
如何在Reddit上挖掘小而美需求

用 Reddit 系统性挖掘「小而美需求」的方法论(实战版)
👉 一句话总览: Semrush 定方向 → Reddit 验需求 → RPA 自动化沉淀痛点 → AI 反推产品 & 内容

一、为什么一定是 Reddit?(平台选择逻辑)
1️⃣ 数据层面(Why Reddit)
引用的是 DataReportal 最新社交媒体报告:
- Reddit 用户体量已超过 X
- 在部分国家,接近甚至超过短视频平台的“可讨论用户量”
- 更关键:Reddit ≠ 内容消费平台,而是问题暴露平台
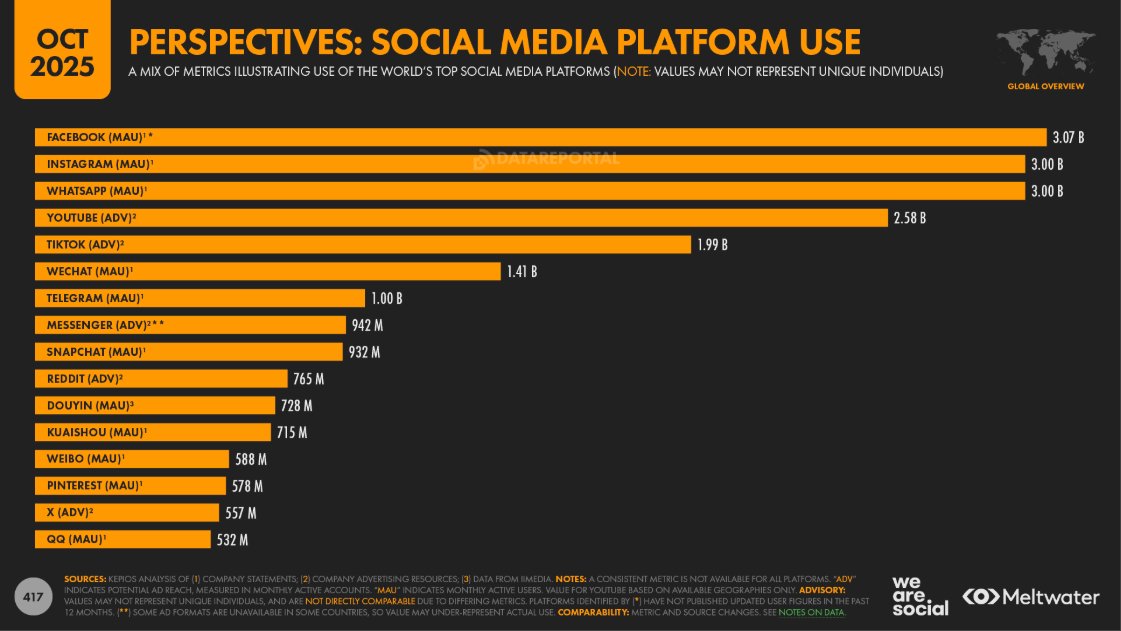
数据来源:datareportal.com/social-media-users?utm_source=chatgpt.com
2️⃣ 机制层面(Why Reddit is special)
Reddit = 海外版「真实用户需求数据库」
原因不是流量,而是需求暴露机制:
- 需求显性化 用户主动描述「我遇到了什么问题」,而不是刷内容被动点赞
- 讨论深度高 评论链长,观点交锋充分
- 去人设化 不靠大 V,不靠包装,信息更真实
- 主题结构天然清晰 Subreddit 本身就是用户细分(人群 × 场景)
- 全球化 + 英文语境 极适合做海外需求调研 & 出海验证
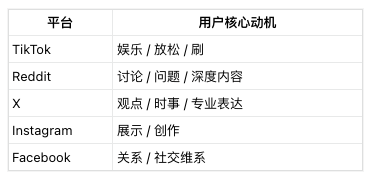
