 相比 v1.0.0 的关键进化:
中文搜索从废到能用。原来用 FTS5 porter 分词,本质是英文分词器,中文几乎搜不到东西。v1.0.3 换成 trigram(三字符滑窗),天然兼容中文,短词还加了 LIKE 模糊匹配兜底。 记忆注入方式更干净。v1.0.0 把记忆塞进 systemPrompt,会干扰 Agent 核心规则。v1.0.3 改用 prependContext 独立注入,互不影响。搜索结果也不再截断到 300 字,返回完整原文。 工程细节全面补齐。去重阈值从 0.60 放宽到 0.80(减少误杀),Agent ID 改从 hookCtx 框架级传递(不再依赖不可靠的 event),Embedding 从 5 家扩到 11 家(加了智谱、硅基流动、百炼等国产厂商),启动时自动清理污染数据,还加了版本自动检查。
**Embedding Provider 的扩展值得单独说。**v1.0.3 新增了 zhipu(智谱)、siliconflow(硅基流动)、bailian(百炼/阿里云)、cohere、mistral、voyage。
对中文用户来说,能直接用国内厂商的 embedding 模型,不用绕海外 API,延迟和成本都更友好。
10.3 Google Always-On Memory Agent:概念好,实现是玩具
几乎同一时间,Google 开源了 Always-On Memory Agent。berryxia 写了一篇文章把它吹上天,但看代码就两个文件:agent.py + dashboard.py。
它的核心卖点是"整合"--每 30 分钟让 LLM 重新审视最近的记忆,发现跨记忆的关联和洞察。
概念确实好。人脑在睡眠时也在做类似的事:回放、连接、压缩。
但实现太粗糙了:
- 查询时把所有记忆 + 洞察塞进 context,规模一大直接爆
- 没有遗忘机制、没有权重衰减
- 没有持久化策略
- 不支持多 Agent
我们的 MemOS 在工程完成度上领先它至少两个量级。16,776 条记忆、49,618 条关系边、BM25 + 向量混合检索、4 Agent 分权--这些不是 demo 能比的。
但"定期跨记忆洞察生成"这个 idea,我们确实没做。
10.4 三方对比:各有各的长板

10.5 这一章的真正启示
三个系统各有长板,但合在一起指向同一个方向:
记忆系统的下一步不是"存得更多",而是"学得更快"。
- Google 的方案告诉我们:记忆之间的主动连接比被动存储更有价值
- MemOS 官方告诉我们:从对话到任务到技能的自动进化链路是真正的壁垒
- v1.0.3 的迭代告诉我们:中文搜索、注入方式、数据治理这些"基础设施级"的改进,比新功能更影响日常体验
- 我们自己的实践告诉我们:规模验证和写入可靠性是一切的基础
下一步的路线图因此变得清晰:
- 升级 MemOS 本地插件到 v1.0.3,拿到 trigram 中文搜索和 prependContext 注入
- 引入 Task → Skill 进化能力(官方插件或自建)
- 加入"定期跨记忆洞察生成"(借鉴 Google 方案)
- 保留并强化关系图谱和写入验证--这是我们的独有优势
- 评估国产 Embedding Provider(智谱/硅基流动/百炼),降低延迟和成本
不是选一个方案替代另一个,而是把三条路线的精华合进我们的系统。
第11章:结尾--AI 什么时候才算真正开始工作?

最开始,我们一遍遍重复同样规则;后来,系统开始记住:
- 你如何做决策
- 团队为何这样分工
- 哪些偏好已经确认
- 哪些坑已经踩过
- 哪些经验应沉淀为共同记忆
AI 真正开始工作,不是第一次回答对问题。
而是它第一次把昨天、上周、上个月积累下来的经验,继续带进今天的协作。
这就是我们做这套记忆基础设施的意义。
附:全文反复出现的"观点钉子"
- 我们缺的不是更强模型,而是更可靠记忆层。
- 有记忆库,不等于 Agent 会用记忆。
- 写入、索引、召回,三者缺一不可。
- 不进入运行链路的记忆,最终会沦为存档。
- 实时写入不是优化,而是时效性范式变化。
- 索引不是细节,它决定能否真正找回记忆。
- 多 Agent 协作需要的不是 memory feature,而是 memory infrastructure。
- 记忆系统的下一步不是"存得更多",而是"学得更快"。