
如何从 Reddit 评论里提炼用户画像?

如何从 Reddit 评论里提炼用户画像?
我一开始看 Reddit,其实只会看帖子。
标题够不够吸引人,赞数高不高,评论多不多。
看多了之后,慢慢发现一个问题:
很多真正有用的信息,不在帖子标题里,而在评论区里。
用户会在评论里讲得更具体:
- 他为什么不满意一个工具。
- 他已经试过哪些替代方案。
- 他为什么最后还是自己手动做。
- 他愿意为什么结果付费。
- 他担心什么风险。
- 他用什么词描述自己的问题。
这些话一开始看起来很碎。
但如果一条一条拆开,就会慢慢拼出一类人。
这篇文章想分享的,就是我现在怎么从 Reddit 评论里提炼用户画像。
不是一套很学术的方法。
更像我自己做选题、看需求、找产品机会时,经常会用的一套工作流。
先锁定具体场景
以前我会直接问:
“这个产品的用户是谁?”
后来发现这个问题太大。
问题一大,答案就容易变成一些很虚的词:
创业者、内容创作者、学生、营销人员、独立开发者。
这些词看起来有用,但落到产品和内容上,经常不知道下一步怎么做。
所以我现在会先换一个问法:
- 谁在什么情况下遇到什么麻烦?
- 他已经怎么解决?
- 哪里还卡住?
- 他为什么愿意继续讨论?
比如我想研究 AI 写作工具,就不会只搜 “AI writing tool”。
我会把它拆成几个更具体的 Reddit 场景:
- 学生用 AI 改论文,但担心检测风险
- 独立开发者用 AI 写营销文案,但觉得表达太假
- 内容创作者用 AI 批量生成帖子,但缺少个人风格
- 非英语母语者用 AI 润色邮件,但担心语气不自然
这样搜出来的评论,信息密度会高很多。
因为用户不再只是泛泛地聊 AI,而是在讲一个具体任务里的卡点。
收集评论,不只收集帖子
我现在看 Reddit,会先用帖子找方向,再用评论找细节。
帖子标题通常告诉我:大家正在讨论什么。
评论区会告诉我:大家为什么在乎这件事。
比如研究 AI 写作,我可能会看 r/ChatGPT、r/freelanceWriters、r/marketing、r/Entrepreneur、r/college。
每个 subreddit 的人群气质都不太一样。
r/ChatGPT 里会有很多工具使用者。
r/freelanceWriters 里会有很多写作者对 AI 的抵触和试探。
r/marketing 里会更关心效率、转化和内容质量。
r/Entrepreneur 里经常出现“能不能拿来做业务”的讨论。
找评论时,不只看高赞。还要看这些信号:
- 评论数量多不多
- 有没有争论
- 有没有多人补充同一个痛点
- 有没有用户反复提到同一类替代方案
- 有没有人明确说“我不会为这个付费”
我以前很容易只摘支持自己想法的评论。
看到有人说“这个需求很强”,就会觉得抓到了机会。
但后来发现,反对、质疑、吐槽也很重要。
因为这些评论会告诉我:用户为什么不买,为什么不信,为什么觉得现有方案已经够用了。
把评论拆成片段
我现在不会直接把一条长评论总结成一句话。
因为一条评论里,通常混着背景、情绪、行为和结论。
如果直接总结,很容易把最有用的细节抹掉。
比如一条评论:
“我试过几个 AI 写作工具,但它们写出来的东西都太像 LinkedIn 鸡汤。我不是不想用 AI,只是每次都要花很多时间改语气,最后还不如自己写。”
我会先把它拆成几个片段:
试过多个 AI 写作工具
不满意输出风格
不排斥 AI
后期改写时间太长