👉 结论一句话: 如果你想找“真实存在、反复出现、愿意付钱解决”的问题,Reddit 是当前性价比最高的地方。
二、卖什么?——用 Semrush 锁定「小而美需求方向」
1️⃣ 使用工具
- **SEMrush **https://www.semrush.com/
小而美需求的两个硬指标(非常关键)
具体量化为:
- KD%(Keyword Difficulty)低 👉 选择 0–14%
- CPC(Cost Per Click)> 0 👉 意味着已经有人愿意为这个词付钱
⚠️ 顺手解释一下:
KD = 做 SEO 的难度
CPC > 0 = 广告主已验证「可变现」
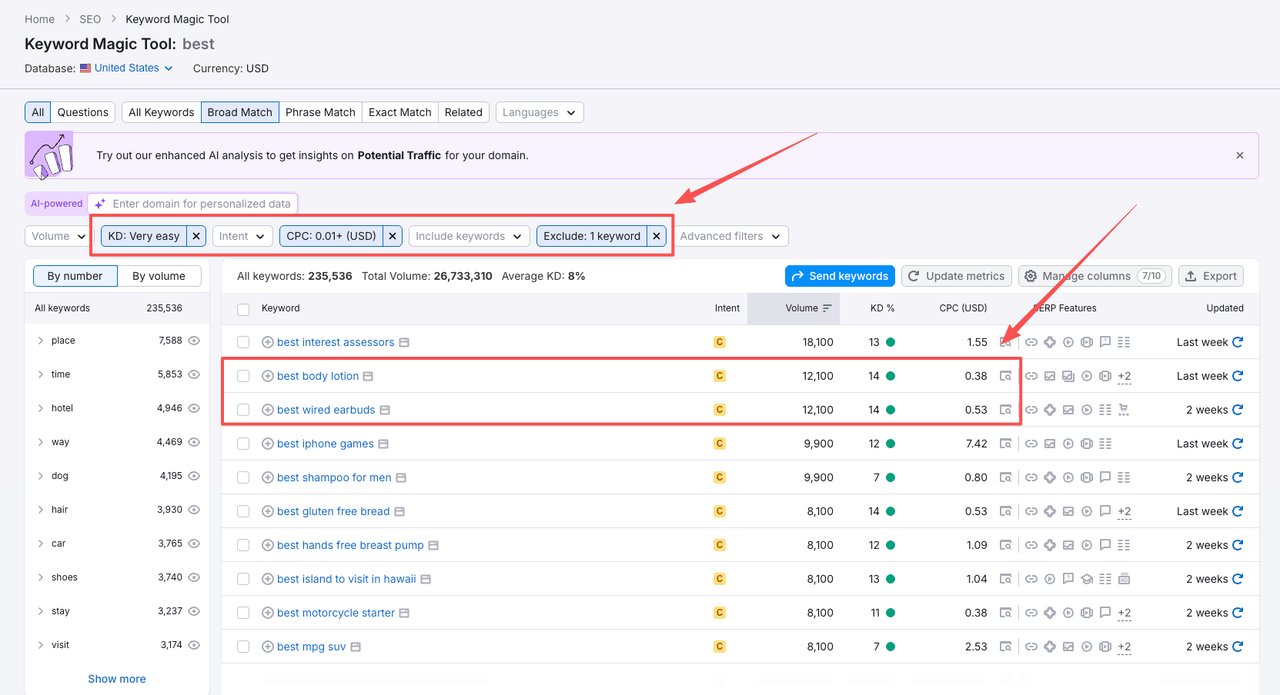
2️⃣ 实操步骤(可以直接照抄)
- 在 SEMrush 搜索框输入 泛词,如:
best - 筛选条件:
KD%:0–14
CPC:> 0.01 - 手动排除:
敏感 / 不可做词(如 casino、near 等)
你会得到一批非常典型的 “未被过度卷的真实需求”,例如:
- Best body lotion (可能是季节词)
- Best wired earbuds
👉 这一步的产出不是产品,是「候选需求池」 到这一步,不要急着做东西。
三、怎么卖?——去 Reddit 验证「这是不是真需求」
1️⃣ 使用工具
