
当你发送一份老文档的图片或者PDF 给 OpenClaw 的时候,一不小心 token量就刷刷往上涨。
为什么呢?
官方内置一些 PDF 和图片的工具都是使用大模型的能力。处理一两页还行,但是处理起大批量文件的话,价格就过于昂贵了。
但是我们这个世界很多信息其实还是没有数字化的,比如说发票,合同,名片。假如不将这些信息数字化提供给 AI,AI 在公司业务中的落地几乎是不可能的。
AI 连合同都看不到,那么如何给你判断合同中的条款是否符合你的利益呢?
所以,OpenClaw 急需精确,价格便宜的 OCR 方案。
文心衍生模型PaddleOCR文档解析能力基于文心大模型体系训练,已上线ClawHub,Agent 工作流中可直接调用文档解析能力,刚好能提供一个完美的解决方案
相比昂贵的大模型视觉方案,PaddleOCR 提供了每天 1w 页的免费解析页数,而且还能申请更多。
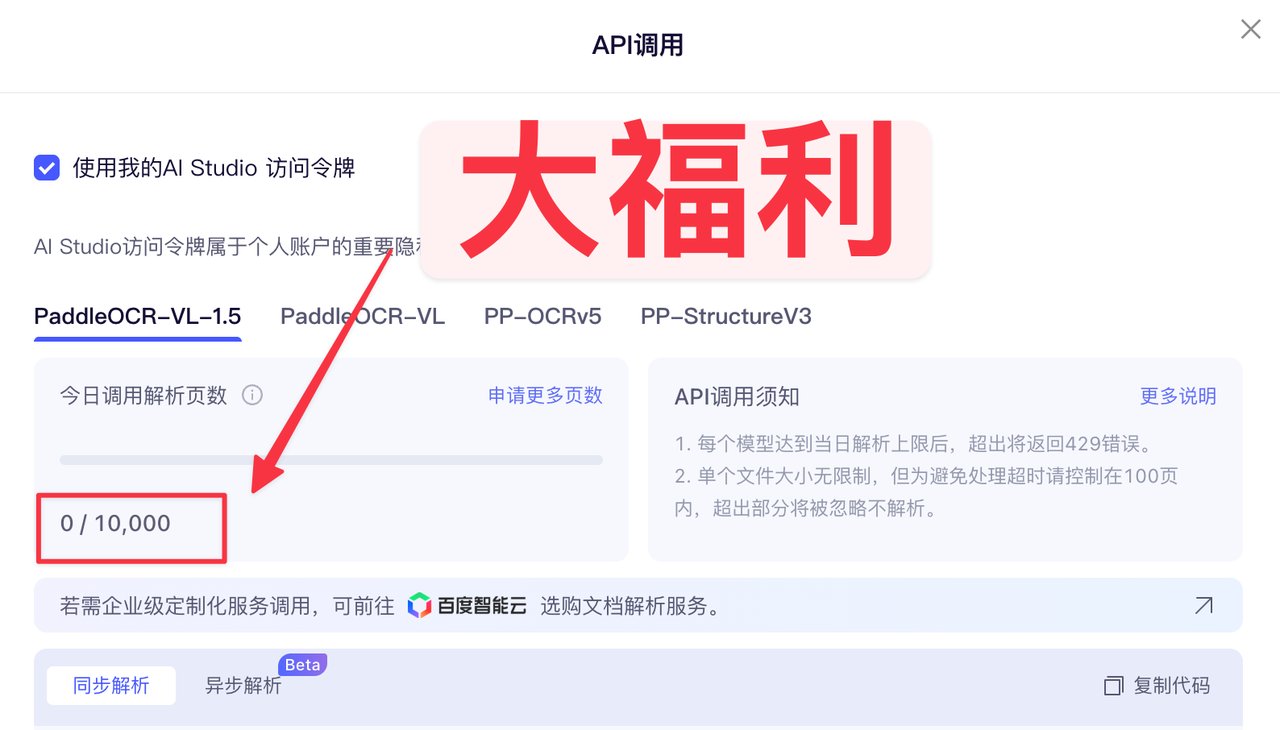
今天就手把手带大家快速白嫖这个福利。
安装PaddleOCR Skill
输入下面网址:clawhub.ai/Bobholamovic/paddleocr-doc-parsing,我们就能看到PaddleOCR Skill。
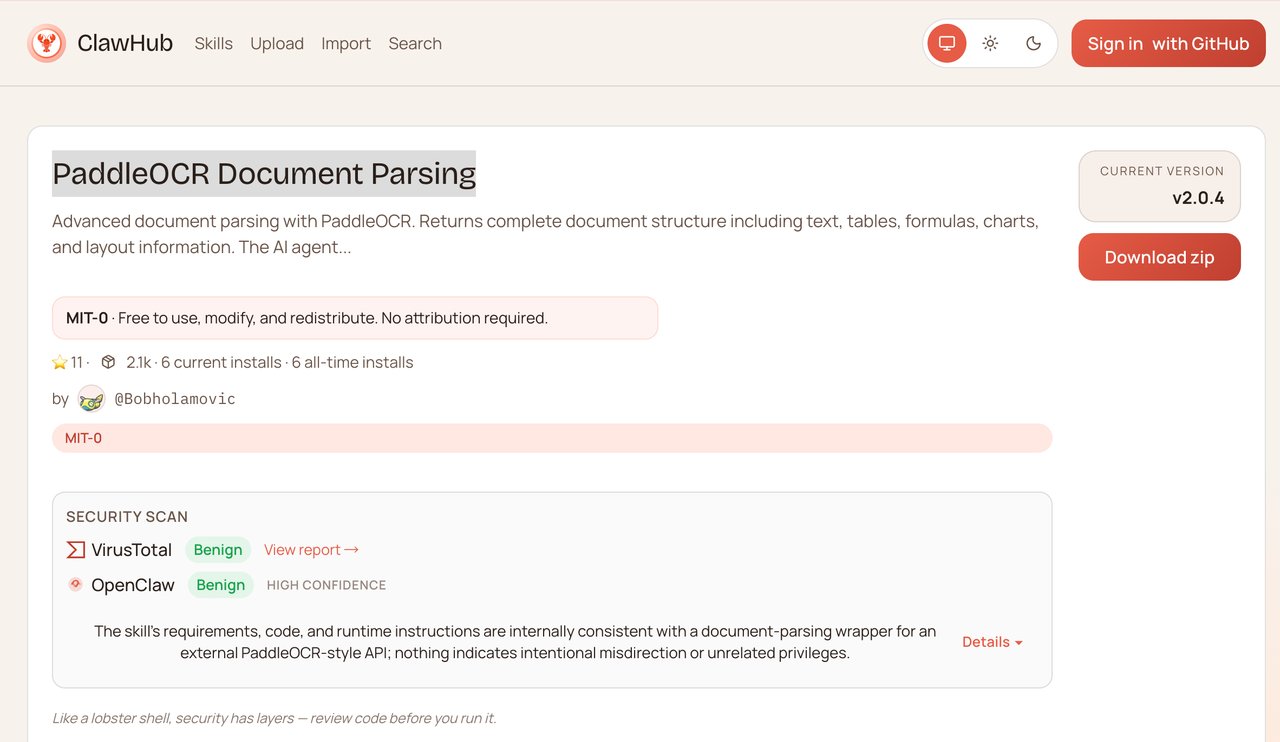
