少即是多(中):让 AI 精分的提示词

你有没有过这种经验:写了几百字的提示词,结果AI出的图乱七八糟——风格杂糅、画面油腻、构图四不像?
检查了一遍提示词,好像该写的都写了——光照、角度、材质、风格、情绪、色彩、构图、镜头参数、艺术家参考……一个都没漏,效果就是总差那么一点。
可能问题出在 "说的太多",不是"漏了什么"。
一、累积出来的烂提示词
我们当然想写一个很棒的提示词,但往往可能是这些原因,不知不觉中把提示词写烂了👇
第一条:AI代写。 你对AI说"帮我写个封面提示词,要高级、吸引眼球",AI输出给你200字的形容词盛宴——电影级光影、精致细节、8K、高级质感、立体金属字、渐变光效……全家桶一应俱全。你看着觉得真专业,复制,粘贴,然后翻车。
第二条:模板和合集。 收藏了很多提示词合集,一股脑发给AI,每个帖里抄一段,公式填空填一遍,可能你收藏的提示词每一段单独看都是好东西,但拼在一起,就起冲突了。
第三条:修补式迭代。 这条最常见但很隐蔽。没有人会主动写自相矛盾的提示词——矛盾是修出来的。 图太柔,加"锐利对焦";锐化过了,加"柔和氛围";不够高级,加"电影级光影"。水多加面,面多加水,几轮之后,图片质量直线下降,矛盾频出,只能重开对话。
每个词确实都有用,但模型只会把它们堆到一起。
二、同一条规律,换了一个载体
上篇讲了建筑和平面设计里的 Less is More。
建筑里,密斯说:结构本身就是装饰。 不要用大理石包钢柱,钢材就是钢材。装饰越多,结构越看不清。
平面设计里,苹果说:留白是主动决策。 产品只占画面30%,剩下的70%不是浪费,是指挥视线的工具。
两个领域,同一句话:注意力是有限的,元素越多,表达越弱。
这句话在1928年的建筑里成立,在1980年代的平面设计里成立,到了2026年,在AI生图领域依然成立。

传统的手绘或 PS 画图,是所见即所得的逐层修改——调一笔,看一眼。
但AI 绘图的流程不同:输入指令,直接产出效果。中间没有预览,你没法像 PS 那样逐层微调。
正因如此,人大概会产生一种本能的焦虑——"我必须一次性把所有要求全写进去,不然没机会改了"。 正是这种焦虑,逼着人把提示词越写越长。
最近几个月我在高强度用 GPT-Image-2 做项目。一开始的提示词写的像小论文,出来的图花里胡哨,试来试去才发现,路径从一开始就错了——那些论文式提示词,正是"AI代写"加"修补式迭代"的混合产物。
1. 权重稀释:注意力的零和游戏
文生图模型处理提示词的方式是权重分配,不是"阅读理解"。(当然具体机制复杂得多)
每个词,模型都会给它一定的注意力权重。提示词越长,每个词分到的权重越少。十个词同时争夺模型的注意力——结果就是都不够强。