- Reddit 官方问答入口 **Reddit Answers **www.reddit.com/answers/
- Atlas 浏览器(侧边栏 + 大模型总结)chatgpt.com/zh-Hans-CN/atlas/

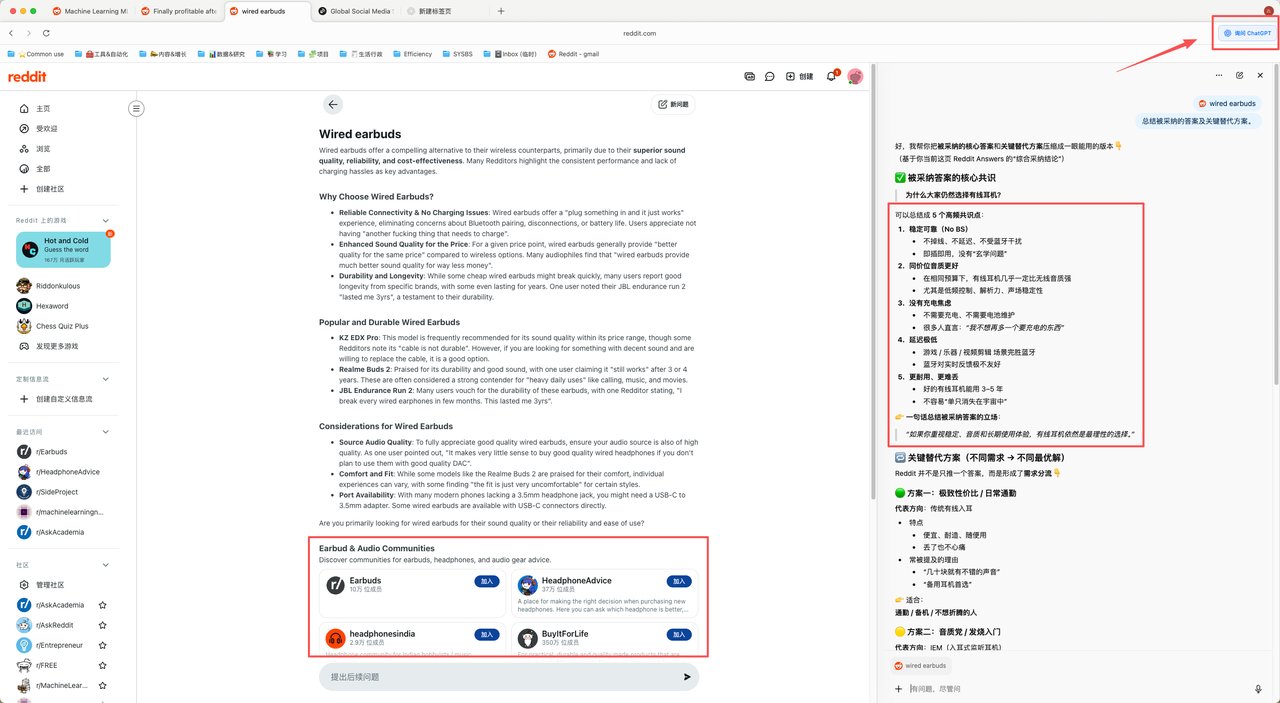
2️⃣ 操作逻辑(非常重要)
以 wired earbuds 为例:
- 在 Reddit Answers 中搜索关键词
- 用 Atlas 侧边栏 总结被采纳答案 & 高赞讨论
- 你关注的不是“好不好”,而是:
为什么选择
反复出现的理由
情绪词 & 场景词
✅ 被采纳答案的核心共识
为什么大家仍然选择有线耳机?
可以总结成 5 个高频共识点:
- **稳定可靠(No BS)
**不掉线、不延迟、不受蓝牙干扰
即插即用,没有“玄学问题” - **同价位音质更好
**在相同预算下,有线耳机几乎一定比无线音质强
尤其是低频控制、解析力、声场稳定性 - **没有充电焦虑
**不需要充电、不需要电池维护
很多人直言:“我不想再多一个要充电的东西” - **延迟极低
**游戏 / 乐器 / 视频剪辑 场景完胜蓝牙
蓝牙对实时反馈极不友好 - **更耐用、更难丢
**好的有线耳机能用 3–5 年
不容易“单只消失在宇宙中”
👉 一句话总结被采纳答案的立场:
“如果你重视稳定、音质和长期使用体验,有线耳机依然是最理性的选择。”
✅同时你还能得到什么?