你以为我们需要乖乖下载安装,但是在 Agent 时代,一句话就能安装大部分东西。
输入下面文字
首先,请帮安装(https://clawhub.ai/Bobholamovic/paddleocr-doc-parsing)上的 Skill
PaddleOCR配置详情
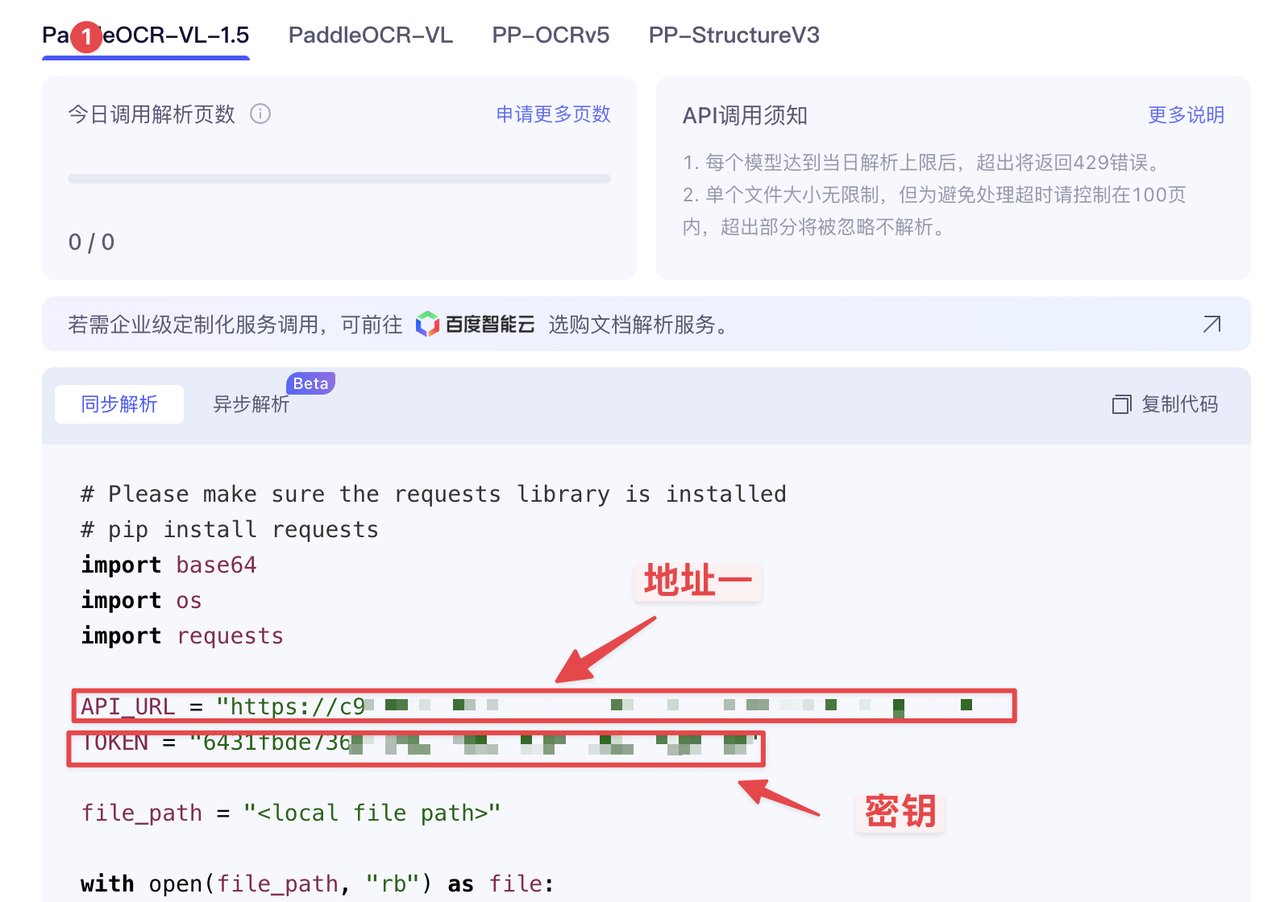
文档解析地址: <地址一>
文字识别地址: <地址二>
Access Token: <密钥>
按照下面步骤执行:登录 ClawHub → 下载 Skill → 安装技能 → 写入配置 → 执行测试 → 向我汇报安装报告。
现在问题是,去哪里获取上面缺失的两个地址和密钥呢!!