有时回到手写
然后再给每个片段打标签:
已尝试替代方案
风格不自然
编辑成本过高
愿意使用 AI
回退到人工完成
这样做会慢一点。
但我能看到用户的行为链条:
他不是不用 AI。
他已经试过。
他的问题不是“生成不了”。
他的问题是“生成后还要改很久”。
最后他又退回到手写。
这个链条,比一句“用户对 AI 写作不满意”更有用。
从标签里找用户分层
刚开始做用户画像时,我也会按身份分层。
比如学生、创业者、营销人员、自由职业者。
后来我发现,只看身份,经常解释不了他们为什么会买,为什么不会买。
现在我会多看四个维度。
第一,问题成熟度。
有的人刚开始抱怨:“这个太难用了。”
有的人已经试过多个工具:“A 不行,B 太贵,C 集成太差。”
有的人已经形成工作流:“先用 ChatGPT 起草,再用 Grammarly 改,最后手动调整语气。”
这三类人说的都是同一个方向的问题,但他们需要的东西差别很大。
刚开始抱怨的人,可能还需要被教育。
已经试过很多工具的人,可能在找替代方案。
已经形成工作流的人,可能更在意集成、稳定和节省步骤。
第二,替代方案。
我会特别看用户现在怎么解决。
因为产品要替代的东西,常常不是另一个软件。
有时是 Excel。
有时是 Notion。
有时是 Google Docs。
有时是外包。
有时是朋友建议。
有时是用户干脆忍着不解决。
第三,付费阻力。
有人不付费,因为不相信结果稳定。
有人不付费,因为担心隐私。
有人不付费,因为免费方案已经够用。
有人愿意付费,但只愿意为节省时间付费。
这些细节会影响后面的产品表达。
如果用户担心隐私,就不能只讲效率。
如果用户担心结果不稳定,就不能只讲自动化。
如果用户免费方案已经够用,就要看有没有更强的付费触发点。
第四,用户原话。
我现在越来越重视用户原话。
他们可能不说 “content generation”,而说 “sounds fake”。
他们可能不说 “workflow automation”,而说 “I still have to babysit it”。
这些词很适合保留下来。
后面写选题、写标题、写落地页、写产品说明时,经常能直接用上。
组装用户画像
当标签越来越多,我会开始把相似片段聚到一起。
这时候才开始写用户画像。
我一般会保留 7 个部分:
- 用户类型
例如:已经尝试多个 AI 写作工具,但对输出风格不满意的内容创作者。 - 典型场景
例如:每天要发 LinkedIn、Newsletter 或产品更新,但不想让内容看起来像 AI 批量生成。 - 核心痛点
例如:AI 初稿节省了一部分时间,但后期修改语气又消耗大量时间。 - 当前替代方案
例如:用 ChatGPT 生成初稿,再多轮提示修改,最后手动重写关键段落。 - 决策标准
例如:能不能保留个人语气、能不能减少编辑时间、能不能直接发布。 - 付费触发点
例如:工具能学习已有文章风格,并稳定产出接近可发布的版本。 - 原话证据
保留代表性评论,用来校准团队理解。
比如最后可能整理成这样的画像:
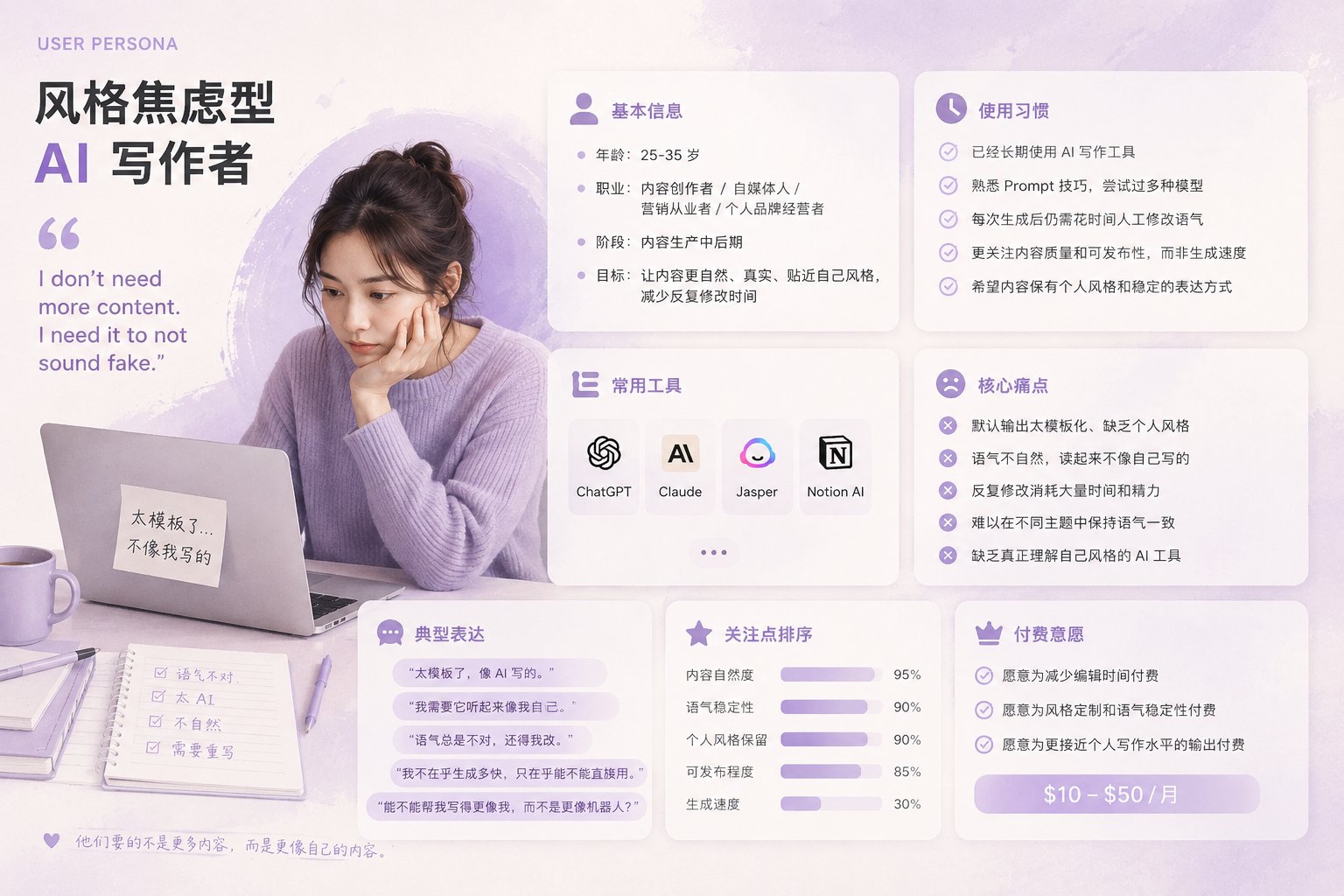
风格焦虑型 AI 写作者
这类用户已经开始使用 AI 写作工具,但对默认输出不满意。他们经常提到“太模板”“太像 AI”“不像我自己写的”。他们试过 ChatGPT、Claude、Jasper 或 Notion AI,也懂一些 prompt 技巧,但每次生成后还要花时间改语气。