- 高频讨论社区(= 内容投放阵地):
r/Earbuds
r/HeadphoneAdvice
r/BuyItForLife
r/headphonesindia
四、怎么做内容?——把痛点变成「可复用资产」
1️⃣ 使用工具
- 八爪鱼RPA(Reddit 应用是免费的)
(暂仅有Windows版)
Reddit应用官方手把手教程:https://base.feishu.cn/template-landing?token=AGI9bXyMFaivx1sXoFVcnoK7nbf&utm_from=octopus(🆓免费) - **飞书多维表(结构化沉淀)
2️⃣ 操作步骤
- 第一步,复制飞书多维表模板,获取“插件授权码”
- 第二步,打开八爪鱼RPA Reddit应用,一键运行
- 第三步,就可以跑起来自动收集Reddit社区帖文和评论到飞书多维表了
GIF
其他RPA平台也可以自己开发类似应用,写好数据获取逻辑和打通飞书多维表的配置即可。
你在这里做的事,其实是三件事:
- **监控 Subreddit
**持续抓取帖子 + 评论 - **提取“原话级痛点”
**用户真实表述,而非你自己的总结 - **结构化存储
**痛点 / 场景 / 情绪 / 对比对象
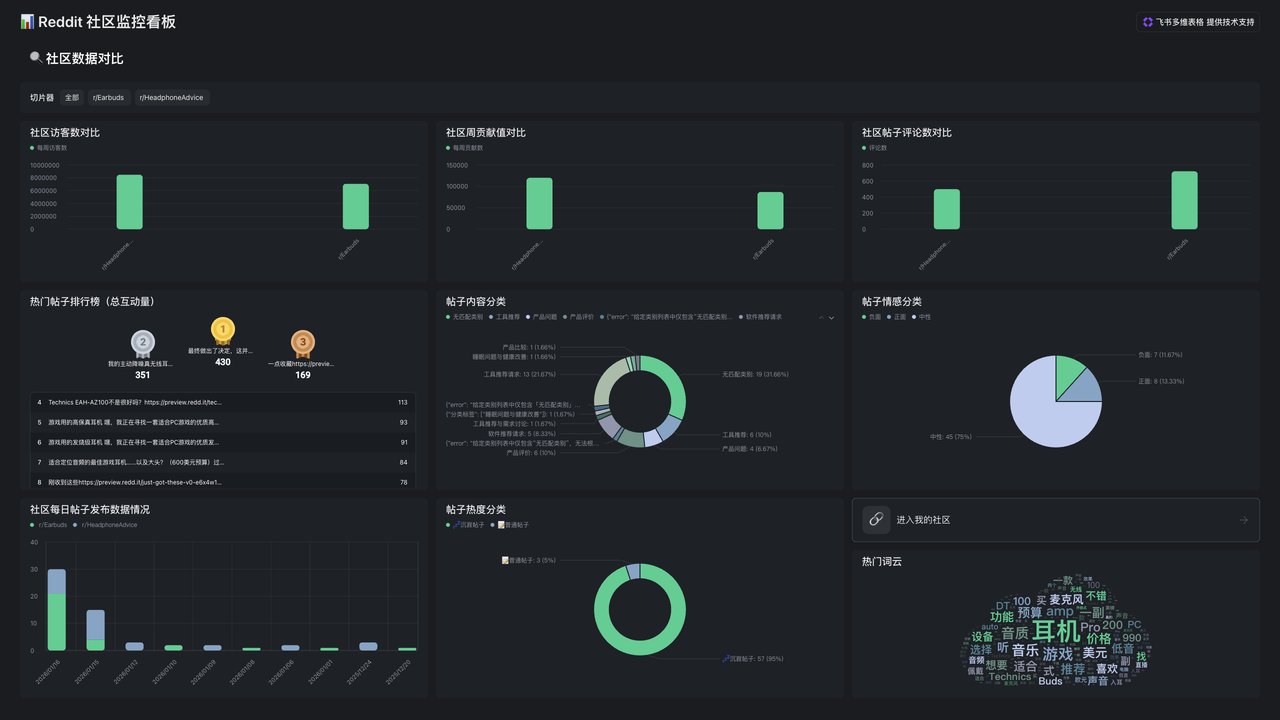
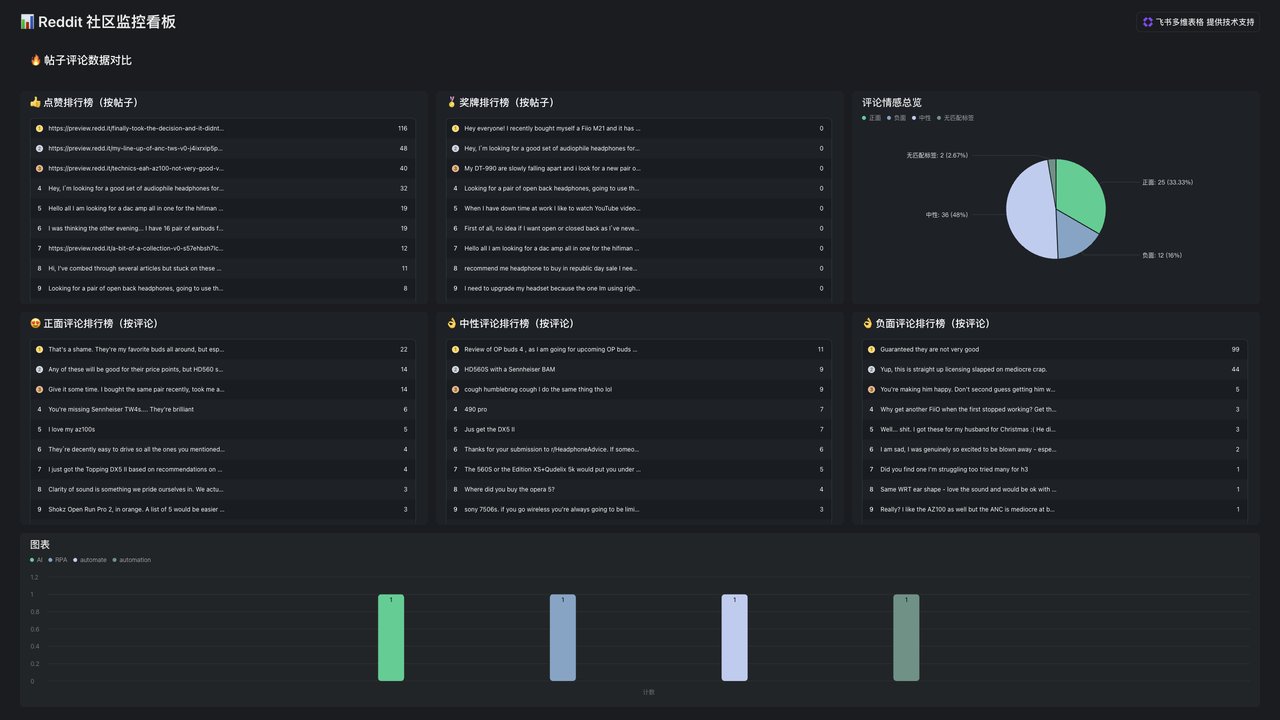
👉 最终你会得到三类“可直接用”的东西:
- 爆款内容选题
- 产品功能优先级
- 广告文案 & 语言
🧠 最终方法论总结
小而美需求 = 被验证 × 可表达 × 可持续
真正的小而美,并不是“小众”,而是“被忽视”。
它们早已存在于真实用户的日常抱怨、选择和妥协中,只是没有被系统地整理和尊重。
当你停止追逐风口,转而长期倾听一群人反复说同样的问题时,产品、内容和商业模式,往往会自然浮现出来。