获取配置
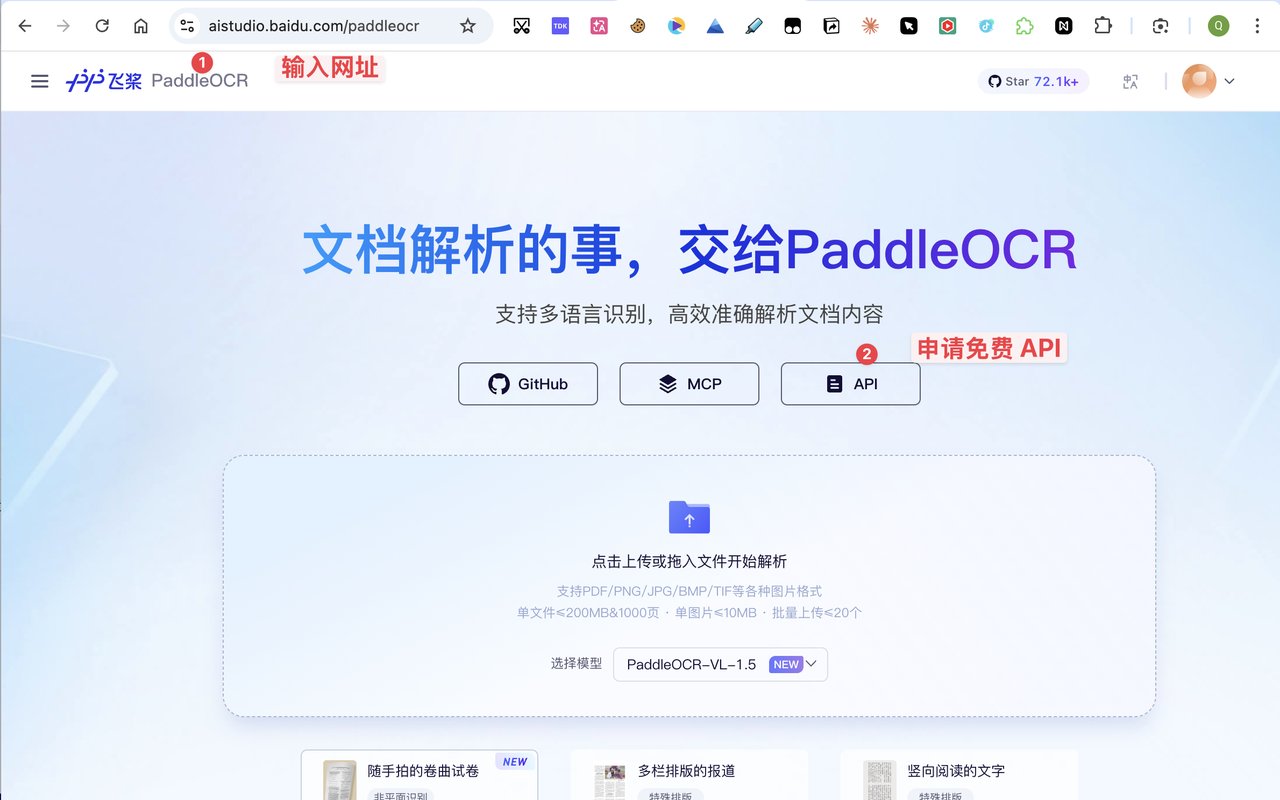
首先我们申请 API:
输入网址:aistudio.baidu.com/paddleocr
同意协议后,我们就能获取关键参数了
获取地址一和密钥如下操作即可:
获取地址二,如下操作:
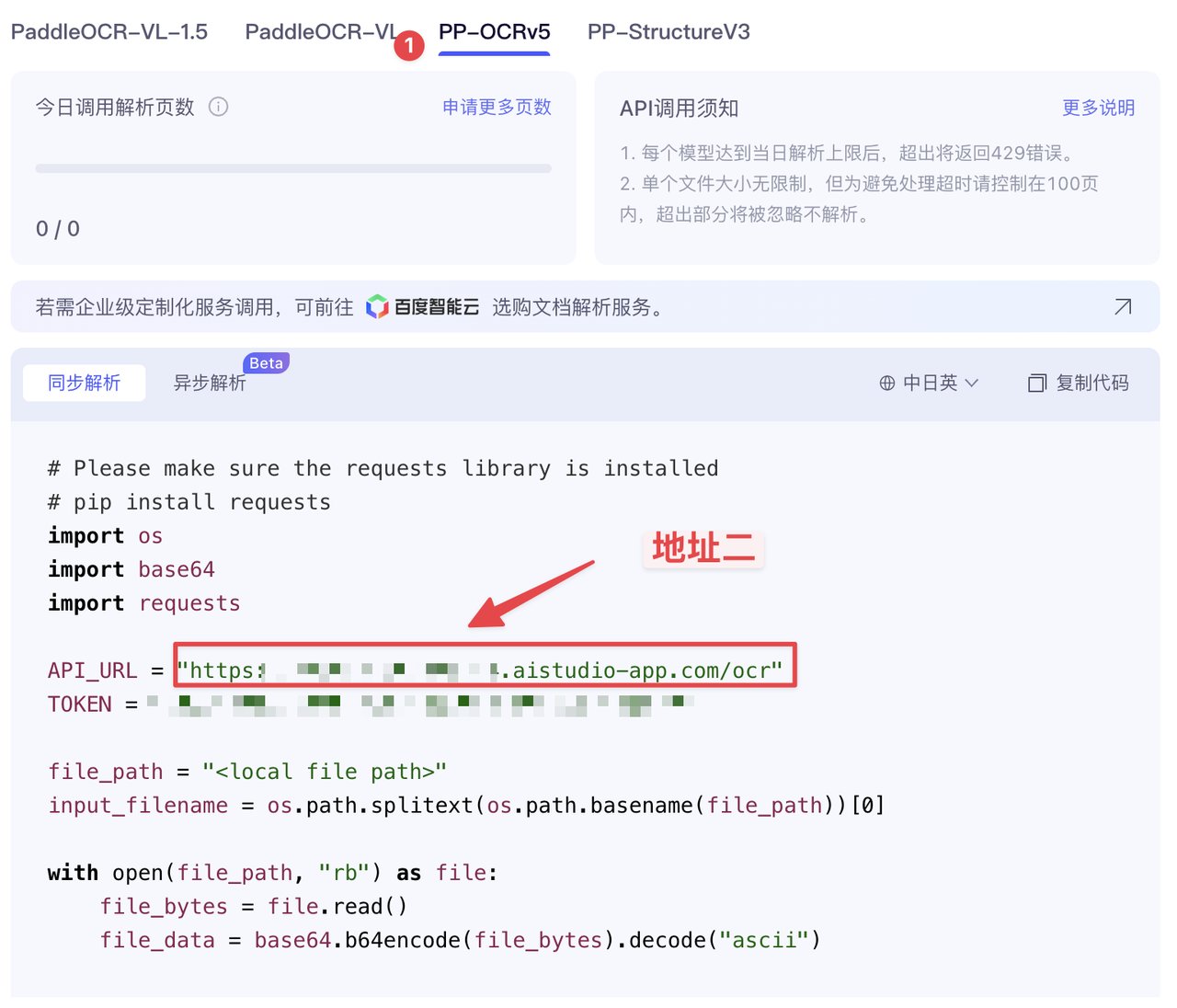
将这些填入,上面的模板,输入到 OpenClaw 的对话框内,即可完成安装。
但是我们大部分平时在外跑业务都是不用电脑的,下面演示如何在手机中实现名片的数字化,保存和记录
实际案例
直接在手机上将日常业务中拍摄的图片发给 OpenClaw,要求其用 PaddleOCR 识别

不会一它就操作成功了

可以看到,已经将数据保存到桌面了。这个案例看似简单,其实已经打通了,实际业务中的文档到 Agent 的流程
后续基于这些人的信息,写邮件,利用 Nano Banana Pro 专门年节假日做贺卡都行,
设计名片

这里是写文案

结束
OpenClaw 将会成为操作系统时代的 Linux 系统,未来将会是 Agent 与人协同的时代。
各个企业要拥抱 Agent,就必须将数据传递给 AI,让 AI 自动处理。
因此 OCR 作为将文档数字化的重要手段,会变得越来越不可或缺。
这段时间PaddleOCR提供了每日 1w 页的解析次数,也不知道这个福利能持续多久,赶紧收藏文章安装给 OpenClaw 使用,也可以分享给你的朋友来体验一下。
喜欢我的文章可以关注我的微信公众号