他们关注的不是生成速度,而是表达是否自然、语气是否稳定、内容能否接近可发布状态。
他们愿意为减少编辑时间付费,也愿意为个人风格保留付费。
他们常见的表达类似:“I don’t need more content. I need it to not sound fake.”
写到这一步,我会尽量让画像看起来像一组行为模式,而不是一个编出来的人。
我也会把原话留在旁边。
这样后面回看时,能知道这个画像从哪里来。
用反例校准画像
这一步我以前很容易跳过。
看到一些评论都指向同一个需求,就会很想马上下结论。
但 Reddit 上愿意评论的人,通常表达更主动,情绪也更强。
所以我现在会刻意找反例。
可以问:
- 有没有用户觉得这个问题不严重?
- 有没有用户用免费方案已经满足?
- 有没有用户明确拒绝付费?
- 有没有其他 subreddit 表达了相反意见?
- 有没有用户只在特定场景下痛,而不是长期痛?
如果一个画像经不起这些问题,后面做产品或者写内容时,就很容易跑偏。
反例不是为了否定需求。
它更像一个校准动作,帮我知道这个需求的边界在哪里。
把画像转成产品动作
用户画像写完,我不会把它停在文档里。
我会继续问三个问题:
这个用户最想减少什么成本?
他最怕什么风险?
他用什么标准判断方案好不好?
如果用户反复提到“AI 写出来不像我”,产品动作可以围绕:
个人风格学习
历史文章导入
改写前后对比
语气一致性检查
不同平台表达适配
可发布版本输出
如果用户反复提到“不敢完全交给 AI”,产品表达就可以换一个方向:
保留人工控制
AI 先做初稿
用户决定最终版本
每一步可编辑、可回退
这也是我觉得 Reddit 评论很有价值的地方。
它不只给我需求点。
它还给我用户的语言、怀疑、替代方案和购买边界。
最后
如果让我把这套流程压缩成几步,我会这样做:
- 先选场景。
- 再收集评论。
- 然后拆片段。
- 接着打标签。
- 再聚合成用户类型。
- 最后用反例校准,并转成产品动作。
我现在越来越少从脑子里直接想用户画像。
更多时候,是先去看用户怎么说。
看他们怎么吐槽,怎么比较,怎么解释自己的选择,怎么拒绝一个方案。
这些原话看起来零散。
但只要耐心拆开、归类、对照,就会慢慢浮现出一类用户的轮廓。
对我来说,这比一开始就写一个漂亮的人设,更可靠,也更接近真实工作里的决策。
数据来源与参考资料
Reddit API Documentation
www.reddit.com/dev/api/
Reddit Data API Terms
redditinc.com/policies/data-api-terms
Reddit Data API Wiki
support.reddithelp.com/hc/en-us/articles/16160319875092-Reddit-Data-API-Wiki
Nielsen Norman Group: Empathy Mapping
www.nngroup.com/articles/empathy-mapping/
BMJ: Practical thematic analysis guide
www.bmj.com/content/381/bmj-2022-074256
Thematic Analysis, Braun & Clarke framework overview
en.wikipedia.org/wiki/Thematic_analysis