这跟上篇讲的"留白"是同一个逻辑。
苹果广告里,产品只占30%的画面——70%的留白让那30%获得了100%的注意力。提示词也一样:删掉的词 = 让剩下的词获得更多权重。你在做的是重新分配注意力。
密斯在1928年说的是:不要填满空间,让结构自己说话。
你在2026年要做的是:不要填满提示词,让核心意图自己说话。
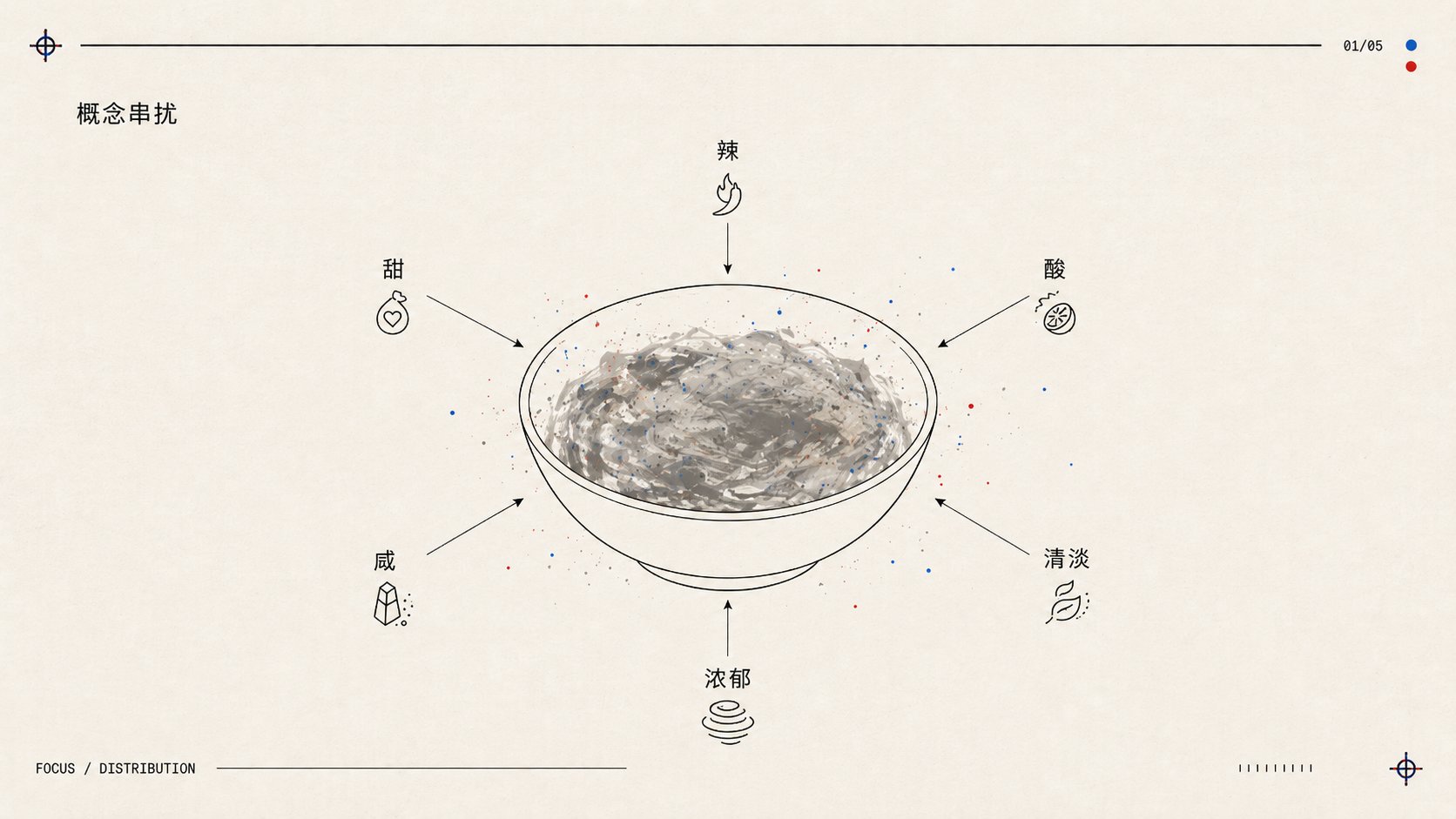
2. 概念串扰:AI版本的“装饰掩盖结构”
比权重稀释更严重的,是概念串扰(concept bleeding):一条提示词里塞进多个概念,在模型读取阶段就互相污染。你给了一串互相矛盾的方向,模型不会拒绝你,它会试图同时满足所有要求。
如标题所述:你在逼AI精神分裂。
就像要求厨师做菜:"这道菜又辣又甜又酸又咸又清淡又浓郁"——最后端上来的东西,什么味都有,这能好吃吗?
三、一个字,就能让图翻车
实现概念串扰只需要一个字:"或"。
我拿 "绘制一个女生,头发红色或绿色" 这句简单的提示词测试了三家大模型:
**GPT-Image-2 和 Gemini 的结果是:**大部分情况下是红色头发,我又把顺序倒过来试:"头发绿色或红色"。结果则是明显偏向绿色,而少数情况下,会出现红绿发色同时出现的情况。
同时还可以看出,就算是混合,也是第一个颜色当主色。因此**“或”**并不是真的随机,写在前面的词,分到的权重就是大。 并且也有干扰,偶尔还会存在人物是红发+绿衣服的情况——这就是"串扰"两个字的字面意思:你没选中的那个颜色不会消失,它可能会渗到别的地方去。
此外还能看出每家模型比例、画风等也各有区别,但这里不做具体讨论。


而 Grok 比较有意思,测试了几次,每次Grok都是干脆直接生成一红一绿两张图,让我自己选,哈哈。

那么可以看出不管哪种处理,指向同一个事实:并不是你决定了这张图片
你以为自己给的是选项——前面的实测已经证明,实际上模型并不会帮你思考选择,只不过是写在前面的提示词优先级更高罢了。
"或" 是把你的决定权交了出去,而 "不要" 则是把你的意图藏了起来。
Google 官方提示指南里有一组现成的对照:描述你要什么,别描述你不要什么——写 "empty street"(空旷的街道),别写 "no cars"(不要有车)。
我用 Gemini 把这组对照演示一遍:

如图所示,上图确实是空旷的街道,而下图中“车”确实没有,但行人、露天咖啡座全冒出来了。
而且,那我问你:图里的自行车,算不算车?
所以,想表达街道的空旷,就直接写空旷的街道,写“没有车的街道”,这根本就是意义不明的一句话。
否定词挡得住字面意思,但无法传达真正的意图。
你说"不要有车",模型抓住的主词是"街道",街道该有的热闹全补了回来;你真正想要的"空旷",一个字都没传达出去。
类似的表达还有**"尽量""稍微""适当"**之类。这些都是说给人听的词——人听到会帮你选、帮你拿捏分寸、帮你脑补,而模型只会把它们当成又一批要分权重的方向,况且,“稍微”到底是多少?就算是人也很难判断,这大概跟“我想要五彩斑斓的黑”是同样的道理。
提示词是一份决策文档。每一个没做完的决定,要么变成噪音,要么变成抛硬币。
密斯管这个叫结构的诚实性:装饰掩盖结构,观者看不到建筑真正的逻辑。放到AI时代,道理朴素得多——清晰表达。方向一冲突,模型就找不到你真正想要的。
四、官方的建议
当然,这些也不是我自己的一家之言,官方也是这么说的。
Midjourney《Prompt Basics》原文:Prompt Basics – Midjourney
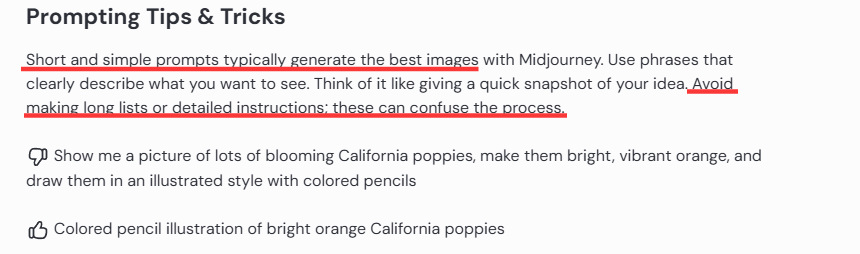
"Short and simple prompts typically generate the best images."
(短而简单的提示词,通常生成最好的图。)
"Avoid making long lists or detailed instructions; these can confuse the process."
(避免长列表和细节指令——它们会扰乱生成过程。)
OpenAI 的官方提示指南给的方法,标题就叫"迭代,而不是堆料"(Iterate instead of overloading):GPT Image Generation Models Prompting Guide

"Long prompts can work well, but debugging is easier when you start with a clean base prompt and refine with small, single-change follow-ups."
(长提示词也能用,但从一个干净的基础提示词开始、每次只改一处地迭代,排查问题容易得多。)
注意,这正是"修补式迭代"的官方正确版本:从少开始,一次只动一处
Google 的 Nano Banana 官方提示指南稍微有些区别。Ultimate prompting guide for Nano Banana | Google Cloud Blog
它通篇虽然没说"写短",但给的四条最佳实践却条条在省权重,如其中两条:

"Use positive framing: Describe what you want, not what you don't want (e.g. 'empty street' instead of 'no cars')."
(正向表达:描述你要什么,别描述你不要什么——写"空旷的街道",别写"不要有车"。)
"Iterate: Refine images with follow-up prompts in a conversational manner."
(迭代:用对话式的追加提示,逐步完善图像。)
三家说法各有侧重——Midjourney 直接劝你写短,OpenAI 劝你从短开始迭代,Google 劝你正向描述、把细节花在刀刃上——提示词怎么写其实官方已经告诉大家了,但好像很少有人看过文档。
总之,你会发现,三家在说同一件事:**所有手段,都在为表达服务,不是真的让你写短提示词。**Less is More 的重点从来不在"少",而在"表达"——删减、写短、正向、迭代,都是为了让核心意图被准确传达。短提示词只是表达清晰之后的副产品。
五、不同的模型,都吃这一套吗?
各个模型的口味确实不同,Nano Banana 像爱详细菜谱的厨师,每道工序交代清楚,他照着做——所以 Google 的指南才教你连布光、镜头都写明白。GPT-Image-2 像只需要听一句"做道川菜"的厨师,菜谱太细反而绑住他的手脚。

顺带澄清一个容易混淆的点:结构化不等于堆砌。 用JSON把提示词写得整整齐齐照样出好图,因为结构化的本质是消除歧义——它和少即是多在做同一件事:让信号干净。
不管哪个模型,该删的都一样:重复的、冲突的、模型能自己推断的;该留的也一样:只有你知道的。 区别只是少到什么程度。
六、没有公式,但有框架
通常文章写到这里,该给公式了:[主体] + [风格] + [光照] + [构图] + [氛围],再附四个模板让你复制粘贴。
但我这篇没有,因为这篇讲的东西,一句话就懂:表达最重要的信息。
这篇文章本身,就是一段提示词。
可以把这篇文章连同上篇,原文一起复制给你的AI,加一句话:"查看并分析这篇文章,以后帮我写提示词的时候,先用这套逻辑思考一遍,与我沟通交流后再产出提示词。"